 混合NVM/DRAM平台上的内存带宽调节策略
混合NVM/DRAM平台上的内存带宽调节策略

01 背景 & 动机
随着相变存储器 (PCM)、STT-MRAM、忆阻器和英特尔的 3D-XPoint 等技术的快速发展,高速的、可字节寻址的新兴 NVM 的产品逐渐涌现于市场中,学术界和工业界针对这一新兴存储介质展开了广泛的应用探索并对计算机基础领域的发展造成了不小的影响。
NVM 编程库,NVM 数据结构,NVM 感知文件系统和基于 NVM 的数据库已经得到了广泛研究,许多内存或存储系统都使用 NVM 编程库移植到 NVM,例如 PmemKV 和 Pmem-RocksDB。Google 等公司已经尝试将首款商用 NVM 产品 Intel Optane DC Persistent Memory 部署到了云数据中心环境中。当NVM 与易失性 DRAM 并排放置以作为快速字节可寻址存储或大容量运行时内存被部署时,就形成了混合 NVM/DRAM 平台。
Noisy Neighbor 问题
在云数据中心中,当一些应用程序(称为 Noisy Neighbor,吵闹邻居)会过度使用内存带宽时,会影响其他应用程序的性能。在传统 DRAM 平台上通过预防策略和补救策略缓解此问题:
1.主动为应用程序设置带宽限制,以防止任何应用程序成为潜在的吵闹邻居。
2.监视并识别系统中是否存在吵闹邻居,限制新出现的吵闹邻居的内存带宽使用。
Intel 发布的商业 Optane PM 可通过 CPU load/store 指令直接访问,但 NVM 的实际带宽仍远低于 DRAM。在混合 NVM/DRAM 平台上由于 NVM 和 DRAM 共享内存总线,这无疑增加了内存带宽干扰的复杂性。
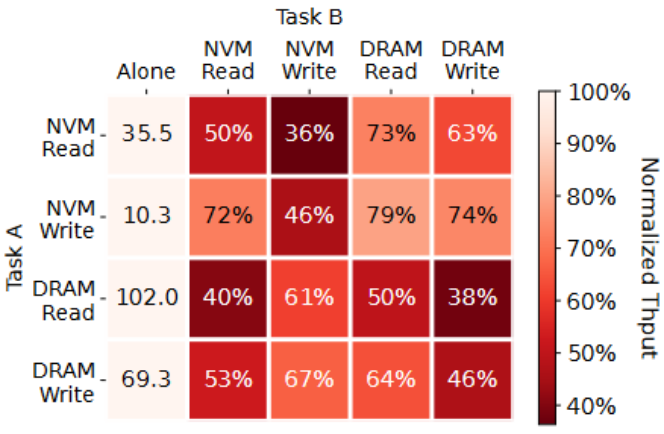
本文在混合平台上运行 fio 工作负载来说明不同类型带宽之间竞争的影响,结果如下图。一共有四类任务:NVM Read、NVM Write、DRAM Read和DRAM Write,首先测量了每类任务单独运行时的吞吐量并作为 baseline,即第一列。随后测量了每两类任务同时运行时主任务的吞吐量,并以归一化的值显示出来,较小的数字(即较暗的块)表示其他嘈杂任务对主任务吞吐量的影响更大。
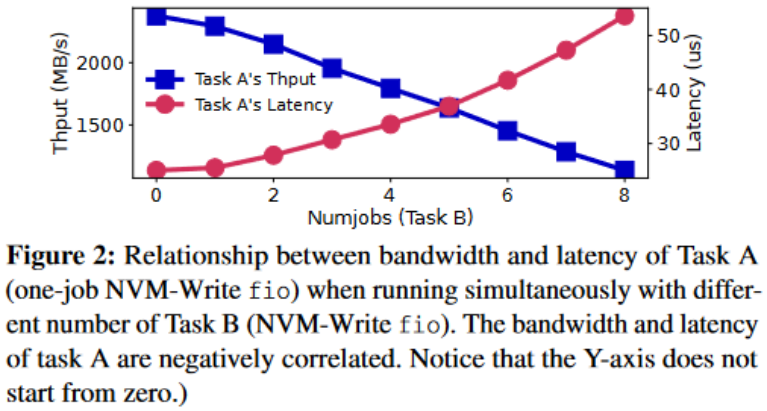
本文在进行带宽实验的同时还检查了任务的吞吐量和延迟之间的关系。下图显示了任务 A(NVM Write)与任务 B(具有可变数量的 NVM-Write fio)同时运行的吞吐量和延迟。
本文得到以下观察结果:
1. 内存干扰的影响与内存访问的类型密切相关,比内存带宽占用量的影响更大。
2. NVM 访问对其他任务的影响比 DRAM 访问更严重。
3. 随着任务 B 的数量增长,任务 A 的带宽逐渐减小(由于带宽干扰的增强),同时任务 A 的延迟增加。由于内存访问延迟与带宽使用呈明显负相关关系,这表明我们可以通过测量不同类型内存访问的延迟来检测内存带宽干扰情况。
这表明在 NVM/DRAM 混合平台在 Noisy Neighbor 问题呈现出更加复杂和严重的特征。在混合平台上进行内存带宽调节存在以下重大挑战:
1.NVM 和 DRAM 内存带宽上限不对称,导致系统实际可用内存带宽很大程度上取决于工作负载中不同类型的内存访问的比例。
2.现有 NVM/DRAM 混合平台上NVM 与 DRAM 共享内存总线,内存流量的混合导致在每个进程的基础上监控不同类型的内存带宽几乎是不可能的,使得现有的为 DRAM 设计的硬件和软件监管方法无效。
3.现有内存调节的硬件和软件机制不足。CPU 供应商提供了硬件机制是粗粒度和定性的,频率缩放和 CPU 调度等技术,可以提供相对细粒度的带宽调整,但它们也是定性的并且减慢了计算和内存访问效率。
现有的硬件调节和计数机制:
Intel Memory Bandwidth Monitoring (MBM) 支持在硬件级统计每个 NUMA 节点的内存流量并记录到指定寄存器。
Intel Memory Bandwidth Allocation (MBA) 硬件功能,以可忽略的开销提供对内存带宽的间接和近似控制。MBA 支持对一组线程进行控制,通过向内存请求插入延迟来限制内存带宽的使用。由于延迟机制,相同的限制值在具有不同内存访问模式的应用程序中可能表现不同。
IMC 性能计数器可以获得不同类型的实时带宽,但仅限于内存通道粒度而不是进程粒度。
02 设计方案
1. MT^2 的设计
本文对现有软硬件技术进行了深入调研,并提出了一种在 NVM/DRAM 混合平台上监控调节并发应用的内存带宽的设计(MT^2)。MT^2 实现于内核态,但用户可通过伪文件系统接口与 MT^2 通信,将线程分类到不同的组(与 cgroups 相同)并指定一个策略来调节每个组的带宽。TGroups(即 Throttling Groups)是 MT^2 中带宽监控和限制的目标。其架构图如下:
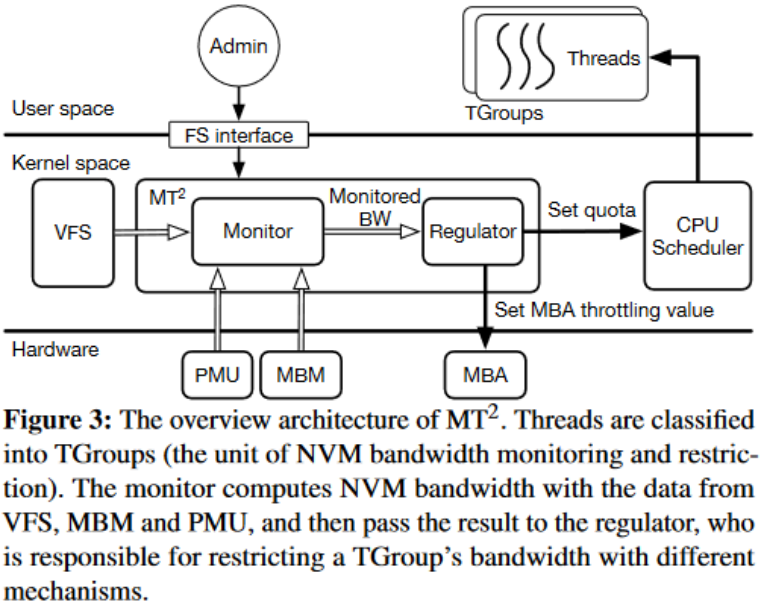
MT^2 由两部分组成:监控器和调节器。从VFS、PMU(Performance Monitoring Unit)和MBM收集的数据,监控器将其分为四种类型,并将它们和干扰信息转发给调节器。根据监控数据和调节测量,调节器通过两种机制做出限制带宽的决定:调整 MBA 限制值和改变 CPU 配额。MT^2 采用动态带宽限制算法,根据实时带宽和干扰水平不断监控和调整限制。
MT^2 提供了两种策略来缓解 Noisy Neighbor 问题(预防和补救策略)以应对不同的场景。为了预防,系统管理员需要为每个 TGroup 设置带宽上限。MT^2 监控精确的实时带宽并强制所有组不要使用超过上限的带宽。但是,多个不超过上限的 TGroup 一起仍然可能造成较强的带宽干扰,可以通过补救策略识别和重新限制。这两种策略是正交的;因此,何时以及如何使用这两种策略取决于具体场景。
2. MT^2 监控器的设计
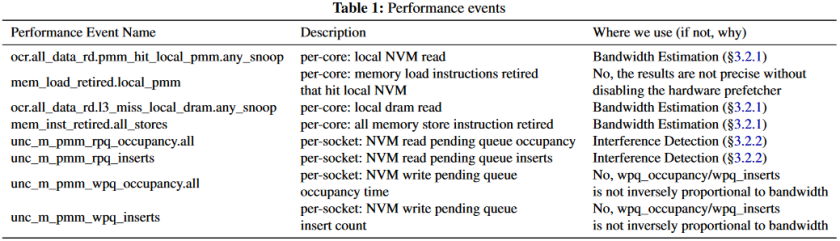
监控器结合了各种硬件和软件技术,以在进程粒度区分不同类型的带宽,检测系统当前的内存干扰程度。在硬件技术方面,重点使用到的一些性能事件的描述如下表所示:
2.1. 带宽估计
获得每种访问类型的准确或估计的带宽值,即 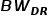 表示 DRAM 读取量、
表示 DRAM 读取量、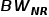 表示 NVM 读取量、
表示 NVM 读取量、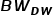 表示 DRAM 写入量和
表示 DRAM 写入量和 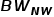 表示 NVM 写入量。
表示 NVM 写入量。
测量每个进程 DRAM 和 NVM 读取量的精确值:
•:基于 ocr.all_data_rd.pmm_hit_local_pmm.any_snoop PMU 事件计数器检索本地 NVM 读取次数并将该值乘以缓存行大小 (64B)
•:基于 ocr.all_data_rd.l3_miss_local_dram.any_snoop PMU 事件计数器检索本地 NVM 读取次数并将该值乘以缓存行大小 (64B)
利用 MBM 来监控每个 TGroup 的总内存访问带宽,即 、、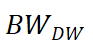 和 的总和。鉴于我们可以通过 PMU 计算出 和 的精确值,此时只需要知道每个进程 的精确值,就能计算出所有值。由于用户空间应用程序只能通过两种方式写入 NVM:文件 API(write)和内存映射文件后的 CPU store 指令。
和 的总和。鉴于我们可以通过 PMU 计算出 和 的精确值,此时只需要知道每个进程 的精确值,就能计算出所有值。由于用户空间应用程序只能通过两种方式写入 NVM:文件 API(write)和内存映射文件后的 CPU store 指令。
•对于文件 API,MT^2 挂钩内核中的 VFS 并跟踪每个 TGroup 的 NVM 写入量。
•对于内存映射访问,受信任的应用程序可以自行收集并向 MT^2 报告其对内存映射 NVM 的写入量。通过挂钩修改英特尔官方 PMDK 编程库,显式地将缓存行刷新或者执行非临时内存写入,并用每线程计数器计算总 NVM 写入量。最后为每个进程设置一个与内核共享的 page,进程中的每个线程将其每线程计数器值写入 page 中的不同槽中。内核中的 MT^2 定期检查计数器并计算每个 TGroup 的带宽。另外,还可以现代英特尔处理器中的一种高效采样功能,基于处理器事件的采样 (PEBS),将每个 TGroup 采样到的内存写入地址与 NVM 的地址范围进行比较,可以得出采样写入 NVM 和 DRAM 的比例,以此粗略计算出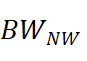 和
和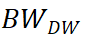 。
。
2.2. 干扰检测
即使给出四种内存访问的准确带宽使用情况,也很难确定带宽干扰是否发生及其严重程度,因为内存访问需求的减少和 Noisy Neighbor 的存在都会导致应用程序使用更少的带宽。
MT2 不是通过内存带宽检测内存干扰,而是通过测量不同类型内存访问的延迟来检测干扰级别,动机实验的关键洞察支撑这一点设计,内存访问延迟与由于竞争导致带宽使用情况呈负相关关系。
• 对于读取,从四个 PMU 性能事件中获取延迟,unc_m_pmm_rpq_occupancy.all(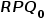 )、unc_m_pmm_rpq_inserts(
)、unc_m_pmm_rpq_inserts(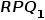 )、unc_m_rpq_occupancy 和 unc_m_rpq_inserts。NVM 读取的延迟可以通过
)、unc_m_rpq_occupancy 和 unc_m_rpq_inserts。NVM 读取的延迟可以通过  来计算,DRAM 读取延迟同理。
来计算,DRAM 读取延迟同理。
• 对于写入,MT^2 定期发出一些 NVM 和 DRAM 写入请求并测量它们的完成时间以获得两种类型写入请求的延迟。
最后需要设置一个阈值来判断带宽干扰是否发生。当某个访问请求的时延超过相应的阈值时,平台就会出现比较严重的干扰,遂影响到该类内存的访问。通过测量不同干扰水平下带宽和延迟之间的关系得出阈值(可以跨不同平台调整阈值),在我们的平台中使用吞吐量减少 10% 时的延迟作为阈值。
3. MT^2 调节器的设计
基于上述收集到的内存带宽相关信息,调节器将干扰水平和监控带宽作为输入,并根据系统管理员设置的调节策略决定采取什么行动来调整TGroup的带宽,以避免或抑制噪声应用程序。
3.1. 内存调节机制
本文使用了两种内存调节机制:Intel Memory Bandwidth Allocation(MBA)硬件功能和 CPU 调度机制。如前所述,MBA通过向内存请求插入延迟来限制内存带宽的使用,而 CPU 调度是通过减少分配给应用程序的内核数量以达到控制内存带宽的效果。例如,通过配置 Linux CPU cgroup 更改线程的 CPU 时间(或 CPU 配额),MT^2 中的 CPU 配额定义了在给定时间段内分配给 TGroup 线程的 CPU 时间上限。具有较低 CPU 配额的 TGroups 占用较少的 CPU 时间,因此它消耗较少的内存带宽。
为了说明 MBA 和 CPU 调度的效果,本文使用 fio 在不同的限制值下生成不同的工作负载。Throttling 值 100 表示没有限制,而 10 表示最大限制,结果如下图所示:
从上述图表中我们可以发现,MBA只支持有限的限制值,并不是所有的限制值都对工作负载有效。MBA 对 DRAM 密集型工作负载的限制的表现比对 NVM 密集型工作负载的限制更好,MBA 对 NVM 写的限制几乎完全无效。因此,MBA 无法精确控制线程的带宽,而 CPU 调度可以作为 MBA 的一种补充机制,CPU 调度可以提供粒度更细且表现看似更好的内存带宽限制。如上表 3 所示,我们需要注意的是,MBA 仅仅减慢了内存访问操作并且不影响其他操作(计算操作),所以 MBA 机制在仅限制内存带宽方面其实是效率更高的,但适用性有限。
3.2 动态带宽限制
本文采用动态带宽限制的算法结合了上述所有机制,首先根据监视器提供的信息识别噪声邻居,然后采取措施限制嘈杂的邻居的内存带宽。
基于上述分析,本文认为具有最多 NVM 写入的 TGroup 更有可能成为嘈杂的邻居,其次是具有最多 NVM 读取的 TGroup,最后是具有更多 DRAM 访问的 TGroup。该算法按上述顺序选择最有可能成为噪声邻居的 TGroup。
然后算法根据要限制的内存带宽类型选择内存调节机制。为了限制NVM访问带宽,该算法采用 CPU 调度机制,为了仅限制 DRAM 访问带宽,该算法选择降低目标 TGroup 的 MBA 值。如果 MBA 已设置为最低值,则算法使用 CPU 调度进行进一步限制。
一旦内存干扰消失,该算法就会尝试放松强制执行的带宽限制。调节器将周期性运行,根据监视器提供的新信息采取另一个步骤。循序渐进的方法减少了平台内存带宽变化的不确定性,并防止应用程序出现不必要的性能抖动。
4. MT^2 的实现
本文修改 Linux 内核 5.3.11 以将 TGroup 添加为 cgroups 的子系统。MT^2 被实现为与 TGroup 子系统紧密合作的内核模块。
首先挂载子系统并在子系统挂载点创建一个新目录(即创建一个新的 TGroup),然后将进程的 pid 写入 cgroup.procs 文件(即将进程添加到 TGroup)。随后可以读取/写入此目录中的另外三个文件以管理 TGroup:
1. priority 文件用于获取和设置 TGroup 的优先级,高优先级进程不受限制,只有低优先级进程才可能被限制。
2. bandwidth 文件是只读的,返回 TGroup 上一秒的带宽。
3. limit 文件用于获取和设置 TGroup 的四种内存访问的绝对带宽限制。MT^2 会确保每个组使用的带宽不会超过预设上限。
注意,每次发生进程上下文切换时,都会为将在此 CPU 内核上运行的新线程设置相应的 MT^2 上下文,即进程对应的 PMU 寄存器、MBA 相关的 MSR 寄存器并设置 CPU 配额,具体实现方法欢迎查阅论文原文。
03 实验评估
实验评估环境的准备
本文从有效性、性能开销以及可信环境下的准确性等多个维度全面评估 MT^2,受限于篇幅,此处重点关注有效性方面。
本实验在具有两个 28 核 Intel Xeon Gold 6238R CPU 并禁用超线程的服务器上进行。服务器有两个 NUMA 节点,每个节点都配备了 6*32GB DDR4 DRAM 和 6*128GB Optane PM,配置为交错的 app-direct 模式,所有实验都在单个 NUMA 节点上进行。
噪声邻居抑制情况分析
本文在使用 MT^2 的混合平台上重新运行了一遍任务并行时的带宽运行,用四种 fio 工作负载来说明 MT^2 在缓解不同类型带宽之间竞争的作用。结果如下图所示,一般来说,带有 MT^2 的列比没有 MT^2 的列的颜色要浅得多,这表明 MT2 可以通过限制其带宽使用来有效减少嘈杂邻居的干扰。
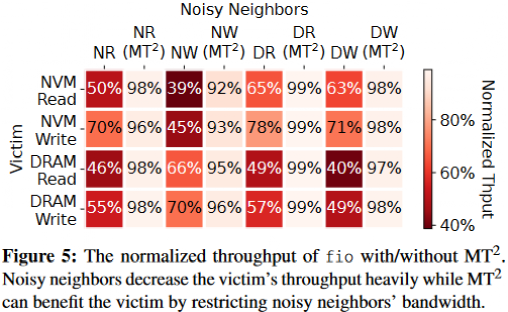
以 NVM Read 工作负载为例,四种噪声邻居将 Victim 进程 fio 的吞吐量降低到基线的 50%、39%、65% 和 44%。通过使用 MT^2 限制嘈杂邻居的带宽,Victim 进程 fio 的吞吐量恢复到基线的 98%、92%、99% 和 98%。其他工作负载呈现类似现象。
分配指定内存带宽
本文利用 TGroup 为四种内存访问模式对应的进程分配了指定的带宽上限限制,通过 fio 实验判断本文设计的限制功能是否有效。结果如下表所示,第一列表示各个任务单独运行时的吞吐量,第二列表示四个任务同时运行时各自的吞吐量。以 DRAM 写入为例,多任务并行时吞吐量下降了 66%(从 7.4GB/s 到 2.5GB/s)。然后,本文为这些任务分配不同的带宽保证(如括号中的数字所示),数据显示这些任务的带宽在 MT^2 的规定下得到满足。
04 总结
持久内存(PM)/ 非易失性内存(NVM)的出现正改变着存储系统的金字塔层次结构。本文发现,由于 NVM 和 DRAM 共享同一条内存总线,带宽干扰问题变得更为严重和复杂,甚至会显著降低系统的总带宽。
本工作介绍了对内存带宽干扰的分析,对现有软硬件技术进行了深入调研,并提出了一种在 NVM/DRAM 混合平台上监控调节并发应用的内存带宽的设计(MT^2)。MT^2 以线程为粒度准确监测来自混合流量的不同类型的内存带宽,使用软硬件结合技术控制内存带宽。
在多个不同的用例中,MT^2 能够有效限制 Noisy Neighbors,消除吵闹邻居的带宽干扰,保证高优先级应用程序的性能。
审核编辑:刘清
-
PCM
+关注
关注
1文章
207浏览量
55399 -
DRAM
+关注
关注
40文章
2373浏览量
188186 -
存储器
+关注
关注
39文章
7715浏览量
170868 -
忆阻器
+关注
关注
8文章
75浏览量
20724 -
NVM
+关注
关注
1文章
46浏览量
19714
原文标题:混合NVM/DRAM平台上的内存带宽调节
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
三星LPDDR5X DRAM已在高通骁龙移动平台上验证使用

stm32F407平台上使用freertos,使用pvPortMalloc申请内存,发现内存中的数据总被修改,怎么解决?

DRAM内存原理
怎样去解决调节rk3288平台上的cpu温度频率出现bug的问题呢
Firefly-RK3399平台上的DDR动态频率驱动调节
DRAM内存模块的设计技术
导体平台上线天线问题的MoM-PO分析
DRAM原理 5 :DRAM Devices Organization
私有云平台的虚拟机内存调度策略





 工商网监
工商网监
评论