 盘点国产GPU在支持大模型应用方面的进展
盘点国产GPU在支持大模型应用方面的进展

电子发烧友网报道(文/李弯弯)目前谈到GPU,大家首先想到的应该就是英伟达了。近一年多时间来,随着大模型的发展,英伟达GPU的强大实力可谓无人不知。而相比之下,国产GPU的声势就小了许多。事实上,近些年国内也有不少GPU企业在逐步成长,虽然在大模型的训练和推理方面,与英伟达GPU差距极大,但是不可忽视的是,不少国产GPU企业也在AI的训练和推理应用上找到位置。
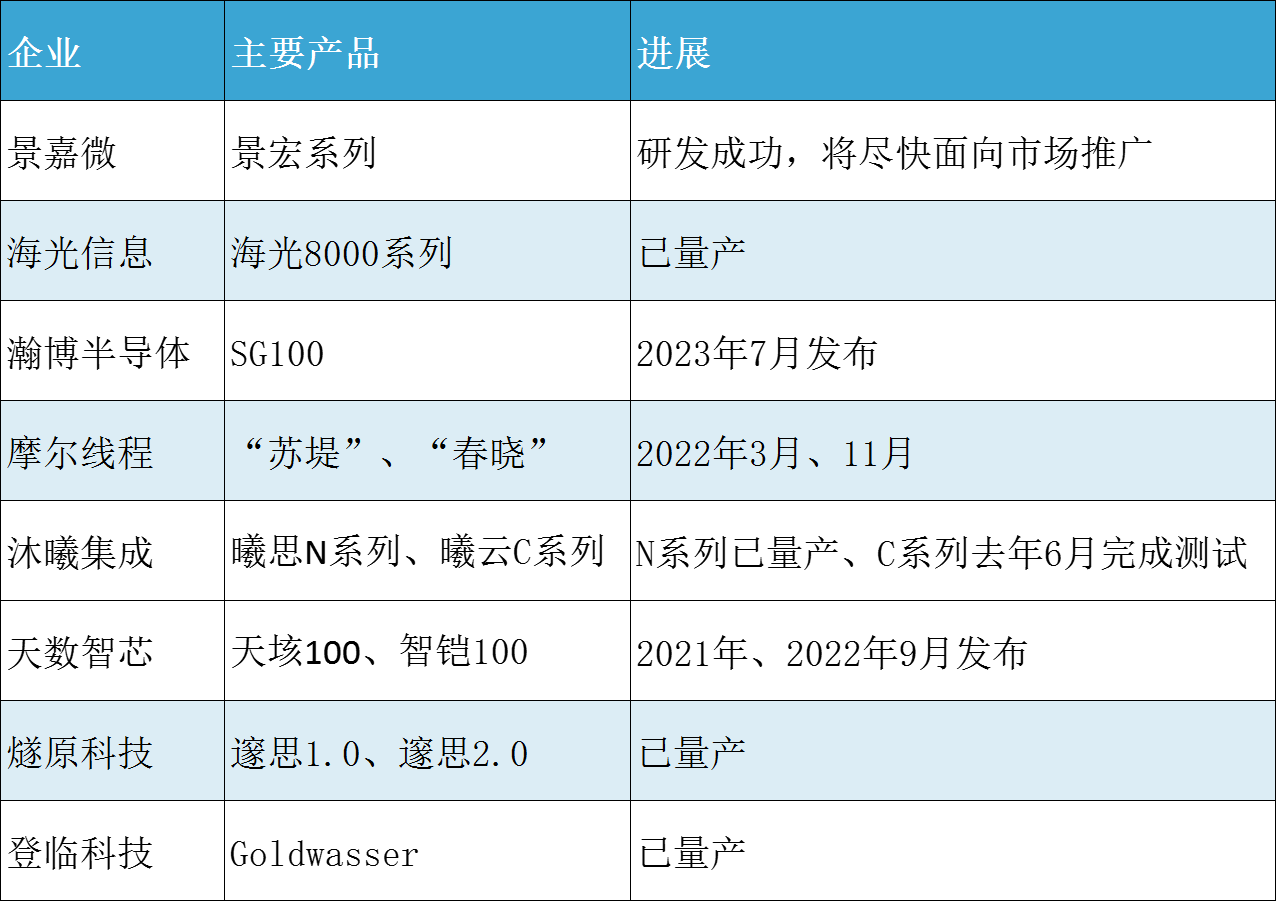
景嘉微
景嘉微是国产GPU市场的主要参与者,目前已经完成JM5、JM7和JM9系列三代图形处理芯片的研发,并成功实现产业化。
2024年3月12日,该公司发布公告称,其面向AI 训练、AI推理、科学计算等应用领域的景宏系列高性能智算模块及整机产品研发成功,并将尽快面向市场推广。
根据公告,景宏系列支持INT8、FP16、FP32、FP64等混合精度运算,支持全新的多卡互联技术进行算力扩展,适配国内外主流CPU、操作系统及服务器厂商,能够支持当前主流的计算生态、深度学习框架和算法模型库,大幅缩短用户适配验证周期。
海光信息
海光信息的产品包括海光通用处理器(CPU)和海光协处理器(DCU)。海光DCU属于GPGPU 的一种,采用“类CUDA”通用并行计算架构,能够较好地适配、适应国际主流商业计算软件和人工智能软件。
海光8000系列具有全精度浮点数据和各种常见整型数据计算能力,具有最多64个计算单元,能够充分挖掘应用的并行性,发挥其大规模并行计算的能力,快速开发高能效的应用程序。
海光DCU主要部署在服务器集群或数据中心,为应用程序提供性能高、能效比高的算力,支撑高复杂度和高吞吐量的数据处理任务。在AIGC持续快速发展的时代背景下,海光DCU 能够完整支持大模型训练,实现LLaMa、GPT、Bloom、ChatGLM、悟道、紫东太初等为代表的大模型的全面应用,与国内包括文心一言等大模型全面适配,达到国内领先水平。
瀚博半导体
瀚博半导体成立于2018年12月,是一家GPU芯片提供商,致力于为人工智能核心算力和图形渲染、内容生成、AIGC提供全栈式芯片解决方案。瀚博目前拥有自主研发的核心IP以及两代GPU芯片,并衍生AI、渲染、视频三大产品线。
据介绍,其2023年推出的第二代GPU SG100芯片,采用7nm先进制程,具备业界一流的渲染性能,同时兼具低延时高吞吐的AI算力和强大的视频处理能力,可广泛支持数字孪生、数字人、云桌面、云手机、云游戏、云渲染、工业软件等多领域应用。
同时针对大模型时代算力需求,瀚博还首发了LLM大模型AI加速卡VA1L,具备200 TOPS INT8/72 TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC网络模型。同时,瀚博更重磅推出AIGC大模型一体机,共使用8张LLM大模型AI加速卡VA1L,支持512GB显存,进而支持1750亿参数的大模型。
摩尔线程
摩尔线程成立于2020年10月,是一家以全功能GPU芯片设计为主的集成电路公司。该公司已经发布两款自主研发的GPU芯片产品,2022年3月发布GPU产品“苏堤”,11月又发布了第二款GPU芯片“春晓”。
“春晓”内置MUSA架构通用计算核心以及张量计算核心,可支持FP32、FP16和INT8三种计算精度;相较于其首款自研的GPU“苏堤”,“春晓”内置的四大计算引擎都进行了全面升级,性能显著提升,AI计算加速平均提升4倍。
沐曦集成
沐曦成立于2020年9月,致力于为异构计算提供全栈GPU芯片及解决方案,可广泛应用于智算、智慧城市、云计算、自动驾驶、数字孪生、元宇宙等前沿领域。
沐曦集成目前有三条产品线规划,曦思N系列GPU产品用于智算推理,曦云C系列GPU产品用于通用计算,曦彩G系列GPU产品用于图形渲染。据沐曦此前对外透露,公司N系列云端推理芯片已经量产出货,C系列于2023年6月13日回片并完成测试。
沐曦产品均采用完全自主研发的GPU IP,拥有完全自主知识产权的指令集和架构,配以兼容主流GPU生态的完整软件栈(MXMACA),具备高能效和高通用性的天然优势,能够为客户构建软硬件一体的全面生态解决方案。
天数智芯
天数智芯致力于开发自主可控、国际领先的高性能通用GPU产品,探索通用GPU赶超发展道路,加快建设自主产业生态,为全产业提供高端算力解决方案。
天数智芯2018年正式启动通用GPU芯片设计,在2021年发布了其通用GPU“天垓100”芯片及天垓100加速卡,2021年10月宣布天垓100正式进入量产环节。2022年9月,又发布了首款7nm制程的云端推理通用GPU产品“智铠100”。
智铠 100 芯片支持 FP32、FP16、INT8 等多精度混合计算,实现了指令集增强、算力密度提升、计算存储再平衡,支持多种视频规格解码。
燧原科技
燧原科技专注人工智能领域云端和边缘算力产品,致力为通用人工智能打造算力底座,提供原始创新、具备自主知识产权的AI加速卡、系统集群和软硬件解决方案。产品可广泛应用于泛互联网、智算中心、智慧城市,智慧金融、科学计算、自动驾驶等多个行业和场景。
该公司于2018年3月成立,仅用18个月时间,即发布第一代AI芯片邃思1.0,又于2021年7月发布邃思2.0。到现在,该公司已经在两款芯片的基础上迭代了两代训练和推理产品,第三代产品也已经在研发中。并且,燧原科技已经在科研领域和智慧城市的应用中落地了训练和推理的超千卡算力集群。
登临科技
登临科技专注于芯片研发与技术创新,致力于打造云边端一体、软硬件协同的前沿芯片产品和平台化基础系统软件。公司自主创新的GPU+(基于GPGPU的软件定义的片内异构计算架构),在兼容CUDA/OpenCL在内的编程模型和软件生态的基础上,通过架构创新,完美解决了通用性和高效率的双重难题。
登临首款基于GPU+的创新AI计算加速器Goldwasser已规模化运用在各个应用场景。未来将继续秉承核心IP全自研的架构实现,以AI计算为主线,以创新为灵魂,加强核心IP自主研发,加速产品在高级自动驾驶,图形加速等相关领域的开拓创新和商业化进程。
写在最后
GPU最初是为解决CPU在图形处理领域性能不足的问题而诞生的,早期它多用于图形处理,而如今大家谈到用于AI训练和推理多是通用计算GPGPU,它脱胎于早期的图形处理器。
上述谈到的GPU企业,有些既有用于AI计算的GPU产品,也有用于图形处理的产品,如景嘉微,是国内较早入局GPU市场的企业,之前已经发布过多个系列的产品,主要用于图形处理。近期才公布面向AI 训练、AI推理、科学计算等应用领域的GPU产品研发成功。
如沐曦入局GPU市场较晚,像用于AI训练、推理的产品,以及用于图形渲染的产品都有规划,不过它是先推出了用于AI计算的GPU芯片,而用于图形渲染的产品预计要到2025年才发布。像瀚博半导体、摩尔线程等也是面向图形渲染和AI计算都有产品。
面对现在关注比较多的大模型的训练和推理,国产GPU企业也在积极跟进,如海光DCU就能够完整支持大模型训练,实现LLaMa、GPT、Bloom、ChatGLM、悟道、紫东太初等为代表的大模型的全面应用;瀚博基于新一代GPU芯片首发了LLM大模型AI加速卡VA1L,能支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC网络模型。天数智芯、燧原科技等也都在支持大模型的应用上取得进展。
-
gpu
+关注
关注
28文章
5272浏览量
136073 -
大模型
+关注
关注
2文章
3773浏览量
5273
发布评论请先 登录
国产来袭!2nm AI GPU?
壁仞科技壁砺166系列GPU产品率先支持Kimi K2.6模型

沐曦股份曦云C系列GPU产品Day 0适配百度文心ERNIE-Image文生图模型
Day-0支持|摩尔线程率先完成MiniMax M2.7大模型适配

沐曦股份曦云C系列GPU产品Day 0适配智谱GLM-5.1旗舰模型
Neway电机方案在机器人技术方面的优势
成都汇阳投资关于国产开源模型持续突破,国产AI 竞争力增强
首款全国产通用GPU芯片发布 沐曦集成推出曦云C600
别让 GPU 故障拖后腿,捷智算GPU维修室来救场!

沐曦MXMACA软件平台在大模型训练方面的优化效果

为什么无法在GPU上使用INT8 和 INT4量化模型获得输出?
Imagination与澎峰科技携手推动GPU+AI解决方案,共拓计算生态
Imagination与澎峰科技携手推动GPU+AI解决方案,共拓计算生态




评论