 图像识别的技术原理,会看没那么简单
图像识别的技术原理,会看没那么简单
对人类来说,描述我们眼睛所看到的事物,即“视觉世界”,看起来太微不足道了,以至于我们根本没有意识到那正是我们时时刻刻在做的事情。在看到某件事物时,不管是汽车、大树,还是一个人,我们通常都不需要过多的思考就能立刻叫出名字。然而对于一台计算机来说,区分识别“人类对象”(比如:在小狗、椅子或是闹钟这些“非人类对象”中识别出奶奶这一“人类对象”)却是相当困难的。
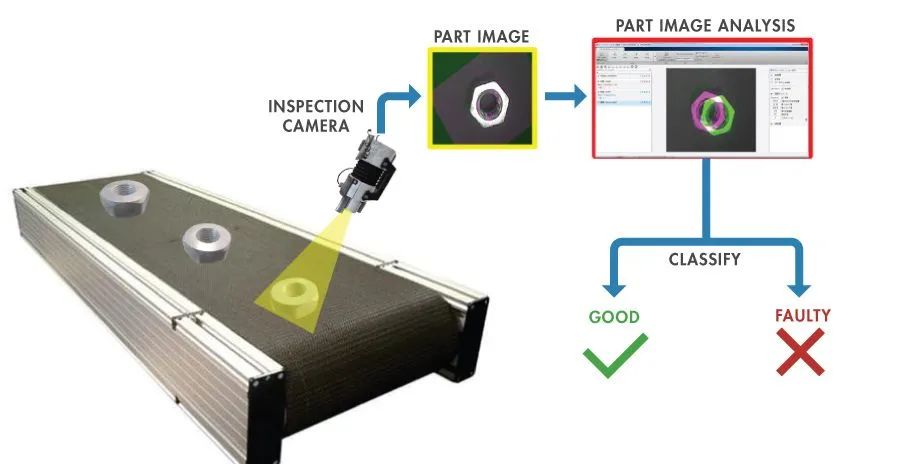
能解决这一问题可以带来非常高的收益。“图像识别”技术,更宽泛地说是“计算机视觉”技术,是许多新兴技术的基础。从无人驾驶汽车和面部识别软件到那些看似简单但十分重要的发展成果——能够监测流水线缺陷和违规的“智能工厂”,以及保险公司用来处理和分类索赔照片的自动化软件。这些新兴科技是离不开“图像识别”的。
在接下来的内容里,我们将要探究“图像识别”所面临的问题和挑战,并分析科学家是如何用一种特殊的神经网络来解决这一挑战的。
学会“看”是一项高难度、高成本的任务
着手解决这个难题,我们可以首先将元数据应用于非结构化数据。在之前的文章里,我们曾描述过在元数据稀缺或元数据不存在的情况下,进行文本内容分类和搜索遇到的一些问题和挑战。让专人来对电影和音乐进行人工分类和标记,确实是一项艰巨的任务。但有些任务不仅艰巨,甚至是几乎不可能完成的。比如训练无人驾驶汽车里的导航系统,让其能够将其他车辆与正在过马路的行人区分开来;或者是每天对社交网站上用户上传的千千万万张的照片和视频进行标记、分类和筛查。
唯一能够解决这一难题的方法就是神经网络。理论上我们可以用常规的神经网络来进行图像分析,但在实际操作中,从计算角度看,使用这种方法的成本非常高。举例来说,一个常规的神经网络,就算是处理一个非常小的图像,假设是30*30像素图像,仍需要900个数据输入和五十多万个参数。这样的处理加工对一个相对强大的机器来说还是可行的;但是,如果需要处理更大的图像,假设是500*500像素的图像,那么机器所需的数据输入和参数数量就会大大增加,增加到难以想象的地步。
除此之外,将神经网络用于“图像识别”还可能会导致另一个问题——过度拟合。简单来说,过度拟合指的是系统训练的数据过于接近定制的数据模型的现象。这不仅会在大体上导致参数数量的增加(也就是进一步计算支出的增加),还将削弱“图像识别”在面临新数据时其他常规功能的正常发挥。
真正的解决方案——卷积
幸运的是,我们发现,只要在神经网络的结构方式上做一个小小的改变,就能使大图像的处理更具可操作性。改造后的神经网络被称作“卷积神经网络”,也叫CNNs或ConvNets。
神经网络的优势之一在于它的普遍适应性。但是,就像我们刚刚看到的,神经网络的这一优势在图像处理上实际上是一种不利因素。而“卷积神经网络”能够对此作出一种有意识的权衡——为了得到一个更可行的解决方案,我们牺牲了神经网络的其他普遍性功能,设计出了一个专门用于图像处理的网络。
在任何一张图像中,接近度与相似度的关联性都是非常强的。准确地说,“卷积神经网络”就是利用了这一原理。具体而言就是,在一张图像中的两个相邻像素,比图像中两个分开的像素更具有关联性。但是,在一个常规的神经网络中,每个像素都被连接到了单独的神经元。这样一来,计算负担自然加重了,而加重的计算负担实际上是在削弱网络的准确程度。
卷积网络通过削减许多不必要的连接来解决这一问题。运用科技术语来说就是,“卷积网络”按照关联程度筛选不必要的连接,进而使图像处理过程在计算上更具有可操作性。“卷积网络”有意地限制了连接,让一个神经元只接受来自之前图层的小分段的输入(假设是3×3或5×5像素),避免了过重的计算负担。因此,每一个神经元只需要负责处理图像的一小部分(这与我们人类大脑皮质层的工作原理十分相似——大脑中的每一个神经元只需要回应整体视觉领域中的一小部分)。
“卷积神经网络”的内在秘密
“卷积神经网络”究竟是如何筛选出不必要的连接的呢?秘密就在于两个新添的新型图层——卷积层和汇聚层。我们接下来将会通过一个实操案例:让网络判断照片中是否有“奶奶”这一对象,把“卷积神经网络”的操作进行分解,逐一描述。
第一步,“卷积层”。“卷积层”本身实际上也包含了几个步骤:
1.首先,我们会将奶奶的照片分解成一些3×3像素的、重叠着的拼接图块。
2.然后,我们把每一个图块运行于一个简单的、单层的神经网络,保持权衡不变。这一操作会使我们的拼接图块变成一个图组。由于我们一开始就将原始图像分解成了小的图像(在这个案例中,我们是将其分解成了3×3像素的图像),所以,用于图像处理的神经网络也是比较好操作的。
3.接下来,我们将会把这些输出值排列在图组中,用数字表示照片中各个区域的内容,数轴分别代表高度、宽度和颜色。那么,我们就得到了每一个图块的三维数值表达。(如果我们讨论的不是奶奶的照片,而是视频,那么我们就会得到一个四维的数值表达了。)
说完“卷积层”,下一步是“汇聚层”。
“汇聚层”是将这个三维(或是四维)图组的空间维度与采样函数结合起来,输出一个仅包含了图像中相对重要的部分的联合数组。这一联合数组不仅能使计算负担最小化,还能有效避免过度拟合的问题。
最后,我们会把从“汇聚层”中得出的采样数组作为常规的、全方位连接的神经网络来使用。通过卷积和汇聚,我们大幅度地缩减了输入的数量,因此,我们这时候得到的数组大小是一个正常普通网络完全能够处理的,不仅如此,这一数组还能保留原始数据中最重要的部分。这最后一步的输出结果将最终显示出系统有多少把握作出“照片中有奶奶”的判断。
以上只是对“卷积神经网络”工作过程的简单描述,现实中,其工作过程是更加复杂的。另外,跟我们这里的案例不同,现实中的“卷积神经网络”处理的内容一般包含了上百个,甚至上千个标签。
“卷积神经网络”的实施
重新开始建立一个“卷积神经网络”是一项非常耗时且昂贵的工作。不过,许多API最近已经实现了——让组织在没有内部计算机视觉或机器学习专家的帮助下,完成图像分析的收集工作。
“谷歌云视觉”是谷歌的视觉识别API,它是以开源式TensorFlow框架为基础的,采用了一个REST API。“谷歌云视觉”包含了一组相当全面的标签,能够检测单个的对象和人脸。除此之外,它还具备一些附加功能,包括OCR和“谷歌图像搜索”。
“IBM沃森视觉识别”技术是“沃森云开发者”的重要组成部分。它虽然涵盖了大量的内置类集,但实际上,它是根据你所提供的图像来进行定制类集的训练的。与“谷歌云视觉”一样,“IBM沃森视觉识别”也具备许多极好的功能,比如OCR和NSFW检测功能。
Clarif.ai是图像识别服务的“后起之秀”,它采用了一个REST API。值得一提的是,Clarif.ai包含了大量的单元,能够根据特定的情境定制不同的算法。像婚礼、旅游甚至食物。
上面的这些API更适用于一些普通的程序,但对于一些特殊的任务,可能还是需要“对症下药”,制定专门的解决方案。不过值得庆幸的是,许多数据库可以处理计算和优化方面的工作,这或多或少地减轻了数据科学家和开发人员的压力,让他们有更多精力关注于模型训练。其中,大部分的数据库,包括TensorFlow,深度学习4J和Theano,都已经得到了广泛、成功的应用。
-
图像识别
+关注
关注
8文章
447浏览量
37913
发布评论请先 登录
相关推荐
基于DSP的快速纸币图像识别技术研究
【HarmonyOS HiSpark AI Camera】渔业卫士-基于图像识别的多自由度水下机器人
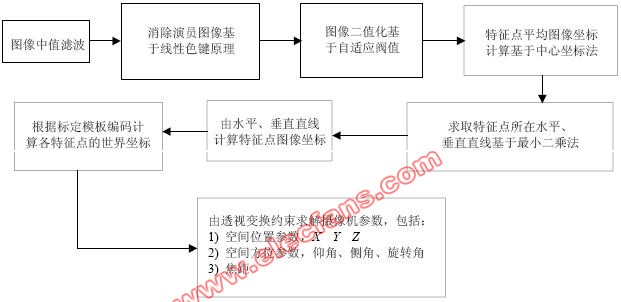
基于图像识别的摄像机参数求解原理
对于图像识别的引入、原理、过程、应用前景的深度剖析
卷积神经网络用于图像识别的原理
模拟矩阵在图像识别中的应用






 工商网监
工商网监
评论