 联发科联手英伟达挑战高通与AMD,游戏、3纳米和大模型
联发科联手英伟达挑战高通与AMD,游戏、3纳米和大模型

2023年5月,联发科与英伟达宣布合作,共同研发车载芯片,原本计划是采用Chiplet形式。
2024年3月,联发科正式发布新一代Dimensity Auto 座舱平台,最大亮点是英伟达RTX GPU IP的加入和台积电3纳米的制造工艺。台积电3纳米制造工艺是目前芯片行业最先进的制造工艺,这是汽车芯片第一次与手机和AI芯片同时使用最先进的制造工艺,但不是Chiplet,推测一来是3纳米的Chiplet制造工艺不够成熟,二就是Chiplet需要动用台积电先进封装,成本并不比单一die低,甚至可能高2-3倍,汽车行业对价格还是相对比较敏感的。
联发科是一家非常低调的公司,品牌形象营造远不如高通,也极少对外透露信息。
联发科一直被高通挤压,特别是在GPU和AI方面,联发科引入英伟达的GPU IP来弥补这一短板。
从联发科官方介绍中,我们不难看出联发科使用的英伟达GPU IP是何种类型的IP,因为DLSS3是RTX40系列独有的功能,也就是说联发科使用了英伟达RTX40系列桌面显卡的IP。
简单介绍一下DLSS3

图片来源:英伟达
DLSS全称Deep Learning Super Sampling(深度学习超采样),主要包括DLAA、插帧和光线重建。插帧即帧生成,它可以生成全新帧,而不仅是像素,从而带来惊人的性能提升。基于NVIDIA Ada Lovelace架构的新光流加速器可分析两帧连续的游戏图像,并计算帧到帧中物体和元素的运动矢量数据,而不使用传统游戏引擎的运动矢量进行建模。这极大地减少了AI在渲染诸如粒子、反射、阴影和光照等元素时的视觉异常。
通过综合游戏中的一对超级分辨率帧,以及引擎和光流运动矢量,并将其输入至卷积神经网络,就能计算生成出新的一帧,这在实时游戏渲染中是首次实现。将DLSS生成的全新帧与DLSS超级分辨率帧相结合,使DLSS 3能用AI重建八分之七的显示像素,与没有DLSS相比,游戏性能提升了4倍。
由于DLSS生成帧在GPU上作为后处理执行,即使游戏受到CPU性能限制,也能从中获得游戏性能提升。对于受到CPU限制的游戏,例如物理计算密集型游戏或大型场景游戏,DLSS 3令GeForce RTX 40系列GPU以高达两倍于CPU可计算的性能渲染游戏。
DLSS 3集成也包括NVIDIA Reflex,可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。
DLSS3的插帧技术目前还是英伟达独有,AMD和英特尔没有,也就是说如果用联发科的芯片运行《赛博朋克2077》这样的硬件杀手游戏,效果或可以碾压特斯拉座舱的AMD 分离式GPU。
RTX40系列也有多个版本,最低的是笔记本电脑用的GTX4050,AD107架构,2560个CUDA,联发科最大可能用这个架构。RTX4050的稀疏INT8算力估计有104TOPS,将来联发科的旗舰芯片或许AI算力大约就是100TOPS,当然了功耗会有25-35瓦以上,水冷恐怕不可避免。
另一大特色就是3纳米工艺,据称目前苹果和联发科已经包下了台积电全部的3纳米产能,高通拿不到台积电的3纳米产能了,高通打算使用三星的3纳米。众所周知,三星与台积电差距还是很大的。制造工艺上,联发科与同在台湾省内的台积电合作更加顺利,联发科的手机芯片也拿到了4纳米首发,领先了高通一步,3纳米上基本也可以确定,联发科也是首发。台积电第一代3nm工艺是N3B,由台积电的大客户苹果率先使用,A17 Pro、M3系列芯片等都是使用的台积电第一代3nm工艺制程。台积电第二代3nm工艺是N3E,N3E预计将比N3B应用更广泛,除了前面提到的联发科天玑9400芯片外,高通骁龙8 Gen4、A18系列芯片也原本计划采用N3E工艺。台积电N3E是N3B的增强版,良率更高,成本更低,但密度会略低于N3B。
联发科这次也是和高通一样,手机芯片与车载芯片同步,都采用最先进的3纳米制造工艺,考虑到3纳米高达数亿美元的惊人的一次性流片成本,联发科的手机和车载芯片应该有共通之处。
2023年9月,联发科宣布首款使用台积电3纳米工艺的芯片即将在2024年量产,这就是联发科新旗舰天玑9400。
天玑9300开始使用全大核设计,晶体管数量高达227亿,比英伟达自动驾驶Orin的170亿还要多很多。天玑9300的227亿晶体管,是真正的遥遥领先:苹果A16是160亿,A17 Pro是190亿,苹果M2是200亿。即便是苹果M3,也“仅”有250亿晶体管,而高通好几代没公布晶体管数目了。历史性的取消小核,CPU由4颗X4超大核和4颗A720大核组成,最高频的X4有更大的缓存。跳出安卓SoC的视角看,天玑9300的4颗超大核和4颗大核,其实更接近于苹果A系列和英特尔的P核(性能核)、E核(能效核)概念。
天玑首发LPDDR5T 9600Mbps内存,速度比之前的LPDDR5x 8533Mbps提升12.5%,这是大家以为要等LPDDR6才能达到的频率(2年前的天玑9000是首发LPDDR 5x 7500Mbps内存,天玑9200是首发LPDDR5x 8533Mbps)。
天玑9400采用ARM旗舰Cortex-x5(下图TCS24就是Cortex-x5,代号黑鹰),这是ARM最强CPU架构。
ARM的路线图
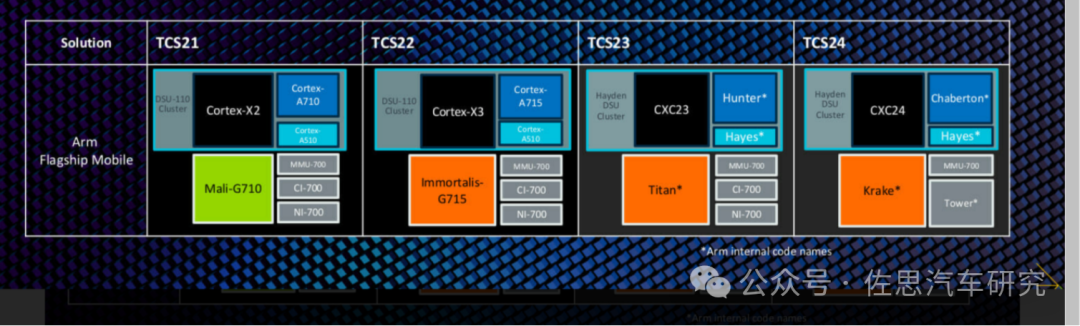
图片来源:ARM
Cortex-x5据说将消除Arm设计的CPU内核与苹果基于Arm指令集自研的CPU内核之间的性能差距。Moor Insights & Strategy CEO Patrick Moorhead指出,ARM全新的Cortex-X系列CPU内核的内部代号为“Blackhawk”,是ARM CEO Rene Haas接下来的工作重点之一,旨在消除Arm设计的CPU内核与苹果基于Arm指令集自研的CPU内核之间的性能差距。Moorhead引用ARM说法表示,“Blackhawk”核心将会带来巨大的性能提升,是五年来同比最大的IPC性能提升。
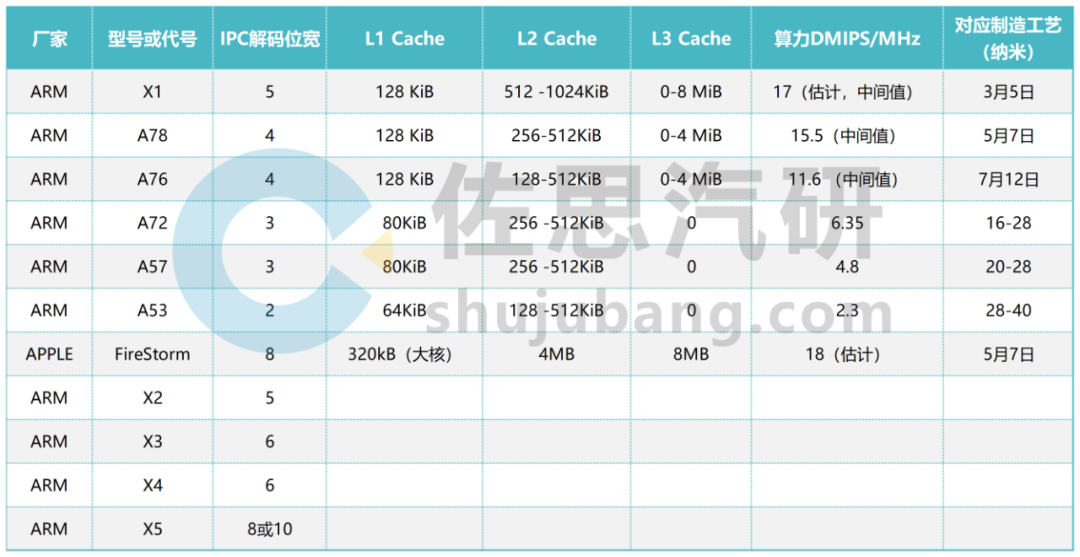
整理:佐思汽研
多年来ARM一直在挤牙膏,IPC带宽从2位,缓慢上升,而苹果一开始就到巅峰的8位,导致安卓性能远低于苹果,X5可能追平苹果的8位解码宽度,也可能直接到10位,超过苹果。
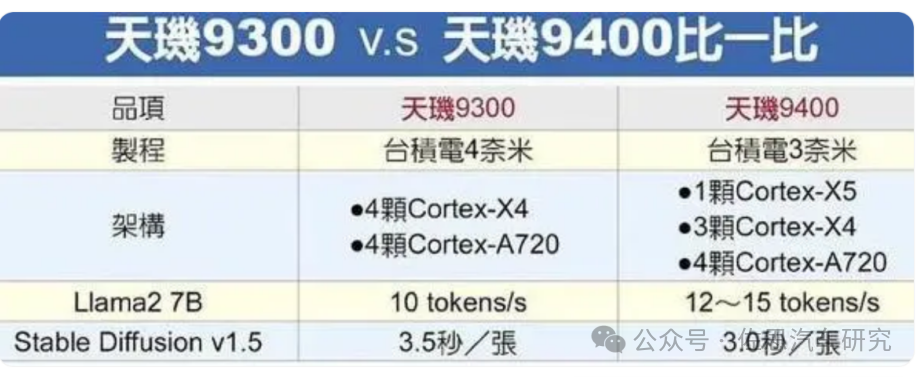
图片来源:联发科
很多人以为AI运算和CPU没关系,或者说CPU无法做AI运算,实际上CPU完全可以做任何类型的AI运算,只是数据吞吐能力不如GPU或AI加速器,抛开数据吞吐,单纯AI运算,CPU是最快的。ARM最新的CPU如Cortex-X3/X4/X5,都能够运行大模型,目前手机领域或者说移动领域大模型最常见的是LIama2,这是目前最好的语言类开源大模型。天玑9400可以做到每秒12-15 tokens。
简单介绍一下LIama2,Meta 出品的 Llama 续作 Llama2,一系列模型(7B、13B、70B)均开源可免费商用。Llama2在各个榜单上精度全面超过Llama1,同时也超过目前所有开源模型。用于车载和手机的70亿参数的相对较小的模型。
尽管语言类大模型LLM训练方法很直观:基于自回归的transformer模型,在大量预料上做自监督训练,然后通过人类反馈强化学习 (RLHF) 等技术来与人类偏好对齐。但高计算需求限制了LLM 只能由少数玩家来推动发展。现有的开源大模型,例如BLOOM、Llama1、Falcon,虽然都能基本达到匹配非开源大模型(如GPT-3、Chinchilla)的能力,但这些模型都不适合成为非开源产品级LLM (比如ChatGPT、BARD、Claude)的替代品,因为这些封闭的产品级LLM经过大量微调,与人类的偏好保持一致,大大提高了它们的可用性和安全性。这一步在计算和人工标注中需要大量的成本,而且往往不透明或容易重现,限制了社区的进步,以促进AI对齐研究。
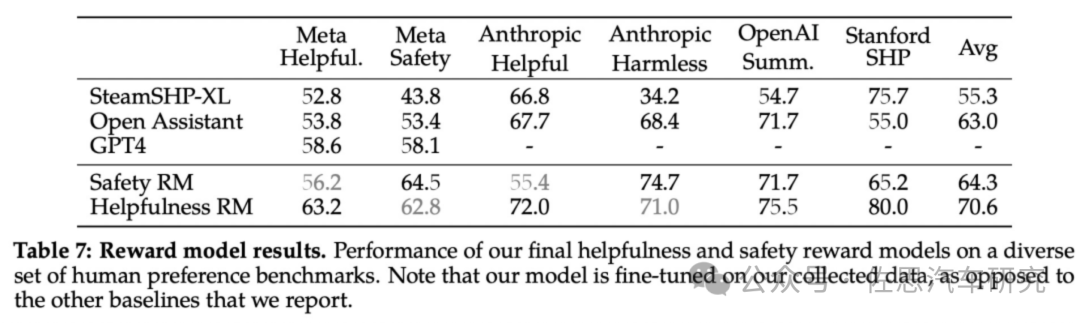
图片来源:网络
Meta自己的奖励模型在基于Llama 2-Chat收集的内部测试集上表现最佳,其中「有用性」奖励模型在「元有用性」测试集上表现最佳,同样,「安全性」奖励模型在「元安全性」测试集上表现最佳。总体而言,Meta的奖励模型优于包括GPT-4在内的所有基线模型。有趣的是,尽管GPT-4 没有经过直接训练,也没有专门针对这一奖励建模任务,但它的表现却优于其他非元奖励模型。
审核编辑:刘清
-
联发科
+关注
关注
57文章
2750浏览量
259884 -
加速器
+关注
关注
2文章
841浏览量
40244 -
英伟达
+关注
关注
23文章
4116浏览量
99634 -
车载芯片
+关注
关注
0文章
84浏览量
15252 -
chiplet
+关注
关注
6文章
499浏览量
13650
原文标题:联发科联手英伟达挑战高通与AMD,游戏、3纳米和大模型
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
2nm“诸神之战”打响!性能飙升+功耗骤降,台积电携联发科领跑

遭强势回应!联发科起诉华为

英伟达+联发科,打入游戏本市场?
MWC2026:6G狂飙!华为、高通、英伟达等五大巨头,亮出哪些突破性技术


安卓主板定制_MTK联发科安卓系统主板PCBA方案开发

【实测分享】智能显示模块图片乱码 / 模糊?用联发科 MTK 芯片方案避坑!
英伟达 Q3 狂揽 308 亿
NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
看点:台积电2纳米N2制程吸引超15家客户 英伟达拟向OpenAI投资1000亿美元
英伟达下一代Rubin芯片已流片
定制安卓主板_联发科|高通|紫光展锐安卓主板方案

从游戏到智能驾驶,英伟达有哪些技术升级?

一加宣布与联发科技达成战略合作,首发天玑9400旗舰家族新成员9400e




评论