 基于DPU和HADOS-RACE加速Spark 3.x
基于DPU和HADOS-RACE加速Spark 3.x

背景简介
Apache Spark(下文简称Spark)是一种开源集群计算引擎,支持批/流计算、SQL分析、机器学习、图计算等计算范式,以其强大的容错能力、可扩展性、函数式API、多语言支持(SQL、Python、Java、Scala、R)等特性在大数据计算领域被广泛使用。其中,Spark SQL 是 Spark 生态系统中的一个重要组件,它允许用户以结构化数据的方式进行数据处理,提供了强大的查询和分析功能。
随着SSD和万兆网卡普及以及IO技术的提升,CPU计算逐渐成为Spark 作业的瓶颈,而IO瓶颈则逐渐消失。 有以下几个原因,首先,因为 JVM 提供的 CPU 指令级的优化如 SIMD要远远少于其他 Native 语言(如C/C++,Rust)导致基于 JVM 进行 CPU 指令的优化比较困难。其次,NVMe SSD缓存技术和AQE带来的自动优化shuffle极大的减轻了IO延迟。最后,Spark的谓词下推优化跳过了不需要的数据,进一步减少了IO开销。
基于此背景,Databricks(Spark背后的商业公司)在2022年SIGMOD会议上发表论文《Photon: A Fast Query Engine for Lakehouse Systems》,其核心思想是使用C++、向量化执行等技术来执行Spark物理计划,在客户工作负载上获得了平均3倍、最大10倍的性能提升,这证明Spark向量化及本地化是后续值得优化的方向。 Spark3.0(2020年6月发布)开始支持了数据的列式处理,英伟达也提出了利用GPU加速Spark的方案,利用GPU的列式计算和并发能力加速Join、Sort、Aggregate等常见的ETL操作。
DPU(Data Processing Unit) 作为未来计算的三大支柱之一,其设计旨在提供强大的计算能力,以加速各种数据处理任务。DPU的硬件加速能力,尤其在数据计算、数据过滤等计算密集型任务上,为处理海量数据提供了新的可能。通过高度定制和优化的架构,DPU能够在处理大规模数据时显著提升性能,为数据中心提供更高效、快速的计算体验,从而满足现代数据处理需求的挑战。但是目前DPU对Spark生态不能兼容,Spark计算框架无法利用DPU的计算优势。
中科驭数HADOS 异构计算加速软件平台(下文简称HADOS)是一款敏捷异构软件平台,能够为网络、存储、安全、大数据计算等场景进行提速。对于大数据计算场景,HADOS可以认为是一个异构执行库,提供了数据类型、向量数据结构、表达式计算、IO和资源管理等功能。 为了发挥Spark与DPU各自的优势,基于HADOS平台,我们开发了RACE算子卸载引擎,既能够发挥Spark优秀的分布式调度能力又可以发挥DPU的向量化执行能力。
我们通过实验发现,将Spark SQL的计算任务通过RACE卸载到DPU上, 预期可以把原生SparkSQL的单表达式的执行效率提升至9.97倍,TPC-DS单Query提升最高4.56倍。本文将介绍如何基于 DPU和RACE来加速 Spark SQL的查询速度,为大规模数据分析和处理提供更可靠的解决方案。
整体架构
整个解决方案可以参考下图:
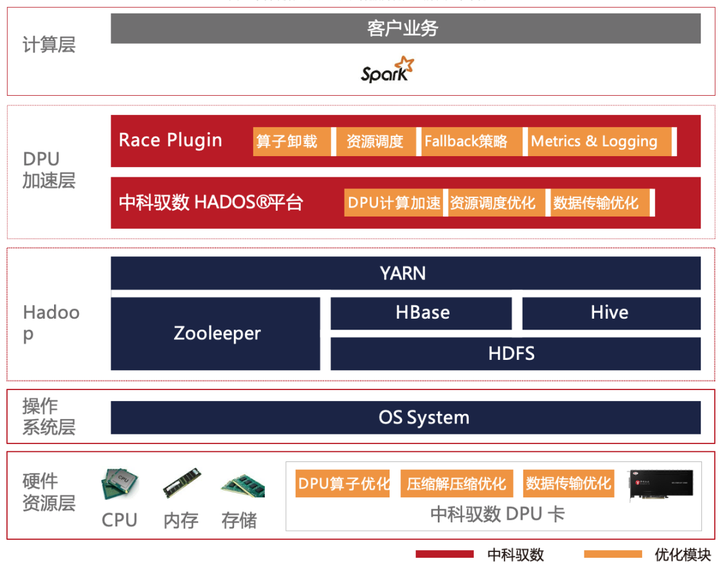
• 最底层硬件资源层是DPU硬件,是面向数据中心的专用处理器,其设计旨在提供强大的计算能力,以加速各种数据处理任务,尤其是优化Spark等大数据框架的执行效率。通过高度定制和优化的架构,DPU能够在处理大规模数据时显著提升性能,为数据中心提供更高效、快速的计算体验。
• DPU加速层底层是HADOS异构计算加速软件平台,是中科驭数推出的专用计算敏捷异构软件开发平台。HADOS数据查询加速库通过提供基于列式数据的查询接口,供数据查询应用。支持Java、Scala、C和C++语言的函数调用,主要包括列数据管理、数据查询运行时函数、任务调度引擎、函数运算代价评估、内存管理、存储管理、硬件管理、DMA引擎、日志引擎等模块,目前对外提供数据管理、查询函数、硬件管理、文件存储相关功能API。
• DPU加速层中的RACE层,其最核心的能力就是修改执行计划树,通过 Spark Plugin 的机制,将Spark 执行计划拦截并下发给 DPU来执行,跳过原生 Spark 不高效的执行路径。整体的执行框架仍沿用 Spark 既有实现,包括消费接口、资源和执行调度、查询计划优化、上下游集成等。
• 最上层是面向用户的原生Spark,用户可以直接使用已有的业务逻辑,无感享受DPU带来的性能提升
目前支持的算子覆盖Spark生产环境常用算子,包括Scan、Filter、Project、Union、Hash Aggregation、Sort、Join、Exchange等。表达式方面,我们开发了目前生产环境常用的布尔函数、Sum/Count/AVG/Max/Min等聚合函数。
其中RACE层的架构如下:
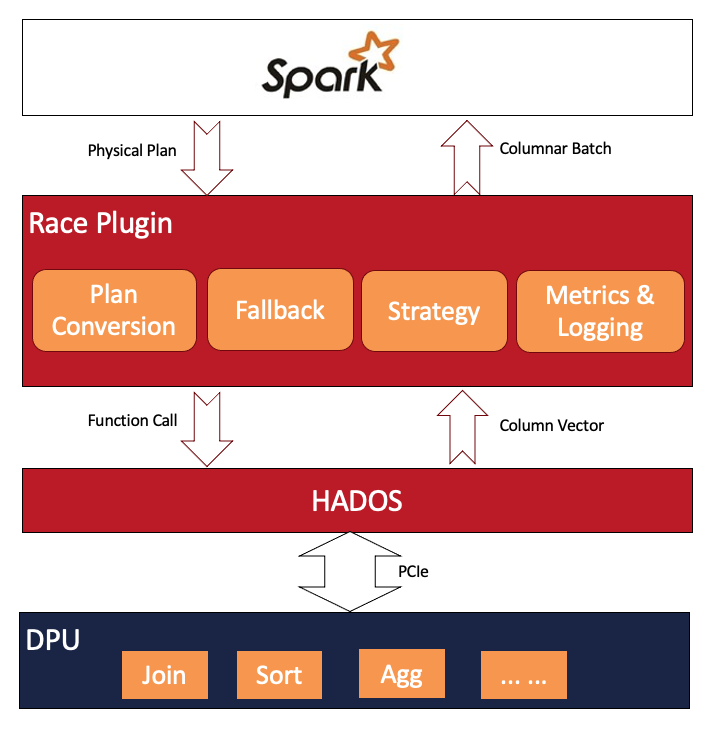
下面我们着重介绍RACE层的核心功能。
核心功能模块
RACE与Spark的集成
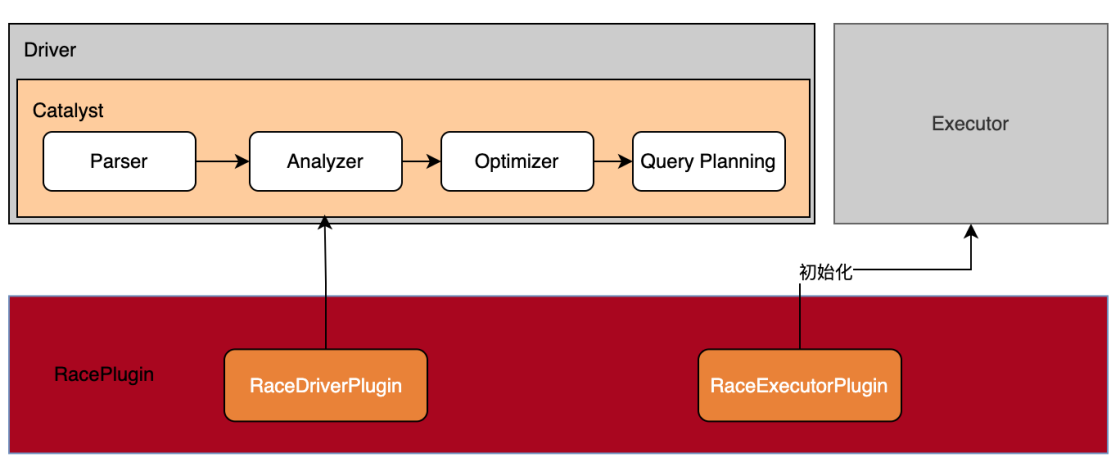
RACE作为Spark的一个插件,实现了SparkPlugin接口,与Spark的集成分为Driver端和Executor端。
• 在Driver端, 通过Spark Catalyst扩展点插入自定义的规则,实现对查询语句解析过程、优化过程以及物理计划转换过程的控制。
• 在Executor端, 插件在Executor的初始化过程中完成DPU设备的初始化工作。
Plan Conversion
Spark SQL在优化 Physical Plan时,会应用一批规则,RACE通过插入的自定义规则可以拦截到优化后的Physical Plan,如果发现当前算子上的所有表达式可以下推给DPU,那么替换Spark原生算子为相应的可以在DPU上执行的自定义算子,由HADOS将其下推给DPU 来执行并返回结果。
Fallback
Spark支持的Operator和Expression非常多,在RACE研发初期,无法 100% 覆盖 Spark 查询执行计划中的算子和表达式,因此 RACE必须有Fallback机制,支持Spark 查询执行计划中部分算子不运行在DPU上。
对于DPU无法执行的算子,RACE安排 Fallback 回正常的 Spark 执行路径进行计算。例如,下图中展示了插件对原生计划树的修改情况,可以下推给DPU的算子都替换成了对应的"Dpu"开头的算子,不能下推的算子仍然保留。除此之外,会自动插入行转列算子或者列转行算子来适配数据格式的变化。
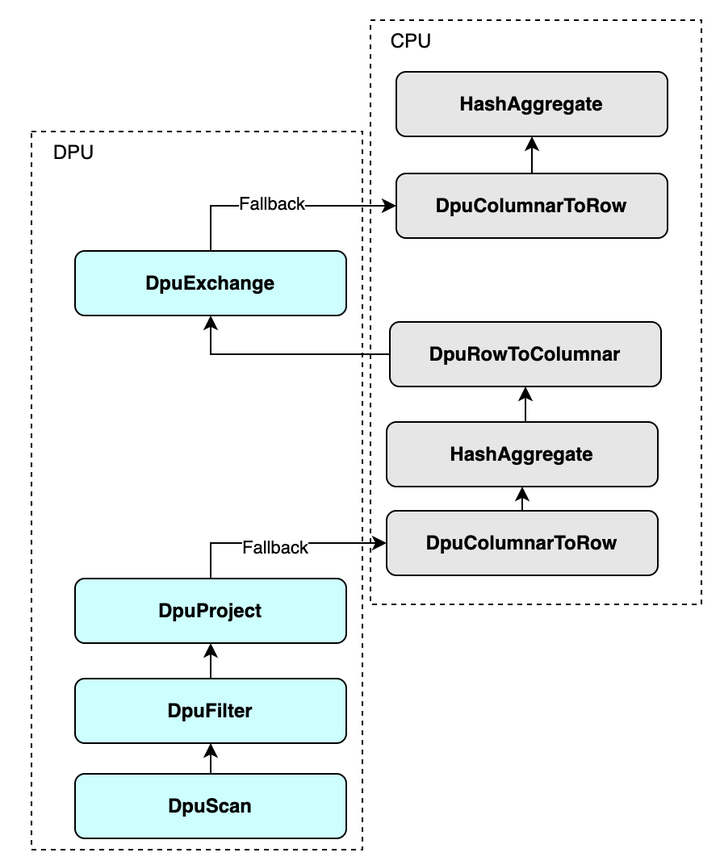
当然了,不管是行转列算子还是列转行算子,都是开销比较大的算子,随着RACE支持的算子和表达式越来越多,Fallback的情况会逐渐减少。
Strategy
当查询计划中存在未卸载的算子时,因为这样引入了行列转换算子,由于其带来了额外的开销,导致即使对于卸载到DPU上的算子,其性能得到提升,而对于整个查询来说,可能会出现比原生Spark更慢的情况。 针对这种情况,最稳妥的方式就是整个Query全部回退到CPU,这至少不会比原生Spark慢,这是很重要的。
由于Spark3.0加入了AQE的支持,规则通常拦截到的是一个个QueryStage,它是Physical Plan的一部分而非完整的 Physical Plan。 RACE的策略是获取AQE规则介入之前的整个Query的 Physical Plan,然后分析该Physical Plan中的算子是否全部可卸载。如果全部可以卸载,则对QueryStage进行Plan Conversion, 如果不能全部卸载,则跳过Plan Conversion转而直接交给Spark处理。
我们在实际测试过程中发现,一些算子例如Take操作,它需要处理的数据量非常小,那么即使发生Fallback,也不会有很大的行列转换开销,通过白名单机制忽略这种算子,防止全部回退到CPU,达到加速目的。
Metrics
RACE会收集DPU执行过程中的指标统计,然后上报给Spark的Metrics System做展示,以方便Debug和系统调优。
Native Read&Write
SparkSQL的Scan算子支持列式读取,但是Spark的向量与DPU中定义的向量不兼容,需要在JVM中进行一次列转行然后拷贝到DPU中,这会造成巨大的IO开销。我们主要有以下优化:
1. 减少行列转换:对于Parquet格式等列式存储格式的文件读取,SparkSQL采用的是按列读取的方式,即Scan算子是列式算子,但是后续数据过滤等数据处理算子均是基于行的算子,SparkSQL必须把列式数据转换为行式数据,这会导致额外的计算开销。而本方案由于都是列式计算的算子,因此无需这种行列转换。
2. 减少内存拷贝: RACE卸载Scan算子到HADOS平台,HADOS平台的DPUScan算子以Native库的方式加载磁盘数据直接复制到DPU,省去了JVM到DPU的拷贝开销
3. 谓词下推支持:DPUScan也支持ColumnPruning规则,这个规则会确保只有真正使用到的字段才会从这个数据源中提取出来。支持两种Filter:PartitionFilters和PushFilters。PartitionFilters可以过滤掉无用的分区, PushFilters把字段直接下推到Parquet文件中去
4. 同时,文件的写出也进行了类似的优化
注意,这些优化仍然需要对数据进行一次复制,DPU直接读取磁盘是一个后续的优化方向。
加速效果
TPC-DS 单Query加速
单机单线程local模式场景,在1T数据集下,TPC-DS语句中有5条语句E2E时间提升比例超过2倍,最高达到4.56倍:
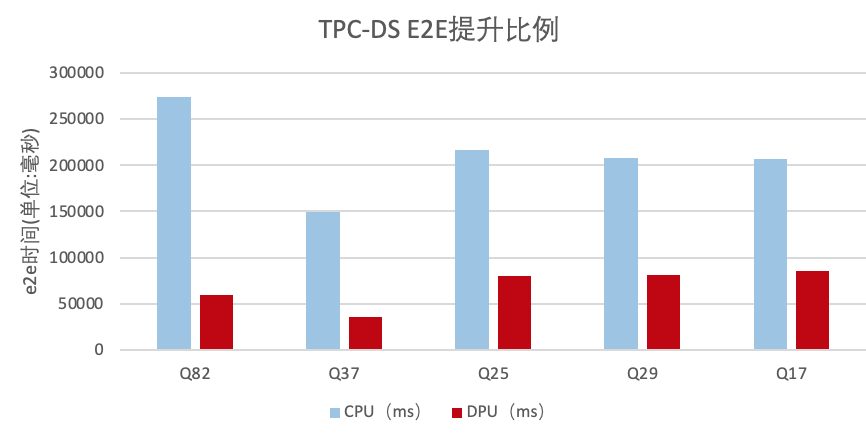
运算符加速效果
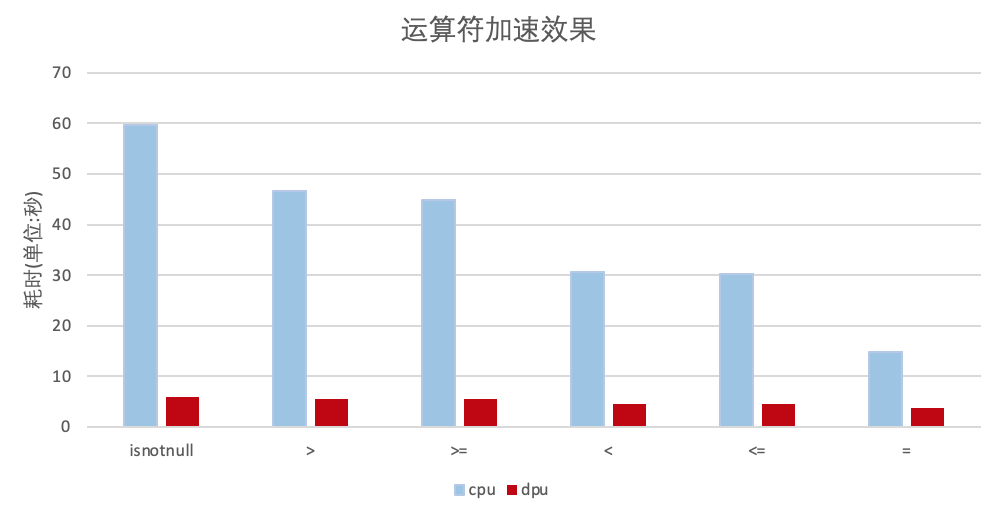
运算符的性能提升,DPU运算符相比Spark原生的运算符的加速比最高达到9.97。
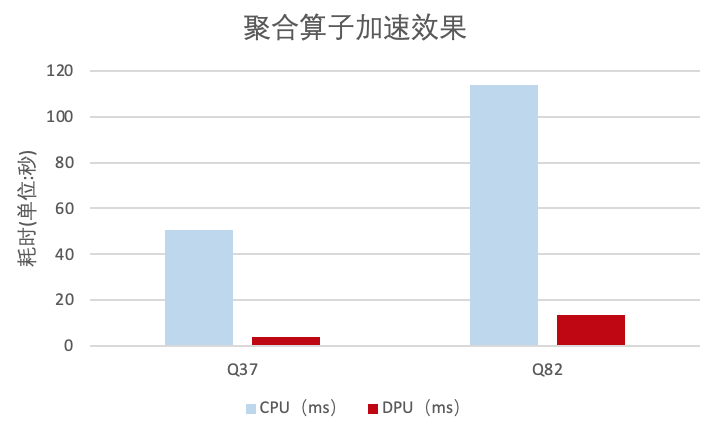
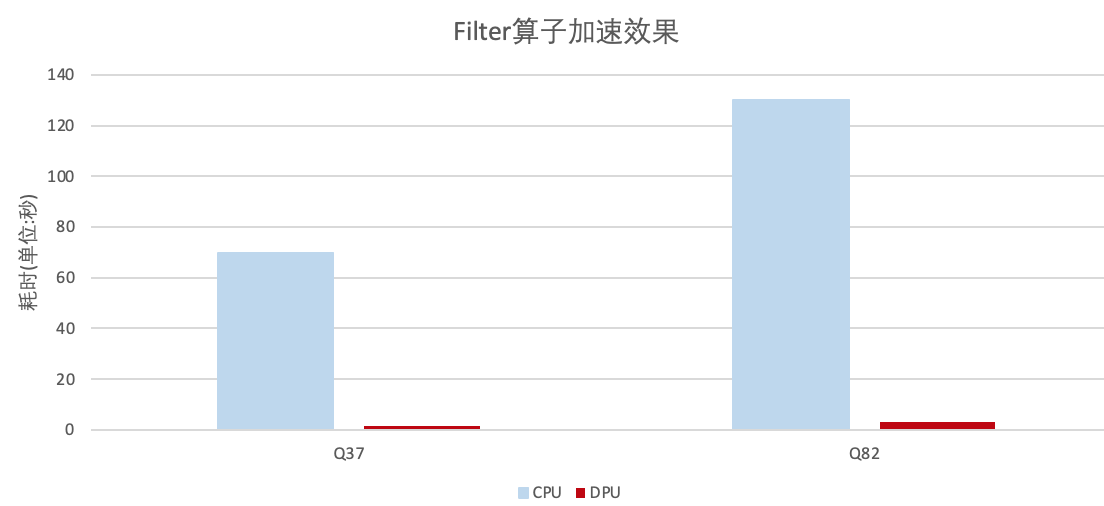
算子加速效果
TPC-DS的测试中,向对于原生Spark解决方案,本方案Filter算子性能最高提高到了43倍,哈希聚合算子提升了13倍。这主要是因为我们节省了列式数据转换为行式数据的开销以及DPU运算的加速。
CPU资源使用情况
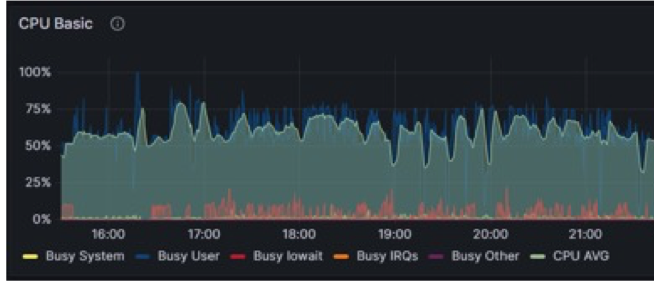
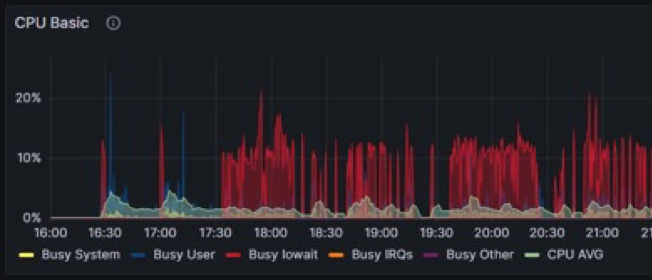
CPU资源从平均60%下降到5%左右
原生Spark方案CPU使用情况:
基于RACE和DPU加速后,CPU使用情况:
总结与展望
通过把Spark的计算卸载到DPU加速器上,在用户原有代码无需变更的情况下,端到端的性能可以得到2-5倍的提升,某些算子能达到43倍性能提升,同时CPU资源使用率从60%左右下降到5%左右,显著提升了原生SparkSQL的执行效率。DPU展现了强大的计算能力,对于端到端的分析,会有一些除去算子之外的因素影响整体运行时间,包括磁盘IO,网络Shuffle以及调度的Overhead。这些影响因素将来可以逐步去做特定的优化,例如:
1. 算子的Pipeline执行
原生Spark的算子Pipeline执行以及CodeGen都是Spark性能提升的关键技术,当前,我们卸载到DPU中的计算还没有支持Pipeline以及CodeGen。未来这两个技术的加入,是继续提升Spark的执行效率的一个方向。
2. 读数据部分,通过DPU卡直读磁盘数据来做优化
我们还可以通过DPU卡直接读取硬盘数据,省去主机DDR到DPU卡DDR的数据传输时间,以达到性能提升的效果,可以参考英伟达的GPU对磁盘读写的优化,官方数据CSV格式的文件读取可优化20倍左右。
3. RDMA技术继续提升Shuffle性能
对于Shuffle占比很高的作业,可以通过内存Shuffle以及RDMA技术,来提升整个Shuffle的过程,目前已经实现内存Shuffle,未来我们还可以通过RDMA技术直读远端内存数据,从而完成整个Shuffle链路的优化。
审核编辑 黄宇
-
DPU
+关注
关注
0文章
417浏览量
27148 -
SPARK
+关注
关注
1文章
108浏览量
21290 -
RACE
+关注
关注
0文章
2浏览量
2455
发布评论请先 登录
无法下载GRID-for-windows驱动程序(GRID 4.x和3.x)
是否可以使用SPC5Studio 3.x进行STM32开发?
什么是DPU?
利用Apache Spark和RAPIDS Apache加速Spark实践
中科驭数发布软件开发平台HADOS 2.0 释放DPU极致性能
Spark基于DPU Snappy压缩算法的异构加速方案
Spark基于DPU的Native引擎算子卸载方案

如何将CCS 3.x工程迁移至最新的Code Composer Studio™ (CCS)

TMS320C6201(修订版2.x)至TMS320C6201B(修订版3.x)



评论