 深入理解RCU:玩具式实现
深入理解RCU:玩具式实现

1、基于锁的****RCU
也许最简单的RCU实现就是用锁了,如下图所示。在该实现中,rcu_read_lock()获取一把全局自旋锁,rcu_read_unlock()释放锁,而synchronize_rcu()获取自旋锁,随后将其释放。
1 static void rcu_read_lock(void)
2 {
3 spin_lock(&rcu_gp_lock);
4 }
5
6 static void rcu_read_unlock(void)
7 {
8 spin_unlock(&rcu_gp_lock);
9 }
10
11 void synchronize_rcu(void)
12 {
13 spin_lock(&rcu_gp_lock);
14 spin_unlock(&rcu_gp_lock);
15 }
基于锁的RCU实现
因为synchronize_rcu()只有在获取锁(然后释放)以后才会返回,所以在所有之前发生的RCU读端临界区完成前,synchronize_rcu()是不会返回的,因此这符合RCU的语义,特别是存在担保方面的语义。
但是,在这样的实现中,一个读端临界区同时只能有一个RCU读者进入,这基本上可以说是和RCU的目的相反。而且,rcu_read_lock()和rcu_read_unlock()中的锁操作开销是极大的,读端的开销从Power5单核CPU上的100纳秒到64核系统上的17微秒不等。更糟的是,使用同一把锁使得rcu_read_lock(),可能会使得系统形成自旋锁死锁。这是因为:RCU的语义允许RCU读端嵌套。所以,在这样的实现中,RCU读端临界区不能嵌套。最后一点,原则上并发的RCU更新操作可以共享一个公共的优雅周期,但是该实现将优雅周期串行化了,因此无法共享优雅周期。
问题:这样的死锁情景会不会出现其他RCU实现中?
问题:为什么不直接用读写锁来实现这个RCU?
很难想象这种实现能用在任何一个产品中,但是这种实现有一点好处:可以用在几乎所有的用户态程序上。不仅如此,类似的使用每CPU锁或者读写锁的实现还曾经用于Linux 2.4内核中。
2、基于每线程锁的RCU
下图显示了一种基于每线程锁的实现。rcu_read_lock()和rcu_read_unlock()分别获取和释放当前线程的锁。synchronize_rcu()函数按照次序逐一获取和释放每个线程的锁。这样,所有在synchronize_rcu()开始时就已经执行的RCU读端临界区,必须在synchronize_rcu()结束前返回。
1 static void rcu_read_lock(void)
2 {
3 spin_lock(&__get_thread_var(rcu_gp_lock));
4 }
5
6 static void rcu_read_unlock(void)
7 {
8 spin_unlock(&__get_thread_var(rcu_gp_lock));
9 }
10
11 void synchronize_rcu(void)
12 {
13 int t;
14
15 for_each_running_thread(t) {
16 spin_lock(&per_thread(rcu_gp_lock, t));
17 spin_unlock(&per_thread(rcu_gp_lock, t));
18 }
19 }
基于锁的每线程RCU实现
该实现的优点在于:允许并发的RCU读者,同时避免了使用单个全局锁可能造成的死锁。不仅如此,读端开销虽然高达大概140纳秒,但是不管CPU数目为多少,始终保持在140纳秒。不过,更新端的开销则在从Power5单核上的600纳秒到64核系统上的超过100微秒不等。
问题:如果在第15至18行看,先获取所有锁,然后再释放所有锁,这样是不是更清晰一点呢?
问题:该实现能够避免死锁吗?如果能,为什么能?如果不能,为什么不能?
本方法在某些情况下是很有效的,尤其是类似的方法曾在Linux 2.4内核中使用。
下面提到的基于计数的RCU实现,克服了基于锁实现的某些缺点。
3、基于计数的简单RCU实现
1 atomic_t rcu_refcnt;
2
3 static void rcu_read_lock(void)
4 {
5 atomic_inc(&rcu_refcnt);
6 smp_mb();
7 }
8
9 static void rcu_read_unlock(void)
10 {
11 smp_mb();
12 atomic_dec(&rcu_refcnt);
13 }
14
15 void synchronize_rcu(void)
16 {
17 smp_mb();
18 while (atomic_read(&rcu_refcnt) != 0) {
19 poll(NULL, 0, 10);
20 }
21 smp_mb();
22 }
使用单个全局引用计数的RCU实现
这是一种稍微复杂一点的RCU实现。本方法在第1行定义了一个全局引用计数rcu_refcnt。rcu_read_lock()原语自动增加计数,然后执行一个内存屏障,确保在原子自增之后才进入RCU读端临界区。同样,rcu_read_unlock()先执行一个内存屏障,划定RCU读端临界区的结束点,然后再原子自减计数。synchronize_rcu()原语不停自旋,等待引用计数的值变为0,语句前后用内存屏障保护正确的顺序。第19行的poll()只是纯粹的延时,从纯RCU语义的角度上看是可以省略的。等synchronize_rcu()返回后,所有之前发生的RCU读端临界区都已经完成了。
与基于锁的实现相比,我们欣喜地发现:这种实现可以让读者并发进入RCU读端临界区。与基于每线程锁的实现相比,我们又欣喜地发现:本节的实现可以让RCU读端临界区嵌套。另外,rcu_read_lock()原语不会进入死锁循环,因为它既不自旋也不阻塞。
问题:但是如果你在调用synchronize_rcu()时持有一把锁,然后又在RCU读端临界区中获取同一把锁,会发生什么呢?
当然,这个实现还是存在一些严重的缺点。首先,rcu_read_lock()和rcu_read_unlock()中的原子操作开销是非常大的,读端开销从Power5单核CPU上的100纳秒到64核系统上的40微秒不等。这意味着RCU读端临界区必须非常长,才能够满足现实世界中的读端并发请求。但是从另一方面来说,当没有读者时,优雅周期只有差不多40纳秒,这比Linux内核中的产品级实现要快上很多个数量级。
其次,如果存在多个并发的rcu_read_lock()和rcu_read_unlock()操作,因为出现大量高速缓冲未命中,对rcu_refcnt的内存访问竞争将会十分激烈。
以上这两个缺点极大地影响RCU的目标,即提供一种读端低开销的同步原语。
最后,在很长的读端临界区中的大量RCU读者甚至会让synchronize_rcu()无法完成,因为全局计数可能永远不为0。这会导致RCU更新端的饥饿,这一点在产品级应用里肯定是不可接受的。
问题:当synchronize_rcu()等待时间过长了以后,为什么不能简单地让rcu_read_lock()暂停一会儿呢?这种做法不能防止synchronize_rcu()饥饿吗?
通过上述内容,很难想象本节的实现可以在产品级应用中使用,虽然它比基于锁的实现更有这方面的潜力,比如,作为一种高负荷调试环境中的RCU实现。下面我们将介绍一种对写者更有利的引用计数RCU变体。
4、不会让更新者饥饿的引用计数RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 atomic_t rcu_refcnt[2];
3 atomic_t rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
RCU全局引用计数对的数据定义
下图展示了一种RCU实现的读端原语,使用一对引用计数(rcu_refcnt[]),通过一个全局索引(rcu_idx)从这对计数中选出一个计数,一个每线程的嵌套计数rcu_nesting,一个每线程的全局索引快照(rcu_read_idx),以及一个全局锁(rcu_gp_lock),上图给出了上述定义。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = atomic_read(&rcu_idx);
9 __get_thread_var(rcu_read_idx) = i;
10 atomic_inc(&rcu_refcnt[i]);
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 atomic_dec(&rcu_refcnt[i]);
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用全局引用计数对的RCU读端原语
拥有两个元素的rcu_refcnt[]数组让更新者免于饥饿。这里的关键点是synchronize_rcu()只需要等待已存在的读者。如果在给定实例的synchronize_rcu()正在执行时,出现一个新的读者,那么synchronize_rcu()不需要等待那个新的读者。在任意时刻,当给定的读者通过通过rcu_read_lock()进入其RCU读端临界区时,它增加rcu_refcnt[]数组中由rcu_idx变量所代表下标的元素。当同一个读者通过rcu_read_unlock()退出其RCU读端临界区,它减去其增加的元素,忽略对rcu_idx值任何可能的后续更改。
这种安排意味着synchronize_rcu()可以通过修改rcu_idx的值来避免饥饿。假设rcu_idx的旧值为零,因此修改后的新值为1。在修改操作之后到达的新读者将增加rcu_idx[1],而旧的读者先前递增的rcu_idx [0]将在它们退出RCU读端临界区时递减。这意味着rcu_idx[0]的值将不再增加,而是单调递减。这意味着所有synchronize_rcu()需要做的是等待rcu_refcnt[0]的值达到零。
有了背景,我们来好好看看实际的实现原语。
实现rcu_read_lock()原语自动增加由rcu_idx标出的rcu_refcnt[]成员的值,然后将索引保存在每线程变量rcu_read_idx中。rcu_read_unlock()原语自动减少对应的rcu_read_lock()增加的那个计数的值。不过,因为rcu_idx每个线程只能设置为rcu_idx设置一个值,所以还需要一些手段才能允许嵌套。方法是用每线程的rcu_nesting变量跟踪嵌套。
为了让这种方法能够工作,rcu_read_lock()函数的第6行获取了当前线程的rcu_nesting,如果第7行的检查发现当前处于最外层的rcu_read_lock(),那么第8至10行获取变量rcu_idx的当前值,将其存到当前线程的rcu_read_idx中,然后增加被rcu_idx选中的rcu_refcnt元素的值。第12行不管现在的rcu_nesting值是多少,直接对其加1。第13行执行一个内存屏障,确保RCU读端临界区不会在rcu_read_lock()之前开始。
同样,rcu_read_unlock()函数在第21行也执行一个内存屏障,确保RCU读端临界区不会在rcu_read_unlock()代码之后还未完成。第22行获取当前线程的rcu_nesting,如果第23行的检查发现当前处于最外层的rcu_read_unlock(),那么第24至25行获取当前线程的rcu_read_idx(由最外层的rcu_read_lock()保存)并且原子减少被rcu_read_idx选择的rcu_refcnt元素。无论当前嵌套了多少层,第27行都直接减少本线程的rcu_nesting值。
1 void synchronize_rcu(void)
2 {
3 int i;
4
5 smp_mb();
6 spin_lock(&rcu_gp_lock);
7 i = atomic_read(&rcu_idx);
8 atomic_set(&rcu_idx, !i);
9 smp_mb();
10 while (atomic_read(&rcu_refcnt[i]) != 0) {
11 poll(NULL, 0, 10);
12 }
13 smp_mb();
14 atomic_set(&rcu_idx, i);
15 smp_mb();
16 while (atomic_read(&rcu_refcnt[!i]) != 0) {
17 poll(NULL, 0, 10);
18 }
19 spin_unlock(&rcu_gp_lock);
20 smp_mb();
21 }
使用全局引用计数对的RCU更新端原语
上图实现了对应的synchronize_rcu()。第6行和第19行获取并释放rcu_gp_lock,因为这样可以防止多于一个的并发synchronize_rcu()实例。第7至8行分别获取rcu_idx的值,并对其取反,这样后续的rcu_read_lock()实例将使用与之前的实例不同的rcu_idx值。然后第10至12行等待之前的由rcu_idx选出的元素变成0,第9行的内存屏障是为了保证对rcu_idx的检查不会被优化到对rcu_idx取反操作之前。第13至18行重复这一过程,第20行的内存屏障是为了保证所有后续的回收操作不会被优化到对rcu_refcnt的检查之前执行。
问题:为什么上图中,在获得自旋锁之前,synchronize_rcu()第5行还有一个内存屏障?
问题:为什么上图的计数要检查两次?难道检查一次还不够吗?
本节的实现避免了简单计数实现可能发生的更新端饥饿问题。
讨论不过这种实现仍然存在一些严重问题。首先,rcu_read_lock()和rcu_read_unlock()中的原子操作开销很大。事实上,它们比上一个实现中的单个计数要复杂很多,读端原语的开销从Power5单核处理器上的150纳秒到64核处理器上的40微秒不等。更新端synchronize_rcu()原语的开销也变大了,从Power5单核CPU中的200纳秒到64核处理器中的40微秒不等。这意味着RCU读端临界区必须非常长,才能够满足现实世界的读端并发请求。
其次,如果存在很多并发的rcu_read_lock()和rcu_read_unlock()操作,那么对rcu_refcnt的内存访问竞争将会十分激烈,这将导致耗费巨大的高速缓存未命中。这一点进一步延长了提供并发读端访问所需要的RCU读端临界区持续时间。这两个缺点在很多情况下都影响了RCU的目标。
第三,需要检查rcu_idx两次这一点为更新操作增加了开销,尤其是线程数目很多时。
最后,尽管原则上并发的RCU更新可以共用一个公共优雅周期,但是本节的实现串行化了优雅周期,使得这种共享无法进行。
问题:既然原子自增和原子自减的开销巨大,为什么不第10行使用非原子自增,在第25行使用非原子自减呢?
尽管有这样那样的缺点,这种RCU的变体还是可以运用在小型的多核系统上,也许可以作为一种节省内存实现,用于维护与更复杂实现之间的API兼容性。但是,这种方法在CPU增多时可扩展性不佳。
另一种基于引用计数机制的RCU变体极大地改善了读端性能和可扩展性。
5、可扩展的基于计数RCU实现
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 DEFINE_PER_THREAD(int [2], rcu_refcnt);
3 atomic_t rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
RCU每线程引用计数对的数据定义
下图是一种RCU实现的读端原语,其中使用了每线程引用计数。本实现与前一个实现十分类似,唯一的区别在于rcu_refcnt成了一个每线程变量。使用这个两元素数组是为了防止读者导致写者饥饿。使用每线程rcu_refcnt[]数组的另一个好处是,rcu_read_lock()和rcu_read_unlock()原语不用再执行原子操作。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = atomic_read(&rcu_idx);
9 __get_thread_var(rcu_read_idx) = i;
10 __get_thread_var(rcu_refcnt)[i]++;
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 __get_thread_var(rcu_refcnt)[i]--;
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用每线程引用计数对的RCU读端原语
问题:别忽悠了!我在rcu_read_lock()里看见atomic_read()原语了!为什么你想假装rcu_read_lock()里没有原子操作?
1 static void flip_counter_and_wait(int i)
2 {
3 int t;
4
5 atomic_set(&rcu_idx, !i);
6 smp_mb();
7 for_each_thread(t) {
8 while (per_thread(rcu_refcnt, t)[i] != 0) {
9 poll(NULL, 0, 10);
10 }
11 }
12 smp_mb();
13 }
14
15 void synchronize_rcu(void)
16 {
17 int i;
18
19 smp_mb();
20 spin_lock(&rcu_gp_lock);
21 i = atomic_read(&rcu_idx);
22 flip_counter_and_wait(i);
23 flip_counter_and_wait(!i);
24 spin_unlock(&rcu_gp_lock);
25 smp_mb();
26 }
使用每线程引用计数对的RCU更新端原语
下图是synchronize_rcu()的实现,还有一个辅助函数flip_counter_ and_wait()。synchronize_rcu()函数和前一个实现基本一样,除了原来的重复检查计数过程被替换成了第22至23行的辅助函数。
新的flip_counter_and_wait()函数在第5行更新rcu_idx变量,第6行执行内存屏障,然后第7至11行循环检查每个线程对应的rcu_refcnt元素,等待该值变为0。一旦所有元素都变为0,第12行执行另一个内存屏障,然后返回。
本RCU实现对软件环境有所要求,(1)能够声明每线程变量,(2)每个线程都可以访问其他线程的每线程变量,(3)能够遍历所有线程。绝大多数软件环境都满足上述要求,但是通常对线程数的上限有所限制。更复杂的实现可以避开这种限制,比如,使用可扩展的哈希表。这种实现能够动态地跟踪线程,比如,在线程第一次调用rcu_read_lock()时将线程加入哈希表。
问题:好极了,如果我有N个线程,那么我要等待2N*10毫秒(每个flip_counter_and_wait()调用消耗的时间,假设我们每个线程只等待一次)。我们难道不能让优雅周期再快一点完成吗?
不过本实现还有一些缺点。首先,需要检查rcu_idx两次,这为更新端带来一些开销,特别是线程数很多时。
其次,synchronize_rcu()必须检查的变量数随着线程增多而线性增长,这给线程数很多的应用程序带来一定的开销。
第三,和之前一样,虽然原则上并发的RCU更新可以共用一个公共优雅周期,但是本节的实现串行化了优雅周期,使得这种共享无法进行。
最后,本节曾经提到的软件环境需求,在某些环境下每线程变量和遍历线程可能存在问题。
读端原语的扩展性非常好,不管是在单核系统还是64核系统都只需要115纳秒左右。Synchronize_rcu()原语的扩展性不佳,开销在单核Power5系统上的1微秒到64核系统上的200微秒不等。总体来说,本节的方法可以算是一种初级的产品级用户态RCU实现了。
下面介绍一种能够让并发的RCU更新更有效的算法。
6、可扩展的基于计数RCU实现,可以共享优雅周期
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 DEFINE_PER_THREAD(int [2], rcu_refcnt);
3 long rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
使用每线程引用计数对和共享更新数据的数据定义
下图是一种使用每线程引用计数RCU实现的读端原语,但是该实现允许更新端共享优雅周期。本节的实现和前面的实现唯一的区别是,rcu_idx现在是一个long型整数,可以自由增长,所以第8行用了一个掩码屏蔽了最低位。我们还将atomic_read()和atomic_set()改成了ACCESS_ONCE()。上图中的数据定义和前例也很相似,只是rcu_idx现在是long类型而非之前的atomic_t类型。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = ACCESS_ONCE(rcu_idx) & 0x1;
9 __get_thread_var(rcu_read_idx) = i;
10 __get_thread_var(rcu_refcnt)[i]++;
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 __get_thread_var(rcu_refcnt)[i]--;
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用每线程引用计数对和共享更新数据的RCU读端原语
1 static void flip_counter_and_wait(int ctr)
2 {
3 int i;
4 int t;
5
6 ACCESS_ONCE(rcu_idx) = ctr + 1;
7 i = ctr & 0x1;
8 smp_mb();
9 for_each_thread(t) {
10 while (per_thread(rcu_refcnt, t)[i] != 0)
{
11 poll(NULL, 0, 10);
12 }
13 }
14 smp_mb();
15 }
16
17 void synchronize_rcu(void)
18 {
19 int ctr;
20 int oldctr;
21
22 smp_mb();
23 oldctr = ACCESS_ONCE(rcu_idx);
24 smp_mb();
25 spin_lock(&rcu_gp_lock);
26 ctr = ACCESS_ONCE(rcu_idx);
27 if (ctr - oldctr >= 3) {
28 spin_unlock(&rcu_gp_lock);
29 smp_mb();
30 return;
31 }
32 flip_counter_and_wait(ctr);
33 if (ctr - oldctr < 2)
34 flip_counter_and_wait(ctr + 1);
35 spin_unlock(&rcu_gp_lock);
36 smp_mb();
37 }
使用每线程引用计数对的RCU共享更新端原语
上图是synchronize_rcu()及其辅助函数flip_counter_and_wait()的实现。flip_counter_and_wait()的变化在于:
1.第6行使用ACCESS_ONCE()代替了atomic_set(),用自增替代取反。
2.新增了第7行,将计数的最低位掩去。
synchronize_rcu()的区别要多一些:
1.新增了一个局部变量oldctr,存储第23行的获取每线程锁之前的rcu_idx值。
2.第26行用ACCESS_ONCE()代替atomic_read()。
3.第27至30行检查在锁已获取时,其他线程此时是否在循环检查3个以上的计数,如果是,释放锁,执行一个内存屏障然后返回。在本例中,有两个线程在等待计数变为0,所以其他的线程已经做了所有必做的工作。
4.在第33至34行,在锁已被获取时,如果当前检查计数是否为0的线程不足2个,那么flip_counter_and_wait()会被调用两次。另一方面,如果有两个线程,另一个线程已经完成了对计数的检查,那么只需再有一个就可以。
在本方法中,如果有任意多个线程并发调用synchronize_rcu(),一个线程对应一个CPU,那么最多只有3个线程在等待计数变为0。
尽管有这些改进,本节的RCU实现仍然存在一些缺点。首先,和上一节一样,需要检查rcu_idx两次为更新端带来开销,尤其是线程很多时。
其次,本实现需要每CPU变量和遍历所有线程的能力,这在某些软件环境可能是有问题的。
最后,在32位机器上,由于rcu_idx溢出而导致需要做一些额外的检查。
本实现的读端原语扩展性极佳,不管CPU数为多少,开销大概为115纳秒。synchronize_rcu()原语的开销仍然昂贵,从1微秒到15微秒不等。然而这比前面的200微秒的开销已经好多了。所以,尽管存在这些缺点,本节的RCU实现已经可以在真实世界中的产品中使用了。
问题:所有这些玩具式的RCU实现都要么在rcu_read_lock()和rcu_read_ unlock()中使用了原子操作,要么让synchronize_rcu()的开销与线程数线性增长。那么究竟在哪种环境下,RCU的实现既可以让上述三个原语的实现简单,又能拥有O(1)的开销和延迟呢?
重新审视代码,我们看到了对一个全局变量的访问和对不超过4个每线程变量的访问。考虑到在POSIX线程中访问每线程变量的开销相对较高,我们可以将三个每线程变量放进单个结构体中,让rcu_read_lock()和rcu_read_unlock()用单个每线程变量存储类来访问各自的每线程变量。
但是,下面将会介绍一种更好的办法,可以减少访问每线程变量的次数到一次。
7、基于自由增长计数的RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 long rcu_gp_ctr = 0;
3 DEFINE_PER_THREAD(long, rcu_reader_gp);
4 DEFINE_PER_THREAD(long, rcu_reader_gp_snap);
使用自由增长计数的数据定义
下图是一种基于单个全局free-running计数的RCU实现,该计数只对偶数值进行计数,相关的数据定义见上图。rcu_read_lock()的实现极其简单。第3行向全局free-running变量rcu_gp_ctr加1,将相加后的奇数值存储在每线程变量rcu_reader_gp中。第4行执行一个内存屏障,防止后续的RCU读端临界区内容“泄漏”。
1 static void rcu_read_lock(void)
2 {
3 __get_thread_var(rcu_reader_gp) = rcu_gp_ctr + 1;
4 smp_mb();
5 }
6
7 static void rcu_read_unlock(void)
8 {
9 smp_mb();
10 __get_thread_var(rcu_reader_gp) = rcu_gp_ctr;
11 }
12
13 void synchronize_rcu(void)
14 {
15 int t;
16
17 smp_mb();
18 spin_lock(&rcu_gp_lock);
19 rcu_gp_ctr += 2;
20 smp_mb();
21 for_each_thread(t) {
22 while ((per_thread(rcu_reader_gp, t) & 0x1) &&
23 ((per_thread(rcu_reader_gp, t) -
24 rcu_gp_ctr) < 0)) {
25 poll(NULL, 0, 10);
26 }
27 }
28 spin_unlock(&rcu_gp_lock);
29 smp_mb();
30 }
使用自由增长计数的RCU实现
rcu_read_unlock()实现也很类似。第9行执行一个内存屏障,防止前一个RCU读端临界区“泄漏”。第10行将全局变量rcu_gp_ctr的值复制给每线程变量rcu_reader_gp,将此每线程变量的值变为偶数值,这样当前并发的synchronize_rcu()实例就知道忽略该每线程变量了。
问题:如果任何偶数值都可以让synchronize_rcu()忽略对应的任务,那么第10行为什么不直接给rcu_reader_gp赋值为0?
synchronize_rcu()会等待所有线程的rcu_reader_gp变量变为偶数值。但是,因为synchronize_rcu()只需要等待“在调用synchronize_rcu()之前就已存在的”RCU读端临界区,所以完全可以有更好的方法。第17行执行一个内存屏障,防止之前操纵的受RCU保护的数据结构被乱序(由编译器或者是CPU)放到第17行之后执行。为了防止多个synchronize_rcu()实例并发执行,第18行获取rcu_gp_lock锁(第28释放锁)。然后第19行给全局变量rcu_gp_ctr加2。回忆一下,rcu_reader_gp的值为偶数的线程不在RCU读端临界区里,所以第21至27行扫描rcu_reader_gp的值,直到所有值要么是偶数(第22行),要么比全局变量rcu_gp_ctr的值大(第23至24行)。第25行阻塞一小段时间,等待一个之前已经存在的RCU读端临界区退出,如果对优雅周期的延迟很敏感的话,也可以用自旋锁来代替。最后,第29行的内存屏障保证所有后续的销毁工作不会被乱序到循环之前进行。
问题:为什么需要第17和第29行的内存屏障?难道第18行和第28行的锁原语自带的内存屏障还不够吗?
本节方法的读端性能非常好,不管CPU数目多少,带来的开销大概是63纳秒。更新端的开销稍大,从Power5单核的500纳秒到64核的超过100微秒不等。
这个实现除了刚才提到的更新端的开销较大以外,还有一些严重缺点。首先,该实现不允许RCU读端临界区嵌套。其次如果读者在第3行获取rcu_gp_ctr之后,存储到rcu_reader_gp之前被抢占,并且如果rcu_gp_ctr计数的值增长到最大值的一半以上,但没有达到最大值时,那么synchronize_rcu()将会忽略后续的RCU读端临界区。第三也是最后一点,本实现需要软件环境支持每线程变量和对所有线程遍历。
问题:第3行的读者被抢占问题是一个真实问题吗?换句话说,这种导致问题的事件序列可能发生吗?如果不能,为什么不能?如果能,事件序列是什么样的,我们该怎样处理这个问题?
8、基于自由增长计数的可嵌套RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 #define RCU_GP_CTR_SHIFT 7
3 #define RCU_GP_CTR_BOTTOM_BIT (1 <<
RCU_GP_CTR_SHIFT)
4 #define RCU_GP_CTR_NEST_MASK
(RCU_GP_CTR_BOTTOM_BIT - 1)
5 long rcu_gp_ctr = 0;
6 DEFINE_PER_THREAD(long, rcu_reader_gp);
基于自由增长计数的可嵌套RCU的数据定义
下图是一种基于单个全局free-running计数的RCU实现,但是允许RCU读端临界区的嵌套。这种嵌套能力是通过让全局变量rcu_gp_ctr的低位记录嵌套次数实现的,定义在上图中。该方法保留低位来记录嵌套深度。为了做到这一点,定义了两个宏,RCU_GP_CTR_NEST_MASK和RCU_GP_CTR_BOTTOM_BIT。两个宏之间的关系是:RCU_GP_CTR_NEST_MASK=RCU_GP_ CTR_BOTTOM_BIT - 1。RCU_GP_CTR_BOTTOM_BIT宏是用于记录嵌套那一位之前的一位,RCU_GP_CTR_NEST_MASK宏则包含rcu_gp_ctr中所有用于记录嵌套的位。显然,这两个宏必须保留足够多的位来记录允许的最大RCU读端临界区嵌套深度,在本实现中保留了7位,这样,允许最大RCU读端临界区嵌套深度为127,这足够绝大多数应用使用。
1 static void rcu_read_lock(void)
2 {
3 long tmp;
4 long *rrgp;
5
6 rrgp = &__get_thread_var(rcu_reader_gp);
7 tmp = *rrgp;
8 if ((tmp & RCU_GP_CTR_NEST_MASK) == 0)
9 tmp = rcu_gp_ctr;
10 tmp++;
11 *rrgp = tmp;
12 smp_mb();
13 }
14
15 static void rcu_read_unlock(void)
16 {
17 long tmp;
18
19 smp_mb();
20 __get_thread_var(rcu_reader_gp)--;
21 }
22
23 void synchronize_rcu(void)
24 {
25 int t;
26
27 smp_mb();
28 spin_lock(&rcu_gp_lock);
29 rcu_gp_ctr += RCU_GP_CTR_BOTTOM_BIT;
30 smp_mb();
31 for_each_thread(t) {
32 while (rcu_gp_ongoing(t) &&
33 ((per_thread(rcu_reader_gp, t) -
34 rcu_gp_ctr) < 0)) {
35 poll(NULL, 0, 10);
36 }
37 }
38 spin_unlock(&rcu_gp_lock);
39 smp_mb();
40 }
使用自由增长计数的可嵌套RCU实现
rcu_read_lock()的实现仍然十分简单。第6行将指向本线程rcu_reader_gp实例的指针放入局部变量rrgp中,将代价昂贵的访问phtread每线程变量API的数目降到最低。第7行记录rcu_reader_gp的值放入另一个局部变量tmp中,第8行检查低位字节是否为0,表明当前的rcu_read_lock()是最外层的。如果是,第9行将全局变量rcu_gp_ctr的值存入tmp,因为第7行之前存入的值可能已经过期了。如果不是,第10行增加嵌套深度,如果你能记得,它存放在计数的最低7位。第11行将更新后的计数值重新放入当前线程的rcu_reader_gp实例中,然后,也是最后,第12行执行一个内存屏障,防止RCU读端临界区泄漏到rcu_read_lock()之前的代码里。
换句话说,除非当前调用的rcu_read_lock()的代码位于RCU读端临界区中,否则本节实现的rcu_read_lock()原语会获取全局变量rcu_gp_ctr的一个副本,而在嵌套环境中,rcu_read_lock()则去获取rcu_reader_gp在当前线程中的实例。在两种情况下,rcu_read_lock()都会增加获取到的值,表明嵌套深度又增加了一层,然后将结果储存到当前线程的rcu_reader_gp实例中。
有趣的是,rcu_read_unlock()的实现和前面的实现一模一样。第19行执行一个内存屏障,防止RCU读端临界区泄漏到rcu_read_unlock()之后的代码中去,然后第20行减少当前线程的rcu_reader_gp实例,这将减少rcu_reader_gp最低几位包含的嵌套深度。rcu_read_unlock()原语的调试版本将会在减少嵌套深度之前检查rcu_reader_gp的最低几位是否为0。
synchronize_rcu()的实现与前面十分类似。不过存在两点不同。第一,第29行将RCU_GP_CTR_BOTTOM_BIT增加到全局变量rcu_gp_ctr,而不是直接加常数2。第二,第32行的比较被剥离成一个函数,检查RCU_GP_CTR_BOTTOM_BIT指示的位,而非无条件地检查最低位。
本节方法的读端性能与前面的实现几乎一样,不管CPU数目多少,开销大概为65纳秒。更新端的开销仍然较大,从Power5单核的600纳秒到64核的超过100微秒。
问题:为什么不像上一节那样,直接用一个单独的每线程变量来表示嵌套深度,反而用复杂的位运算来表示?
除了解决了RCU读端临界区嵌套问题以外,本节的实现有着和前面实现一样的缺点。另外,在32位系统上,本方法会减少全局变量rcu_gp_ctr变量溢出所需的时间。随后将介绍一种能大大延长溢出所需时间,同时又极大地降低了读端开销的方法。
问题:怎样才能将全局变量rcu_gp_ctr溢出的时间延长一倍?
问题:溢出是致命的吗?为什么?为什么不是?如果是致命的,有什么办法可以解决它?
9、基于静止状态的RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 long rcu_gp_ctr = 0;
3 DEFINE_PER_THREAD(long, rcu_reader_qs_gp);
基于quiescent-state的RCU的数据定义
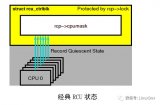
下图是一种基于静止状态的用户态级RCU实现的读端原语。数据定义在上图。从图中第1至7行可以看出,rcu_read_lock()和rcu_read_unlock()原语不做任何事情,就和Linux内核一样,这种空函数会成为内联函数,然后被编译器优化掉。之所以是空函数,是因为基于静止状态的RCU实现用之前提到的静止状态来大致的作为RCU读端临界区的长度,这种状态包括第9至15行的rcu_quiescent_state()调用。进入扩展的静止状态(比如当发生阻塞时)的线程可以分别用thread_offline()和thread_online() API,来标记扩展的静止状态的开始和结尾。这样,thread_online()就成了对rcu_read_lock()的模仿,thread_offline()就成了对rcu_read_unlock()的模仿。此外,rcu_quiescent_state()可以被认为是一个rcu_thread_online()紧跟一个rcu_thread_offline()。从RCU读端临界区中调用rcu_quiescent_state()、rcu_thread_offline()或rcu_thread_online()是非法的。
1 static void rcu_read_lock(void)
2 {
3 }
4
5 static void rcu_read_unlock(void)
6 {
7 }
8
9 rcu_quiescent_state(void)
10 {
11 smp_mb();
12 __get_thread_var(rcu_reader_qs_gp) =
13 ACCESS_ONCE(rcu_gp_ctr) + 1;
14 smp_mb();
15 }
16
17 static void rcu_thread_offline(void)
18 {
19 smp_mb();
20 __get_thread_var(rcu_reader_qs_gp) =
21 ACCESS_ONCE(rcu_gp_ctr);
22 smp_mb();
23 }
24
25 static void rcu_thread_online(void)
26 {
27 rcu_quiescent_state();
28 }
基于静止状态的RCU读端原语
在rcu_quiescent_state()中,第11行执行一个内存屏障,防止在静止状态之前的代码乱序到静止状态之后执行。第12至13行获取全局变量rcu_gp_ctr的副本,使用ACCESS_ONCE()来保证编译器不会启用任何优化措施让rcu_gp_ctr被读取超过一次。然后对取来的值加1,储存到每线程变量rcu_reader_qs_gp中,这样任何并发的synchronize_rcu()实例都只会看见奇数值,因此就知道新的RCU读端临界区开始了。正在等待老的读端临界区的synchronize_rcu()实例因此也知道忽略新产生的读端临界区。最后,第14行执行一个内存屏障,这会阻止后续代码(包括可能的RCU读端临界区)对第12至13行的重新排序。
问题:第14行多余的内存屏障会不会显著增加rcu_quiescent_state()的开销?
有些应用程序可能只是偶尔需要用RCU,但是一旦它们开始用,那一定是到处都在用。这种应用程序可以在开始用RCU时调用rcu_thread_online(),在不再使用RCU时调用rcu_thread_offline()。在调用rcu_thread_offline()和下一个调用rcu_thread_ online()之间的时间成为扩展的静止状态,在这段时间RCU不会显式地注册静止状态。
rcu_thread_offline()函数直接将每线程变量rcu_reader_qs_gp赋值为rcu_gp_ctr的当前值,该值是一个偶数。这样所有并发的synchronize_rcu()实例就知道忽略这个线程。
问题:为什么需要第19行和第22行的内存屏障?
rcu_thread_online()函数直接调用rcu_quiescent_state(),这也表示延长静止状态的结束。
1 void synchronize_rcu(void)
2 {
3 int t;
4
5 smp_mb();
6 spin_lock(&rcu_gp_lock);
7 rcu_gp_ctr += 2;
8 smp_mb();
9 for_each_thread(t) {
10 while (rcu_gp_ongoing(t) &&
11 ((per_thread(rcu_reader_qs_gp, t) -
12 rcu_gp_ctr) < 0)) {
13 poll(NULL, 0, 10);
14 }
15 }
16 spin_unlock(&rcu_gp_lock);
17 smp_mb();
18 }
基于静止状态的RCU更新端原语
下图是synchronize_rcu()的实现,和前一个实现很相像。
本节实现的读端原语快得惊人,调用rcu_read_lock()和rcu_read_unlock()的开销一共大概50皮秒(10的负12次方秒)。synchronize_rcu()的开销从Power5单核上的600纳秒到64核上的超过100微秒不等。
问题:可以确定的是,ca-2008Power系统的时钟频率相当高,可是即使是5GHz的时钟频率,也不足以让读端原语在50皮秒执行完毕。这里究竟发生了什么?
不过,本节的实现要求每个线程要么周期性地调用rcu_quiescent_state(),要么为扩展的静止状态调用rcu_thread_offline()。周期性调用这些函数的要求在某些情况下会让实现变得困难,比如某种类型的库函数。
另外,本节的实现不允许并发的synchronize_rcu()调用来共享同一个优雅周期。不过,完全可以基于这个RCU版本写一个产品级的RCU实现。
10、关于玩具式RCU实现的总结
如果你看到这里,恭喜!你现在不仅对RCU本身有了更清晰的了解,而且对其所需要的软件和应用环境也更熟悉了。想要更进一步了解RCU的读者,请自行阅读在各种产品中大量采用的RCU实现。
之前的章节列出了各种RCU原语的理想特性。下面我们将整理一个列表,供有意实现自己的RCU实现的读者做参考。
1.必须有读端原语(比如rcu_read_lock()和rcu_read_unlock())和优雅周期原语(比如synchronize_rcu()和call_rcu()),任何在优雅周期开始前就存在的RCU读端临界区必须在优雅周期结束前执行完毕。
2.RCU读端原语应该有最小的开销。特别是应该避免如高速缓存未命中、原子操作、内存屏障和条件分支之类的操作。
3.RCU读端原语应该有O(1)的时间复杂度,可以用于实时用途。(这意味着读者可以与更新者并发运行。)
4.RCU读端原语应该在所有上下文中都可以使用(在Linux内核中,只有空的死循环时不能使用RCU读端原语)。一个重要的特例是RCU读端原语必须可以在RCU读端临界区中使用,换句话说,必须允许RCU读端临界区嵌套。
5.RCU读端原语不应该有条件判断,不会返回失败。这个特性十分重要,因为错误检查会增加复杂度,让测试和验证变得更复杂。
6.除了静止状态以外的任何操作都能在RCU读端原语里执行。比如像I/O这样的操作也该允许。
7.应该允许在RCU读端临界区中执行的同时更新一个受RCU保护的数据结构。
8.RCU读端和更新端的原语应该在内存分配器的设计和实现上独立。
9.RCU优雅周期不应该被在RCU读端临界区之外阻塞的线程而阻塞。
所有这些目标,都被Linux内核RCU实现所满足。后续将分析Linux内核中RCU实现代码。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20149浏览量
247160 -
LINUX内核
+关注
关注
1文章
318浏览量
23052 -
Posix
+关注
关注
0文章
36浏览量
10055 -
rcu
+关注
关注
0文章
21浏览量
5714
原文标题:谢宝友: 深入理解RCU之五:玩具式实现
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深入理解Linux RCU:经典RCU实现概要





 工商网监
工商网监
评论