 关于数字处理技术部分的路线图介绍
关于数字处理技术部分的路线图介绍

早段时间,美国SIA和SRC发布一份半导体未来发展路线图。本章节是路线图中关于数字处理技术部分的路线图介绍译文,现在分享给读者。
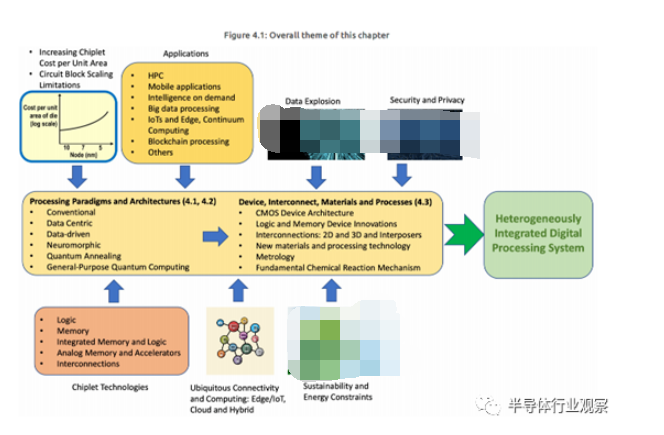
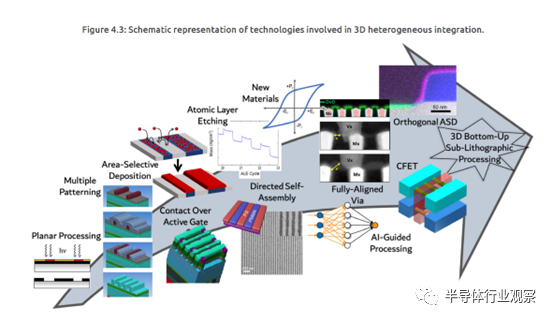
数字处理的路线图审视了数字处理的当前和新兴驱动因素,以及处理范式中所需的创新。这些要求决定了数字处理、存储芯片、支持芯粒、互连和整个系统架构所必需的技术和体系结构。反过来,芯粒和互连体系结构定义了设备、互连以及化学和化学加工技术的要求。化学加工需要深入了解物理和化学反应机制,以便将其整合到产品中。数字处理章节还规定了系统级集成数字处理系统所需的附加要求和解决方案,以及与整体安全性、电源转换/传递、系统可靠性和运行时管理需求相关的系统级考虑,这些内容在路线图的其他章节中讨论。图4.1描述了本章的整体主题。
01.主要障碍和挑战
在实现异构集成数字处理系统方面,需要解决一些障碍和挑战:
1. 随着数据的数量和速率呈指数增长,处理数据的移动成本问题,包括性能(延迟和带宽)、每传输一比特的端到端能量消耗。
2. 限制系统级别的总能耗,并大幅提高数字处理系统作为整体的能效,以处理数据激增和必要的数据处理。
3. 解决当前使用的体系结构以及由总功耗、功耗分配、插板和互连所引入的系统内封装(SiPs)的规模限制。
4.改进对未来设备制造的物理和化学过程的基本理解,包括先进的图案形成、原子尺度薄膜沉积、蚀刻、区域选择性沉积和其他选择性材料处理。 5.解决对异构集成数字处理系统安全性和可靠性不断增长的需求,包括监测和解读所有必要信息,以确保安全和可靠的运行。
6.解决和改善端到端的可持续性,涵盖预设计、设计、制造、使用以及最终处理/回收。
7.提供高级设计工具,允许将功能分解为多芯片片体系结构,同时优化多个参数;大型设计空间中的优化所带来的挑战,需要基于机器学习的解决方案。
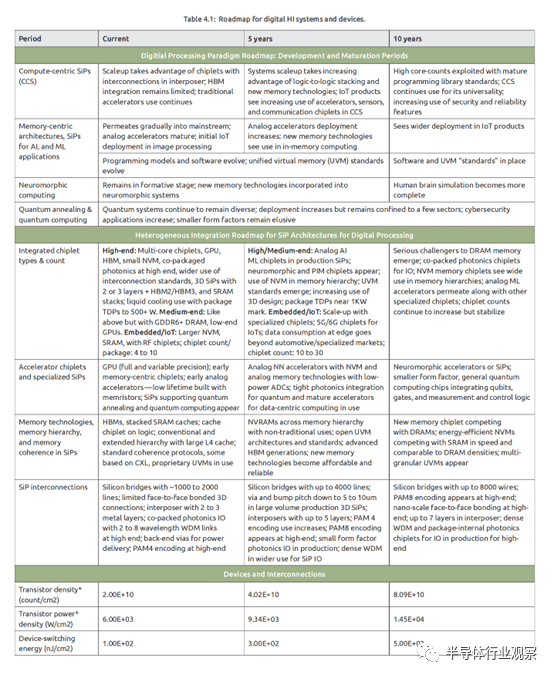
第4.1节讨论了应用需求如何推动数据处理范式,而第4.2节讨论了系统级别的架构影响、相关挑战、实施和技术需求。第4.3节将系统级架构需求具体细化到在设备、互连、材料和化学处理方面的挑战,以及有前景的解决方案。数字处理范式、系统级架构以及数字处理设备/材料的路线图如表4.1所示。
01.4.1节—应用、数字处理范式和硬件-软件(HW-SW)协同设计
这一部分确定了最迫切和突出的应用和市场驱动的设计需求。其中一些应用需求也指出了当前数据处理体系结构的不足,因此本节还涵盖了数字处理范式的演变。最后,软硬件协同设计强调了在不同系统设计层面的协同方式以满足功耗和性能需求的必要性。
4.1.1 应用
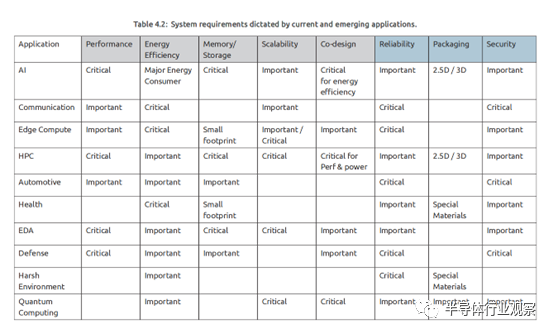
正如第1章所详述的那样,各种广泛的应用将推动半导体路线图的制定,对性能、能效、安全性、可靠性、可扩展性、存储和互连等方面有多种不同的要求。例如,高性能计算(HPC)和人工智能(AI)强调大规模计算和存储,而物联网(IoT)应用则更加地关注在能量、计算和存储方面的限制。上文表4.2概括了这些各种应用的关键和重要需求。 需要注意的是,人工智能应用涵盖了生成式人工智能应用的重要子类,其中大型数据集推动了学习步骤,使得能够基于从训练数据集中学到的模式生成合成数据。特别是,生成式人工智能应用加剧了对存储容量、能耗和处理能力的需求。 本章重点关注数字技术,从系统架构到设备,涵盖了这些应用的一些核心需求,包括数字处理范式、硬件-软件协同设计、能效高性能的计算和存储架构,以及设备和材料加工技术。其他一些应用需求,比如可靠性、封装和安全性,将在其他章节中讨论。
4.1.2 数字处理范式
当基于CPU的处理平台无法满足特定应用的计算/能效/存储效率要求时,一般的方法是从标准计算转向定制计算解决方案,比如定制处理器或硬件加速器。 为了改善这些应用的计算能效和性能,有必要探索新的计算范式,以超越当前主流计算中心范式。 以下计算范式发展前景大、具有特定的应用:
1. 计算中心范式(Compute-centric):大多数当前的计算架构主要关注:计算单元、存储单元和用于支持计算结构的互连。应用处理的效率通过利用计算的特性来解决,例如指令(CPU、DSP、ASIP)、指令级并行性(标量、超标量、VLIW)和任务级并行性(多核、异构架构)。
2. 数据驱动架构(Data-driven architectures):大量应用涉及大规模数据处理,开始将焦点从计算转移到存储,因为有大量能量花费在存储和互连上。为了提高性能和能源的整体效率,新的存储设备和架构正在发展。
3. 存储中心范式(Memory-centric:):随着数据密集型应用中存储和计算的成本(性能和功耗)继续倾向于存储(称为“存储墙”),越来越多的架构倾向于将计算资源放置在靠近数据的位置,如存内计算和近存计算。
4. 随机计算(Stochastic computing):目前的计算范式处理和存储信息的精度是以数字(8、32、64位)表示的。数值数据的处理具有计算成本,在大量不强制要求数字精度的应用中,将信息以概率数据形式存储,并采用相关简化的计算,可以显著提高能效。
5. 认知计算(Cognitive computing):与随机计算类似,信息也可以用大型随机向量来存储和处理,这被超维度计算所利用。对于人工智能系统而言,这种计算范式在网络架构、学习的能源效率、推理和噪声/误差容忍度方面有很多优势。用大型随机向量表示符号数据也能实现多层次的认知计算。
6. 神经形态计算(Neuromorphic computing):这是受脑启发的计算范式,包括基于神经元和突触的集成记忆和计算架构。通过事件驱动/异步计算和通信(如脉冲神经网络),提高了能源效率。 7. 量子退火和量子计算(Quantum annealing and quantum computing):传统计算以位存储信息,并通过算术进行计算,而量子计算以多维状态(量子位)存储信息,并利用量子位的叠加和干涉来为大型复杂问题提供指数级的计算能力增长。
4.1.3 软硬件协同设计
这种硬件-软件协同设计的描述主要聚焦于高性能计算(HPC)用例,因为HPC社区愿意投资开发硬件和软件。自三十年前大规模并行处理器(MPP)架构问世以来,HPC转向了利用商用现成计算技术的策略,例如X86微处理器和通用DRAM内存。这标志着定制设计的Cray Vector HPC系统的终结。随着丹纳德比例的终结和摩尔定律的放缓,MPP策略仍然存在,但近20年来的重点转向了使用带有通用处理器(COTS CPUs)的计算节点,搭配执行大部分双精度浮点运算的图形加速器。Exascale Computing Project建立了与处理器和系统公司合作的架构研发项目,以支持协同设计合作,从而带来了新的硬件和软件能力,用于异构CPU-GPU HPC,并扩展以支持科学机器学习。正如在第4.2.2节所描述的那样,性能是HPC社区的主要目标。从TeraFlop到PetaFlop的性能提升导致的功耗增加了2.8倍,最近从PetaFlop到ExaFlop的性能提升导致的功耗增加了9.0倍,可持续性较差。 未来HPC和计算性能的进步将需要一种全面的协同设计方法,以在真实工作负载上实现能效计算性能的显著增长。
对真实应用性能测量的转变为异构处理器提供了动力,它将领域专门化的加速器与通用处理器、先进的内存和网络接口整合在一起。这些HPC驱动因素的融合与CHIPS和Science Act的目标一致,旨在为硬件原型开发、芯粒的先进封装和3D异构集成创造基础设施和生态系统。微电子共同体的发展旨在使ASIC设计工具更加民主化,并且新兴的芯粒集成标准都支持不断发展的芯片片市场。这些持续的需求和市场趋势将需要更广泛、更深入地能够同时考虑系统软件栈和硬件。这是深层次的协同设计,算法和架构一起设计,以开发最佳解决方案。
在未来十年中,高性能计算(HPC)的能效性能驱动因素将与许多计算领域的共同需求相一致,需要有能力将处理器、存储技术、加速器和离散功能单元定制成异构计算设计。先进封装和基于芯粒技术标准的3D集成的出现,例如通用芯粒互连标准(UCIe),将支持它们融入异构处理器中。集成这些定制芯粒技术的工具将是这种能力的关键组成部分,并将涵盖从电路设计到布局设计,一直到全系统仿真。这些硬件设计工具需要与性能分析工具同时应用,以更好地理解应用程序及其算法。这将实现对硬件技术设计的快速探索和评估,并对应用程序的变化进行优化,以在复杂的权衡(性能、功耗效率、易移植性、设计和制造成本、总体拥有成本)中实现解决方案的优化。
人工智能无疑将在这个领域发挥作用,多个学术和工业倡议已经将人工智能纳入其设计和优化周期。 除了对综合设计空间进行推理的工具之外,还需要从软件到集成电路高效地塑造未来技术。异构计算系统软件将需要在软件框架、编译器技术、运行时和操作系统方面不断取得进步。从硬件技术的角度来看,这将需要用于ASIC设计、SoC设计、存储子系统设计的高生产力工具,以及多个异构芯粒组合互操作的能力。以不同的数字处理技术制造的个别组件将需要低成本、低功耗、高产出地无缝集成,这将需要在异构封装技术方面取得显著进步。粗粒度的可重构架构(CGRAs)和在分解架构中动态组合离散组件的能力将进一步扩展可能的协同设计空间;这将需要能够在应用运行时进行优化的工具,并跨并行运行的工作负载整合优化标准。虽然当前某些云计算环境面临这种复杂性的一些方面,但未来十年将会看到在更大范围和应用工作负载中的重构能力。
致力于实现这种更深层次协同设计的技术的研发对于我们国家战略计算工作负载的持续性能和能效的指数级增长至关重要。2023年4月,国家科学院发布了一份报告,概述了高性能计算的重要性、技术颠覆、市场生态颠覆,以及重新思考硬件和架构创新、软件、系统获取和云计算的作用。
03.4.2节—系统级架构
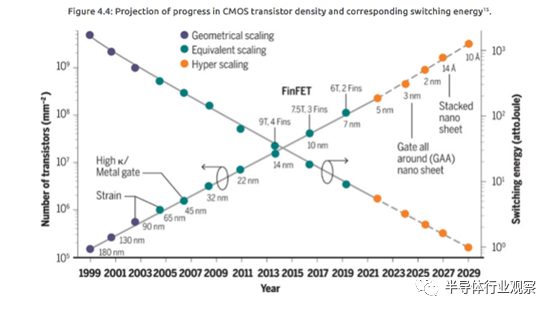
SRC的十年计划指出,数据容量和数据传输成本在处理系统中占据主导地位。在芯片规模上,芯粒花费在互连方面的能量比例已经在先进节点上大幅增长,如图4.2所示。封装内系统必须处理各个规模下的数据传输成本,无论是绝对功耗还是数据传输过程中每比特的能量消耗。
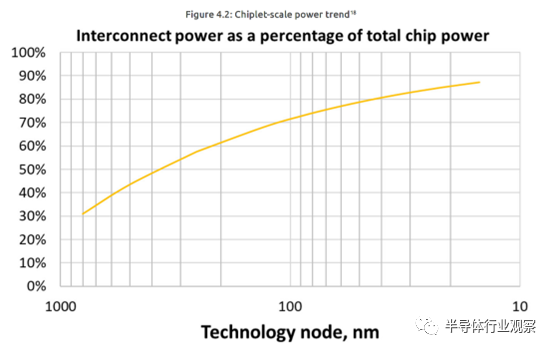
本章中所讨论的系统级架构技术在缓解数据传输成本方面显示出前景的潜在技术概述如下:
1. 近存处理。 2. 存内处理,涵盖开发具有嵌入式逻辑的合适内存设备。 3. 在互连接口内部的处理,例如在芯片内路由器中进行数据传输。 4. 3D芯粒堆叠架构,大幅减少芯粒间互连的距离。 5. 避免系统级数据移动的架构解决方案,比如广播方式。 6. 由于时钟信号在全局分布,相关的互连功耗(使用H树或类似的互连拓扑结构)需要解决。 在互连的层面上,下面列举了几种可能降低互连能耗的解决方案: 1. 使用许多芯粒集成技术中提供的重新分配层(RDLs),如CoWoS。 2. 在2D和3D配置中,使用短距离的时钟转发链接,避免需要用于时钟/数据恢复的面积和能耗较大的PLL和DLL。
3. 使用超出PAM 4的先进符号编码技术。 4. 使用能源管理链接,支持类似DVFS的模拟方法和其他技术。 5. 在封装级别IO应用光子学。从长远来看,这可能是解决芯粒间连接的一种方法,但非IO部署还需要进行重大的发展。 显然,发展互连标准以简化芯粒集成并发挥HI的全部潜力是必不可少的。标准正在不断演进(如BoW、ODSA、UCIe等),其他标准也可能会演进或基于主导标准构建,包括用于功耗分配、可靠性监测、安全监测和测试的标准。
SRC的十年计划显示,如果当前的芯片/系统设计趋势继续以预计的部署速度发展,系统功耗总体趋势将超过全球总发电量。为了解决这个改善能源效率的重大挑战,需要采用多种解决方案,包括以下方面: 1. 创新的存储技术,包括非易失性存储设备、模拟存储设备等。 2. 提高通用多核架构的能效。 3. 用更佳能效的专用功能加速器替换或增强通用处理解决方案。
4. 人工智能/机器学习(AI/ML)的首选处理引擎从传统的数字ML加速器(如GPU和GPU)转向更加能效的替代方案,尤其是模拟AI/ML加速器。 5. 神经形态计算可提供每单位能量的极致性能,超过传统基于晶体管的解决方案几个数量级。 6. 减少数据移动成本的系统架构创新。
4.2.1.存储技术 目标/需求:独立存储器材料和设备
需要方法来拓展当前主流的独立存储器、DRAM和NAND闪存技术,同时使“新兴”存储器得以出现和发明/发现新型存储器可能性。
障碍/挑战
DRAM的进一步缩放受到需要大量空间容纳电容器的阻碍,因此通过层叠(同质集成)的3D器件堆叠,类似于3D NAND的做法,对于持续提高密度有很大的帮助。3D同质DRAM的一个主要障碍在于它需要具有适当驱动特性和极低泄漏的BEOL兼容选择器件,这一点尚未实现。在3D NAND中持续的层叠需要刻蚀技术的进步和更薄的材料(朝向2D),尤其是通道。对于DRAM和NAND,需要新的封装架构方案和支持芯片堆叠(3D HI)的技术,超越当前的HBM方法。
新兴存储器依然“新兴”,目前还没有任何具备取代DRAM和NAND Flash在大规模独立实施中所需属性的存储器。新兴存储器必须克服各自已知的缺陷,以在成本、缩放、可靠性、变异性、重复性、循环性等指标方面与这些主流存储器竞争。在解决新兴存储器的不足方面做了很多工作(如各种类型的ReRAM、PCRAM、MRAM和FERAM),但还没有取得整体性的成功。如果没有整体的设备竞争力,这些技术将被限制在较小规模的细分领域实施,例如MRAM作为非易失性SRAM替代品和FERAM作为相对快速和低电压的非易失性存储器。
对于整个存储器空间,尚未建立或甚至设想的革命性新应用平台(如新的AI架构、新型消费设备,甚至在新领域中的DRAM和/或NAND)可以促使新兴存储器出现。因此,新的技术机会和重叠部分应继续受到关注。独立存储器空间中未曾预见到的机会可能通过朝向减轻耗能、计算至存储器互连瓶颈(所谓的“内存墙”)的新架构的演变而展现。
可能的解决方案
对于任何存储器和/或选择器件的材料和器件解决方案,必须全面了解许多目标性能指标和集成挑战,这些能够使设备成为对当前存储器的潜在替代品或补充品。 材料和器件的发展必须与建模(第一原理、传输、多物理等)同步进行,以指导开发和实施。新的架构和技术空间有助于消除当前路线图问题,可能会为已建立的和/或新兴存储器技术开启新机会。
对于扩大主流存储器技术(3D NAND存储器和3D DRAM)的性能和能源效率,以及采用新兴存储器技术(ReRAM、PCRAM、MRAM和FERAM(包括FeFET和FTJ存储器)的需求列举如下;新型存储器技术的可取之处和趋势、类模拟的存储器设备和其他存储器也在下面列举: 主流存储器 3D NAND:扩大需要更薄的通道材料(2D),具有合理高迁移率(>20 cm^2/Vs),并且与BEOL材料处理窗口兼容的同时进行3D沉积技术(ALD);通过铁电材料使用极高的介电常数。 3D DRAM:层叠需要BEOL兼容的选择设备,具有高驱动电流(>10 MA/cm^2),在+/-2V附近,并且极低的泄漏(<<10^-15A)。朝向2D也是如此。 支持DRAM和NAND以及其他新兴存储器应用的3D异质封装架构和方法,。
新兴存储器
ReRAM:朝向对电阻状态的确定性控制,以减少设备变异性和循环重复性,最小漂移和高稳定性。
PCRAM:对抗漂移和原子偏聚的材料,需求较低的驱动电流。
MRAM:MTJ器件或具有10-100倍较低临界电流或电压切换和10-100倍较高电阻比率的模拟器件。
FERAM(包括FeFET和FTJ):在X-Y和Z方向上具有高而均匀的残极化,高保持力和抵抗偏置和疲劳。
新型存储器 类模拟器:对多种存储器状态(>10)进行确定性控制,具有近线性响应、大动态范围、低变异性,以及大规模的高循环和可靠性。 其他具有对抗性能属性的新型概念。
4.2.2. 传统数字处理 挑战和需求
通用计算集成电路将继续保持其工作效率。这些系统已经在从HPC到嵌入式/IoT应用的各种应用中进行了优化和使用。需要解决的挑战有: 1.高核心数量单芯片实现的低产量和高成本,有效地限制了规模化。 2.在高核心计数系统中保持缓存一致性阻碍了规模化。 3.当工作负载被卸载到加速器时,核心空闲或低利用率核心造成的能耗效率低下。 4.传统内存层次结构和封装IO的压力不断提高。 5.需要对长时间运行的应用程序设置检查点(在HPC领域很典型)。 6.由于内存复制、一致性活动和虚拟内存异常处理的缺乏统一虚拟内存,而产生的低效率。 总体来说,就像任何多芯粒集成的系统中,传统数字处理系统最初将依赖于2.5D集成,在封装内具有密集、低延迟的互连,以及专用的芯粒到芯粒的连接;有限形式的3D集成将在不久的将来进一步投产;芯片连接标准的发展(如UCIe、ODSA一组标准的BoW)和芯粒尺度缓存一致性标准,如CXL(本质上实现了众所周知的MESI协议),有助于为传统处理系统的多芯粒集成铺平道路,这些系统包括额外的芯粒用于加速、内存和IO。
可能的解决方案
解决系统规模化的挑战可能包括大规模核心芯片的多芯粒实现,这将成为解决单芯片实现的低产量和高成本的标准。异构多核心芯片或具有异构核心的芯片(称为“大-小”配置)提供了一种减轻能耗浪费的方式;系统管理程序和操作系统调度程序可以有效地利用异构核心;此外,通过调度技术避免核心空闲或低利用率,以提高在工作负载被卸载到加速器芯片时的整体能源效率;需要为此开发合适的软件和操作系统基础设施。
总体而言,加速器芯片能效的提高将在产品中植入各种不同的加速技术。 通过网络加速,例如多播、收集、屏障和其他同步特性的内部加速,可以减少核心到核心通信延迟;自适应路由将减少拥塞并释放出互连的可用双切面带宽;在SiP中,可以通过许多方式减轻互连瓶颈,这些方式包括在2.5D配置中使用宽桥接,堆叠低功耗核心和/或IO处理器,或在高功率芯片核心上堆叠SRAM缓存;最后是通过互连垫内的多层金属实现网络的并行处理,带来显著的连接改进。
内存层次结构的限制可以通过多种方式来解决,包括使用在封装内部实现额外缓存级别的芯片、堆叠的SRAM较低级别缓存、整合新型内存技术、使用共存的HBM芯片,以及使用以内存为中心的计算范式和加速器。
对于一般计算系统的规模化策略是将多核处理器芯粒、加速器和其他芯粒、IO芯粒和内存芯粒集成在一起,但这需要在系统中实现在共享虚拟内存层面的内存一致性机制。由于规模化的系统存在数百个大型缓存和更远的互联距离,出现了动态可分区NUMA域的概念。而检查点解决方案将依赖于内部和外部非易失性内存技术,这些技术在本章的早期进行了讨论。 封装IO的限制可以通过集成通信频率高或速率快的芯粒来避免;共封装的光子学也可以规避封装IO瓶颈,但大规模低成本的部署仍将是一个挑战;耐受较大温度波动并且整体成本低的光子学收发器的开发至关重要。针对缺乏统一的虚拟内存机制的问题,需要制定多核和加速器芯片集成时关于虚拟内存机制的标准。
4.2.3. 存内数据处理 目标/需求
诸如深度神经网络(DNN)和同态加密(HE)之类的应用需要在内存层次结构的不同级别之间频繁移动数据,带宽有限和延迟和能耗高的数据传输成本降低了系统性能并增加了处理的能耗,但是,此类操作的操作数之一是静态的,例如在DNN中的神经网络权重。存内处理(PIM)是加速此类数据密集工作的可行解决方案,因为它能够在内存组件中直接进行计算:通过在缓存、主存储器和存储设备上处理能力,可以将数据中心的处理压力扩展到边缘设备,实现系统级性能和能耗效率的改进。 PIM方法必须扩展到支持事务处理、数据库和搜索的应用,以及加速位级操作和加速特定生物信息学的相关应用。
路障/挑战
用于系统集成中的PIM芯片片段面临着几个挑战,包括: 1.PIM加速器的体系结构设计和计算精度通常依赖于过度理想化的器件/电路参数,在实际材料制造过程中难以实现。 2.由于内部总线带宽有限,需要灵活数据访问模式(例如,非局部访问或集体操作)的工作负载仍然受到数据移动瓶颈的影响。 3.由于芯片内存容量有限,随着模型规模快速增长,基于PIM的加速器的性能因PIM数据替换而产生的数据移动而受到降级。 4.软件栈缺乏支持。大多数编译器/库不了解PIM加速器中的特殊数据流或PIM加速器与主机之间的数据流,因此,它们无法充分利用PIM设计的全部潜力。 5.现有的PIM设计在整体应用中缺乏灵活性。由于需要实现与处理器的内存共享或细粒度同步,这可能导致性能下降。 6.目前还没有完整的解决方案将PIM集成到现有系统中。尚未验证任何解决方案与缓存一致性、操作系统内存管理、编程语言中现有的内存模型等的兼容性。
可能的解决方案
异构集成允许专门的PIM芯粒与其他芯粒、高速互连和一般IO芯粒进行有用部署;同时也允许在内存层次结构的不同级别上集成PIM,但需要提供适当的API以允许工作负载调度、数据分阶段和其他需求。 为了发挥PIM的系统的全部潜力,算法-硬件协同设计很关键。我们需要追踪驱动、高级仿真工具作为的硬件基元,用于设计相关软件栈、库和运行时系统。
4.2.4 模拟AI加速器 目标/需求
预计在未来的五到十年中,AI/ML应用的主导地位将在多个规模级别上部署,从边缘设备和移动平台(如自动驾驶汽车)到大型数据中心。这些应用中的一大部分依赖于神经网络变种(CNN、DNN等),当前的产品证明了现有和未来需求的广泛多样性。在任何这些系统中,及时的响应和高吞吐量至关重要,用于训练AI/ML加速器的数据集也显著增长,因此,必须显著提高AI/ML加速子系统的能效,以满足数据集和应用规模的扩展。
路障/挑战
传统的基于神经网络的加速器采用数字逻辑实现,依赖于一系列乘法累加(MAC)逻辑。改进的器件技术、可变精度等传统的方法可用于扩大容量和提高这些加速器能效支持;近年来还出现了基于模电乘法器的MAC,它们依赖于忆阻器、相变存储器等技术,特别适用于一些可以容忍一定精度缺失的低功耗应用;在大规模加速器方面仍存在一些挑战,如解决数据传输开销、显著降低组合系统的功耗以避免热挑战,以及相关的可靠性问题。
可能的解决方案
具有长寿命和扩展精度的密集模拟AI加速器芯片,可以支持动态或可配置的精度调整,从而改进现有寿命较短的技术。这对材料创新、低噪声和稳定的模拟电压调节器、低功耗和小尺寸ADC等提出新的需求。候选模拟AI加速器的示例包括基于相变存储器(PCM)交叉阵列的模拟神经网络加速器和基于其他内存架构的模拟NN加速器。 采用新器件技术实施的替代MAC设计具有固有的能效(例如碳纳米管晶体管),但必须提高可靠性/寿命。 具有SRAM般性能和高耐久度的SONOS Flash模拟存储器或MTJ存储器设备,用于权重等。 这些解决方案可以结合在3D芯粒栈中,进而需要高纳米颗粒/微颗粒密度、新的供电/转换策略等。
4.2.5. 关于规模化系统级封装的其他方面
为了扩展系统配置以支持更高性能,需要提高组件集成度,从而引入多个架构和微架构挑战,超越了先前讨论的物理和热挑战。在多核之间进行的许多操作涉及广播和多播操作,这会随着核间通信距离的增加而导致完成延迟增加。尽管2.5D和3D集成允许未来芯片内互连的双边带宽显著增加,但大规模片上网络(NoC)的拥塞可能导致限制有效带宽改进的瓶颈,当数据从处理单元(PE)穿越SiP到达SiP边缘的IO和内存控制器时,NoC的拥塞特别严重。此外,NoC区域目前占总SiP面积的20%-30%,SiP总功耗的5%-10%,因此进一步增加互连密度以解决带宽问题需要慎重的权衡。 系统规模扩大的一个基本限制是功耗壁垒。由于芯粒的互连功耗构成了其功耗的主要组成部分,异质集成通过在封装内集成具有宽而短的互连的芯粒来降低总体功耗,这可以减少穿越包边界所需的IO功耗。这种情况在通过桥接连接的2.5D集成和特别是3D堆叠芯片片段架构中成立,不幸的是,3D芯片片段集成必须处理散热、功耗传输和产量问题,这些问题在规划图中的其他部分有所讨论。在短期和目前,3D DRAM(例如HBM)、低功耗芯粒堆栈中设置一层高功耗逻辑,提供了内存和系统规模化的实际解决方案;长期的系统规模化要求系统的整体能效通过以下一个或多个方面来扩展:系统架构的创新;器件和互连创新;以及冷却技术的创新。
支持SiP规模化的其他可能解决方案
这些解决方案对4.2.2节中讨论的解决方案进行了补充和扩展:
QoS意识路由和带宽敏感(例如GPU)与延迟敏感(例如CPU)的PE的拥塞管理。
精细化的(例如路由器级)DVFS支持进行功耗管理。
数据压缩技术以增加带宽并允许更窄的互连链接。
芯粒之间的集成光子学。
用于稀疏性的硬件支持,以改善封装内大规模3D缓存和广泛的计算资源的利用。
针对数据移动模式定制互连拓扑的协同设计。
这样大型系统的架构研究还将需要创新的仿真技术,允许在多个抽象级别进行仿真,以分析芯粒内的微体系结构细节,这对整个系统的性能、功耗和热特性进行跨芯粒、不同类型的数据处理单元和中间层的分析是必要的。 除了在二维或三维的中间层上的芯片片段集成,用于定制应用的更大的晶圆级系统也可以实现系统的规模扩展,但这些产品的广泛部署可能不太可能。
4.2.6. 神经形态计算 目标/需求
AI应用主要使用具有高度计算、内存和能源需求的深度神经网络体系结构进行训练和推断。基于大脑的神经形态计算已经出现,作为一种高能效的范式,与神经网络相比,它提供了数倍的能源效率改进。神经形态系统的特征为:计算-内存集成架构(神经元和突触)以及异步和模拟/数字操作(脉冲神经网络,SNNS),这种架构允许扩展和并发性,而异步操作实现了高能源效率的运行。 障碍/挑战 采用新的计算范式通常伴随着软件基础设施的挑战。移植现有的AI应用以及新的认知应用将需要新的抽象层和算法,这些架构的扩展采用模拟/混合信号处理还需要具有容错性的设备和架构。
可能的解决方案
专为神经形态计算而设计的新内存和计算设备。
基于芯粒和3D集成的大规模网络。
应用程序领域特定的软件抽象层。
将SNN用作异构系统中的定制加速器。
4.2.7. 量子退火和通用量子计算
量子系统分为两种主要类型:量子退火系统,用于高复杂度的优化问题;以及通用量子计算系统,使用模拟或“数字”量子门。量子比特(Qubits)是所有量子系统中信息存储的基本单元,所有量子系统都依赖于量子叠加和量子纠缠原理,与传统比特(bit)只能处于两种状态之一不同,量子比特实际上由于量子叠加可以处于多种具有不同概率的状态。这使得相较于传统位,单个量子位可以存储更多信息,因此,对Qubits的操作基本上是矢量操作,而量子系统可以处理庞大的问题空间,并且受益于矢量操作。
Qubits容易出现退相干,存储的信息会由于噪声而恶化,将Qubits存储在非常低的温度(接近毫开尔文)可以延迟退相干。此外,对Qubits状态的测量是破坏性的(有效地消除了叠加状态),量子系统使用量子纠缠现象这种难以理解和未解释的性质来在读取期间保持状态,量子纠缠将两个物理耦合的Qubits的量子状态联系在一起,使得对其中一个Qubit进行状态改变会影响与其纠缠的另一个Qubit的状态。在测量时,纠缠的Qubits会暂时解耦,以保持一个Qubit的状态,而另一个Qubit被读取,多个纠缠的Qubits组成一个单个的逻辑Qubit,系统中Qubits的数量决定了处理的问题空间的大小,但是扩大这个数量仍然是一个挑战。 Qubits和量子逻辑门有许多不同的实现方式,Qubit的实现包括以下几种:
超导Qubits,其中Qubit是具有Josephson结实现电感的谐振器。
冷原子Qubits,作为超冷和隔离(“困住”)的原子。
离子Qubits,类似于冷原子,但是使用离子而不是原子。
光子Qubits,作为孤立的光子粒子或超混合的“压缩”光子的光束。
通过修改CMOS晶体管通道困住并操作的孤立电子Qubit。
新兴的基于FinFET的困住载流子Qubit。
层间互连使得量子系统的许多关键部分可以在一个封装中实现,这些部分会因系统而异。一些可能的集成组件包括:组成规模化Qubits集合的芯粒,用于测量和激发的芯粒,用于光子束形成或光子隔离的芯粒,以及在使用光子Qubits的系统中实现量子门的芯粒。总的来说,多芯粒Qubits集合需要使用协同的互连,这也带来相应的挑战。 量子系统的主要需求是开发新的体系结构来减小物理尺寸并降低运行成本,寻找一个真正通用的量子计算机仍然是困难的,而且在短期内也不太可能实现。总的来说,量子系统体积庞大,需要大型多级稀释制冷设备来保持所有或部分核心部件处于非常低的温度。,数量子系统需要紧凑型台式制冷设备专门冷却Qubits、测量/激发电路和量子门。 从封装的角度来看,量子系统的IO仍然是一个挑战,可能会使用光子学连接和共封装的光子学。此外,相应的封装解决方案需要能够承受大温度变化。
4.2.8 交叉考虑
4.2.8.1 电源转换和电源管理
SiP的配电带来了一些独特的挑战,包括电源的布线考虑、高端系统中大电流引入的线路压降(sags)、集成数字和模拟芯粒的SiP对电能质量的需求,以及一般的噪声和串扰问题。由于距离更近,3D 芯粒堆栈本身就面临着独特的挑战,包括电源布线布局限制、串扰和噪声。 解决这些现有的挑战的一些潜在解决方案(可能会继续使用)包括:
背面供电,通过芯粒背面的连接以分布式方式将电力直接输送到使用点,以避免信号路由层和电源路由层之间可能存在的争用。中介层中的再分配层可以简化该解决方案中适当点的电源布线。
嵌入中介层的电源转换器可以减少与高电流和电力线骤降下的欧姆(即 I2R)损耗相关的问题。
对于高端SiP,可以通过为封装提供更高的电压并在封装内部使用负载点(POL)电源转换器芯粒以分布式方式将较高电压转换为芯粒等级电压来避免高电流需求和相关的欧姆损耗。
为了适应封装内部转换器,有必要采用先进的磁学设计(以及相关的材料开发),以降低整体高度,实现更高的体积功率转换密度。与此同时,还应为小尺寸电容器开发先进的电介质。对于三维系统,需要为三维堆栈内的电源路由开发解决方案。这些解决方案还需要避免通过电网和共享电源转换器设置非预期的转换通道。未来的解决方案包括扩展当今工业中用于 HBM 和最近的 3D 逻辑芯粒堆栈、边缘供电以及在芯片内使用本地电源调节。在这方面需要适当的软 IP 开发和标准,以指定电源连接的物理参数。
4.2.8.2 安全
许多适用于封装单芯片解决方案的传统安全威胁在 HI 系统中成倍增加,例如芯粒篡改、芯粒探测逆向工程和信息泄漏(物理或使用 X 射线),以及侧信道、隐信道和固件泄露。这是由于芯粒之间的距离很近,特别是在 3D 芯粒堆栈中, 也由于芯粒使用更宽和低延迟的互连、通用电源转换器和配电网络。解决 3D 配置中的侧信道和隐蔽信道的安全解决方案仍然是一个特殊的挑战,开发适当的方法和 EDA 工具,以在设计时检测和避免潜在的信道以消除或减少攻击面。HI 特有的威胁是中介层本身的完整性可能会被篡改。数字SiP中使用的模拟加速器呈现出以模数转换器和模拟存储器组件为中心的新攻击面。最后,另一个威胁来自运行时固件或应用软件的入侵,这些入侵可能导致信息泄露和拒绝服务攻击。
人们一直在研究 Chiplet 验证解决方案,相关技术也已相当成熟。例如,水印、逻辑锁定和设计混淆等。通常,芯粒和中介层身份验证是针对 SiP 的一些可能攻击的必要解决方案。这需要使用交换所工具进行注册,在启动时或运行时使用软件包内的本地信任根来保护访问以验证芯粒、固件和系统软件。为此,必须开发一个完整的安全意识生态系统。高可用性系统的 SiP 还可以采用以硬件为中心的隔离机制,以便在检测到不良行为者(包括已遭到入侵的整个芯粒)时将其隔离,从而允许 SiP 的其余部分继续提供服务,但性能会同样下降。部署在芯粒中的可靠且值得信赖的传感器是支持运行时监控和平稳降级的必要条件。机器学习技术无疑可用于检测多个芯粒的异常行为。总的来说,重要需求包括运行时监视技术、检测异常行为的机制以及在运行时处理检测到的攻击的机制。所有这些都需要大量的方法开发,而这些方法目前还没有到位。第 3 章详细介绍了 SiP 的安全问题和解决方案。
4.2.8.3 可靠性问题
确保芯粒可靠性的技术,包括器件、材料和封装工艺技术,已经得到了很好的发展,并且不是HI独有的,软错误及其处理技术也是如此。然而,芯粒故障和软错误会对SiP产生级联效应,因此需要开发系统级容错技术。这些可能包括使用冗余和设施来隔离故障芯粒,如第 4.2.8 节和第 3 章中提到的一些安全解决方案中使用的。在专为关键任务应用设计的 SiP 中,故障处理技术需要更加激进,但这些技术总是需要付出合理的代价。通常,系统级架构解决方案必须在 SiP 中使用,以实现高保证系统。 HI 系统在集成阶段提出了独特的可靠性挑战。需要冗余和容错彼此联系。在系统规模上,由于中介层和互连上的热致机械应力而引入的故障构成了威胁。协同设计技术对于使用基于多物理场的紧凑型模型对装配和使用过程中的热致应力进行早期可靠性评估至关重要。开发可靠的装配和封装工艺以及适当的计量和材料表征也至关重要(参见第 4.3.5 节)。最后,在组装期间和部署的运行时进行测试是一项重大挑战。 可靠性问题及其影响、测试技术和材料以及相关计量需求将在本路线图的其他地方进行讨论。
4.2.8.4 可持续性
HI SiP 设计流程和设计范式必须不断发展,以纳入以可持续性为中心的选择。可持续材料工艺和技术的发展对于提供这些选择至关重要。对体现可持续性考虑的深度协同设计 EDA 工具的需求仍然很高,并在未来几年内变得越来越重要。使用更小、更可持续、更节能和高能效芯片的多芯粒解决方案有所帮助,较小的芯片尺寸可确保更高的产率并减少浪费。然而,在组装步骤中产生的废料必须与组装更多芯片的需求进行权衡。在促进可持续设计和制造方面,需要制定衡量标准、方法和指南。在运行阶段,必须采用良好的系统级电源管理技术和支持可持续的热管理的封装技术。最后,报废处理阶段对可持续发展的影响仍未量化,需要在这方面取得重大进展,以最终实现这一阶段的可持续发展。第 2 章详细介绍可持续性方面的考虑因素、需求和一些潜在的解决方案。
04.4.3节—设备、材料、化学工艺、表征和计量
本章将讨论逻辑和存储设备、互连、2D和其他新材料、单片 3D 集成、高级图案化(包括 hyper-NA 和 DSA)、原子级化学过程(如 ALD 和 ALE)以及表征和计量技术。
4.3.1 逻辑和存储器器件
4.3.1.1 逻辑器件 目标/需求
连接设备的数量和计算过程中传输的数字数据量继续呈指数级增长。同时,电子设备消耗的可用功率的总比例也正在以指数级的速度增加。为了保持一致,每次计算消耗的能量(的降低)会要求器件面积和体积继续减少,并且要求实现新的材料、器件设计、化学处理和设备,以实现比当前系统高出1,000,000倍以上的新型节能CMOS逻辑。此外,CMOS正积极转向3D堆叠,以降低功耗,增加功能并支持进一步扩展。必须采用新的策略来提供电力并散发不必要的热量。还需要化学处理和新的集成方案,来为有效且高效的3D规模化提供新的途径。
障碍/挑战
传统CMOS逻辑中的计算功耗由电源电压、栅极电流泄漏程度、关断状态泄漏、器件电容(包括栅极、互连和寄生电容)和时钟频率决定。频率的增加对降低电压、电容和漏电提出了很高的要求,这些要求由以下因素决定:器件材料(即栅极介电常数和厚度、N-P 突变性和隔离度、互连金属电导率); 物理器件尺寸和设计(即栅极触点电容、模块高度、互连电容、源极/漏极重叠等);器件集成和封装(即2D平面封装与3D堆叠的对比)。我们也需要新的技术来实现高纵横比和非对称架构(high aspect ratio and asymmetric architectures),尤其是当特征排列要求相对于元件厚度非常小的时候。我们需要在使用低温工艺制造和组成新材料上有新的认识。背面供电需要注意与3D集成兼容,同时尽量减少有害电容。除了减少寄生电容和电阻外,我们还需要考虑材料的热耗散特性,以最大限度地减少规模的和堆叠的器件中的热积聚。
可能的解决方案
器件结构与设计:器件结构从FinFET到Ribbon FET再到Stacked Ribbon FET的演进将对解决问题有所帮助,但可能不足以满足目标的能效需要。我们也需要继续探索垂直场效应晶体管(Vertical FET)、隧道式场效应晶体管(Tunnel FET)以及任何其他器件架构或结构。Cryo-FETs在非常的低的温度下也可以考虑,但是对大多数应用来说,可行性有限。这些结构可以通过减少短沟道效应,最小化有害的接触-门电容、过孔电阻和接触电阻来推动低功耗实现。改善栅极控制的方法(负电容或更高的有效 k),都能通过改善栅极的控制和实现栅极尺度缩小来降低功耗。通过在栅极层添加铁电材料、Tunnel FETs和FETs可以过滤源极-漏极势垒上的热离子发射,从而克服传统 CMOS 晶体管中 60mV/ decade 的亚阈值摆幅限制。其中许多器件方案的整体可靠性还有待验证,而且每种方法的长期稳定性能都取决于材料选择和制造方法。
特征尺寸缩放:使用设计技术协同优化(DTCO)技术,在模块级评估并优化功率、性能和面积(PPA),可以在3D架构中实现非常激进的面积规模。版图依赖效应也很重要,这可以通过从双扩散技术到单扩散(double-diffusion break to single-diffusion break)技术的过渡以及COAG(Contact Over Active Gate) FinFET 设计来解决。为了减小器件体积和热质量,也需要在低热预算3D成型金属和间隙填充工艺,低热预算、低成本和更小沟道的预算堆叠方法等方向上有更多创新。通过先进的2D半导体和绝缘体以所需的几何形状进行保形沉积和蚀刻,可以对沟道提供更好的静电控制,并通过更小的沟道电阻和低寄生电容来降低功耗。芯粒(Chiplet)的设计和集成也将受益于新兴的系统技术协同优化方法(System Technology Co-Optimization,STCO)。
沟道材料:沟道材料会继续发展,从应变硅到硅锗,再到锗,以及低维材料,如一维碳纳米管 (CNT) 和二维过渡金属二卤化物 (TMD)。低维材料是极大规模器件的理想候选材料,因为它们能以较薄的本体厚度(即约1纳米)保持高载流子迁移率,这对实现出色的静电控制至关重要。例如,由多个碳纳米管组成的一维碳纳米管场效应晶体管(CNFET)与2纳米硅纳米片相比,能量延迟积(EDP)预计可提升7倍。其他低密度场效应晶体管,如高有效质量二维过渡金属二卤化物TMD,由于减少了隧道效应,在低功耗应用中大有可为。这些应用中沟道必须坚固耐用,缺陷少,可靠性高,能实现低电阻欧姆接触,并与低温栅极电介质和具有可调功功能的栅极金属兼容。具有合适迁移率(约 100 cm2/Vsec)和低漏电的氧化物半导体(Oxide semiconductors)可以在低温下沉积,但在集成中使用需要更高的热稳定性,且需要手段来避免不必要的 H2 掺杂效应和与氧气相互作用。也有一些探索性的接触方式和材料选择来设计新型场效应晶体管,如自旋场效应晶体管(spin-FET)和拓扑晶体管(topological transistors),它们有可能提高性能或提供更多功能。
互连材料:互连材料也需要改进。目前使用的铜需要很薄的 TaN 扩散势垒层,在小通孔中,势垒层(电阻很大)可能占据通孔体积的很大一部分。钌、钴和钼是潜在的候选材料,但也可能会有产生重大影响的其他材料。 可降低寄生电阻、电容和器件发热的新材料:要在制造过程中实现大规模和三维的结构,就必须提高特征尺寸和对准的精确度(例如,更小的边缘贴装误差和均匀的栅极长度控制),以及在纵横比超过 50-100:1 的垂直结构中保持亚纳米一致性。对于垂直器件设计,每个器件的功耗降低了,但单位体积的功耗却变得非常大,这就需要新的散热方案。垂直器件的制造还需要在低温材料合成方面取得进展。这些进展包括多孔金属有机框架(MOFs)及其他有机和无机结构。高质量、低缺陷的材料通常是在高温下实现的,因为在高温下,热力学驱动力会促进结晶和缺陷减少,但高热预算会损坏底层材料和材料连接。我们需要更好地了解化学表面过程,以便在原子尺度上对材料组装进行低温动力学控制。对于很小尺度的器件,任何能够降低有源器件外部介电常数、改善变化、减少自热、降低接触电阻以及降低互连电阻、电容的材料进步,都将有助于实现的更大的逻辑规模和性能提升。
4.3.1.2 存储设备 目标/需求
新存储技术的需求量很大,而且还将继续增长,尤其是在数据中心、图像和传感器处理以及人工智能等应用领域。人们对电子存储器的需求正在快速增长,以至于存储器所需的硅片很快就会超过全球可用的数量。此外,内存访问的能效,特别是 CPU 查询 DRAM 的能效,跟不上算力的发展(如前文提到的"内存墙"),这促使人们需要全新的新技术。为了满足不断增长的存储需求并帮助降低系统能耗,存储密度需要在降低功耗的情况下达到目前水平的100倍或更高,为此人们需要采用带宽超高的架构,以及在内存旁计算甚至在内存内计算的架构。
障碍/挑战
提高高速缓冲存储器密度(SRAM替代)将直接缓解CPU和DRAM 之间的数据传输所带来的功耗问题。但是,必须满足严格的设备级要求:末级高速缓存或嵌入式DRAM (eDRAM) 的读/写时间接近10毫微秒,L2/L3 级高速缓存的读/写时间要求更快(约 2 至 3 毫微秒)。耐用性需要接近 1015 到 1018 个读写周期,工作电压需要足够低,这样竞争存储器件才能嵌入高级逻辑晶体管。因此,要实现下一代高能效、高速密集型嵌入式存储器,必须对主要存储器选项进行重大改进。
当前独立存储器特征几何尺寸在不断压缩,以实现持续的二维规模扩展,但不可避免地会出现规模扩展变得不可行的情况,例如 NAND 闪存就出现了这种情况。其浮动栅极长度接近 20 纳米,无法实现必要的电荷存储。NAND的传统横向单元串现已过渡到利用第三维优势的垂直设计——这是第一个真正的3D同质集成。DRAM的扩展也能受益于向三维的类似过渡,但由于电容单元比NAND闪存栅极更大(在X和Y两个维度上),因此难度更大。垂直存储器件堆叠还需要具有适当驱动特性和极低漏电的新型BEOL兼容的选择器件。所有新的集成方法,都需要新的材料和新的化学工艺,特别是分别通过ALD和ALE实现沉积和蚀刻控制的技术。通过新的架构方案,使内存更接近于计算,即所谓的存内和存旁数据处理,可能会缓解这种持续的规模扩展。此外,新的架构方案将推动新的混合和异构三维集成技术的发展,这就要求在芯片级和晶圆级堆叠方面进行创新,以超越当前的高带宽内存(HBM)实现方式。
可能的解决方案
新兴存储器:新兴存储器目前仍处于"新兴"阶段,包括阻变随机存储器(ReRAM)、相变随机存储器 (PCRAM)、磁阻随机存储器 (MRAM)、铁电随机存储器(FERAM)、压缩随机存储器(Z-RAM) 和晶闸管RAM (T-RAM)。没有任何产品被认为具有能够取代现有 SRAM、DRAM 和 NAND 闪存技术的综合特性,而这些经典闪存技术都是以存储电子为根基的。新兴存储器必须克服成本、扩展性、器件可变性、可重复性、可循环性、可靠性和其他指标方面的已知缺陷。早期应用可能是特定场景用途。例如,MRAM作为非易失性SRAM的替代品,FERAM作为相对较快的非易失性存储器的替代品,非常适合智能卡等低功耗、低循环应用。与利用电子存储的设备不同,ReRAM中的原子运动以及PCRAM 中的原子运动本质上是随机的(即不可控的和潜在的非确定的),从而导致大量的变化,限制了当前的与/或实现和非常需要容错性的系统。使存储器在数字处理中更加核心的新架构可以指向并使用具有一个或多个已经出现的存储器固有属性的存储器解决方案。
铁电存储器:可以考虑几种形式的铁电存储器,包括铁电随机存取存储器、铁电晶体管和铁电隧道结或二极管。用于存储器系统的铁电体可以是基于萤石的材料,包括掺杂二氧化铪、钙钛矿晶族(如 BaTiO3)和纤锌矿(如掺杂 AlN、ZnTe 和 BeS)。我们需要深入了解材料,包括缺陷如何影响动态开关、唤醒、疲劳和介电击穿,特别是允许缩放至低于 1V 的工作电压以与先进逻辑技术节点兼容。
此外,还需要改进分析技术,以确定缺陷类型和密度,并确定相组成。器件需要在界面金属工程学方面取得进展,以容忍在外加磁场作用下的突然极化切换,从而提高抗干扰能力,并实现 1015 到 1018 个读写周期的耐用性,以替代高速缓冲存储器。为实现铁电晶体管,需要通过调制铁电极化和载流子密度来减少陷阱充电/放电效应,并且通过栅极堆栈和源/漏工程来减少缺陷和实现低压操作。隧道结可能需要具有超低缺陷的超薄(< 3 纳米)铁电层,以通过高隧穿电阻 (TER) 实现高离子和高开/关断比。
目前尚不清楚这是否可以在规模的铁电器件中可靠地实现,但取决于编程脉冲电压和持续时间的部分铁电极化会导致多种类似模拟的电阻状态,这表明铁电器件有可能用于多比特存储。实现类似模拟存储器件的 3D 交叉阵列可以实现允许高效神经形态的计算的存储器密度。对于这些高密度配置,需要全面了解规模 FeFET 中多电流等级和耐压的变化,而具有类似二极管电流电压特性的 FTJ器件,可能会在堆叠交叉阵列中提供无选择器、两端子、多电平存储单元。
自旋电子存储器:自旋电子存储器的选择包括自旋转移力矩 MRAM(STT MRAM)和自旋轨道力矩 MRAM(SOT MRAM)。STT MRAM 需要铁磁材料工程设计,以降低磁化反转的开关电流,同时还需要器件设计,在不影响隧穿磁阻 (TMR) 的情况下,通过增大有效自旋转移力矩来降低开关电流。为了在 SOT MRAM 中实现低开关电流的磁反转,需要使用具有更大自旋轨道效应的新材料。
此外,高密度配置还需要整合其他现象(如电压控制的磁各向异性或磁电和反铁磁效应)的新型器件设计。 新内存:能与现有技术甚至新兴技术相媲美的器件具有很高的标准。终极器件将具有确定的、模拟的和线性的存储器状态,可在低电压和/或低电流条件下实现低纳秒或皮秒级的切换。如果无法实现这样的终极存储器,那么解决本节和 4.2.1 中讨论的当前新兴存储器的固有问题,可能有助于在特定应用中获得采用,或者实现如神经形态的新架构方案。
4.3.2 片上互连 目标/需求
芯片上的互连器件负责为器件传输信号和电源。电源互连需要低电阻,而信号线则受益于低电容和/或低电阻-电容乘积。面积规模推动了最小金属间距的指数式下降,预计到这个十年结束,最小金属间距将突破20纳米大关。随着最小金属间距的缩小,为实现性能和可靠性目标,需要不断改进材料(导体和电介质)、新的集成创新和采用新的图案设计方案,以实现更好的覆盖(overlay)和LER的降低。
障碍/挑战
铜互连器件需要扩散屏障和小特征的金属填充,屏障和铜之间不能有空隙,这是一项巨大的挑战。此外,铜阻挡层和衬里的缩小速度不及最小间距,造成铜传导横截面积变小、铜电阻率增加以及内在的可靠性问题(偏置热应力和电迁移)。
可能的解决方案
新型阻隔层和衬里材料可以被积极减薄以实现间隙填充和改善线路电阻,同时仍然通过电阻满足可靠性目标,这可以通过使用有机阻隔分子进行选择性阻挡沉积来改进。新的集成方法,如混合金属化和半大马士革减法金属蚀刻方法,也可用于降低互连电阻。此外,还可探索无需阻挡层的铜替代候选材料(如钌、钴、钨和钼)。可以采用先进的低介电材料来降低线路电容,但这需要材料工艺方法来保持模板的保真度,并避免蚀刻和清洗过程中的介电常数退化。实现低互连电容的另一种方法是采用高多孔材料(如 MOFs)以及可控气隙工艺。采用背面供电将实现最小间距的反向缩放,以及信号互连(器件正面)和电源线(器件背面)的独立优化。
4.3.3 二维(2D)材料 目标/需求
低维材料(LDMs)主要包括二维材料和排列整齐的一维碳纳米管(CNTs)阵列,其因超薄的单元、优异的电学特性、热特性和化学特性,成为极大规模器件的理想候选材料。二维导体(如石墨烯和 MXenes)可降低薄层电阻、散热并避免电迁移。半导体二维材料(如 MoS2 和 WS2)由于增强了对通道的静电控制、减少了隧道效应并降低了投影变异性,因此在低功耗应用中大有可为。像氢化硼这样的绝缘二维材料可用作具有二维半导体沟道的场效应晶体管(形成干净的范德华界面)和其他存储器件的电介质。具有多个排列整齐的碳纳米管通道的场效应晶体管(CNFET)有望成为高能效数字逻辑的候选器件,与硅场效应晶体管相比,可实现7倍的能耗延迟积(EDP)。
基于LDM的商业产品已经得到验证。CNFET 已集成到硅工业设施中(如 SkyWater Technology),并用于 ADI 公司未来商业产品的研发。墨烯是一种二维半金属,已应用于商用传感器和特种相机中。此外,低温制造可实现逻辑层和存储器层的单片 3D 集成,从而释放出 1,000 倍的 EDP 优势。即使是集成在硅 CMOS 上的单个 CNFET 层,也能实现 5-10 倍的效益(利用 SkyWater CNFET 实验数据进行物理设计验证)。然而,我们需要新的化学工艺,将高性能 LDM 集成到极大规模的器件中。对于二维器件,重点是晶圆级合成和低温、低缺陷材料沉积。对于一维器件,重点是均匀和受控的组装。
障碍/挑战
LDM FET 中的欧姆接触和栅极-绝缘体集成需要改进的材料和工艺。在具有适当(低)缺陷密度的硅微晶片上沉积 LDM 是一项主要挑战。大多数二维材料合成方法需要高温(>800ºC),与 BEOL CMOS 工艺不兼容,而且由于裂缝和杂质的形成,转移工艺的规模扩大尤其困难。在二维材料上涂覆金属或绝缘体,或蚀刻图案或通孔,都会产生额外的缺陷。二维材料中高密度缺陷的存在会降低性能和良率,同时增加可变性。在二维半导体中,虽然 n 型接触电阻 (RC) 已接近量子极限,但必须确定规模的 p 型和 n 型低 Rc 接触(<15 纳米)。目前已经实现了规模 p 型 CNFET(即包括致密 CNT、规模低 Rc 接触和自对准延伸掺杂)的集成的里程碑。CNT 净化(即金属 CNT去除)和设计技术(如针对金属 CNT 的弹性设计,DREAM)方面的进步使得抗缺陷的 VLSI 电路成为可能。然而,实现这些优势的关键挑战在于在晶圆尺度统一 CNT 取向以及 2-10 纳米范围内可控统一间距的严格目标,而目前任何已知方法都无法实现这些目标。
可能的解决方案
对于二维材料来说,最重要的需求是改进低温合成和/或在二维材料上转移、蚀刻和沉积其他材料。BEOL 应用需要低温工艺,但 FEOL 并不要求低温工艺。最小化二维材料缺陷的潜在途径包括:使用具有不同温度区域的反应器进行低温合成;使用晶片脱粘和涉及较厚二维层材料(比单层材料具有更高的机械稳定性)的改进传输;采用原子层蚀刻;以及调整金属蒸发过程中的能量传递。发现能够克服高温化学处理限制的新型二维材料并优化与二维半导体兼容的材料(可能包括 CaF2、PTCDA、BiSO5、SrTiO3 等)的合成。对于 CNFET,CNT 带隙均匀性(如手性富集)和沉积方法(如尺寸限制自对准)对于确保高密度排列的 CNT 至关重要。此外,开发基于 LDM 的场效应晶体管的理论模型对于聚焦实验工作也至关重要。
4.3.4 3D单片集成 目标/需求
随着物理和等效缩放的极限越来越接近现实,三维单片方法是一个关键的机会,即在晶圆级进行三维化学处理。在某种程度上,这是在背面供电方面最新进展的基础上的自然延伸。在这一领域存在着巨大的可能性,包括:通过将两个或更多器件叠加在一起,显著提高逻辑密度;由于材料和结构可以在堆叠方法中解耦,因此在块级和晶体管级都具有显著的性能优势;以及在同一逻辑芯片上集成其他功能,包括存储器、射频和功率传输等。我们的目标是从产品的角度,通过 DTCO 或 STCO 更好地了解这些方法的优势,以及在处理和共同集成所有成分方面所面临的挑战。
障碍/挑战
三维单片集成有许多明显的机遇,也有许多艰巨的挑战,既需要创新,也需要严谨的执行。关键的系统级挑战在于理解和定义所有关键的工艺要素,这些要素将使三维单片集成的实施规模得以扩大。在技术领域,关键问题是建造和加工这些实施所需的高宽比特征。虽然这在 DRAM 中司空见惯,但逻辑技术也必须学习和采用,以满足其特定需求和应用。
可能的解决方案
为了使3D单片集成成为逻辑规模和附加功能的可行选择,最迫切需要的是对关键选项和技术定义进行仔细详细的DTCO分析,以开发所需的沉积和蚀刻工艺技术。在堆叠晶体管的实现中,这样一个特殊的项目是需要所谓的“分闸”,其中顶部和底部晶体管的栅极可以分别和独立地解决。必须审查和理解的问题围绕着对这种功能的需求(这在当前技术中是必然的),以及这种连接所需的区域、工艺方法等。这个简单的例子可以提示我们去考虑在当前技术中可能被认为是理所当然的每个方面,但这些方面可能会影响提供增值 3D 单片集成方法的能力。 同样,化学工艺技术专家已经在努力识别和解决与3D单片集成相关的工艺难题。值得庆幸的是,结合本章其他部分的许多想法将是关键的可能解决方案。例如,为了解决3D单片集成中高度堆叠的挑战,可以考虑从较厚的硅纳米带通道切换到二维材料。此外,ALD 和 ALE 技术将是克服这些结构中高宽比的关键。
4.3.5 图案化、化学工艺和制造
4.3.5.1 高NA光刻和定向自组装
目标/需求
EUV:光刻技术使芯片制造商能够在先进的节点上开发出更小更快的设备。利用 13.5 纳米波长,ASML 的 0.33 NA EUV 扫描仪正被各大公司用于先进的芯片生产。然而,在 32 nm 间距以下,将很难使用 0.33 NA 的低缺陷的直接印制 EUV 来制作未来的芯片。这个问题可以通过使用低 NA 的双重曝光来解决,但这会带来工艺复杂性、成本增加和设计规则限制。一旦 0.55 高 NA 的 EUV 扫描仪问世,业界就会知道是否能在 20 nm 间距以下通过一次曝光直接印刷线/空间图案。 展望未来,超 NA(>0.7 NA)是一个新领域,它将一次形成晶体管规模。对于超 NA,最小投影间距分辨率约为 12 纳米,因为焦距深度 (DOF) 与 NA2 成比例,预计抗蚀层厚度为 10 纳米(图 4.5)。

EUV + DSA:通过量化分辨率[R]、线宽粗糙度[L]和灵敏度[S]来分析光刻胶材料,但优化其中一种材料至少会降低其他材料中的一种。这种 "RLS权衡 "是一个主要问题,需要高度重视,才能以可接受的剂量解决光刻胶问题。打破 RLS 权衡的一种方法是使用定向自组装 (DSA),这是一种与 EUV 互补的技术。块状共聚物(BCP)整流的EUV 光刻胶使用光刻定义的引导图案,利用 BCP 的相分离来创建与 EUV 设计布局相称的定义明确的线/空间结构和六边形接触孔 (CH)。BCP 具有内置尺寸以扩展缩放,并且能够抵抗缺陷,与单独的光学光刻相比,可提高整体图案均匀性(LER、LWR 和 CDU)。
障碍/挑战
EUV:目前生产的大多数 EUV 光刻胶都是基于聚合物的化学放大光刻胶 (CAR),而金属氧化物光刻胶(MOR) 则是一个新平台。进入超NA领域后,光刻胶厚度的尺度(超NA预计为 10 纳米)带来了限制和挑战,这将扩大线边粗糙度和缺陷。 薄聚合物光刻胶的挑战
随机性(较薄的光刻胶,由于分子大小、聚集/偏析和多种成分而具有更多的分子不均匀性)。
高光子散粒噪声效应。
蚀刻传输限制。
高底层效果。
二次电子效应(~4 nm 的模糊成为分辨率的一部分)
金属氧化物光刻胶的挑战
完全是负性光刻胶。要打印接触孔,需要一个容易掩盖缺陷的明场掩模
由于与底层的相互作用而导致的不稳定性(其机制知之甚少。)
由于与大气相互作用而导致的不稳定性(其机制知之甚少。
需要提高光刻胶吸收的量子效率(剂量与间距的平方成反比,并可能无意中导致剂量损失。弥补这一点的唯一方法是在保持良好大气稳定性的同时提高光刻胶的灵敏度。这将有助于控制 EUV 光源的功率)
二次电子效应(模糊小于聚合物光刻胶,但会进一步限制宽度分辨率。)
需要新的光刻胶材料和化学工艺进行沉积和干显影。
与MOR相比,聚合物光刻胶不易与晶圆堆和大气相互作用
EUV + DSA:用于线/空间(L/S)和接触孔(CH)的 EUV 光刻胶图案整流需要新的材料发明,用于引导图案、BCP材料和BCP 蚀刻开发,以满足严格的粗糙度和缺陷率要求。LS 和 CH 是通过化学外延形成的,而 CH 矫正并不适用于逻辑应用中的布局。
L/S 挑战
仅限于单一间距,无法用于需要变化的应用(多间距、不同空间和大面积无人区)
对双重曝光 CD 变化敏感(需要小的 CD 变化)
CH 挑战
难以用紧凑的间距打印(需要分成多次打印,每隔一个 CH 打印一次,然后进行第二次打印)。超 NA 可实现单次印刷 CH)。
控制图案放置误差 (PPE) 和缺陷(部分闭合和缺孔)的策略
CH 矫正图案,仅限于六边形对称。
绘制化学位置图以及表征和量化图案基底上的化学成分的计量技术是 EUV 和 DSA 面临的共同挑战和限制。
可能的解决方案
EUV 超薄 (≤10nm)尺度的光刻胶:随着特征尺寸的缩小,光刻胶分子成分成为特征尺寸的一部分。构成光刻胶的分子必须是单组分、小的构建块,以防止聚集和分离。新的设计结构将需要超薄光刻胶和底层组合。需要了解聚合物尺寸和构象对LER的影响。未来的光刻胶设计需要考虑光电子和二次电子的范围和随机影响。 功率源:由于剂量与宽度成比例,因此需要更高功率的光源。
新型光刻胶材料和光刻胶加工:干法沉积和干法显影(即分别通过原子层/分子层沉积和化学选择性干法刻蚀)是进一步研究的重要方向。通过进一步的化学处理对沉积和/或显影的光刻胶改性,例如通过气相渗透添加的聚合物、通过原子层的沉积成型和原子层的蚀刻。新的材料组合物,包括金属有机框架和相关材料也可能被证明是有用的 EUV + DSA 要使用 hyper-NA 光刻,L/S 和 CH的应用都需要间距小于 20 纳米、线边粗糙度和线宽粗糙度小于 1.7 纳米的第 2 代高驰豫 BCP 材料。双嵌段体系普遍存在,但具有高蚀刻选择性的新型三嵌段 A-B-C 共聚物将拓宽 DSA 的应用。在嵌段共聚物加工过程中,使用单个 BCP 嵌段相对于另一个嵌段的顺序浸润 (SIS) 以及干显影冲洗材料来帮助图案折叠,可以提高蚀刻选择性和粗糙度值。新的BCP退火技术,如BCP的溶剂蒸汽退火,将允许热不稳定的BCP分子出现。
EUV 和 EUV+DSA 的“登月计划” 1 .超薄光刻胶的趋势是向单层发展,那么, a.如何将单层变成蚀刻掩模? b. 如何构建抗蚀剂层? 2 .我们如何才能将不再用作蚀刻掩模的薄光刻胶与 DSA 等互补技术相结合,进行图案转移? 3 .光图形化在超NA之后是有上限的,那么还有哪些不使用光子的创造性图案化策略(例如,氦离子束光刻)呢? 4 .今天,DSA的间距是有限的。DSA 的“登月计划”要求实现用于间距无关自组装的引导图形和 BCP 材料设计。此外,还需要打破六边形对称,实现正常的 CH 整流。 4.3.5.2 Atomic Scale Processing, including Atomic Layer Deposition and Atomic Layer Etching(原子级处理,包括原子层沉积和原子层蚀刻)
目标/需求
新型器件结构和材料需要对原子尺度的材料合成和加工有新的认识和更好的控制。原子层沉积(ALD)是目前的一种主要方法,它使用受控的自限性表面反应序列,而准自限性原子层蚀刻(ALE)也在迅速实现大规模应用。区域选择性沉积 (ASD) 通常采用沉积和蚀刻相结合的方法,也很受关注。原子层退火等其他原子尺度工艺也在探索之中。然而,这些方法尚未充分发挥控制原子位置和键合构型的潜力,而这正是目标器件设计所需要的。我们需要在分子工程方面取得新的进展,包括前分子的设计与合成、新型钝化化学物质的开发、原子和基于人工智能的建模、基于 ALD 自限性原理的定向化学合成以及尚未实现的新型 ML 控制策略。
障碍/挑战
在单个自限制 ALD 循环中,薄膜的生长程度取决于活性前体的结构和表面活性位点的性质。这意味着人们需要更好地了解 ALD 成核过程中的机制,以及它们如何过渡到持续生长。在形成超薄薄膜时,了解反应机制的这种转变变得更加重要。同样,ALE 中的许多机理已被描述,但仍然未知的是ALE机理如何随着蚀刻的进行而演变,或它们如何应用于超薄薄膜。设计分析和量化表面反应的可靠工具,以及在制造过程中实时监控反应的计量方法,也仍然是一项重大挑战。 在制造新器件时,需要使用暴露在表面的多种不同材料。这给原子级加工带来了挑战,因为在一种暴露材料上进行所需的反应可能导致有害结果或对相邻材料造成不必要的损害。例如,二维材料的出现带来了更多的挑战,因为二维结构是由内部的化学各向异性定义的,具有反应性边缘和相对被动的暴露表面。
ALD 和 ALE 过程中使用的反应物是具有内置原子级精度的分子,ALD 利用这种精度实现大面积的平均均匀性和一致性。一个关键的挑战是创造出具有原子精度的新的可行和可扩展的低温工艺,以实现固体薄膜和材料的连接。在后端应用中,保持低温(<400°C)对于避免掺杂剂和金属在底层扩散至关重要。因此,与外延生长等高温制程不同,低温限制了平衡热力学可用于驱动预期结果的程度。在 ALE 过程中,还必须避免蚀刻剂物种扩散到非蚀刻区域。此外,ALD 和 ALE 本身具有随机性,因此空间位阻和其他分子效应会导致原子尺度上的内在不均匀性。随着特征尺寸不断接近分子尺寸,了解 ALD 和 ALE 过程中的分子尺度随机现象将非常重要。
可能的解决方案
化学选择性:确定、促进、分析和量化 ALD 和 ALE 中化学选择性的方法是未来加工的重中之重。要提高选择性,包括 ASD 和选择性蚀刻,需要平衡基本热力学驱动力和化学反应速率。表面钝化可以阻止不希望发生的、能量上有利的反应。但是,如果可以提高所需的过程的速率,以限制不需要的辅助成核程度,那么通过表面控制来实现固有选择性(不需要分子钝化)可能会更有利。虽然 ALD 可以在高纵横比表面上以亚单层或原子级精度控制均匀薄膜的厚度,但 ASD 实现的化学选择性也可能为控制横平级的"蘑菇"生长提供途径。研究人员正开始了解非反应表面上的前体相互作用如何影响所产生的 ASD 图案的形状和横向过度生长的程度。量化图案形状的更好方法(如垂直选择性分析)可以带来新的认识,解决 ALD 和 ALE 过程中随机表面反应的基本限制。此外,ASD 的大多数研究都集中在 "双色"过程,即起始表面有两种暴露材料(即两种颜色),一种新材料沉积在一种颜色上,而不是另一种颜色上。更复杂的 "多材料ASD "需要新的方法来结合多种ASD工艺和材料,而 "多色自动沉积 "则涉及更复杂的起始图案。此外,使用 ASD 和光图案化技术的 "颜色添加 ASD "方案可以构建复杂的 3D 电路,步骤更少,对齐效果更好。
前体和工艺协同设计:前驱体和工艺的协同设计是进一步研究的一个重要方向。对前驱体稳定性、易失性和反应性的新认识,包括新型 Hf 化合物的开发等,推动了 ALD 工艺和 ALD 集成到半导体制造中的重大进展。例如,专门设计用于在所需表面上进行选择性反应的前驱体将具有很高的价值。当在预先设计的反应条件下使用特定的共反应物时,前驱体/工艺协同设计还能产生遵循所需的预定反应路径的反应物。这样就可以在低温下沉积稳定、低缺陷的晶体材料,用于先进的设备系统。
工艺强化:原子级加工也可受益于新的协同方法,即沉积和蚀刻相结合,作为一个重复的循环序列,或作为同时发生的共定位反应或相邻反应。化学工业已充分认识到将多个合成步骤整合到单一强化工艺中的重要性,而在电子加工领域,工艺强化方面的类似进展也非常重要。沉积和蚀刻可以通过调节温度来平衡,以控制平衡产物分布,但这种平衡通常需要高温,而在高温下往往会产生不必要的掺杂和金属扩散。结合低温工艺反应的新技术有望指导未来器件结构所需的反应途径。 化学过程建模与控制:人工智能和机器学习的新兴能力可能会为理解、设计和优化单个基本反应步骤提供新的途径,并提供将反应和复杂工艺序列与完整的制造设计相结合的手段。新的原位反应分析工具与定向人工智能分析建模相结合,对于提高生产可靠性,控制成本,以及最大限度地减少能源消耗和对环境的影响至关重要。
4.3.6 表征和计量
在未来十年中,表征和计量方法将面临新材料、结构、设备和材料工艺日益关键的测量需求的挑战。要应对这些挑战,就必须加强工艺/结构与计量之间的联系。测量需求的一个显著变化来自于三维结构的转变和复杂性的增加。对于计量设备供应商来说,有两个突出的例子非常重要,一个是 n型和 p型MOS晶体管的垂直堆叠(预计将在未来 10 多年内出现),另一个是存储器中具有明显高宽比孔的多层薄膜的堆叠。显微镜和相关表征(如电子衍射和 X 射线表征)的空间分辨率要求在数据分析方面取得进展,以便能够常规使用。这些结构的表征和计量的另一个关键方面是需要在更宽的波长范围内(从红外到紫外到 X 射线)提供纳米级结构的基本材料属性信息,包括热、机械和电气等。缺陷检测面临的挑战是需要从特征尺寸更小、纵横比更高的器件中提供具有统计意义的信息。需要机器学习和人工智能来帮助实现计量设备控制、数据分析和配方创建。NIST 具有独特的能力,能够进行新测量方法的研发,并提供关键的标准和参考材料。关键机构和合作伙伴可以帮助推动生态系统的发展,从而实现快速规模扩展和混合计量等概念。这将通过基础设施的发展得到进一步加强。
编辑:黄飞
-
处理器
+关注
关注
68文章
20149浏览量
247170 -
CMOS
+关注
关注
58文章
6188浏览量
241582 -
存储器
+关注
关注
39文章
7715浏览量
170854 -
蚀刻
+关注
关注
10文章
428浏览量
16463 -
EUV
+关注
关注
8文章
614浏览量
88527
原文标题:美国眼中的数字处理器路线图
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
靠谱不?分析师自制苹果2013年产品路线图
物联网学习路线图
Intel公布2021年CPU架构路线图及封装技术
《智能网联汽车技术路线图 2.0》部分核心内容介绍
未来10年智能传感器怎么发展?美国发布最新MEMS路线图






 工商网监
工商网监
评论