 聊一聊Transformer中的FFN
聊一聊Transformer中的FFN

作者:潘梓正,莫纳什大学博士生
最近看到有些问题[1]说为什么Transformer中的FFN一直没有大的改动。21年刚入学做ViT的时候就想这个问题,现在读博生涯也快结束了,刚好看到这个问题,打算稍微写写, 也算是对这个地方做一个小总结吧。
1. Transformer与FFN
Transformer的基本单位就是一层block这里,一个block包含 MSA + FFN,目前公认的说法是,
•Attention作为token-mixer做spatial interaction。
•FFN(又称MLP)在后面作为channel-mixer进一步增强representation。
从2017至今,过去绝大部分Transformer优化,尤其是针对NLP tasks的Efficient Transformer都是在Attention上的,因为文本有显著的long sequence问题。安利一个很好的总结Efficient Transformers: A Survey [2], 来自大佬Yi Tay[3]。到了ViT上又有一堆attention[4]改进,这个repo一直在更新,总结的有点多,可以当辅助资料查阅。
而FFN这里,自从Transformer提出基本就是一个 Linear Proj + Activation + Linear Proj的结构,整体改动十分incremental。
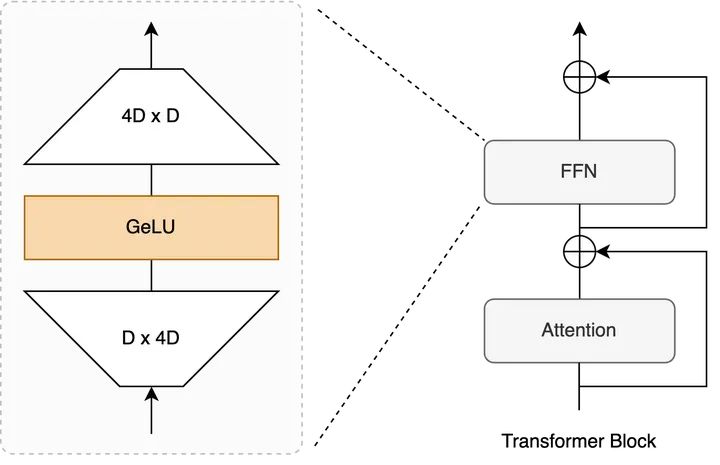
Transformer Block示意图 + FFN内部
2. Activation Function
经历了ReLU, GeLU,Swish, SwiGLU等等,基本都是empirical observations,但都是为了给representation加上非线性变换做增强。
•ReLU对pruning挺有帮助,尤其是过去对CNN做pruning的工作,激活值为0大致意味着某个channel不重要,可以去掉。相关工作可查这个repo[5]。即便如此,ReLU造成dead neurons,因此在Transformer上逐渐被抛弃。
•GeLU在过去一段时间占比相当大,直到现在ViT上使用十分广泛,当然也有用Swish的,如MobileViT[6]。
•Gated Linear Units目前在LLM上非常流行,其效果和分析来源于GLU Variants Improve Transformer[7]。如PaLM和LLaMA都采用了SwiGLU, 谷歌的Gemma使用GeGLU。
不过,从个人经验上来看(偏CV),改变FFN中间的activation function,基本不会有极大的性能差距,总体的性能提升会显得incremental。NLP上估计会帮助reduce overfitting, improve generalization,但是与其花时间改这个地方不如好好clean data。。。目前来说
3. Linear Projections
说白了就是一个matrix multiplication, 已经几乎是GPU上的大部分人改model的时候遇到的最小基本单位。dense matrix multiplication的加速很难,目前基本靠GPU更新迭代。
不过有一个例外:小矩阵乘法可以结合软硬件同时加速,比如instant-ngp的tiny cuda nn, 64 x 64这种级别的matrix multiplication可以使得网络权重直接放到register, 激活值放到shared memory, 这样运算极快。
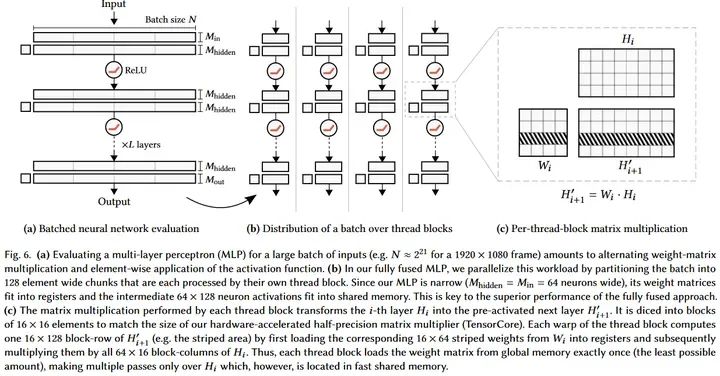
Source: https://github.com/nvlabs/tiny-cuda-nn
但是这对今天的LLM和ViT来讲不现实,最小的ViT-Tiny中,FFN也是个192 x (4 x 192)这种级别,更不用说LLM这种能> 10000的。
那为什么Linear Projection在Transformer里就需要这么大?
常见的说法是Knowledge Neurons。tokens在前一层attention做global interaction之后,通过FFN的参数中存放着大量training过程中学习到的比较抽象的knowledge来进一步update。目前有些studies是说明这件事的,如
•Transformer Feed-Forward Layers Are Key-Value Memories[8]
•Knowledge Neurons in Pretrained Transformers[9]
•...
问题来了,如果FFN存储着Transformer的knowledge,那么注定了这个地方不好做压缩加速:
•FFN变小意味着model capacity也变小,大概率会让整体performance变得很差。我自己也有过一些ViT上的实验 (相信其他人也做过),两个FC中间会有个hidden dimension的expansion ratio,一般设置为4。把这个地方调小会发现怎么都不如大点好。当然太大也不行,因为FFN这里的expansion ratio决定了整个Transformer 在推理时的peak memory consumption,有可能造成out-of-memory (OOM) error,所以大部分我们看到的expansion ration也就在4倍,一个比较合适的performance-memory trade-off.
•FFN中的activations非低秩。过去convnet上大家又发现activations有明显的低秩特性,所以可以通过low rank做加速,如Kaiming的这篇文章[10],如下图所示。但是FFN中间的outputs很难看出低秩的特性,实际做网络压缩的时候会发现pruning FFN的trade-off明显不如convnets,而unstructured pruning又对硬件不友好。
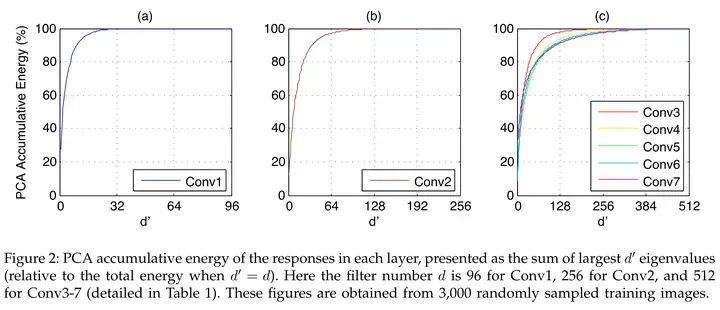
Source: Zhang et.al, Accelerating Very Deep Convolutional Networks for Classification and Detection
4. 所以FFN真的改不动了吗?
当然不是。
我们想改动一个model or module的时候,无非是两个动机:1)Performance。2)Efficiency。
性能上,目前在NLP上可以做Gated MLP[11], 如Mamba[12]的block中,或者DeepMind的新结构Griffin[13]。
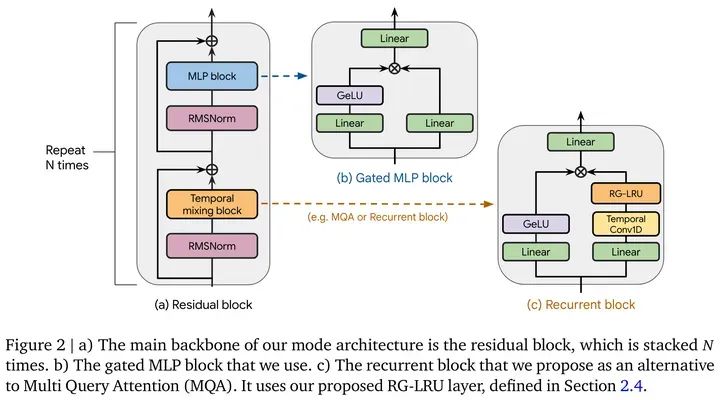
Source: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
但是难说这个地方的性能提升是不是来自于更多的参数量和模型复杂度。
在CV上,有个心照不宣的trick,那就是加depthwise convolution引入locality,试过的朋友都知道这个地方的提升在CV任务上有多明显,例如CIFAR100上,DeiT-Ti可以涨接近10个点这样子。。。
但是呢,鉴于最原始的FFN依然是目前采用最广泛的,并且conv引入了inductive bias,破坏了原先permutation invariant的sequence(因为卷积要求规整的shape,width x height)。大规模ViT训练依然没有采用depthwise conv,如CLIP, DINOv2, SAM, etc。
效率上,目前最promising是改成 **Mixture-of-Expert (MoE)**,但其实。。。GPT4和Mixtral 8x7B没出来之前基本是Google在solo,没人关注。当然现在时代变了,Mixtral 8x7B让MoE起死回生。最近这个地方的paper相当多,简单列几个自己感兴趣的:
•Soft MoE: From Sparse to Soft Mixtures of Experts[14]
•LoRA MoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin[15]
•DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models[16]
5. 达到AGI需要什么结构?
目前这个阶段,没人知道一周以后会有什么大新闻,就像Sora悄无声息放出来,一夜之间干掉U-Net,我也没法说什么结构是最有效的。
总体上,目前没有任何结构能真的完全beat Transformer,Mamba 目前 也不行,如这篇[17]发现 copy and paste不太行,scaling和in-context能力也有待查看。
考虑到未来扩展,优秀的结构应该满足这么几个东西,个人按重要性排序:
•Scaling Law。如果model很难通过scale up提升性能,意义不大(针对AGI来讲)。但是建议大家不要针对这个地方过度攻击学术界paper,学术界很难有资源进行这种实验,路都是一步一步踩出来的,提出一个新architecture需要勇气和信心,给一些宽容。嗯,说的就是Mamba。
•In-Context Learning能力。这个能力需要强大的retrieval能力和足够的capacity,而对于Transformer来讲,retrieval靠Attention,capacity靠FFN。scaling带来的是两者协同提升,进而涌现强大的in-context learning能力。
•Better Efficiency。说到底这也是为什么我们想换掉Transformer。做过的朋友都知道Transformer训练太耗卡了,无论是NLP还是CV上。部署的时候又不像CNN可以做bn conv融合,inference memory大,low-bit quantization效果上也不如CNN,大概率是attention这个地方low-bit损失大。在满足1,2的情况下,如果一个新结构能在speed, memory上展现出优势那非常有潜力。Mamba能火有很大一部分原因是引入hardware-aware的实现,极大提升了原先SSM的计算效率。
•Life-long learning。知识是不断更新的,训练一个LLM需要海量tokens,强如OpenAI也不可能每次Common Crawl[18]放出新data就从头训一遍,目前比较实际的方案是持续训练,但依然很耗资源。未来的结构需要更高效且持久地学习新知识。
Hallucination问题我反倒觉得不是大问题,毕竟人也有幻觉,比如对于不知道的,或自以为是的东西很自信的胡说一通,强推Hinton怼Gary Marcus这个视频[19]。我现在写的东西再过几年回来看,说不定也是个Hallucination。。。
总结: FFN因为结构最简单但是最有效,被大家沿用至今。相比之下,Transformer改进的大部分精力都在Attention这个更明显的bottleneck上,有机会再写个文章聊一聊这里。
审核编辑:黄飞
-
gpu
+关注
关注
28文章
5339浏览量
136287 -
Transformer
+关注
关注
0文章
156浏览量
6993 -
nlp
+关注
关注
1文章
491浏览量
23393
原文标题:聊一聊Transformer中的FFN
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
从焊接角度聊一聊,设计PCB的5个建议

来聊一聊Altium中Fill,Polygon Pour,Plane的区别和用法
聊一聊stm32的低功耗调试
聊一聊7系列FPGA的供电部分
聊一聊FPGA的片内资源相关知识




评论