 基于M55H的定制化backbone模型AxeraSpine
基于M55H的定制化backbone模型AxeraSpine

一
背景
Backbone模型是各种视觉任务训练的基石,视觉任务模型的性能和模型的速度都受backbone模型的影响,良好的backbone模型可以有效提高视觉任务模型的性能和精度。因此设计优良的backbone模型对视觉任务模型的表现至关重要。目前存在低延迟且高性能的开源模型已经有很多,但这些模型的设计往往只考虑到了理论计算量,并没有和实际的硬件条件相结合,因此这些模型部署到实际的硬件上,并不能发挥最大的速度潜能。针对这个挑战,为了发挥backbone模型的最大潜力,我们在M55H平台上,基于MobileNetV2模型定制了适用于M55H平台的backbone模型AXSpine系列,相比于原始MobileNetV2模型,AXSpine-Middle在精度提升的同时,速度提升了50%,硬件的MAC利用率大幅提高,在多个具体任务上达到80%以上。另外还有多组通过裁剪或者扩充的AXSpine系列模型提供,以供不同延迟和精度要求的视觉任务进行选择。
二
性能指标
以下展示AXSpine-Middle模型和MobileNetV2模型在爱芯元智M55H平台上不同分辨率的性能对比,数据集采用ImageNet数据集,精度均在224x224分辨率条件下进行测试,更多AXSpine模型指标在文章末尾表格中:
| 模型名称 | Input shape | acc1(224 x 224 标准输入条件下) | M55H 帧率(@vnpu111) |
| MobileNetV2 | 1x3x576x320 | 71.88 | 124 fps |
| MobileNetV2 | 1x3x288x160 | 71.88 | 373.7 fps |
| AXSpine-Middle | 1x3x576x320 | 72.87 | 186 fps |
| AXSpine-Middle | 1x3x1280x720 | 72.87 | 36.5 fps |
| AXSpine-Middle | 1x3x1920x1080 | 72.87 | 19.4 fps |
三
相关模型介绍
3.1 MobileNetV2
MobileNetV2是google提出的用于移动端的backbone模型,具有精度高、计算量小的特点,在移动端设备上推理效果显著。MobileNetV2模型的基本组成块为倒置残差卷积,由两组1x1的卷积和一组3x3的depthwise卷积构成。1x1卷积主要作用为对depthwise卷积做升/降维,3x3的depthwise卷积则在升维的空间上进行卷积运算,这种架构可以在保证表达能力的同时有效地增强计算效率。随后,这种倒置残差卷积结构进行若干次的堆叠,构造成为MobileNetV2模型。
3.2 地平线相关模型
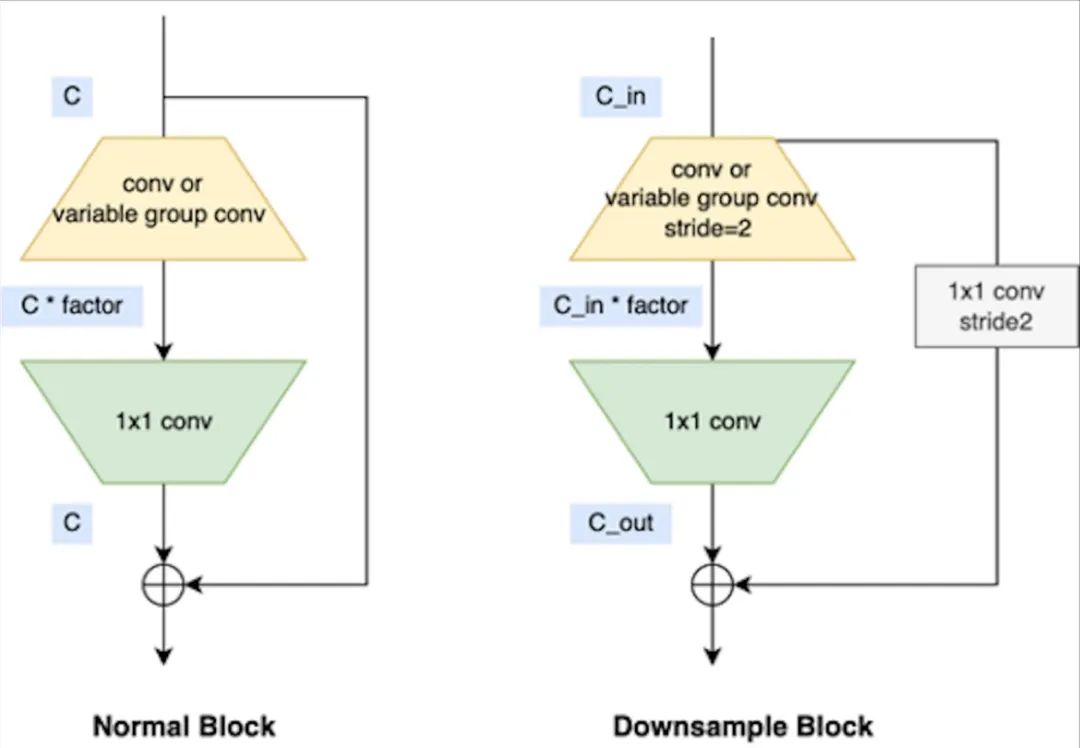
地平线公司也在自身平台上专门对backbone模型进行了优化,并推出了VarGENet和MixVarGENet等系列模型,其基本块如下图所示:

3.3 特斯拉相关模型
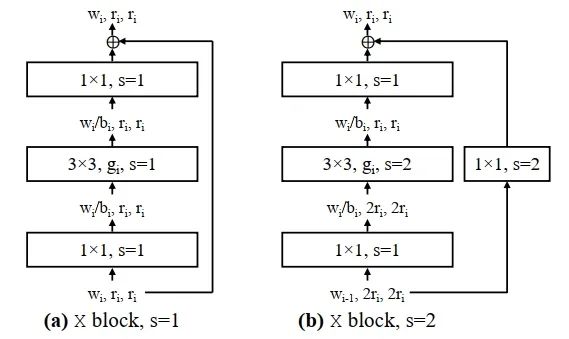
特斯拉相关模型为RegNet,RegNet为何凯明的相关工作,旨在用超参数搜索的方式,指导模型设计的相关工作,在低运算量的条件下,取得了相对优良的精度,由于没有用到depthwise卷积,在GPU模型上表现良好,被特斯拉硬件采用。其基本结构与resnet等同,如下所示:
四
模型优化
相对于MobileNetV2官方实现,AXSpine模型做了以下改动:
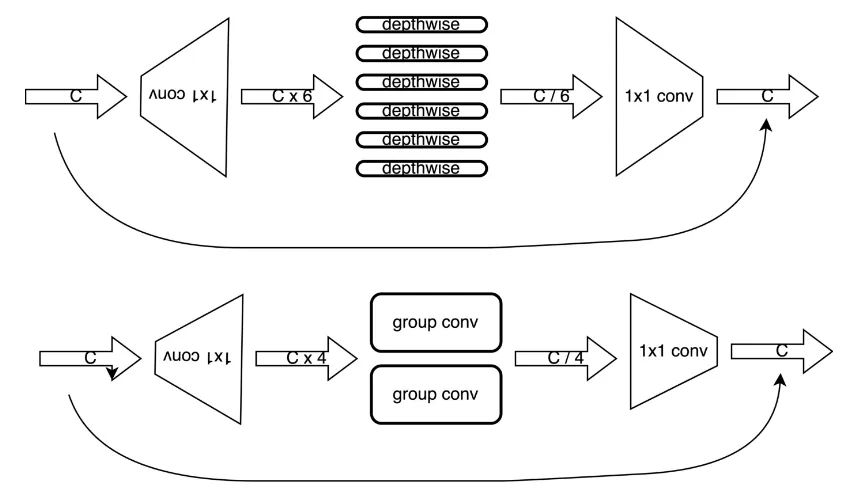
●将MobileNetV2的所有的depthwise卷积修改为小channel size的group卷积;
●将模型第二层的倒置残差卷积替换为一个简单的3x3 conv层;
●对不满足硬件通道对齐的层进行硬件通道对齐;
● 减小部分层的expand_ratio提高运算速度;
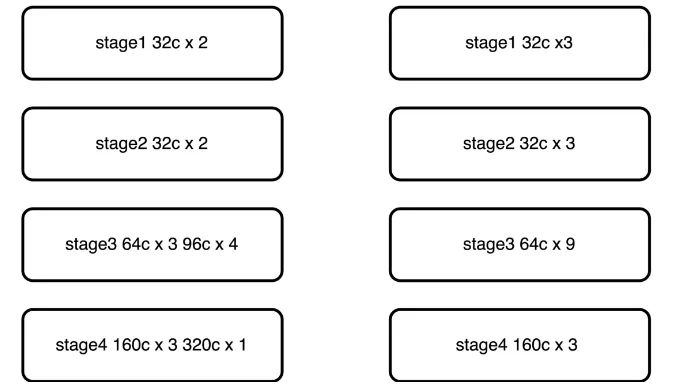
● 将原有的5层stage结构,仿照convnext修改为4层stage结构3393,速度提升,精度降低。
五
改动详细说明
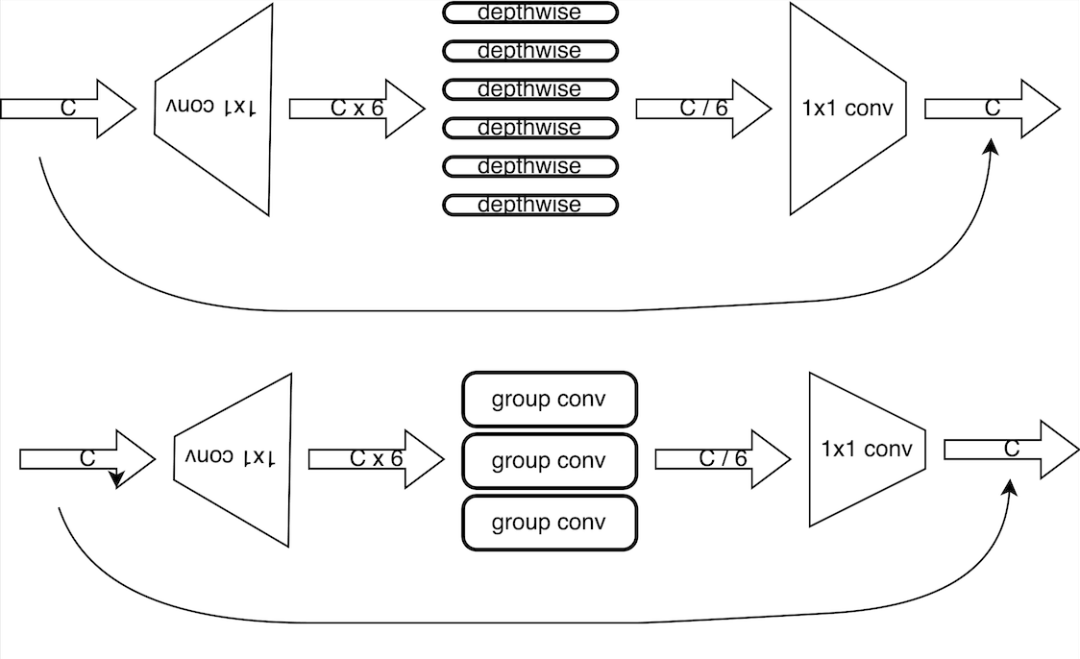
5.1 depthwise卷积修改为group卷积
由于边缘侧芯片的depthwise卷积的支持往往比较低效,这导致使用depthwise卷积的MobileNetV2无法发挥理论计算效率,在这里将depthwise卷积修改为group卷积,增强模型的表达能力,由于芯片组卷积,在特定channel的情况最为高效,因此将所有的depthwise卷积修改为特定channel数的group卷积。
5.2 替换第二层倒置残差卷积
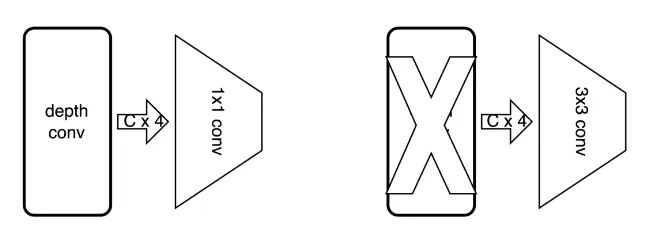
MobileNetV2的第一层为一个3x3的普通卷积,第二层为一个expand_ratio = 1 的倒置残差卷积,在原有的MobileNetV2设计中,使用倒置残差卷积的目的是为了减少计算量,然而当修改为group卷积后,运算量反倒大幅增加,因此将第二层的倒置残差卷积的两个堆叠的卷积层,修改为单个普通的3x3卷积。
5.3 对不满通道对齐的卷积进行对齐
硬件单元在计算的过程中,需要进行数据对齐,如果不满足数据对齐条件,就会降低运算效率,M55H硬件也是一样。因此,为了充分利用硬件的计算能力,需要对不满足channel对齐的层进行对齐操作,MobileNetV2模型中,部分层不满足硬件对齐条件,这里需要对不满足硬件对齐的层进行向上补齐操作,不影响性能,表达能力有所提升。
5.4 减小expand_ratio
由于原有的depthwise卷积被替换成了group卷积,模型的表达能力大幅增强,而我们修改MobileNetV2模型的最终目的是为了在保证精度的情况下,提升速度,因此在此处对expand_ratio进行消减,将expand_ratio从6修改为4,第二层的expand_ratio由4再消减为2,理论上模型的计算量减少约30%,这种expand_同时也考虑到了M55H的调度特性,在实际的调度过程中,由于各层特征图的大小得到了均衡,整体调度效率也得到了提升。
5.5 修改模型stage排布
借鉴convnext文章中的的思路,模型应当包含有4个stage,每个stage的比例大概为13:1较优,基于此判断,对MobileNetV2模型的stage进行重新划分,将原有的stage排布按照39:3进行排列,相比于直接削减channel数提升速度的方式,修改stage对模型精度的损伤较小,修改见下图所示:
六
总结
经过对MobilenetV2模型的适应性改动,爱芯元智发布了基于M55H芯片平台的定制化模型AXSpine,相比于原版MobilenetV2模型,AXSpine-Middle模型具有更高的精度和达到50%提升的速度。得益于爱芯元智M55H平台软硬件联合设计优化,经过改良后的AXSpine模型相较业界友商在单位算力情况下,展现出了强大的性能和延迟表现。此外除了AXSpine-Middle模型以外,还有若干组模型上架,以满足不同的延迟和精度需求,总结表格如下,以下模型目前已应用于多组视觉任务中,欢迎使用:
| 模型名称 | Input shape | acc1(224 x 224 标准输入条件下) | M55H 帧率(@vnpu111) |
| MobileNetV2 | 1x3x576x320 | 71.88 | 124 fps |
| AXSpine-Small | 1x3x576x320 | 71.59 | 227 fps |
| AXSpine-Middle | 1x3x576x320 | 72.87 | 186 fps |
| AXSpine-Big | 1x3x576x320 | 75.31 | 131 fps |
审核编辑:刘清
-
GPU芯片
+关注
关注
1文章
307浏览量
6553
原文标题:爱芯分享 | 基于M55H的定制化backbone模型AxeraSpine
文章出处:【微信号:爱芯元智AXERA,微信公众号:爱芯元智AXERA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
SDIO 初始化卡在带有 IW610 模块的定制板上,初始化SDIO接口时,程序会陷入循环,为什么?
2026年快速温变箱采购趋势:智能化、定制化、节能化如何落地?

爱芯元智高阶智能驾驶芯片M97回片并成功点亮
新唐科技基于端侧AI MCU M55M1的智慧门禁解决方案介绍

定制灌封胶_特殊场景灌封胶定制化服务流程与案例

芯伯乐700mA线性稳压器XBLW L78M05H/L78M12H:稳定可靠,简化电源设计

电能质量在线监测装置如何进行定制化与联动应用?
如何使用rt-thread studio中,使用 定制化的SDK建立工程?
【内测活动同步开启】这么小?这么强?新一代大模型MCP开发板来啦!
DS-HR1M H00-CN-V2
集成Docker,解锁 HMI/网关的定制化应用

定制化SoC阵列设计




评论