 打破英伟达CUDA壁垒?AMD显卡现在也能无缝适配CUDA了
打破英伟达CUDA壁垒?AMD显卡现在也能无缝适配CUDA了

电子发烧友网报道(文/梁浩斌)一直以来,围绕CUDA打造的软件生态,是英伟达在GPU领域最大的护城河,尤其是随着目前AI领域的发展加速,市场火爆,英伟达GPU+CUDA的开发生态则更加稳固,AMD、英特尔等厂商虽然在努力追赶,但目前还未能看到有威胁英伟达地位的可能。
最近一家英国公司Spectral Compute推出了一款方案,可以为AMD的GPU原生编译CUDA源代码,目前正在RNDA2、RDNA3上进行规模测试。这或许可以打破CUDA与英伟达GPU的生态壁垒?
SCALE编译器
Spectral Compute据称花了7年时间开发SCALE,SCALE不依赖英伟达的代码,而是通过一些开源LLVM组件等,建立了其CUDA兼容的工具链,让SCALE在多个平台之间能高度兼容。
其实在以往也有一些其他GPU硬件兼容CUDA的方式,比如AMD支持的ZLUDA推出的开源移植项目,通过重新编译二进制代码,就能够让CUDA库在AMD自家的ROCm上运行,令AMD GPU适配CUDA生态。
但SCALE的特性在于,可以避免代码移植的步骤,开发人员可以使用单一版本的代码库,因为SCALE本身与CUDA的源代码兼容,这大大提高了可用性。
Spectral Compute的CEO Michael Sondergaard表示:我们相信,只需要编写一次代码,就可以在任何硬件平台上运行它,对于CPU代码来说,这已经实现很多年了,那为什么GPU不行呢?我们着手通过弥合主流的CUDA编程语言和其他GPU硬件供应商之间的兼容性差距,来直接解决这个问题。
Michael 还提到:“应该构建一个围绕GPU的开源生态系统,类似目前CPU所享有的生态环境,同时确保不同平台间的互联互通。”他认为,通过SCALE可以弥合CUDA与其他硬件供应商之间的兼容性鸿沟,从而打破市场上存在的壁垒。
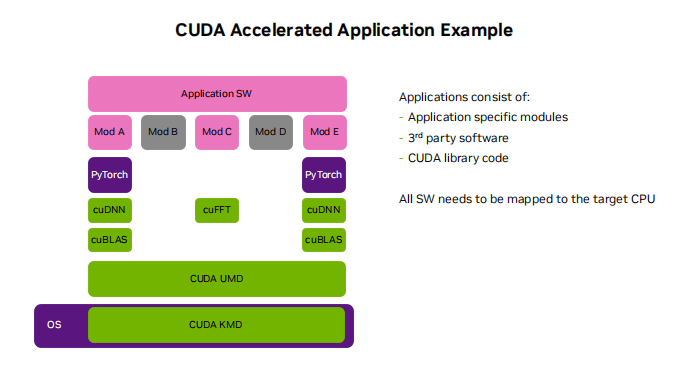
据介绍,SCALE是一种通用并行GPU工具包,其功能与英伟达的CUDA工具包相仿,它能够在编译CUDA代码的同时,为非英伟达 GPU生成相应的二进制文件,这样就彻底避免了对翻译层的依赖。
目前,SCALE已经在多种软件中成功运行,比如Blender、Llama-cpp、XGboost、FAISS、GOMC、STDGPU、Hashcat和NVIDIA Thrust等专业软件,这些软件已经可以在RDNA2和RDNA3的AMD GPU上正常使用CUDA。
不过SCALE本身不是开源的,但用户可以通过免费的软件许可使用这个功能,这或许是为了规避英伟达针对CUDA兼容而出台的EULA条款。
其他厂商兼容CUDA的努力
市场上其实并不缺乏CUDA的挑战者,包括AMD的ROCm,开放标准联盟Khronos Group联合旗下成员打造出的SYCL编程语言等,而英特尔也与SYCL深度绑定,希望打破CUDA的统治。
当然,对于AMD和英特尔这样的巨头而言,他们有资本去尝试构建一个新的生态,但对于更多的初创公司和中小规模公司而言,兼容就是成本最低的路线。
比如国内的GPU初创公司摩尔线程,基于MUSA的统一架构推出了多款GPU产品,并打造了软件开发平台,包括AI开发平台、MUSA SDK、MT Smart Media和MTVerse XR等。
而这套生态架构可以充分兼容现有的软件生态,能借助MUSIFY工具实现代码零成本迁移到MUSA平台,也包括对CUDA生态的兼容。
在2021年的时候,在一个名为Vortex的RISC-V GPU项目上,也实现了对CUDA软件工具包的支持。
在这个项目中,研究人员设计并实现了一条流水线,旨在全面支持从CUDA到增强版RISC-V GPU架构的代码迁移。这条流水线以CUDA源代码为起点,目标是在强化的RISC-V GPU架构上直接运行这些代码。具体而言,流水线分为以下几步:首先将CUDA源代码转换为NVVM中间表示(IR),接着把NVVM IR转化为SPIR-V IR,随后利用POCL将SPIR-V IR转译成针对RISC-V的二进制文件,最终在增强后的RISC-V GPU上执行这些二进制文件。
写在最后
尽管CUDA生态目前是英伟达GPU的最大优势之一,但从这些厂商的努力可以看到,其他GPU硬件也正在有越来越多的方法兼容CUDA,有机会从英伟达手中夺得一些市场份额。但AI领域的龙头效应越来越强,能够挑战英伟达的GPU厂商可能机会越来越小了。
-
amd
+关注
关注
25文章
5729浏览量
140747 -
显卡
+关注
关注
17文章
2526浏览量
71853 -
CUDA
+关注
关注
0文章
128浏览量
14591 -
英伟达
+关注
关注
23文章
4142浏览量
99856
发布评论请先 登录
RV生态又一里程碑:英伟达官宣CUDA将兼容RISC-V架构!
国产GPU再下一城,群起突围英伟达+AMD
台积电晶圆厂采用英伟达CUDA-X 光刻环节效率提升
英伟达发布RTX Spark超级芯片
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
如何在NVIDIA CUDA Tile中编写高性能矩阵乘法


NVIDIA CUDA Tile的创新之处、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile简化GPU编程

NVIDIA CUDA 13.1版本的新增功能与改进
首款全国产训推一体AI芯片发布,兼容CUDA生态

打破智能家居生态壁垒,乐鑫一站式Matter解决方案实现无缝互联




评论