 如何实现一个高性能内存池
如何实现一个高性能内存池

写在前面
本文的内存池代码是改编自Nginx的内存池源码,思路几乎一样。由于Nginx源码的变量命名我不喜欢,又没有注释,看得我很难受。想自己写一版容易理解的代码。
应用场景
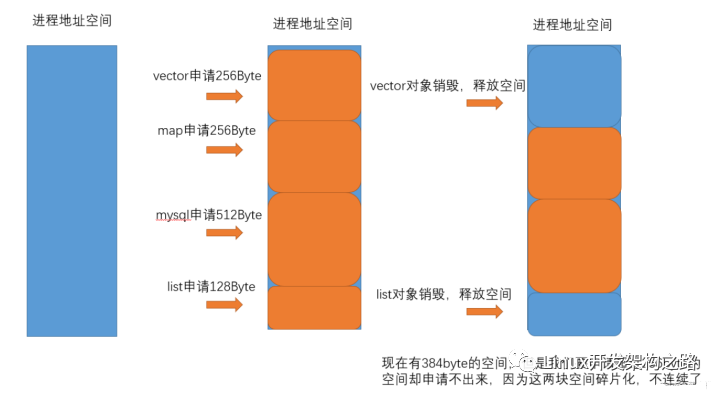
写内存池的原理之前,按照惯例先说内存池的应用场景。
为什么我们需要内存池?
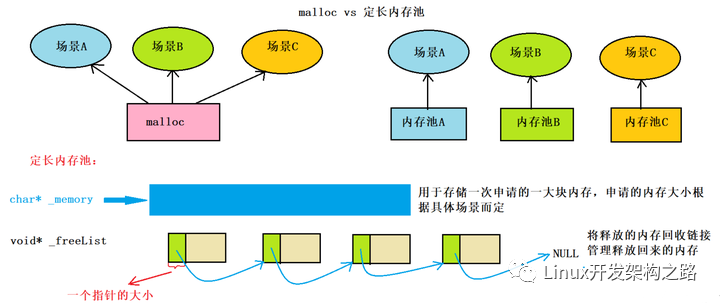
- 因为malloc等分配内存的方式,需要涉及到系统调用sbrk,频繁的malloc和free会消耗系统资源。
既然如此,我们就预先在用户态创建一个缓存空间,作为内存池。
每次malloc的时候,从用户态的内存池中获得分配的内存,不走系统调用,就能像赛车加氮气一样超级加速内存管理。
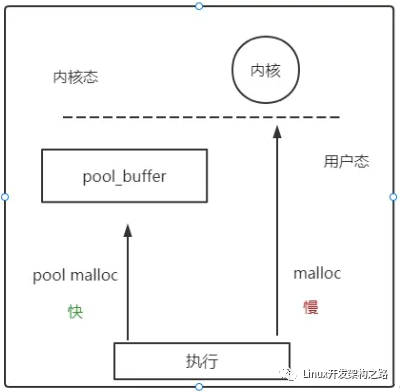
2.如果频繁地malloc和free,由于malloc的地址是不确定的,因为每次malloc的时候,会先在freelist中找一个适合其大小的块,如果找不到,才会调用sbrk直接拓展堆的内存边界。(freelist是之前free掉的内存,内核会将其组织成一个链表,留待下次malloc的时候查找使用。)
因为不确定,所以容易产生内存碎片。

如果我们需要4个字节的空间,却因为malloc的位置随机分配在这个滑稽的位置,就导致虽然我们有2+2的空间但是只能望洋兴叹的尴尬处境。
Nginx内存池的特点
nginx中线程池与内存池都是池,核心思想都是对系统的资源调度起一个缓冲的作用,但是多少还是有点区别。
对于线程池来说,两队列+中枢的架构,在不同公司的框架实现都大同小异。
但是内存池却是在不同的框架中,实现不尽相同。
为什么会有区别,根本原因是面向的实际业务不同,从而导致不同公司的内存池会灵活变通,有各自鲜明的特点。
在Nginx的服务器中,每当有一个客户端connect进来后,就会为其单独创建一个内存池,用于recv和send的缓冲区buffer。
所以Nginx的内存池的特点是,其包含了两种内存分配方式,大内存和小内存使用不同的数据结构来存储。从而适应客户端不同的请求,如果只是一些简单的表单,就用小内存,如果是上传下载大文件,就用大内存。
同时Nginx的内存池还有一个重要的特点:不像线程池会回收利用所有线程,Nginx的内存池不回收小内存的buffer,只回收大内存的buffer。
同样是出于实际业务的考虑,每个内存池都对应一个客户,那么一个客户端产生的小内存碎片自然不会太多,即使不回收,也不会有太大代价。
同时tcp本身就有keep-alive机制,超过一定时间就断开,Nginx是典型的将不同客户端分发到多进程的网络模型,连接断开,进程结束,从而对应的内存池会释放,相当于一次性回收所有的大小内存。
但是在连接中大内存因为占用空间大,Nginx觉得还是有必要回收,所以只做了回收大内存这个接口。
数据结构
我们先讲核心的,小内存的实现。
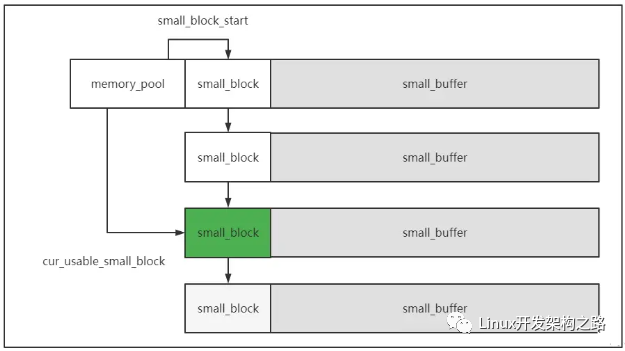
首先整个内存池pool中有两条链,一条是big block链,一条是small block链。
一个small block我们可以看做是一个小缓冲区,而整条链的小缓冲区串起来组成一个大缓冲区,就是内存池了。
small block数据结构如下:
public:
char * cur_usable_buffer;
char * buffer_end;
small_block * next_block;
int no_enough_times;
};
- cur_usable_buffer:指向该block的可用buffer的首地址
- buffer_end:指向该block的buffer的结尾地址
- next_block: 指向block链的下一个small block
- no_enough_times:每次分配内存,都要顺着small block链,找链中的每个小缓冲区看是否有足够分配的内存,如果在该block没找到,就会将该值+1,代表没有足够空间命中的次数。
对于small block,我们看它的格局要更上层一点,达到看山不是山,看水不是水的境界,因为它不仅仅是单独的block对象,还代表了后面跟着的buffer,当链中所有小缓冲区都不够位置分配新的空间时,就会创建新的small block,而创建的时候,会一次性创建small_block+buffer_capacity大小的空间。
为什么要这么设置,而不是先malloc一个small_block,再malloc一个small_buffer,别问,问就是不优雅,像这样分配内存,相当于两个连在一起形成一个整块,很舒适,适合强迫症,而不是东一块随机地址,西一块随机地址,那还叫池吗?干脆叫地下水管道吧,一堆支流。
我们不需要在small_block的数据结构中存buffer的首地址指针,因为很自然的是,我们拿到small_block的指针后自然也就拿到了buffer的首地址指针
即 buffer_head_ptr = (char*)small_block + sizeof(small_block);
small_block中各指针的指向:

然后是整个内存池pool的数据结构
public:
size_t small_buffer_capacity;
small_block * cur_usable_small_block;
big_block * big_block_start;
small_block small_block_start[0];
//-----------------------------上面是成员,下面是api--------------------------------------------
static memory_pool * createPool(size_t capacity);
static void destroyPool(memory_pool * pool);
static char* createNewSmallBlock(memory_pool * pool,size_t size);
static char* mallocBigBlock(memory_pool * pool,size_t size);
static void* poolMalloc(memory_pool * pool,size_t size);
static void freeBigBlock(memory_pool * pool, char *buffer_ptr);
};
- small_buffer_capacity:对于Nginx的内存池,每个small buffer的大小都是一样的,所以该值代表了small buffer的容量,在创建内存池的时候作为参数确定。
- cur_usable_small_block:每次要分配小内存的时候,并不会从头开始找合适的空间,而是从这个指针指向的small_block开始找。
- big_block_start:big block链的链头
- small_block_start:small block的链头。
这里要提一点的是,该类的最后一个成员small_block_start,其为一个长度为0的数组,这在C99中是一种柔性数组的写法,所以比较吃编译器,我是在linux环境下编译,没什么问题,但是vs环境可能会报错,如果报错就设置长度为1。
为什么要这么设置,后面讲第一个api createPool 的时候会说。
还有全员使用静态成员方法也是与此有关,因为Nginx是纯C写的,我使用静态成员方法也是一种兼容C的面向过程函数的变种吧(笑~)。
最后是big block的数据结构
public:
char * big_buffer;
big_block * next_block;
};
- big_buffer:大内存buffer的首地址
- next_block:因为big block也是链式结构,指向下一个big block
big block最简单,因为Nginx似乎不在乎big block优不优雅了,其big_block和big_buffer的地址就是分开的,不会连在一起。

接口实现
创建内存池 createPool:
这里需要再次提到刚刚的柔性数组,small_block_start
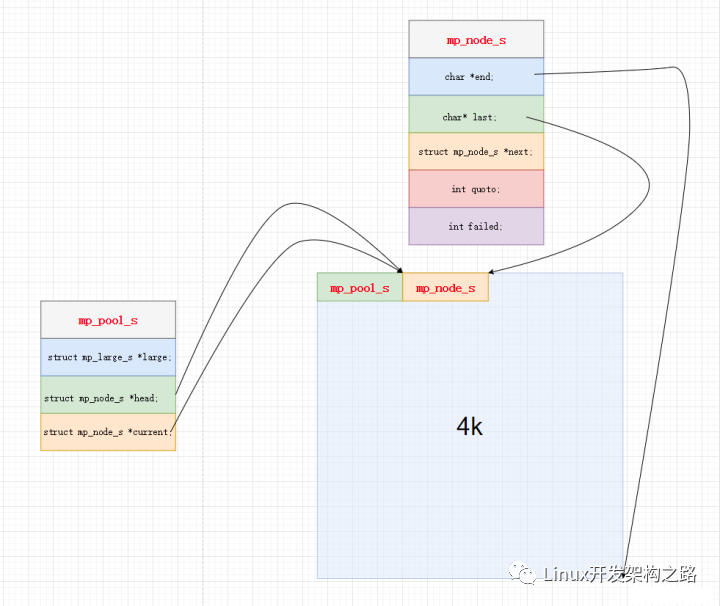
Nginx希望创建内存池pool的时候,不是单独一个孤零零的pool对象,而是创建pool的同时,就创建第一个small_block,而创建一个新的small_block又需要同步建立一个small_buffer,而Nginx希望这三个对象的内存是连起来的,如图所示,于是优雅再次出现。
柔性数组的意义在于,我们希望在memory_pool保留一个指针锚点来指向第一个small_block而不是通过刚刚的指针加法来找到small_block的首地址,那便使用一个0长度的数组作为这个锚点。
这样malloc整段内存,small_block就会接在memory_pool的后面,且以small_block_start的形式成为pool的成员,实际上small_block_start长度为0是不占pool的内存空间的。
而为什么使用静态成员函数也是这个原因,使用柔性数组必须保证其位置定义在整个类的内存空间的末尾,静态函数虽然在类中声明,但是实际会存放在静态区中保存,不占用类的内存。
//-创建内存池并初始化,api以静态成员(工厂)的方式模拟C风格函数实现
//-capacity是buffer的容量,在初始化的时候确定,后续所有小块的buffer都是这个大小
memory_pool * memory_pool::createPool(size_t capacity){//-我们先分配一大段连续内存,该内存可以想象成这段内存由pool+small_block+small_block_buffers三个部分组成.
//-为什么要把三个部分(可以理解为三个对象)用连续内存来存,因为这样整个池看起来比较优雅.各部分地址不会天女散花地落在内存的各个角落.
size_t total_size = sizeof(memory_pool)+sizeof(small_block)+capacity;
void *temp = malloc(total_size);
memset(temp,0,total_size);
memory_pool * pool = (memory_pool*)temp;
fprintf(stdout,"pool address:%pn",pool);
//-此时temp是pool的指针,先来初始化pool对象
pool ->small_buffer_capacity = capacity;
pool ->big_block_start = nullptr;
pool ->cur_usable_small_block = (small_block*)(pool->small_block_start);
//-pool+1的1是整个memory_pool的步长,别弄错了。此时sbp是small_block的指针
small_block * sbp = (small_block*)(pool+1);
fprintf(stdout,"first small block address:%pn",sbp);
//-初始化small_block对象
sbp -> cur_usable_buffer = (char*)(sbp+1);
fprintf(stdout,"first small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = sbp->cur_usable_buffer+capacity;//-第一个可用的buffer就是开头,所以end=开头+capacity
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
return pool;
};
代替malloc的分配内存的接口:poolMalloc
第一步,我们判断poolMalloc的size是一个大内存还是小内存。
如果是大内存就走mallocBigBlock这个api。
如果是小内存,就从cur_usable_small_block这个small block开始找足够的空间去分配内存,注意并不是从small block链的开头开始寻找。因为大概率cur_usable_small_block之前的所有small block都已经分配完了,所以为了提高命中效率,需要这样一个指针指向寻找的开始。
对于每个small block,我们直接用buffer_end 和 cur_usable_buffer相减就可以得到一个small buffer的剩余容量去判断是否能分配。

如果空间足够,就从cur_usable_buffer开始分配size大小的空间,并返回这段空间的首地址,同时更新cur_usable_buffer指向新的剩余空间。
如果直到链的末尾都没有足够的size大小的空间,那就需要创建新的small block,走createNewSmallBlock这个api。
void* memory_pool::poolMalloc(memory_pool * pool,size_t size){
//-先判断要malloc的是大内存还是小内存
if(sizesmall_buffer_capacity){//-如果是小内存
//-从cur small block开始寻找
small_block * temp = pool -> cur_usable_small_block;
do{
//-判断当前small block的buffer够不够分配
//-如果够分配,直接返回
if(temp->buffer_end-temp->cur_usable_buffer>size){
char * res = temp->cur_usable_buffer;
temp -> cur_usable_buffer = temp->cur_usable_buffer+size;
return res;
}
temp = temp->next_block;
}while (temp);
//-如果最后一个small block都不够分配,则创建新的small block;
//-该small block在创建后,直接预先分配size大小的空间,所以返回即可.
return createNewSmallBlock(pool,size);
}
//-分配大内存
return mallocBigBlock(pool,size);
}
创建新的小内存块:createNewSmallBlock
首先创建一个smallblock和连带的buffer,还是如这张图所示:

因为我们创建的目的是为了分配size空间,所以初始化后,便预留size大小的buffer,对cur_usable_buffer进行更新。
值得提的是,每次到了创建新的small block的环节,就意味着目前链上的small buffer空间已经都分配得差不多了,可能需要更新cur_usable_small_block,这就需要用到small block的no_enough_times成员,将cur_usable_small_block开始的每个small block的该值++,Nginx设置的经验值阈值是4,超过4,意味着该block不适合再成为寻找的开始了,需要往后继续尝试。
char* memory_pool::createNewSmallBlock(memory_pool * pool,size_t size){
//-先创建新的small block,注意还有buffer
size_t malloc_size = sizeof(small_block)+pool->small_buffer_capacity;
void * temp = malloc(malloc_size);
memset(temp,0,malloc_size);
//-初始化新的small block
small_block * sbp = (small_block *)temp;
fprintf(stdout,"new small block address:%pn",sbp);
sbp -> cur_usable_buffer = (char*)(sbp+1);//-跨越一个small_block的步长
fprintf(stdout,"new small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = (char*)temp+malloc_size;
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
//-预留size空间给新分配的内存
char* res = sbp -> cur_usable_buffer;//-存个副本作为返回值
sbp -> cur_usable_buffer = res+size;
//-因为目前的所有small_block都没有足够的空间了。
//-意味着可能需要更新线程池的cur_usable_small_block,也就是寻找的起点
small_block * p = pool -> cur_usable_small_block;
while(p->next_block){
if(p->no_enough_times>4){
pool -> cur_usable_small_block = p->next_block;
}
++(p->no_enough_times);
p = p->next_block;
}
//-此时p正好指向当前pool中最后一个small_block,将新节点接上去。
p->next_block = sbp;
//-因为最后一个block有可能no_enough_times>4导致cur_usable_small_block更新成nullptr
//-所以还要判断一下
if(pool -> cur_usable_small_block == nullptr){
pool -> cur_usable_small_block = sbp;
}
return res;//-返回新分配内存的首地址
}
分配大内存空间:mallocBigBlock
如果size超过了预设的capacity,那就会走这个api。
其同样也是一个链式查找的过程,只不过比查找small block更快更粗暴。
big block链没有类似cur_usable_small_block这样的节点,只要从头开始遍历,如果有空buffer就返回该block,如果超过3个还没找到(同样是Nginx的经验值)就直接不找了,创建新的big block。
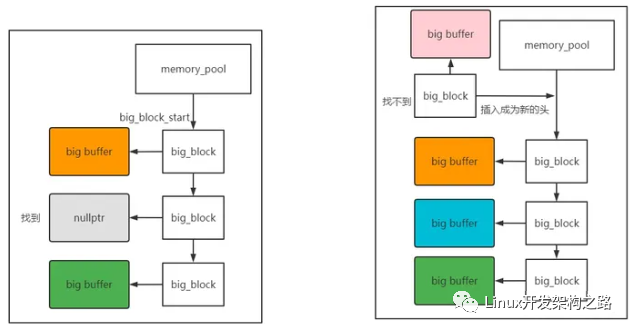
还有一点值得注意的是,big_buffer是个大内存,所以其是个malloc的随机地址,
但是big_block本身是一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。
所以这里有个套娃的内存池poolMalloc操作,用来分配big_block的空间。
char* memory_pool::mallocBigBlock(memory_pool * pool,size_t size){
//-先分配size大小的空间
void*temp = malloc(size);
memset(temp, 0, size);
//-从big_block_start开始寻找,注意big block是一个栈式链,插入新元素是插入到头结点的位置。
big_block * bbp = pool->big_block_start;
int i = 0;
while(bbp){
if(bbp->big_buffer == nullptr){
bbp->big_buffer = (char*)temp;
return bbp->big_buffer;
}
if(i>3){
break;//-为了保证效率,如果找三轮还没找到有空buffer的big_block,就直接建立新的big_block
}
bbp = bbp->next_block;
++i;
}
//-创建新的big_block,这里比较难懂的点,就是Nginx觉得big_block的buffer虽然是一个随机地址的大内存
//-但是big_block本身算一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。
//-所以这里有个套娃的内存池malloc操作
big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));
//-初始化
new_bbp -> big_buffer = (char*)temp;
new_bbp ->next_block = pool->big_block_start;
pool -> big_block_start = new_bbp;
//-返回分配内存的首地址
return new_bbp->big_buffer;
}
释放大内存:freeBigBlock:
由于big block是一个链式结构,所以要找到对应的buffer并free掉,就需要从这个链的开头开始遍历,一直到找到位置。
void memory_pool::freeBigBlock(memory_pool * pool, char *buffer_ptr){
big_block* bbp = pool -> big_block_start;
while(bbp){
if(bbp->big_buffer == buffer_ptr){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
return;
}
bbp = bbp->next_block;
}
}
销毁线程池:destroyPool:
这个思路也很简单,pool中有两条链分别指向大内存和小内存,那么分别沿着这两条链去free掉内存即可,由于大内存的buffer和big block不是一起malloc的,所以只需要free掉buffer,而big block是分配在小内存池中的,所以,之后free掉小内存的时候会顺带一起free掉。
比较值得注意的一点是,small链的free不是从第一个small block开始的,而是第二个small block。如图所示,第一个small block的空间是和pool一起malloc出来的,不需要free,只要最后的时候free pool就会一起释放掉。

void memory_pool::destroyPool(memory_pool * pool){
//-销毁大内存
big_block * bbp = pool->big_block_start;while(bbp){
if(bbp->big_buffer){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
}
bbp = bbp->next_block;
}
//-为什么不删除big_block节点?因为big_block在小内存池中,等会就和小内存池一起销毁了
//-销毁小内存
small_block * temp = pool -> small_block_start->next_block;
while(temp){
small_block * next = temp -> next_block;
free(temp);
temp = next;
}
free(pool);
}
测试代码
测试一下用内存池分配的地址是否如我们所设计的那样。
memory_pool * pool = memory_pool::createPool(1024);
//-分配小内存
char*p1 = (char*)memory_pool::poolMalloc(pool,2);
fprintf(stdout,"little malloc1:%pn",p1);
char*p2 = (char*)memory_pool::poolMalloc(pool,4);
fprintf(stdout,"little malloc2:%pn",p2);
char*p3 = (char*)memory_pool::poolMalloc(pool,8);
fprintf(stdout,"little malloc3:%pn",p3);
char*p4 = (char*)memory_pool::poolMalloc(pool,256);
fprintf(stdout,"little malloc4:%pn",p4);
char*p5 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc5:%pn",p5);
//-测试分配不足开辟新的small block
char*p6 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc6:%pn",p6);
//-测试分配大内存
char*p7 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc1:%pn",p7);
char*p8 = (char*)memory_pool::poolMalloc(pool,4096);
fprintf(stdout,"big malloc2:%pn",p8);
//-测试free大内存
memory_pool::freeBigBlock(pool, p8);
//-测试再次分配大内存(我这里测试结果和p8一样)
char*p9 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc3:%pn",p9);
//-销毁内存池
memory_pool::destroyPool(pool);
exit(EXIT_SUCCESS);
}
完整代码
// * 修改了很多nginx中晦涩的变量名,比较容易理解
#include
#include
#include
using namespace std;
class small_block{
public:
char * cur_usable_buffer;
char * buffer_end;
small_block * next_block;
int no_enough_times;
};
class big_block{
public:
char * big_buffer;
big_block * next_block;
};
class memory_pool{
public:
size_t small_buffer_capacity;
small_block * cur_usable_small_block;
big_block * big_block_start;
small_block small_block_start[0];
static memory_pool * createPool(size_t capacity);
static void destroyPool(memory_pool * pool);
static char* createNewSmallBlock(memory_pool * pool,size_t size);
static char* mallocBigBlock(memory_pool * pool,size_t size);
static void* poolMalloc(memory_pool * pool,size_t size);
static void freeBigBlock(memory_pool * pool, char *buffer_ptr);
};
//-创建内存池并初始化,api以静态成员(工厂)的方式模拟C风格函数实现
//-capacity是buffer的容量,在初始化的时候确定,后续所有小块的buffer都是这个大小
memory_pool * memory_pool::createPool(size_t capacity){
//-我们先分配一大段连续内存,该内存可以想象成这段内存由pool+small_block+small_block_buffers三个部分组成.
//-为什么要把三个部分(可以理解为三个对象)用连续内存来存,因为这样整个池看起来比较优雅.各部分地址不会天女散花地落在内存的各个角落.
size_t total_size = sizeof(memory_pool)+sizeof(small_block)+capacity;
void *temp = malloc(total_size);
memset(temp,0,total_size);
memory_pool * pool = (memory_pool*)temp;
fprintf(stdout,"pool address:%pn",pool);
//-此时temp是pool的指针,先来初始化pool对象
pool ->small_buffer_capacity = capacity;
pool ->big_block_start = nullptr;
pool ->cur_usable_small_block = (small_block*)(pool->small_block_start);
//-pool+1的1是整个memory_pool的步长,别弄错了。此时sbp是small_block的指针
small_block * sbp = (small_block*)(pool+1);
fprintf(stdout,"first small block address:%pn",sbp);
//-初始化small_block对象
sbp -> cur_usable_buffer = (char*)(sbp+1);
fprintf(stdout,"first small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = sbp->cur_usable_buffer+capacity;//-第一个可用的buffer就是开头,所以end=开头+capacity
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
return pool;
};
//-销毁内存池
void memory_pool::destroyPool(memory_pool * pool){
//-销毁大内存
big_block * bbp = pool->big_block_start;
while(bbp){
if(bbp->big_buffer){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
}
bbp = bbp->next_block;
}
//-为什么不删除big_block节点?因为big_block在小内存池中,等会就和小内存池一起销毁了
//-销毁小内存
small_block * temp = pool -> small_block_start->next_block;
while(temp){
small_block * next = temp -> next_block;
free(temp);
temp = next;
}
free(pool);
}
//-当所有small block都没有足够空间分配,则创建新的small block并分配size空间,返回分配空间的首指针
char* memory_pool::createNewSmallBlock(memory_pool * pool,size_t size){
//-先创建新的small block,注意还有buffer
size_t malloc_size = sizeof(small_block)+pool->small_buffer_capacity;
void * temp = malloc(malloc_size);
memset(temp,0,malloc_size);
//-初始化新的small block
small_block * sbp = (small_block *)temp;
fprintf(stdout,"new small block address:%pn",sbp);
sbp -> cur_usable_buffer = (char*)(sbp+1);//-跨越一个small_block的步长
fprintf(stdout,"new small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = (char*)temp+malloc_size;
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
//-预留size空间给新分配的内存
char* res = sbp -> cur_usable_buffer;//-存个副本作为返回值
sbp -> cur_usable_buffer = res+size;
//-因为目前的所有small_block都没有足够的空间了。
//-意味着可能需要更新线程池的cur_usable_small_block,也就是寻找的起点
small_block * p = pool -> cur_usable_small_block;
while(p->next_block){
if(p->no_enough_times>4){
pool -> cur_usable_small_block = p->next_block;
}
++(p->no_enough_times);
p = p->next_block;
}
//-此时p正好指向当前pool中最后一个small_block,将新节点接上去。
p->next_block = sbp;
//-因为最后一个block有可能no_enough_times>4导致cur_usable_small_block更新成nullptr
//-所以还要判断一下
if(pool -> cur_usable_small_block == nullptr){
pool -> cur_usable_small_block = sbp;
}
return res;//-返回新分配内存的首地址
}
//-分配大块的内存
char* memory_pool::mallocBigBlock(memory_pool * pool,size_t size){
//-先分配size大小的空间
void*temp = malloc(size);
memset(temp, 0, size);
//-从big_block_start开始寻找,注意big block是一个栈式链,插入新元素是插入到头结点的位置。
big_block * bbp = pool->big_block_start;
int i = 0;
while(bbp){
if(bbp->big_buffer == nullptr){
bbp->big_buffer = (char*)temp;
return bbp->big_buffer;
}
if(i>3){
break;//-为了保证效率,如果找三轮还没找到有空buffer的big_block,就直接建立新的big_block
}
bbp = bbp->next_block;
++i;
}
//-创建新的big_block,这里比较难懂的点,就是Nginx觉得big_block的buffer虽然是一个随机地址的大内存
//-但是big_block本身算一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。
//-所以这里有个套娃的内存池malloc操作
big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));
//-初始化
new_bbp -> big_buffer = (char*)temp;
new_bbp ->next_block = pool->big_block_start;
pool -> big_block_start = new_bbp;
//-返回分配内存的首地址
return new_bbp->big_buffer;
}
//-分配内存
void* memory_pool::poolMalloc(memory_pool * pool,size_t size){
//-先判断要malloc的是大内存还是小内存
if(sizesmall_buffer_capacity){//-如果是小内存
//-从cur small block开始寻找
small_block * temp = pool -> cur_usable_small_block;
do{
//-判断当前small block的buffer够不够分配
//-如果够分配,直接返回
if(temp->buffer_end-temp->cur_usable_buffer>size){
char * res = temp->cur_usable_buffer;
temp -> cur_usable_buffer = temp->cur_usable_buffer+size;
return res;
}
temp = temp->next_block;
}while (temp);
//-如果最后一个small block都不够分配,则创建新的small block;
//-该small block在创建后,直接预先分配size大小的空间,所以返回即可.
return createNewSmallBlock(pool,size);
}
//-分配大内存
return mallocBigBlock(pool,size);
}
//-释放大内存的buffer,由于是一个链表,所以,确实,这是效率最低的一个api了
void memory_pool::freeBigBlock(memory_pool * pool, char *buffer_ptr){
big_block* bbp = pool -> big_block_start;
while(bbp){
if(bbp->big_buffer == buffer_ptr){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
return;
}
bbp = bbp->next_block;
}
}
int main(){
memory_pool * pool = memory_pool::createPool(1024);
//-分配小内存
char*p1 = (char*)memory_pool::poolMalloc(pool,2);
fprintf(stdout,"little malloc1:%pn",p1);
char*p2 = (char*)memory_pool::poolMalloc(pool,4);
fprintf(stdout,"little malloc2:%pn",p2);
char*p3 = (char*)memory_pool::poolMalloc(pool,8);
fprintf(stdout,"little malloc3:%pn",p3);
char*p4 = (char*)memory_pool::poolMalloc(pool,256);
fprintf(stdout,"little malloc4:%pn",p4);
char*p5 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc5:%pn",p5);
//-测试分配不足开辟新的small block
char*p6 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc6:%pn",p6);
//-测试分配大内存
char*p7 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc1:%pn",p7);
char*p8 = (char*)memory_pool::poolMalloc(pool,4096);
fprintf(stdout,"big malloc2:%pn",p8);
//-测试free大内存
memory_pool::freeBigBlock(pool, p8);
//-测试再次分配大内存(我这里测试结果和p8一样)
char*p9 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc3:%pn",p9);
//-销毁内存池
memory_pool::destroyPool(pool);
exit(EXIT_SUCCESS);
}
-
内存
+关注
关注
9文章
3231浏览量
76496 -
缓存
+关注
关注
1文章
248浏览量
27807 -
源码
+关注
关注
8文章
689浏览量
31457 -
nginx
+关注
关注
0文章
193浏览量
13203
发布评论请先 登录
详解内存池技术的原理与实现
C++内存池的设计与实现
数据全复用高性能池化层设计思路分享
采用GDDR6的高性能内存解决方案
Linux下一种高性能定时器池的实现
什么是内存池

内存池主要解决的问题



评论