 一文详解SSD中的掉电保护(热插拔)原理
一文详解SSD中的掉电保护(热插拔)原理
为什么固态硬盘需要掉电保护?
作为企业级标准NVMe块设备接口的固态硬盘固件,需要保证在存储系统遇到异常掉电的情况下,或对盘进行热插拔操作的情况下,保证盘上数据的可用性,正确性和一致性。
如果IDC机房忽然断电,或者运维人员误操作下了正在存储数据的固态硬盘,发生数据丢失,可能会影响上层业务的运行,甚至导致客户数据的丢失。后果可能会非常严重。
通常消费级的固态硬盘不需要添加掉电保护的功能,因为在消费级的PC上,通常不会存有特别关键的数据,异常掉电带来的数据丢失后果通常不大,只要固件功能能够保证盘重新上电保证可用性即可。所以在成本的考量下,没有必要在笔记本电脑的硬盘上增加掉电保护功能。
固态硬盘掉电保护的特性?
可用性:
在存储系统异常断电之后,重新给服务器上电,固态硬盘在回复主机端CSTS.RDY信息后,所有功能可用。
正确性:
保存在盘上的数据,保证其数据不会因为异常掉电而被改变,成为错误数据。
一致性:
对于已经回复host Completion Queue Entry(CQE)的写命令数据,固件应保证其信息的正确性。对于已发送未回复CQE的数据,盘可以是老数据,新数据,或者新老混合数据的状态,其混合粒度与NVMe设计有关,在其粒度内(例如保证16KB粒度的数据一致性),数据可以全部都是新数据或者全部都是老数据,不可以出现其他数据。
掉电保护要保护什么数据?
首先,所有的存储系统都有两种基本的功能,即写入时找到空余的位置和读取时找到正确的对应数据位置。
那么为了维护这样的功能,存储系统中都至少有两种数据即真正有效的 用户数据(user data) 和管理用户数据具体位置和状态的 元数据(metadata) ,举个例子,在单机文件系统ext中,文件的内容就是用户数据,而super block和inode数据则为元数据。
掉电保护的目的是保证存储系统的整个状态在完成上电操作后,主机端看到的数据结构和数据内容在逻辑上完全和掉电前一致,即保证元数据和用户数据都被固化在非易失存储器上(NAND flash)。那在固态硬盘中,有哪些用户数据和元数据需要保存?
1.用户数据
NVMe协议中,对用户数据的操作有很多种类,例如直接对数据操作的写(write)命令,对用户数据映射关系进行修改的Dataset Management(TRIM)命令和对整盘进行操作的Format及Sanitize命令等,这些操作的结果都是对主机端看到的逻辑数据块内的内容进行修改,虽然其过程可能并非对NAND上的数据进行改动。
2.元数据
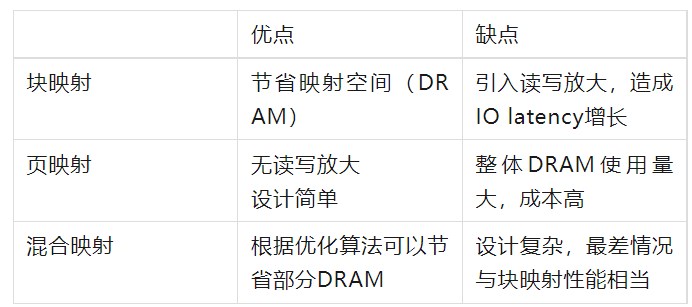
SSD固件中最重要的元数据为Logic address to physical address mapping table,逻辑地址到物理地址的映射表,我们常常称之为L2P表,根据设计的不同主要有三种映射方式:块映射(block mapping),页映射(page mapping)和混合映射(hybird mapping)。
块映射是以block为单位进行映射,在逻辑空间到物理空间的映射过程中,最小映射粒度是块,从而极大的减少了映射表的大小,可以将其存放在SRAM中,假设当前盘的物理空间大小是5TB,其物理块的大小是366 page * 2 plane * 3 (TLC)* 16KB = 34.3MB,如果以5TB/34.3MB可以获得152854个映射关系,如果每个映射entry占用8B空间,则其映射表有1194KB,大约1.2MB的空间。
如果我们将其换成3840GB的标准块设备映射表,每个映射entry依然以8B/4KB计算,其映射表约为7680MB。
当前,为了满足企业级应用和云厂商对于IO latency的需求,企业级SSD通常选用页映射。
通过计算我们可以得到,大容量SSD page mapping SSD对于DRAM的需求非常巨大,同时在异常掉电过程中,如何储存这个巨大的元数据表,保证其上电后数据的一致性,
页映射

块映射

如何保护掉电时的数据?
保护掉电时的数据首先要有能量来源,作为电子设备,除了电源供能外,电池和电容都可以作为额外的供能来源。电池的问题是成本高,而电容的问题是电压下降快,支撑时间短。当然为了可能在盘的生命周期内只会发生几次的的异常掉电情况就在每块盘上都安装一块电池,对于数据中心是非常不划算的买卖,同时也非常的不环保,那么我就就要设计一下固态硬盘的固件,使其在异常掉电事件发生时,只需要毫秒级的时间,就可以完成用户数据和元数据的整体固化,为下次上电过程提供充足的信息恢复数据。

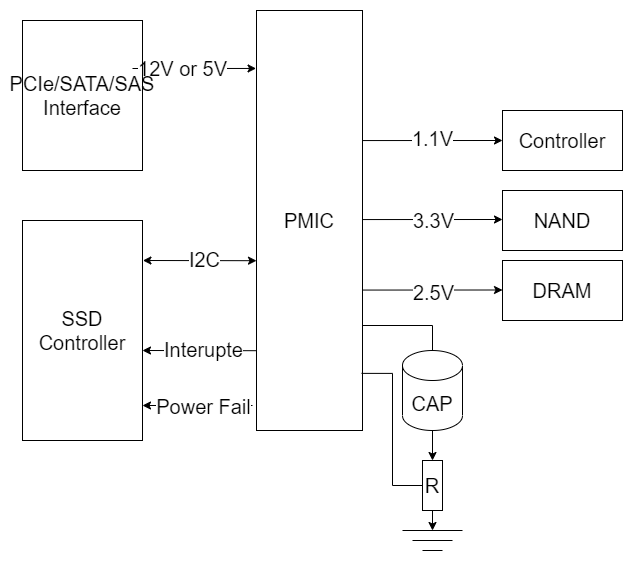
如上图所示,在一个SSD的PCB上,主要有如上图所示的6种主要硬件,分别是与主机端连接的接口,现在主流的是PCIe接口,SSD控制器,PMIC电源控制芯片,DRAM,大量的NAND芯片以及电容。
当有主机的正常供电时,电源从PCIe接口供电,从PMIC将5V电压转化为Controller、DRAM和NAND使用的1.1V,2.5V和3.3V电压,通过不同的通路送出,同时通过分压电路将电容的电压提升到一个相对较高的数值(因为电容存储的电量和电容的电压值平方成正比),将电量保存在电容中。
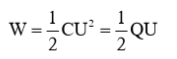
根据上面的公式,我们可以假设电容是1800uF,当充满电时电容的电压是36V,那么可以计算出其保存的电量大约是,1.166J。如果当前的最低可用电压是5V,即电容电压低于5V时SSD上有些器件已经开始不能工作了,则最低可用的电容能量是0.0225J,基本可以忽略不记。
假定SSD的标准功率是25W,最大瞬时功率是30W,那么1.166J的能量可以让SSD在电容的供能情况下运行多久?
0.04664s,也就是46ms,如果是以30W来算也能撑38ms。
PMIC的选型?
通过上面的介绍,我们可以知道,为了实现异常断电的保护,我们需要两个硬件的器件,分别是PMIC和电容。PMIC的主要功能有:
电压转换
将供电的12V电压转换为SSD PCB板上器件使用的对应电压。
电容充电
通过分压电阻确定电容的电压,并对电容进行充电。
异常掉电检测
通过对接口电压输入的检测,当接口的电压下降到12V的90%以下时,产生中断信号给到SSD controller,并开始使用电容供电
输出电压&电流实时监测
对于输出的电路,进行电压过流欠流,电流过流欠流的保护。
其他高级功能
例如现在许多PMIC芯片可以提供模拟主机端掉电的功能,通过内部切断供电切换到电容供电,并在一定时间后检测电容电压的下降情况,从而确定电容的健康程度。
电容如何选型?
市面上的SSD主要有两种主流的电容,一种是体积较大铝电解电容,另一种是相对较为小但是相同容量占PCB面积较大的钽电容:
铝电容的好处是成本低,耐压好,钽电容的优点是容量密度大,稳定性好,寿命长,但是耐压差,成本高。在现有的SSD使用寿命内(普遍在3-5年),铝电容虽然容量较差,但是通过提高电容的电压,可以很好的提高电容存储电量从而弥补电容密度低的缺点,并且最最重要的是,铝电容相对于钽电容便宜太多,在大规模量产的SSD产品中,能够节约非常大的成本。如果有机会拆一拆企业级的SSD,你会发现随着时间的推移,越来越多的厂商选择使用铝电容解决热插拔问题。
电容的容量如何确定?
在选定了电容类型之后,选择电容的容量是下一步非常重要的工作,也是和SSD固件设计最密切相关的一步。我们上面提到的FTL表,在页映射的模式下非常大,如果是我们现在主流使用的4TB盘,其映射表大小通常在3.84GB左右,按照我们前面的计算,盘需要在几十毫秒的时间内,将3.84GB的数据全部写入盘上,这是不现实的。
我们可以对SSD的后端(从主控到NAND的带宽)进行计算,通常一个控制器有8-16个连接NAND芯片的channel,每个Channel上可连接16个NAND芯片来算,后端总共可以使能16*16=256个NAND Die同时做program操作,如果TLC的标准Program时间是2.5ms,一次写入的数据量是2plane * 3 (TLC) *16KB = 96KB数据,则每秒钟可以写入9.375GB的数据(理论极限),这个数据量是在后端没有任何损耗的情况下,并且按照平均program时间来算的,如果我们按照NAND的使用后期,program时间增长的情况来算,其带宽最差可以减少到1/3的理论带宽,在这种情况下,写入3.84GB的数据也需要400ms以上的电容支撑时间,而我们计算出来的电容则只能支持40ms,这还是我们用了1800uF的大电容的情况下提供的时间。
如果保存整个FTL表的策略不可能,有没有其他方法?
我们先来看一看FTL表上电恢复策略的历史演进:
- 扫描全盘恢复
- Checkpoint的引入
- snapshot的引入
- P2L的引入
- Snapshot+Journal
- 单独的Metadata stream
扫描全盘
这是一种最简单朴素的上电恢复策略,其过程是在写入数据的时候,对每个写入单位,例如页,加上一个表示写入顺序的sequence number或者叫version,这个数字用来表示当前页的写入顺序。这种方法有一个前提,是用来排序的页都在一个写入流中,所以当我们有多个写入的流,例如冷热数据分离,GC和User data分离的情况,需要先区分数据的流,再区分页的顺序。
还有一种策略是sequence number策略的简化版,叫block sequence number,这种策略借助了物理块内写入顺序必然是连续的规则,只对block进行排序,block内的顺序自然按照物理上的顺序进行排序,但是这种情况很难应对多流同时写入的顺序排序问题。

sequence number一般被存放在物理页的额外空间内,这个空间内和上电重建相关的主要信息就是sequence number和当前物理页对应的逻辑块的信息(LBA),通过这两个信息,扫描全盘数据即可重新恢复L2P表的大部分信息。
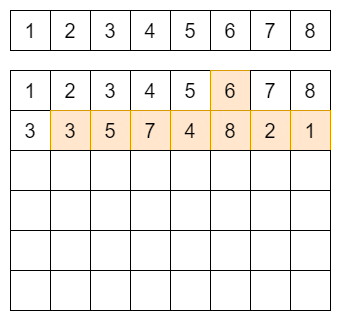
按照上图所示,如果下面的方框是NAND上真实的写入顺序,即先横排从左向右写满再换行,那么其中有颜色的部分为最新的映射位置,因为按照写入的顺序,后面写入的LBA是最新的,我们就可以恢复出来L2P表的映射关系。
扫描全盘的策略引入了一个问题,即TRIM命令的恢复问题。
这个问题的解决方法可以是保存一份Valid Page Bitmap,并在掉电的过程中将整体表保存下来,在SSD容量还比较小的时代,保存整个表还算是比较容易的事情,但是到了大容量时代,即使是VPB table,整个表的大小在4TB的情况下会是128MB。
除了TRIM信息没有办法恢复的问题,扫描全盘的策略还有另外一个问题,上电恢复时间太长,整个上电恢复除了读取全盘的AUX区域信息外,还需要非常长时间的排序和DRAM访问,通常这个时间都在分钟级以上,在现有的云使用场景中,应用希望尽可能快的拉起服务,SSD和系统的启动时间都在向着微秒级发展,分钟级别的上电时间显然是不够用的。
Checkpoint
Checkpoint是存储系统和文件系统里常用的概念,即将关键数据进行备份,用作系统的回滚。在SSD中,checkpoint作为一份完整的L2P表加VPB表,其信息通常周期性的被存放在固定的SSD固件内部block上,不与用户数据混杂,同时一般最少保存2份最近的备份,以免一份数据损坏,不能恢复。
Checkpoint可以解决大部分的盘上信息的扫描,但是固件不可能每次写入或者trim或者format时都做一次checkpoint,这样写放大就太大了,那如果在Checkpoint没有cover的位置发生了掉电怎么办?
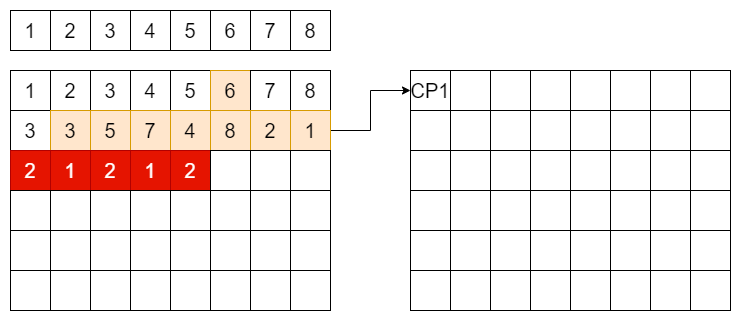
假设我们的用户数据按照顺序写到了如图的位置,其中CP1的位置系统在其他地方做了checkpoint,后面更新的LBA1和LBA2的红色数据没有被包含在CP1中,那么通常的做法是,在做过最新的CP生效后,写入的新数据的AUX中包含指向最近一份的CP的指针。
上电顺序:
- 通过Sequence number扫描block,获取最新的正在写入的block信息
- 通过二分法查找到当前写入的位置,通过最后一个页的信息找到CP指针
- 从NAND中Load CP指针指向的位置,将整份CheckPoint加载到内存
- 通过CP对应的sequence number找到对应的user data写入的sequence number
- 从该位置起启动“全盘扫描”算法,将红色部分全部更新到内存中的L2P表中
- 将Valid Page Bitmap生效到L2P表上
因为有了checkpoint,上电需要扫描的信息大大的减少,但TRIM对应的Valid Page Bitmap依然需要在掉电的过程中保存到NAND上。
Snapshot
所有掉电算法其实都能完成上电L2P表的重建,区别在于其速度和效率,同时鲁棒性更好。这里的Snapshot方法其实原理上和checkpoint相同,但是将其拆分成多个部分分别固化在NAND上。
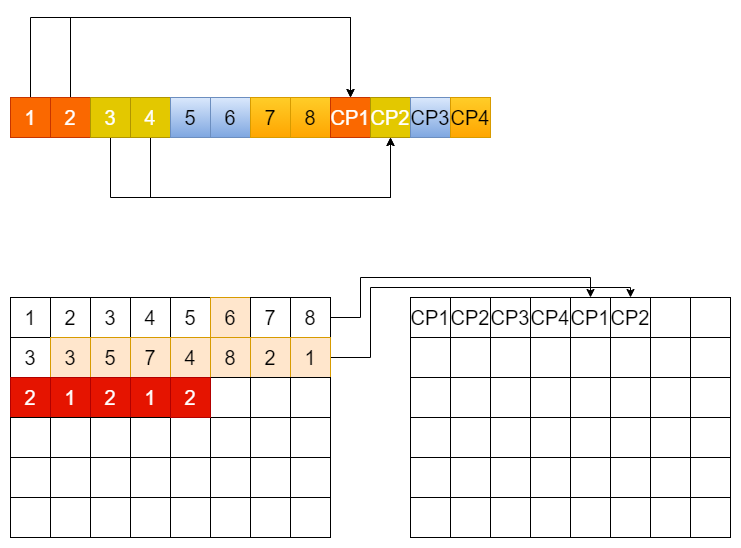
Snapshot方法首先将整个L2P表均匀的划分成多个部分,例如图上的L2P表只有8个LBA,被两两分成了4个部分,即CP1,CP2,CP3,和CP4。如果firmware计算下来,每一行user data写入,触发一次CP的写入是最合算的,那么除了format全盘时写入的一份空CP外,后面的每一个部分都由user data的写入数量触发。
上面的例子中,第一行user data写完时,触发了metadata流中的第二个CP1部分的写入,写入的是LBA1和LBA2的部分,写入之后又到了第二行,则写入了LBA3和LBA4的部分。
大家可以试想一下,这里写入的LBA1和LBA2是指向哪个物理位置的?其实是指向第一对LBA1和LBA2的位置,即整个NAND分布的第一和第二个page,第二行的LBA1和LBA2并没有被包含进来,所以在这种算法之下,每个LBA的部分要分别计算开始“全盘扫描”算法的位置,CP1的起始位置是第二行的开始,CP2的起始位置是第三行的开始,而CP3和CP4的起始位置是所有数据。
虽然在当前的例子中,看起来扫描全盘的数据变多了,但实际上在盘整体运行至稳态后,其扫描数据并不会比checkpoint方法多很多。其好处是每次CP运行时不会有太多数据需要写,并且总体上可以很精准的控制user data和metadata的比例,从而更好的控制写放大和latency。
上电流程:
- 通过block信息扫描到metadata block
- 找到最后一份完整的CP(当前例子是CP2 CP1 CP4 CP3)
- 通过每一份CP的sequence number找到需要“全盘扫描”的起始位置
- 开始全盘扫描更新L2P表
- 更新Valid Page Bitmap表到L2P表
这里同样面临的问题是TRIM的Valid Page Bitmap的问题,其数据依然需要在掉电过程中保存。总体上来说,从checkpoint到snapshot的优化,引入了固件逻辑复杂度,但是分片的方法可以避免很多在checkpoint过程中掉电的问题,以及避免了触发Checkpoint的逻辑点的选择,固定了user data和metadata的比例,更好的控制写放大和时延。
P2L的引入
P2L是一种对L2P映射表的反向映射信息,其作用相当于在AUX中保存的LBA的信息的汇总。
前面提到“扫描全盘”算法中需要对每个页都发起读,这个过程是一个非常耗时的过程,而P2L可以将一整个block上的LBA信息进行集中,从而加速扫描全盘的过程。该信息作用更大的地方在于GC,在GC选中源Block时,其上数据的有效性也可以通过扫描其AUX并对比L2P表进行确认,但GC本身在稳态时成为最大数据量来源,此时能加速GC则对整个盘的性能提升非常有帮助。为了提升GC的效率,通常固件中都会引入P2L信息(物理位置到逻辑块的反向映射信息)和Valid Bit Table信息(快速选源)。
回到我们的上电重建:
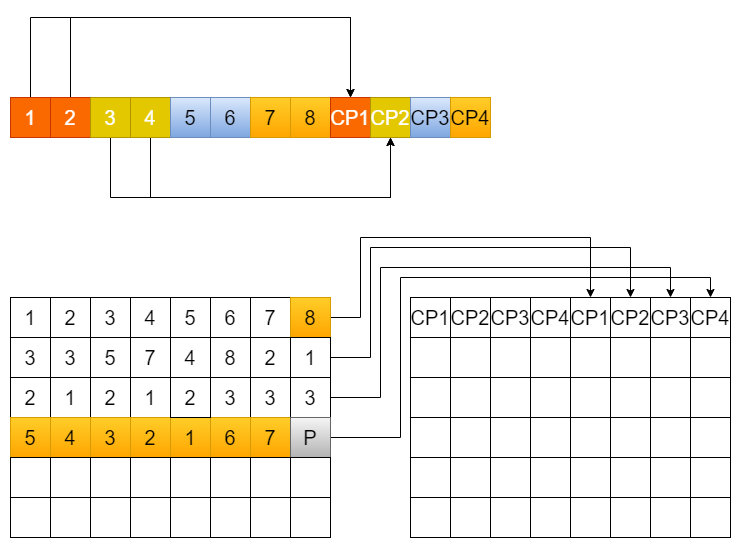
如果我们规定固件中每4行的用户数据需要一个P2L的page,这个page中保存了上面4行中每个page对应的LBA的信息,这个信息被保存在这个block的最后一个一个page上,则我们可以得到的P2Lpage中的信息就像上图中的矩阵一样,P2L自己的LBA信息可以规定为一个特定的无效值,如0xFFFFFFFE等。
这样当上电过程中,需要对该区域进行扫描全盘时,不需要再去读取每一行的用户数据,只需要将P2Lpage的信息读取即可。如果该page发生读错误,可以通过扫描全盘算法进行backup。
引入了P2L之后,不但能加速上电时间,还能起到元数据保护的作用,另外主要还是GC的速率得到非常大的提升。
Journal的引入
journal是什么?实际上Journal是用一个简短的元数据记录来保存L2P变化的信息,举个例子,如果固件做了一笔写,则L2P中的一个信息做了修改,则Journal中会记录一次物理页信息的替换,LBA3421中如果原来指向PPA 12,则新写入的LBA3421会产生一个journal,类型是写信息,记录了LBA,新写入的PPA信息(LBA和PPA pair)。这里如果是TRIM,则会记录LBA的信息。
Journal会保存在DRAM或者SRAM中,当凑足一定的数量后(通常是16KB这样的NAND可写入单位),固化到metadata流中。
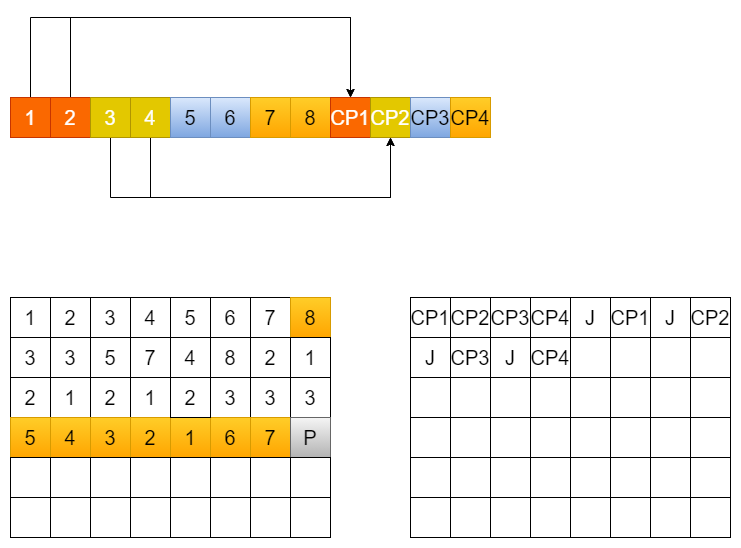
假设一个Journal page中刚好包含8个写page的信息,则可以看到写到4行用户数据的时候,每个CP part前都有一个Journal page,如果Journal page出现在所有有效的CP part之前,则其已经被包含在后面的CP part中,可以不需要做update的操作。
Journal同时可以包括trim和write两种操作的记录,所以在这种设计下,Valid Page Bitmap是不一定需要的,当然这种Bitmap依然可以起到加速trim的作用,但是在逻辑正确性的层面,其并非是必须的。
其优点是显而易见的,可以完全脱离User data来记录metadata,但是也有缺点,即引入了Journal所占用的空间,同时不能完全代替P2L的作用,这里P2L的策略和Journal的策略各有优劣,可以根据设计SSD的目标用户来做权衡,如果想提供更快的上电时间,Journal是更优的策略,如果想节省一定的OP(over provision),则P2L已经可以满足需求。同时,Journal策略可能更匹配多流的设计其流间的上电顺序更容易确定。
单独的Metadata流
我们前面提到的Checkpoint,snapshot,journal信息都是独立于user data的metadata,他们可以被单独的放在一个流上(独立的NAND block上),也可以和用户数据混在一起。多种策略其实在之前的产品中都有实践,并且都能交付。但是在云场景对QoS要求更加严格的今天,多流已经成为一个标配,而元数据不影响用户数据的时延是一个基本需求,所以从协议到固件设计都提出了多流的概念。单独的Metadata流可以引入更加复杂的GC机制,除了为用户数据提供足够的空间外,元数据也要保证数据失效后被擦除的速度。
如我们前面看到的snapshot+journal的方案,其数据就是被独立放置在额外的NAND物理空间上。
根据以上提到的多种L2P元数据固化策略,掉电时需要保存的数据量也会有所不同。
首先是 write buffer中的数据 :
由于用户对IO时延越来越苛刻的要求,现在多数的厂商将write buffer直接做在Controller的SRAM中,当数据从PCIe来的时候,直接fetch到SRAM的好处是速度非常快,在4KB的QS1写测试中,Intel的TLC产品可以达到5-7us的写时延。当固件在SRAM中收集到足够的program数据时,开始直接向NAND传输数据。而在此之前,当数据完全写入SRAM的时候,SSD固件就会向CQE中写入信息,表示write命令完成,虽然此时数据还在SRAM中。

从图上可以看出,当到达第二步的时候,host已经认为数据写完成,如果此时发生掉电或者热插拔现象,SRAM中的数据需要通过电容电量固化到NAND中。这个数据量有多少,各家各不相同,但是基本的计算思路应该是相同的,即需要足够的数据量保证带宽。
为什么写入buffer的大小和带宽有关?因为第一,controller和NAND的关系是1对多的关系,即分发的关系,每一个NAND Die是否在空闲状态,是否出错,是否正在read或者write是需要管理的,而在数据发送出去之前,是需要hold在buffer中的。第二,NAND的program是有一定出错的概率的,如果发生的program错误,有两种常见的处理方式:
- program过程中不释放buffer,等到program返回正确状态才释放
- program开始即释放buffer,如果program失败按照read失败处理
通常第一种方式更安全,所以企业级SSD一般会选择第一种错误处理方式,而这种方式带来的问题是需要hold更长时间的write buffer,需要更大的SRAM即更多的成本。在成本和性能之间,设计者需要做一个平衡。
所有在SRAM中的数据几乎都要在掉电时保存到NAND上,假设我们有1MB的数据需要保存,就要将数据的信息计算到电容的电量中。
GC写buffer的处理
通常GC的流程是,从GC源block中读取一段有效数据,写入到新的GC流block中,这个过程中有一些数据会缓存在SRAM或者DRAM的buffer中。这段数据是否需要在掉电过程中固化?答案是不需要,因为数据的来源来自于源block,这里需要注意的是,上电过程中的L2P表的重建过程会需要特别注意,不要将映射指向GC的目的block,这里有很多的细节需要设计,在不同的L2P表GC update策略中会有不同的做法。不过可以确认的是,在掉电过程中不需要对GC buffer做额外的处理即可。
元数据的处理:
我们前面提到了多种L2P表的固化方法,他们是为正常掉电设计的,异常掉电过程中,一般来说如果是消费级产品,不加电容的话,不论使用全盘扫描还是checkpoint,都可以达到让SSD重新用起来的目标。只是write buffer中的数据不能保证恢复。
在企业级SSD中,虽然保底使用全盘扫描总能恢复当前L2P表,但是其速度会非常慢,所以通常我们把最后缓存在Metadata buffer中的数据,例如未写入NAND的Journal,dirty Valid Page Bitmap等信息同时写入NAND,其数据量通常不超过10MB。
我们假设我们设计的企业级产品有30MB的用户数据buffer,10MB的元数据buffer需要写入,那么需要多大的电容呢?
我们首先需要计算后端带宽:
假设我们的controller有16个channel,每个channel上都挂有16个NAND Die,则共有256个独立的物理die,也就是一个super page有256个独立的physical page。die是NAND可以处理读写擦指令的最小逻辑单位,其内部是不能并行执行其他指令的(可以通过multiplane write等技术并行执行相同命令,但不可同时执行不同命令,因为其逻辑电路是per die设计的),所以后端带宽如果全都执行program命令的话,在TLC的2plane NAND上,可以并行执行256*96KB的program,即24MB。当然这只是一个理论值,在实际运行过程中,还有其他各种损耗,Controller传输的阶梯效应,整体SSD功耗限制等,最终能有效利用其中的80%就算是很好的带宽利用率了。
假设总数据量是30MB+10MB=40MB,后端全die一次的program量是24MB,加上NAND上on going的program,总共需要所有Die在电容支持下program 3次完整的Tprog。

这里如果我们按照TLC NAND spec给出的最差情况,一个program完成的Max time是7ms,那么总共算下来需要3*7=21ms的总时间。前面我们已经计算过大概30w的SSD在1800uF的电容下可以运行多久,相信通过这个时间的比较大家也知道,只要电容运行时间超过program需要的时间,在理论上这个方案就是可行的。
但实际的过程中,我们还需要考虑很多其他的问题,例如如果NAND在做erase全盘的操作,这时掉电需要对NAND发送erase suspend命令并等到命令返回成功,如果盘上写入数据出错,是否需要重写等问题。我们这里仅做掉电处理概念性的介绍,不做详细的讨论,如果您有兴趣,可以联系我私下讨论这些掉电时的异常处理。
通常的处理是我们按照计算出来的需要时间的2-3倍来设计电容,这样即使发生了异常,大概率还是能在电容涵盖的时间内完成保护。
掉电的固件设计
完成了硬件的设计和参数的确定后,固件的设计其实主要还是配合硬件完成工作。首先是中断设计。
掉电中断设计
异常掉电时,PMIC会首先产生一个中断信号脉冲传递给controller,当前绝大部分的controller使用了ARM核,使用的中断可以选择的是IRQ类型和FIQ类型。通常而言,掉电事件的优先级在整个系统中是最高的,但是由于SSD固件的特殊性,我所经历过的一些项目都没有选择可打断中断的FIQ,而选择了让其他中断运行完成后再进入的IRQ。这里的前提假设有两个。第一,在设计其他中断处理函数时,是否设计为可打断的函数,通常我们认为中断处理函数内容非常简单,时间非常短,没有同步行为,则会设计时不会考虑被打断,资源也没有锁等处理机制。第二,在时间上,异常掉电时间是可以容忍微秒级别的延迟的,但是由于其对各种硬件资源的独占性需求,希望在掉电过程中其他资源使用者能及时释放资源。
掉电中断通常设计为两部分:
- 通知硬件中断正在进行的PCIe传输,关闭其他中断源
- 设置全局信号通知所有核上运行固件,发生掉电中断
掉电固件设计
SSD上的资源释放是掉电处理中的关键,SSD上的主要资源是Controller的CPU资源,DRAM资源(L2P表的访问修改权限等),SRAM资源,NAND控制权和其他一些辅助器件的资源。
通常SSD的固件任务,除了IO之外都会设计为可被调度的task状态机,例如GC任务就会被设计为多个阶段,从触发,到选源,到读取,到写入,到L2P更新,都会有自己独立的状态,同时独立的状态中会将数据拆分,例如数据可能会以256KB为单位进行操作等。这样设计的好处是每个子任务都可以独立完成,在任务的中间可以对全局的掉电状态进行检查,并且任务的间隙中对硬件和固件资源没有占用,相当于每个子任务状态机的一个状态结束,都会释放资源。这种设计方案的好处是,对于IO时延和异常掉电都有益处,但是设计复杂度非常高,并且要求设计者在设计任何其他task时,都要时刻考虑状态机的设计,考虑掉电时的资源占用问题,给设计者增加了复杂度。
与之相应的,设计掉电流程时,设计者会尽可能的少占用runtime时的任务所使用的资源,例如掉电过程可以使用一个单独reserved super block作为写入的目的block,可以使用一段自定义的L2P表专门映射30MB的用户数据等。
掉电过程中如果有足够的电容,则可以将30MB+10MB的数据都写入TLC block中,但是当数据量大,或者NAND写入过慢时,又不能增加电容容量,可以将TLC(或QLC)NAND当做SLC来使用,尤其相比于QLC,SLC的后端带宽可以显著增加,从而使SSD在不增加硬件成本的情况下依然保证掉电数据不丢失。
如果使用TLC作为掉电保护的目标block:
- 收到全局的掉电处理状态
- 完成当前核上的runtime task分片
- 切入掉电处理task
- 发送erase suspend指令处理正在erase的die
- 等待所有TLC上的program完成,将所有read指令进行abort
- 将所有buffer中的数据(30MB)写入掉电处理block,补齐到RAID
- 等待写状态返回
- 将Dirty Journal及Dirty Valid Page Bitmap(10MB)写入 目标block
- 等待写状态返回
- 等待电容释放完电量
如果使用SLC作为掉电保护
- 收到全局的掉电处理状态
- 完成当前核上的runtime task分片
- 切入掉电处理task
- 发送erase suspend和write、read abort指令(需NAND支持)
- 等待abort结束
- 将write buffer中数据写入SLC block
- 等待写状态返回
- 将Dirty Journal及Dirty Valid Page Bitmap(10MB)写入SLCblock
- 等待写状态返回
- 记录SLCblock的位置到root信息中
可以看出,用户数据要先于元数据信息写入,这个也非常好理解,元数据必须包含新写入的映射关系,否则上电恢复的过程中将丢掉这些信息。
上电恢复过程
上电的恢复过程与掉电的过程其实正好相反:
- 扫描所有的block以确定其所在的流和顺序
- 从掉电保存信息的block上恢复write buffer中的信息和metadata信息
- 从metadata流中恢复L2P表
- 将write buffer中的信息重新写入正常流
- 确认电容充电完成且电容状态健康
- 回复host CSTS.RDY标志
上电的过程中需要注意,可以将上电整个过程分成三个部分,第一部分是Load信息的过程,第二部分是将掉电信息中的user data和metadata重新写入正常路径,第三部分是给host Ready flag,从而让host可以开始发送新的IO,而盘也可以正常处理下一次异常掉电。
这里需要注意的是一种叫back to back的掉电,即在上电的第一部分和第二部分中再次发生异常掉电的处理。这种处理要求整个上电的过程是归一化的,也就是说当再次发生掉电时,下次上电不需要占用额外的资源,可以统一处理。
掉电过程中的NAND错误
NAND是一种不稳定的介质,所以有可能在掉电保存信息的过程中,发生了NAND介质错误,或者在掉电后过了很长一段时间才上电,在此期间发生了介质错误,那么是否可以像正常的program或者read error一样处理呢?
掉电处理的设计有一个通用性的原则就是,能在上电过程中处理的事情,就不要占用电容的电量在掉电过程处理,如果有额外的电量,可以处理。
如果在掉电过程中发现了program状态出错,这时的信息还在我们的buffer里,有两种可供选择的方法,第一是重新再次program,第二是等上电时像read error一样用RAID来纠错。选择哪种方法要根据NAND出错的概率来计算,如果program fail和UECC发生在同一个RAID set上的概率低于产品设计时的UECC允许概率,则可以将其当做read error来统一处理。
异常掉电的Debug
异常掉电的debug可以单独的拿出来写一篇文章,因为异常掉电的处理面临非常多种的复杂情况,可以说盘上的固件在做任何Task时都有可能触发异常掉电,所以要写UT来测试异常掉电可能会非常复杂。而任何同步操作导致的资源释放变慢,掉电处理task接管SSD时间晚等问题,都有可能造成SSD在电容电量之内没能处理完所有数据,导致上电过程失败。
首先,掉电过程在结束时需要一个明显的标识来确定掉电task完整做完。
其次,掉电过程需要记录足够的log信息来供工程师debug使用。
最后,通过控制PMIC来进行假掉电事件的模拟可以抓到很多问题。
异常掉电处理的发展和展望
异常掉电是SSD固件中一个比较难设计好的feature,并且通过复杂的设计保证的很多功能在现实的应用场景中也很难遇到,一旦出现了掉电丢数据的情况,通常损失非常惨重,轻则丢失一些重要客户,重则造成工程甚至人身安全的损失。随着单盘的容量越来越大,L2P表的体积也越来越大,其上电时间因而也线性的增加了。
1.通过改变L2P表的结构来优化
L2P表是一个线性映射表,如果我们将其与文件或者对象相结合,是否可以通过树或者其他形式进行直接对映射?
2.通过改变L2P表固化的介质
相变存储器的引入和多层的L2P表merge设计可能会是一个固化L2P表的新思路,这里以Optane为代表的非易失存储器可以用来存储L2P表,这样SSD中就彻底的解决了L2P表固化问题。
-
NAND
+关注
关注
16文章
1546浏览量
134819 -
热插拔
+关注
关注
2文章
194浏览量
32886 -
SSD
+关注
关注
20文章
2691浏览量
115513 -
固态硬盘
+关注
关注
11文章
1358浏览量
56499 -
掉电保护
+关注
关注
2文章
24浏览量
15747
发布评论请先 登录
相关推荐
热插拔是什么?热插拔有哪些特点?
即插即用和热插拔的区别
HDMI端口热插拔问题
关于非隔离dcdc电源模块的热插拔问题详解
空间受限应用中的PMBus热插拔电路基础介绍
基于TPS2491的热插拔保护电路设计
为什么热插拔应用需要 TVS 二极管?
基于IC的热插拔电路保护的优势





 工商网监
工商网监
评论