 语言大模型内部究竟是如何工作的?
语言大模型内部究竟是如何工作的?

OneFlow编译
当ChatGPT在去年秋天推出时,在科技行业乃至世界范围内引起了轰动。当时,机器学习研究人员尝试研发了多年的语言大模型(LLM),但普通大众并未十分关注,也没有意识到它们变得多强大。
如今,几乎每个人都听说过LLM,并有数千万人用过它们,但是,了解工作原理的人并不多。你可能听说过,训练LLM是用于“预测下一个词”,而且它们需要大量的文本来实现这一点。但是,解释通常就止步于此。它们如何预测下一个词的细节往往被视为一个深奥的谜题。
其中一个原因是,这些系统的开发方式与众不同。一般的软件是由人类工程师编写,他们为计算机提供明确的、逐步的指令。相比之下,ChatGPT是建立在一个使用数十亿个语言词汇进行训练的神经网络之上。
因此,地球上没有人完全理解LLM的内部工作原理。研究人员正在努力尝试理解这些模型,但这是一个需要数年甚至几十年才能完成的缓慢过程。
然而,专家们确实对这些系统的工作原理已有不少了解。本文的目标是将这些知识开放给广大受众。我们将努力解释关于这些模型内部工作原理的已知内容,而不涉及技术术语或高级数学。
我们将从解释词向量(word vector)开始,它是语言模型表示和推理语言的一种令人惊讶的方式。然后,我们将深入探讨构建ChatGPT等模型的基石Transformer。最后,我们将解释这些模型是如何训练的,并探讨为什么要使用庞大的数据量才能获得良好的性能。
1
词向量
要了解语言模型的工作原理,首先需要了解它们如何表示单词。人类用字母序列来表示英文单词,比如C-A-T表示猫。语言模型使用的是一个叫做词向量的长串数字列表。例如,这是一种将猫表示为向量的方式:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
(注:完整的向量长度实际上有300个数字)
为什么要使用如此复杂的表示法?这里有个类比,华盛顿特区位于北纬38.9度,西经77度,我们可以用向量表示法来表示:
• 华盛顿特区的坐标是[38.9,77]
• 纽约的坐标是[40.7,74]
• 伦敦的坐标是[51.5,0.1]
• 巴黎的坐标是[48.9,-2.4]
这对于推理空间关系很有用。你可以看出,纽约离华盛顿特区很近,因为坐标中38.9接近40.7,77接近74。同样,巴黎离伦敦也很近。但巴黎离华盛顿特区很远。
语言模型采用类似的方法:每个词向量代表了“词空间(word space)”中的一个点,具有相似含义的词的位置会更接近彼此。例如,在向量空间中与猫最接近的词包括狗、小猫和宠物。用实数向量表示单词(相对于“C-A-T”这样的字母串)的一个主要优点是,数字能够进行字母无法进行的运算。
单词太复杂,无法仅用二维表示,因此语言模型使用具有数百甚至数千维度的向量空间。人类无法想象具有如此高维度的空间,但计算机完全可以对其进行推理并产生有用的结果。
几十年来,研究人员一直在研究词向量,但这个概念真正引起关注是在2013年,那时Google公布了word2vec项目。Google分析了从Google新闻中收集的数百万篇文档,以找出哪些单词倾向于出现在相似的句子中。随着时间的推移,一个经训练过的神经网络学会了将相似类别的单词(如狗和猫)放置在向量空间中的相邻位置。
Google的词向量还具有另一个有趣的特点:你可以使用向量运算“推理”单词。例如,Google研究人员取出最大的(biggest)向量,减去大的(big)向量,再加上小的(small)向量。与结果向量最接近的词就是最小的(smallest)向量。
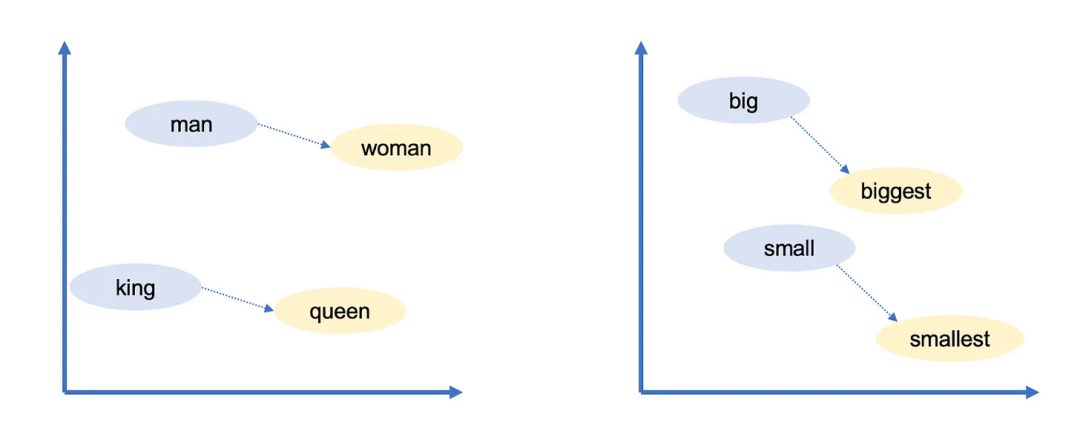
你可以使用向量运算来做类比!在这个例子中,大(big)与最大的(biggest)的关系,类似于小(small)与最小的(smallest)的关系。Google的词向量捕捉到了许多其他的关系:
• 瑞士人与瑞士类似于柬埔寨人与柬埔寨。(国籍)
• 巴黎与法国类似于柏林与德国。(首都)
• 不道德的与道德的类似于可能的与不可能的。(反义词)
• Mouse(老鼠)与mice(老鼠的复数)类似于dollar(美元)与dollars(美元的复数)。(复数形式)
• 男人与女人类似于国王与女王。(性别角色)
因为这些向量是从人们使用语言的方式中构建的,它们反映了许多存在于人类语言中的偏见。例如,在某些词向量模型中,(医生)减去(男人)再加上(女人)等于(护士)。减少这种偏见是一个很新颖的研究领域。
尽管如此,词向量是语言模型的一个有用的基础,它们编码了词之间微妙但重要的关系信息。如果一个语言模型学到了关于猫的一些知识(例如,它有时会去看兽医),那同样的事情很可能也适用于小猫或狗。如果模型学到了关于巴黎和法国之间的关系(例如,它们共用一种语言),那么柏林和德国以及罗马和意大利的关系很可能是一样的。
2
词的意义取决于上下文
像这样简单的词向量方案并没有捕获到自然语言的一个重要事实:词通常有多重含义。
例如,单词“bank”可以指金融机构或河岸。或者考虑以下句子:
•John picks up amagazine(约翰拿起一本杂志)。
•Susan works for amagazine(苏珊为一家杂志工作)。
这些句子中,“magazine”的含义相关但又有不同。约翰拿起的是一本实体杂志,而苏珊为一家出版实体杂志的机构工作。
当一个词有两个无关的含义时,语言学家称之为同音异义词(homonyms)。当一个词有两个紧密相关的意义时,如“magazine”,语言学家称之为多义词(polysemy)。
像ChatGPT这样的语言模型能够根据单词出现的上下文以不同的向量表示同一个词。有一个针对“bank(金融机构)”的向量,还有一个针对“bank(河岸)”的向量。有一个针对“magazine(实体出版物)”的向量,还有一个针对“magazine(出版机构)”的向量。正如你预想的那样,对于多义词的含义,语言模型使用的向量更相似,而对于同音异义词的含义,使用的向量则不太相似。
到目前为止,我们还没有解释语言模型是如何做到这一点——很快会进入这个话题。不过,我们正在详细说明这些向量表示,这对理解语言模型的工作原理非常重要。
传统软件的设计被用于处理明确的数据。如果你让计算机计算“2+3”,关于2、+或3的含义不存在歧义问题。但自然语言中的歧义远不止同音异义词和多义词:
• 在“the customer asked the mechanic to fixhiscar(顾客请修理工修理他的车)”中,“his”是指顾客还是修理工?
• 在“the professor urged the student to doherhomework(教授催促学生完成她的家庭作业)”中,“her”是指教授还是学生?
• 在“fruitflieslike a banana”中,“flies”是一个动词(指在天空中飞的水果像一只香蕉)还是一个名词(指喜欢香蕉的果蝇)?
人们根据上下文来解决这类歧义,但并没有简单或明确的规则。相反,这需要理解关于这个世界的实际情况。你需要知道修理工通常会修理顾客的汽车,学生通常完成自己的家庭作业,水果通常不会飞。
词向量为语言模型提供了一种灵活的方式,以在特定段落的上下文中表示每个词的准确含义。现在让我们看看它们是如何做到这一点的。
3
将词向量转化为词预测
ChatGPT原始版本背后的GPT-3模型,由数十个神经网络层组成。每一层接受一系列向量作为输入——输入文本中的每个词对应一个向量——并添加信息以帮助澄清该词的含义,并且更好地预测接下来可能出现的词。
让我们从一个简单的事例说起。
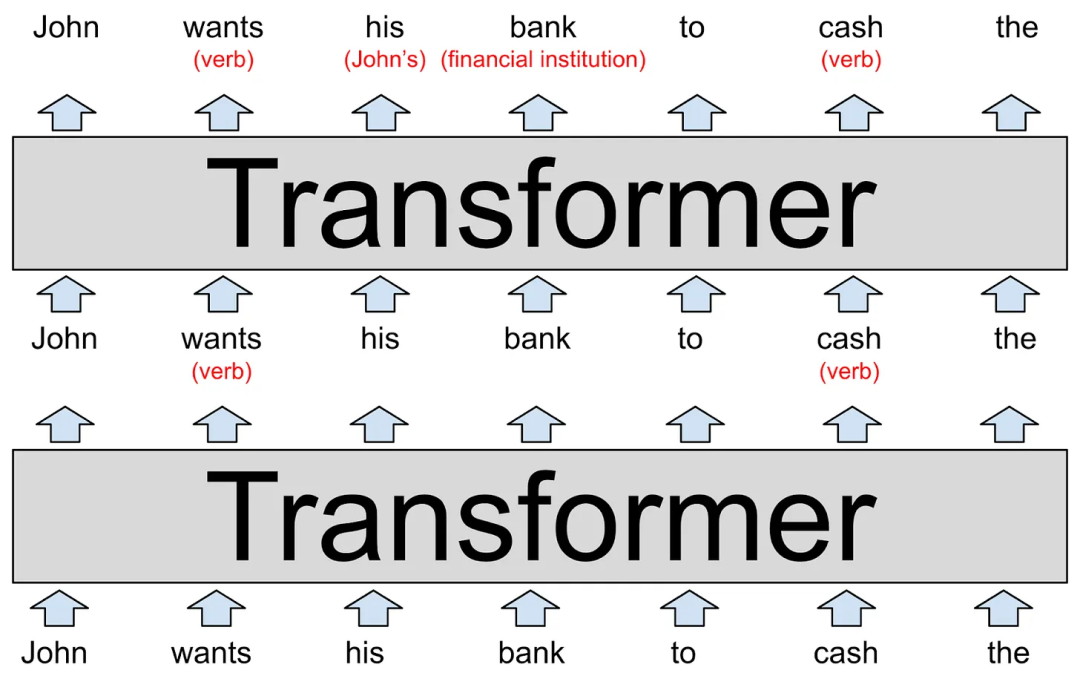
LLM的每个层都是一个Transformer,2017年,Google在一篇里程碑的论文中首次介绍了这一神经网络结构。
在图表底部,模型的输入文本是“John wants his bank to cash the(约翰想让他的银行兑现)”, 这些单词被表示为word2vec风格的向量,并传送至第一个Transformer。这个Transformer确定了wants和cash都是动词(这两个词也可以是名词)。我们用小括号中的红色文本表示这一附加的上下文,但实际上模型会通过修改词向量的方式来存储这一信息,这种方式对人类来说很难解释。这些新的向量被称为隐藏状态(hidden state),并传递给下一个Transformer。
第二个Transformer添加了另外两个上下文信息:它澄清了bank是指金融机构(financial institution)而不是河岸,并且his是指John的代词。第二个Transformer产生了另一组隐藏状态向量,这一向量反映的是该模型之前所学习的所有信息。
上述图表描绘的是一个纯假设的LLM,所以不要对细节过于较真。真实的LLM往往有更多层。例如,最强大的GPT-3版本有96层。
研究表明(https://arxiv.org/abs/1905.05950),前几层专注于理解句子的语法并解决上面所示的歧义。后面的层(为保持图表大小的可控性上述图标没有显示)则致力于对整个段落的高层次理解。
例如,当LLM“阅读”一篇短篇小说时,它似乎会记住关于故事角色的各种信息:性别和年龄、与其他角色的关系、过去和当前的位置、个性和目标等等。
研究人员并不完全了解LLM是如何跟踪这些信息的,但从逻辑上讲,模型在各层之间传递时信息时必须通过修改隐藏状态向量来实现。现代LLM中的向量维度极为庞大,这有利于表达更丰富的语义信息。
例如,GPT-3最强大的版本使用有12288个维度的词向量,也就是说,每个词由一个包含12288个的数字列表表示。这比Google在2013年提出的word2vec方案要大20倍。你可以把所有这些额外的维度看作是GPT-3可以用来记录每个词的上下文的一种“暂存空间(scratch space)”。较早层所做的信息笔记可以被后来的层读取和修改,使模型逐渐加深对整篇文章的理解。
因此,假设我们将上面的图表改为,描述一个96层的语言模型来解读一个1000字的故事。第60层可能包括一个用于约翰(John)的向量,带有一个表示为“(主角,男性,嫁给谢丽尔,唐纳德的表弟,来自明尼苏达州,目前在博伊西,试图找到他丢失的钱包)”的括号注释。同样,所有这些事实(可能还有更多)都会以一个包含12288个数字列表的形式编码,这些数字对应于词John。或者,该故事中的某些信息可能会编码在12288维的向量中,用于谢丽尔、唐纳德、博伊西、钱包或其他词。
这样做的目标是,让网络的第96层和最后一层输出一个包含所有必要信息的隐藏状态,以预测下一个单词。
4
注意力机制
现在让我们谈谈每个Transformer内部发生的情况。Transformer在更新输入段落的每个单词的隐藏状态时有两个处理过程:
1. 在注意力步骤中,词汇会“观察周围”以查找具有相关背景并彼此共享信息的其他词。
2. 在前馈步骤中,每个词会“思考”之前注意力步骤中收集到的信息,并尝试预测下一个单词。
当然,执行这些步骤的是网络,而不是个别的单词。但我们用这种方式表述是为了强调Transformer是以单词作为这一分析的基本单元,而不是整个句子或段落。这种方法使得LLM能够充分利用现代GPU芯片的大规模并行处理能力。它还帮助LLM扩展到包含成千上万个词的长段落。而这两个方面都是早期语言模型面临的挑战。
你可以将注意力机制看作是单词之间的一个撮合服务。每个单词都会制作一个检查表(称为查询向量),描述它寻找的词的特征。每个词还会制作一个检查表(称为关键向量),描述它自己的特征。神经网络通过将每个关键向量与每个查询向量进行比较(通过计算点积)来找到最佳匹配的单词。一旦找到匹配项,它将从产生关键向量的单词传递相关信息到产生查询向量的单词。
例如,在前面的部分中,我们展示了一个假设的Transformer模型,它发现在部分句子“John wants his bank to cash the”中,“his(他的)”指的是“John(约翰)”。在系统内部,过程可能是这样的:“his”的查询向量可能会有效地表示为“我正在寻找:描述男性的名词”。“John”的关键向量可能会有效地表示为“我是一个描述男性的名词”。网络会检测到这两个向量匹配,并将关于"John"的向量信息转移给“his”的向量。
每个注意力层都有几个“注意力头”,这意味着,这个信息交换过程在每一层上会多次进行(并行)。每个注意头都专注于不同的任务:
• 一个注意头可能会将代词与名词进行匹配,就像我们之前讨论的那样。
• 另一个注意头可能会处理解析类似"bank"这样的一词多义的含义。
• 第三个注意力头可能会将“Joe Biden”这样的两个单词短语链接在一起。
诸如此类的注意力头经常按顺序操作,一个注意力层中的注意力操作结果成为下一层中一个注意力头的输入。事实上,我们刚才列举的每个任务可能都需要多个注意力头,而不仅仅是一个。
GPT-3的最大版本有96个层,每个层有96个注意力头,因此,每次预测一个新词时,GPT-3将执行9216个注意力操作。
5
一个真实世界的例子
在上述两节内容中,我们展示了注意力头的工作方式的理想化版本。现在让我们来看一下关于真实语言模型内部运作的研究。
去年,研究人员在Redwood Research研究了GPT-2,即ChatGPT的前身,对于段落“When Mary and John went to the store, John gave a drink to(当玛丽和约翰去商店,约翰把一杯饮料给了)”预测下一个单词的过程。
GPT-2预测下一个单词是Mary(玛丽)。研究人员发现有三种类型的注意力头对这个预测做出了贡献:
• 他们称之为名称移动头(Name Mover Head)的三个注意力头将信息从Mary向量复制到最后的输入向量(to这个词对应的向量)。GPT-2使用此最右向量中的信息来预测下一个单词。
• 神经网络是如何决定Mary是正确的复制词?通过GPT-2的计算过程进行逆向推导,科学家们发现了一组他们称之为主语抑制头(Subject Inhibition Head)的四个注意头,它们标记了第二个John向量,阻止名称移动头复制John这个名字。
• 主语抑制头是如何知道不应该复制John?团队进一步向后推导,发现了他们称为重复标记头(Duplicate Token Heads)的两个注意力头。他们将第二个John向量标记为第一个John向量的重复副本,这帮助主语抑制头决定不应该复制John。
简而言之,这九个注意力头使得GPT-2能够理解“John gave a drink to John(约翰给了约翰一杯饮料”没有意义,而是选择了“John gave a drink to Mary(约翰给了玛丽一杯饮料)”。
这个例子侧面说明了要完全理解LLM会有多么困难。由五位研究人员组成的Redwood团队曾发表了一篇25页的论文,解释了他们是如何识别和验证这些注意力头。然而,即使他们完成了所有这些工作,我们离对于为什么GPT-2决定预测“Mary”作为下一个单词的全面解释还有很长的路要走。
例如,模型是如何知道下一个单词应该是某个人的名字而不是其他类型的单词?很容易想到,在类似的句子中,Mary不会是一个好的下一个预测词。例如,在句子“when Mary and John went to the restaurant, John gave his keys to(当玛丽和约翰去餐厅时,约翰把钥匙给了)”中,逻辑上,下一个词应该是“the valet(代客停车员)”。
假设计算机科学家们进行充足的研究,他们可以揭示和解释GPT-2推理过程中的其他步骤。最终,他们可能能够全面理解GPT-2是如何决定“Mary”是该句子最可能的下一个单词。但这可能需要数月甚至数年的额外努力才能理解一个单词的预测情况。
ChatGPT背后的语言模型——GPT-3和GPT-4——比GPT-2更庞大和复杂,相比Redwood团队研究的简单句子,它们能够完成更复杂的推理任务。因此,完全解释这些系统的工作将是一个巨大的项目,人类不太可能在短时间内完成。
6
前馈步骤
在注意力头在词向量之间传输信息后,前馈网络会“思考”每个词向量并尝试预测下一个词。在这个阶段,单词之间没有交换信息,前馈层会独立地分析每个单词。然而,前馈层可以访问之前由注意力头复制的任何信息。以下是GPT-3最大版本的前馈层结构。
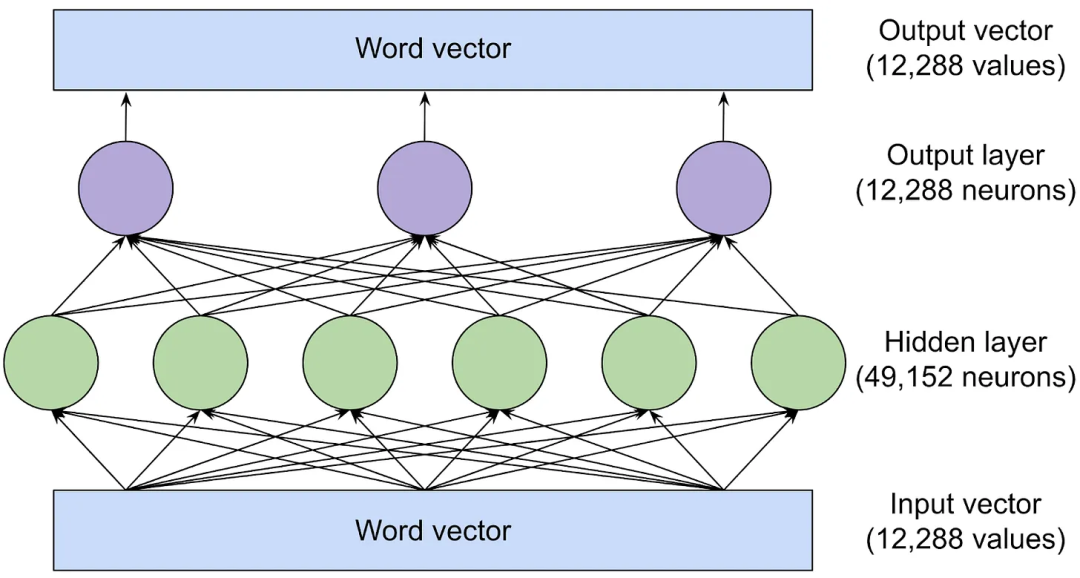
绿色和紫色的圆圈表示神经元:它们是计算其输入加权和的数学函数。
前馈层之所以强大,是因为它有大量的连接。我们使用三个神经元作为输出层,六个神经元作为隐藏层来绘制这个网络,但是GPT-3的前馈层要大得多:输出层有12288个神经元(对应模型的12288维词向量),隐藏层有49152个神经元。
所以在最大版本的GPT-3中,隐藏层有49152个神经元,每个神经元有12288个输入值(因此每个神经元有12288个权重参数),并且还有12288输出神经元,每个神经元有49152个输入值(因此每个神经元有49152个权重参数)。这意味着,每个前馈层有49152*12288+12288*49152=12亿个权重参数。并且有96个前馈层,总共有12亿*96=1160亿个参数!这相当于具有1750亿参数的GPT-3近三分之二的参数量。
来自特拉维夫大学的研究人员发现,前馈层通过模式匹配进行工作:隐藏层中的每个神经元都能匹配输入文本中的特定模式。下面是一个16层版本的GPT-2中的一些神经元匹配的模式:
• 第1层的神经元匹配以“substitutes”结尾的词序列。
• 第6层的神经元匹配与军事有关并以“base”或“bases”结尾的词序列。
• 第13层的神经元匹配以时间范围结尾的序列,比如“在下午3点到7点之间”或者“从周五晚上7点到”。
• 第16层的神经元匹配与电视节目相关的序列,例如“原始的NBC日间版本,已存档”或者“时间延迟使该集的观众增加了57%。”
正如你所看到的,在后面的层中,模式变得更抽象。早期的层倾向于匹配特定的单词,而后期的层则匹配属于更广泛语义类别的短语,例如电视节目或时间间隔。
这很有趣,因为如前所述,前馈层每次只能检查一个单词。因此,当将序列“原始的NBC日间版本,已存档”分类为“与电视相关”时,它只能访问“已存档”这个词的向量,而不是NBC或日间等词汇。可以推断,前馈层之所以可以判断“已存档”是电视相关序列的一部分,是因为注意力头先前将上下文信息移到了“已存档”的向量中。
当一个神经元与其中一个模式匹配时,它会向词向量中添加信息。虽然这些信息并不总是容易解释,但在许多情况下,你可以将其视为对下一个词的临时预测。
7
使用向量运算进行前馈网络的推理
布朗大学最近的研究展示了前馈层如何帮助预测下一个单词的优雅例子。我们之前讨论过Google的word2vec研究,显示可以使用向量运算进行类比推理。例如,柏林-德国+法国=巴黎。
布朗大学的研究人员发现,前馈层有时使用这种准确的方法来预测下一个单词。例如,他们研究了GPT-2对以下提示的回应:“问题:法国的首都是什么?回答:巴黎。问题:波兰的首都是什么?回答:”
团队研究了一个包含24个层的GPT-2版本。在每个层之后,布朗大学的科学家们探测模型,观察它对下一个词元(token)的最佳猜测。在前15层,最高可能性的猜测是一个看似随机的单词。在第16层和第19层之间,模型开始预测下一个单词是波兰——不正确,但越来越接近正确。然后在第20层,最高可能性的猜测变为华沙——正确的答案,并在最后四层保持不变。
布朗大学的研究人员发现,第20个前馈层通过添加一个将国家向量映射到其对应首都的向量,从而将波兰转换为华沙。将相同的向量添加到中国时,答案会得到北京。
同一模型中的前馈层使用向量运算将小写单词转换为大写单词,并将现在时的单词转换为过去时的等效词。
8
注意力层和前馈层有不同的功能
到目前为止,我们已经看到了GPT-2单词预测的两个实际示例:注意力头帮助预测约翰给玛丽一杯饮料;前馈层帮助预测华沙是波兰的首都。
在第一个案例中,玛丽来自用户提供的提示。但在第二个案例中,华沙并没有出现在提示中。相反,GPT-2必须“记住”华沙是波兰的首都,这个信息是从训练数据中学到的。
当布朗大学的研究人员禁用将波兰转换为华沙的前馈层时,模型不再预测下一个词是华沙。但有趣的是,如果他们接着在提示的开头加上句子“波兰的首都是华沙”,那么GPT-2就能再次回答这个问题。这可能是因为GPT-2使用注意力机制从提示中提取了华沙这个名字。
这种分工更广泛地表现为:注意力机制从提示的较早部分检索信息,而前馈层使语言模型能够“记住”未在提示中出现的信息。
事实上,可以将前馈层视为模型从训练数据中学到的信息的数据库。靠前的前馈层更可能编码与特定单词相关的简单事实,例如“特朗普经常在唐纳德之后出现”。靠后的层则编码更复杂的关系,如“添加这个向量以将一个国家转换为其首都。
9
语言模型的训练方式
许多早期的机器学习算法需要人工标记的训练示例。例如,训练数据可能是带有人工标签(“狗”或“猫”)的狗或猫的照片。需要标记数据的需求,使得人们创建足够大的数据集以训练强大模型变得困难且昂贵。
LLM的一个关键创新之处在于,它们不需要显式标记的数据。相反,它们通过尝试预测文本段落中下一个单词来学习。几乎任何书面材料都适用于训练这些模型——从维基百科页面到新闻文章再到计算机代码。
举例来说,LLM可能会得到输入“I like my coffee with cream and(我喜欢在咖啡里加奶油和)”,并试图预测“sugar(糖)”作为下一个单词。一个新的初始化语言模型在这方面表现很糟糕,因为它的每个权重参数——GPT-3最强大的版本高达1750亿个参数——最初基本上都是从一个随机数字开始。
但是随着模型看到更多的例子——数千亿个单词——这些权重逐渐调整以做出更好的预测。
下面用一个类比来说明这个过程是如何进行的。假设你要洗澡,希望水温刚刚好:不太热,也不太冷。你以前从未用过这个水龙头,所以你随意调整水龙头把手的方向,并触摸水的温度。如果太热或太冷,你会向相反的方向转动把手,当接近适当的水温时,你对把手所做的调整幅度就越小。
现在,让我们对这个类比做几个改动。首先,想象一下有50257个水龙头,每个水龙头对应一个不同的单词,比如"the"、"cat"或"bank"。你的目标是,只让与序列中下一个单词相对应的水龙头里出水。
其次,水龙头后面有一堆互联的管道,并且这些管道上还有一堆阀门。所以如果水从错误的水龙头里出来,你不能只调整水龙头上的旋钮。你要派遣一支聪明的松鼠部队去追踪每条管道,并沿途调整它们找到的每个阀门。
这变得很复杂,由于同一条管道通常供应多个水龙头,所以需要仔细思考如何确定要拧紧和松开哪些阀门,以及程度多大。
显然,如果字面理解这个例子,就变得很荒谬。建立一个拥有1750亿个阀门的管道网络既不现实也没用。但是由于摩尔定律,计算机可以并且确实以这种规模运行。
截止目前,在本文中所讨论的LLM的所有部分——前馈层的神经元和在单词之间传递上下文信息的注意力头——都被实现为一系列简单的数学函数(主要是矩阵乘法),其行为由可调整的权重参数来确定。就像我故事中的松鼠松紧阀门来控制水流一样,训练算法通过增加或减小语言模型的权重参数来控制信息在神经网络中的流动。
训练过程分为两个步骤。首先进行“前向传播(forward pass)”,打开水源并检查水是否从正确的水龙头流出。然后关闭水源,进行“反向传播(backwards pass)”,松鼠们沿着每根管道竞速,拧紧或松开阀门。在数字神经网络中,松鼠的角色由一个称为反向传播的算法来扮演,该算法“逆向(walks backwards)”通过网络,使用微积分来估计需要改变每个权重参数的程度。
完成这个过程——对一个示例进行前向传播,然后进行后向传播来提高网络在该示例上的性能——需要进行数百亿次数学运算。而像GPT-3这种大模型的训练需要重复这个过程数十亿次——对每个训练数据的每个词都要进行训练。OpenAI估计,训练GPT-3需要超过3000亿万亿次浮点计算——这需要几十个高端计算机芯片运行数月。
10
GPT-3的惊人性能
你可能会对训练过程能够如此出色地工作感到惊讶。ChatGPT可以执行各种复杂的任务——撰写文章、进行类比和甚至编写计算机代码。那么,这样一个简单的学习机制是如何产生如此强大的模型?
一个原因是规模。很难过于强调像GPT-3这样的模型看到的示例数量之多。GPT-3是在大约5000亿个单词的语料库上进行训练的。相比之下,一个普通的人类孩子在10岁之前遇到的单词数量大约是1亿个。
在过去的五年中,OpenAI不断增大其语言模型的规模。在一篇广为传阅的2020年论文中OpenAI报告称,他们的语言模型的准确性与模型规模、数据集规模以及用于训练的计算量呈幂律关系,一些趋势甚至跨越七个数量级以上”。
模型规模越大,在涉及语言的任务上表现得越好。但前提是,他们需要以类似的倍数增加训练数据量。而要在更多数据上训练更大的模型,还需要更多的算力。
2018年,OpenAI发布了第一个大模型GPT-1于。它使用了768维的词向量,共有12层,总共有1.17亿个参数。几个月后,OpenAI发布了GPT-2,其最大版本拥有1600维的词向量,48层,总共有15亿个参数。2020年,OpenAI发布了GPT-3,它具有12288维的词向量,96层,总共有1750亿个参数。
今年,OpenAI发布了GPT-4。该公司尚未公布任何架构细节,但业内普遍认为,GPT-4比GPT-3要大得多。
每个模型不仅学到了比其较小的前身模型更多的事实,而且在需要某种形式的抽象推理任务上表现出更好的性能。
例如,设想以下故事:一个装满爆米花的袋子。袋子里没有巧克力。然而,袋子上的标签写着“巧克力”而不是“爆米花”。山姆发现了这个袋子。她以前从未见过这个袋子。她看不见袋子里面的东西。她读了标签。
你可能猜到,山姆相信袋子里装着巧克力,并会惊讶地发现里面是爆米花。
心理学家将这种推理他人思维状态的能力研究称为“心智理论(Theory of Mind)”。大多数人从上小学开始就具备这种能力。专家们对于任何非人类动物(例如黑猩猩)是否适用心智理论存在分歧,但基本共识是,它对人类社会认知至关重要。
今年早些时候,斯坦福大学心理学家米Michal Kosinski发表了一项研究,研究了LLM的能力以解决心智理论任务。他给各种语言模型阅读类似刚刚引述的故事,然后要求它们完成一个句子,比如“她相信袋子里装满了”,正确答案是“巧克力”,但一个不成熟的语言模型可能会说“爆米花”或其他东西。
GPT-1和GPT-2在这个测试中失败了。但是在2020年发布的GPT-3的第一个版本正确率达到了近40%,Kosinski将模型性能水平与三岁儿童相比较。去年11月发布的最新版本GPT-3将上述问题的正确率提高到了约90%,与七岁儿童相当。GPT-4对心智理论问题的回答正确率约为95%。
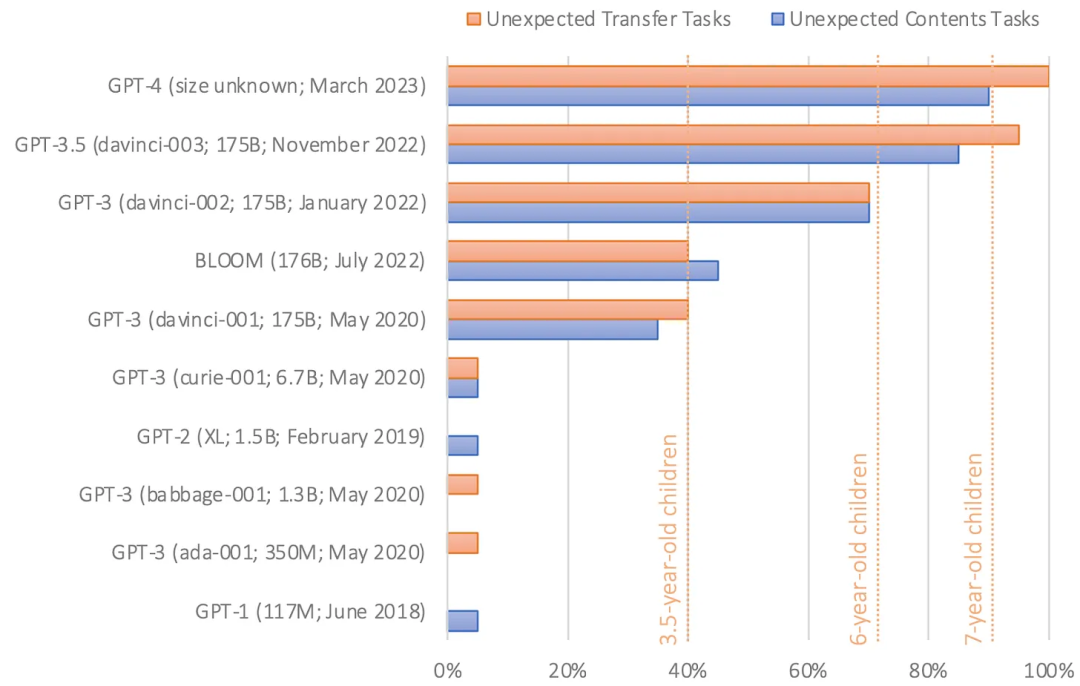
“鉴于这些模型中既没有迹象表明ToM(心智化能力)被有意设计进去,也没有研究证明科学家们知道如何实现它,这一能力很可能是自发且自主地出现的。这是模型的语言能力不断增强的一个副产品。"Kosinski写道。
值得注意的是,研究人员并不全都认可这些结果证明了心智理论:例如,对错误信念任务的微小更改导致GPT-3的性能大大下降;而GPT-3在测量心智理论的其他任务中的表现更为不稳定,正如其中肖恩所写的那样,成功的表现可能归因于任务中的混淆因素——一种“聪明汉斯(clever Hans,指一匹名为汉斯的马看似能完成一些简单的智力任务,但实际上只是依赖于人们给出的无意识线索)”效应,只不过是出现在了语言模型上而不是马身上。
尽管如此,GPT-3在几个旨在衡量心智理论的任务上接近人类的表现,这在几年前是无法想象的,并且这与更大的模型通常在需要高级推理的任务中表现更好的观点相一致。
这只是语言模型表现出自发发展出高级推理能力的众多例子之一。今年4月,微软的研究人员发表的一篇论文表示,GPT-4展示了通用人工智能的初步、诱人的迹象——即以一种复杂、类人的方式思考的能力。
例如,一位研究人员要求GPT-4使用一种名为TiKZ的晦涩图形编程语言画一只独角兽。GPT-4回应了几行代码,然后研究人员将这些代码输入TiKZ软件。生成的图像虽然粗糙,但清晰地显示出GPT-4对独角兽的外观有一定的理解。

研究人员认为,GPT-4可能以某种方式从训练数据中记住了绘制独角兽的代码,所以他们给它提出了一个后续的挑战:他们修改了独角兽的代码,移除了头角,并移动了一些其他身体部位。然后他们让GPT-4把独角兽的头角放回去。GPT-4通过将头角放在正确的位置上作出了回应:

尽管作者的测试版本的训练数据完全基于文本,没有包含任何图像,但GPT-4似乎仍然能够完成这个任务。不过,通过大量的书面文本训练后,GPT-4显然学会了推理关于独角兽身体形状的知识。
目前,我们对LLM如何完成这样的壮举没有真正的了解。有些人认为,像这样的例子表明模型开始真正理解其训练集中词的含义。其他人坚持认为,语言模型只是“随机鹦鹉”,仅仅是重复越来越复杂的单词序列,而并非真正理解它们。
这种辩论指向了一种深刻的哲学争论,可能无法解决。尽管如此,我们认为关注GPT-3等模型的经验表现很重要。如果一个语言模型能够在特定类型的问题中始终得到正确答案,并且研究人员有信心排除混淆因素(例如,确保在训练期间该语言模型没有接触到这些问题),那无论它对语言的理解方式是否与人类完全相同,这都是一个有趣且重要的结果。
训练下一个词元预测如此有效的另一个可能原因是,语言本身是可预测的。语言的规律性通常(尽管并不总是这样)与物质世界的规律性相联系。因此,当语言模型学习单词之间的关系时,通常也在隐含地学习这个世界存在的关系。
此外,预测可能是生物智能以及人工智能的基础。根据Andy Clark等哲学家的观点 ,人脑可以被认为是一个“预测机器”,其主要任务是对我们的环境进行预测,然后利用这些预测来成功地驾驭环境。预测对于生物智能和人工智能都至关重要。直观地说,好的预测离不开良好的表示——准确的地图比错误的地图更有可能帮助人们更好地导航。世界是广阔而复杂的,进行预测有助于生物高效定位和适应这种复杂性。
在构建语言模型方面,传统上一个重大的挑战是,找出最有用的表示不同单词的方式,特别是因为许多单词的含义很大程度上取决于上下文。下一个词的预测方法使研究人员能够将其转化为一个经验性问题,以此避开这个棘手的理论难题。
事实证明,如果我们提供足够的数据和计算能力,语言模型能够通过找出最佳的下一个词的预测来学习人类语言的运作方式。不足之处在于,最终得到的系统内部运作方式人类还并不能完全理解。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4845浏览量
108374 -
机器学习
+关注
关注
67文章
8570浏览量
137421 -
GPT
+关注
关注
0文章
376浏览量
17016 -
ChatGPT
+关注
关注
31文章
1608浏览量
10433 -
LLM
+关注
关注
1文章
351浏览量
1409
原文标题:通俗解构语言大模型的工作原理
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论