 8G显存一键训练,解锁Llama2隐藏能力!XTuner带你玩转大模型
8G显存一键训练,解锁Llama2隐藏能力!XTuner带你玩转大模型

自 ChatGPT 发布以来,大模型的强大让人们看见了通用人工智能的曙光,各个科技大厂也纷纷开源自家的大语言模型。然而,大模型也意味着高昂的硬件成本,让不少平民玩家望而却步。
为了让大模型走入千家万户,赋能百业,上海人工智能实验室开发了低成本大模型训练工具箱 XTuner,旨在让大模型训练不再有门槛。通过 XTuner,最低只需 8GB 显存,就可以打造专属于你的 AI 助手。
X 种选择
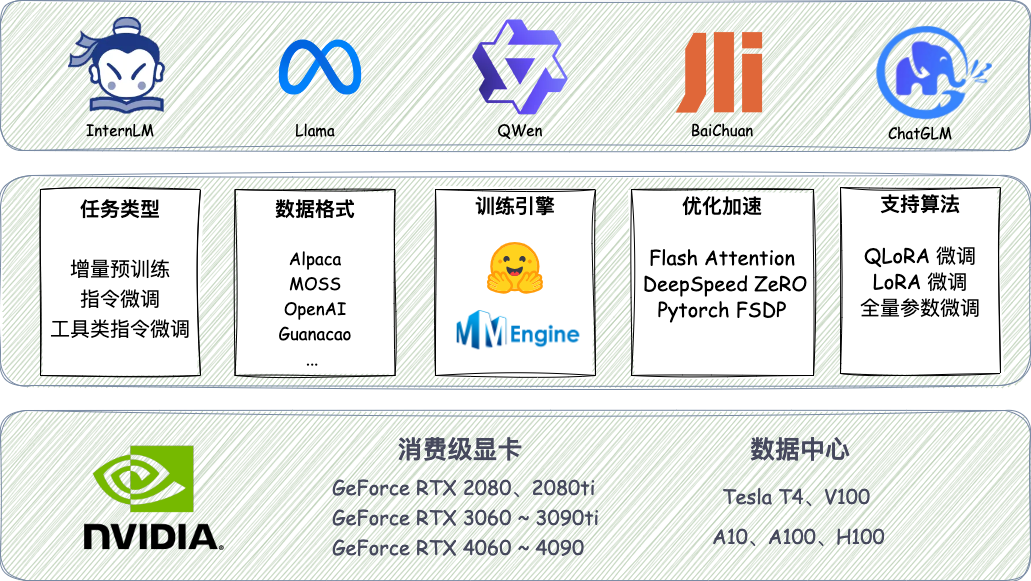
XTuner 提供了丰富的功能,上图中的各项功能都可以随意组合搭配。
除单点功能外,XTuner 还有以下三个黑科技,让开发者可以做到真正的“面向数据”工作。
高效的数据引擎
XTuner 适配了多个热门开源数据集格式,开发者如已有对应格式的数据集,可以直接使用,并支持多种格式数据源的混合使用:
Alpaca 格式,斯坦福大学开源数据集的格式,也是社区开源项目使用较多的一种格式
MOSS 格式,复旦大学开源指令微调数据集的格式,包含多轮对话和工具调用
Gunacao 格式,QLoRA 项目中所使用数据集的格式
OpenAI 格式,GPT-3.5-Turbo Finetune 接口要求的数据集格式
更多数据集格式正在持续添加中......
pip install xtuner # 训练混合了 Alpaca 格式和 Gunacao 格式的数据 xtuner train internlm_7b_qlora_alpaca_enzh_oasst1_e3
除了支持多种数据集格式外,XTuner 还针对大语言模型数据的特点,对各种数据集格式做了充分的解耦,相较于其他的 Finetune 开源项目,可以在不破坏 Chat 模型对话模版的情况下,对 Chat 模型进行 Finetune。
pip install xtuner # 不破坏 Chat 模型对话模版,继续增量指令微调 xtuner train internlm_chat_7b_qlora_oasst1_e3
针对 GPU 计算特点,在显存允许的情况下,XTuner 支持将多条短数据拼接至模型最大输入长度,以此最大化 GPU 计算核心的利用率,可以显著提升训练速度。例如,在使用 oasst1 数据集微调 Llama2-7B 时,数据拼接后的训练时长仅为普通训练的 50%。
多种训练引擎
XTuner 首次尝试将 HuggingFace 与 OpenMMLab 进行结合,兼顾易用性和可配置性。支持使用 MMEngine Runner 和 HuggingFace Trainer 两种训练引擎,开发者如有深度定制化需求,可根据使用习惯灵活配置。
pip install xtuner # 使用 MMEngine Runner 训练 xtuner train internlm_7b_qlora_oasst1_e3 # 使用 HugingFace Trainer 训练 xtuner train internlm_7b_qlora_oasst1_e3_hf
一键启动训练
XTuner 内置了增量预训练、单轮&多轮对话指令微调、工具类指令微调的标准化流程,让开发者只需聚焦于数据本身。
同时, XTuner 集成了 QLoRA、DeepSpeed 和 FSDP 等技术,提供各种尺寸模型在各种规格硬件下的训练解决方案,通过 XTuner 一键式启动训练,仅需 8GB 显存即可微调 7B 模型。
pip install 'xtuner[deepspeed]' # 8G 显存微调 Llama2-7B xtuner train llama2_7b_qlora_oasst1_512_e3 --deepspeed deepspeed_zero2
基于此,开发者可以专注于数据,其他环节放心交给 XTuner,抽出更多精力去奔向大模型的星辰大海!
X 种玩法
通过 XTuner,开发者可以给大模型添加插件,补足大模型欠缺的能力,甚至获得某些 ChatGPT 才有的技能。
XTuner 在 HuggingFace Hub 上提供了丰富的大模型插件,以下示例都可以在 Hub 中找到,欢迎大家下载体验!
ColoristLlama -- 你的专属调色师
通过在少量颜色注释数据集上对 Llama2-7B 进行指令微调训练,XTuner 成功解锁了其调色能力。最终得到的模型甚至可以像“你的甲方”一样反复修订!


pip install xtuner xtuner chat hf meta-llama/Llama-2-7b-hf --adapter xtuner/Llama-2-7b-qlora-colorist --prompt-template colorist
Llama "联网" -- 更可靠及时的回答
借助 XTuner 及插件开源数据集,我们还解锁了 Llama 2、QWen 等开源模型的隐藏能力, 使其可以像 ChatGPT 一样联网搜索、调用工具,获得更可靠的回复。


-
gpu
+关注
关注
28文章
5283浏览量
136105 -
显存
+关注
关注
0文章
112浏览量
14116 -
大模型
+关注
关注
2文章
3797浏览量
5280
原文标题:8G显存一键训练,解锁Llama2隐藏能力!XTuner带你玩转大模型
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
零基础手写大模型资料2026
DP1323EL的电动车解锁方案:超高速读写,提升电动车一键解锁体验
【CIE全国RISC-V创新应用大赛】基于 K1 AI CPU 的大模型部署落地
RA8P1部署ai模型指南:从训练模型到部署 | 本周六

基于DP1323EL的电动车解锁方案:超高速读写,提升电动车一键解锁体验
基于DP1323EL的电动车解锁方案:超高速读写,提升电动车一键解锁体验
在Ubuntu20.04系统中训练神经网络模型的一些经验
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率

大模型推理显存和计算量估计方法研究
HarmonyOS应用一键置灰指南
群晖发布AI模型全流程存储解决方案,破局训练效率与数据孤岛难题



评论