 使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度学习性能
使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度学习性能


NVIDIA Jetson Orin 是同类嵌入式人工智能平台中的翘楚。Jetson Orin SoC 模块以 NVIDIA Ampere 架构 GPU 为核心,但 SoC 上还有更多的计算功能:
NVIDIA Orin SoC 的功能非常强大,拥有 275 个峰值 AI TOPs,是最佳的嵌入式和汽车 AI 平台。您知道吗,这些 AI TOPs 中近 40% 来自 NVIDIA Orin 上的两个 DLA?NVIDIA Ampere GPU 拥有同类产品中最佳的吞吐量,而第二代 DLA 则拥有同类产品中最佳的能效。近年来,随着 AI 应用的快速增长,对更高效计算的需求也在不断增长。在能效始终是关键 KPI 的嵌入式方面尤其如此。
这就是 DLA 的用武之地。DLA 专门为深度学习推理而设计,可以比 CPU 更有效地执行卷积等计算密集型深度学习操作。
当集成到 SoC(如Jetson AGX Orin 或 NVIDIA DRIVE Orin)中时, GPU 和 DLA 的组合可以为您的嵌入式 AI 应用程序提供一个完整的解决方案。我们将在这篇文章中讨论深度学习加速器,让您不再错过。我们将介绍涵盖汽车和机器人领域的几个案例研究,以展示 DLA 如何帮助 AI 开发者为其应用程序添加更多功能和性能。最后,我们将介绍视觉 AI 开发者如何使用 DeepStream SDK 构建应用工作流,使用 DLA 和整个 Jetson SoC 实现最佳性能。
以下是 DLA 会产生重大影响的一些关键性能指标。
关键性能指标
在设计应用程序时,您需要满足一些关键性能指标或 KPI。例如最大性能和能效之间的设计权衡,这需要开发团队仔细分析和设计应用程序,以便在 SoC 上使用不同的 IP。
如果应用程序的关键 KPI 是延迟,则必须在一定的延迟预算下在应用程序中安排任务。您可以将 DLA 作为加速器,用于与运行在 GPU 上的计算密集型任务并行的任务。DLA 峰值性能对 NVIDIA Orin 整体深度学习(DL)性能的贡献率在 38% 至 74% 之间,具体取决于电源模式。
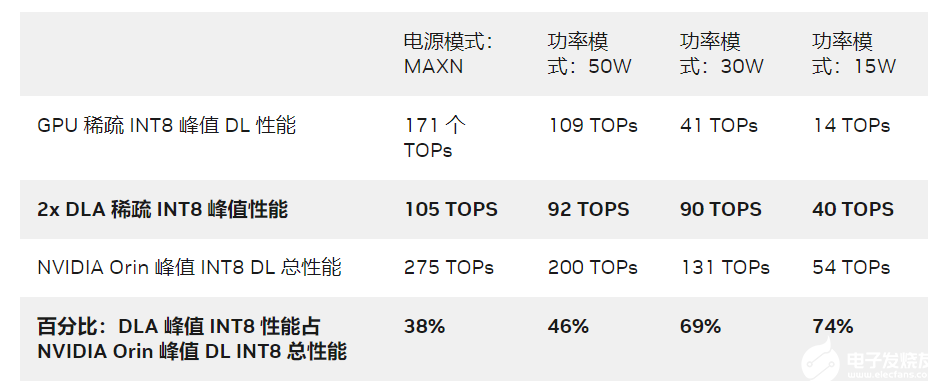
表 1. DLA 吞吐量
Jetson AGX Orin 64GB 上 30W 和 50W 功率模式的 DLA TOPs 与 NVIDIA DRIVE Orin 汽车平台上的最大时钟相当。
如果功耗是您的关键 KPI 之一,那么就应该考虑使用 DLA 来利用其功耗效率方面的优势。与 GPU 相比,每瓦 DLA 的性能平均高出 3–5 倍,这具体取决于电源模式和工作负载。以下图表显示了代表常见用例的三个模型的每瓦性能。
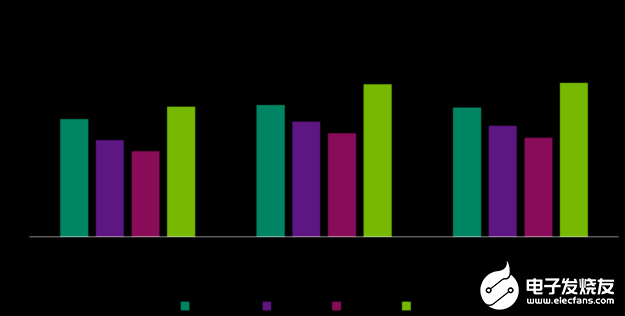
图 1. DLA 能效
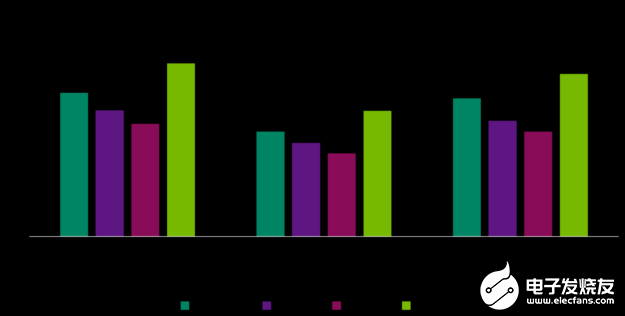
图 2. 结构化稀疏性和每瓦性能优势
换句话说,如果没有 DLA 的能效,就不可能在给定的平台功率预算下在 NVIDIA Orin 上实现高达 275 个峰值的 DL TOPs。想要了解更多信息和更多型号的测量结果,请参阅 DLA-SW GitHub 库。
以下是 NVIDIA 内部如何在汽车和机器人领域使用 DLA 提供的 AI 计算的一些案例研究。
案例研究:汽车
NVIDIA DRIVE AV是端到端的自动驾驶解决方案堆栈,可帮助汽车原始设备制造商在其汽车产品组合中添加自动驾驶和映射功能。它包括感知层、映射层和规划层,以及基于高质量真实驾驶数据训练的各种 DNN。
NVIDIA DRIVE AV 团队的工程师致力于设计和优化感知、映射,并通过利用整个 NVIDIA Orin SoC 平台规划工作流。考虑到自动驾驶堆栈中需要处理大量的神经网络和其他非 DNN 任务,它们会依靠 DLA 作为 NVIDIA Orin SoC 上的专用推理引擎来运行 DNN 任务。这一点至关重要,因为 GPU 计算能力是为处理非 DNN 任务而保留的。如果没有 DLA 计算,团队将无法达到 KPI。
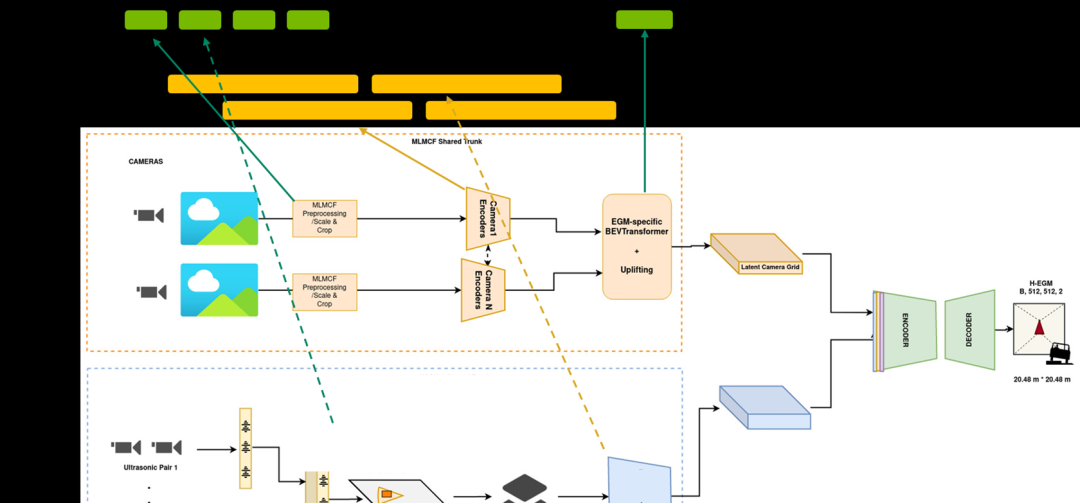
图3.感知管线的一部分
想要了解更多信息,请访问Near-Range Obstacle Perception with Early Grid Fusion:https://developer.nvidia.cn/zh-cn/blog/near-range-obstacle-perception-with-early-grid-fusion/
例如,在感知工作流中,它们有来自八个不同相机传感器的输入,整个工作流的延迟必须低于某个阈值。感知堆栈是 DNN 的重头戏,占所有计算的 60% 以上。
为了达到这些 KPI,并行工作流任务被映射到 GPU 和 DLA,其中几乎所有的 DNN 都在 DLA 上运行,而非 DNN 任务则在 GPU 上运行,以实现总体工作流的延迟目标。然后,其他 DNN 在映射和规划等其他工作流中按顺序或并行消耗输出。您可以将工作流视为一个巨大的图形,其中的任务在 GPU 和 DLA 上并行运行。通过使用 DLA,该团队将延迟降低了 2.5 倍。

图 4. 作为感知堆栈一部分的对象检测
NVIDIA 自动驾驶团队工程经理 Abhishek Bajarger 表示:“利用整个 SoC,特别是 DLA 中专用的深度学习推理引擎,使我们能够在满足延迟要求和 KPI 目标的同时,为软件堆栈添加重要功能。只有 DLA 才能做到这一点。”
案例研究:机器人
NVIDIA Isaac 是一个功能强大的端到端平台,用于开发、仿真和部署机器人开发者使用的 AI 机器人。特别是对于移动机器人来说,可用的 DL 计算、确定性延迟和电池续航能力是非常重要的因素。这就是为什么将 DL 推理映射到 DLA 非常重要的原因。
NVIDIA Isaac 团队的一组工程师开发了一个使用 DNN 进行临近分割的库。邻近分割可用于确定障碍物是否在邻近场内,并避免在导航过程中与障碍物发生碰撞。他们在 DLA 上实现了 BI3D 网络,该网络可通过立体摄像头执行二进制深度分类。
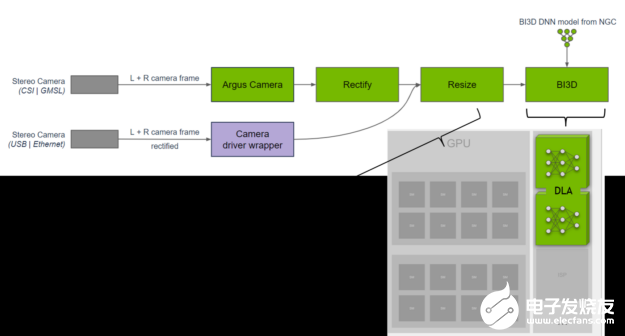
图 5. 近距离分割流水线
一个关键的 KPI 是确保从立体摄像头输入进行 30 帧/秒的实时检测。NVIDIA Isaac 团队将这些任务分配到 SoC 上,并将 DLA 用于 DNN,同时为在 GPU 上运行的硬件和软件提供功能安全多样性。想要了解更多信息,请访问NVIDIA Isaac ROS 邻近分割:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_proximity_segmentation

图 6. 使用 BI3D 对立体输入进行邻近分割
将 NVIDIA DeepStream 用于 DLA
探索 DLA 最快捷的方式是通过 NVIDIA DeepStream SDK,一个完整的流分析工具包。
如果你是一名视觉 AI 开发者,正在构建 AI 驱动的应用程序来分析视频和传感器数据,那么 DeepStream SDK 可以帮助您构建最佳的端到端工作流。对于零售分析、停车管理、物流管理、光学检测、机器人技术和体育分析等云端或边缘用例,DeepStream 可让您不费吹灰之力就能使用整个 SoC,特别是 DLA。
例如,您可以使用下表中突出显示的 Model Zoo 中的预训练模型在 DLA 上运行。在 DLA 上运行这些网络就像设置一个标志一样简单。想要了解更多信息,请访问如何使用 DLA 进行推理:https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_Quickstart.html#using-dla-for-inference
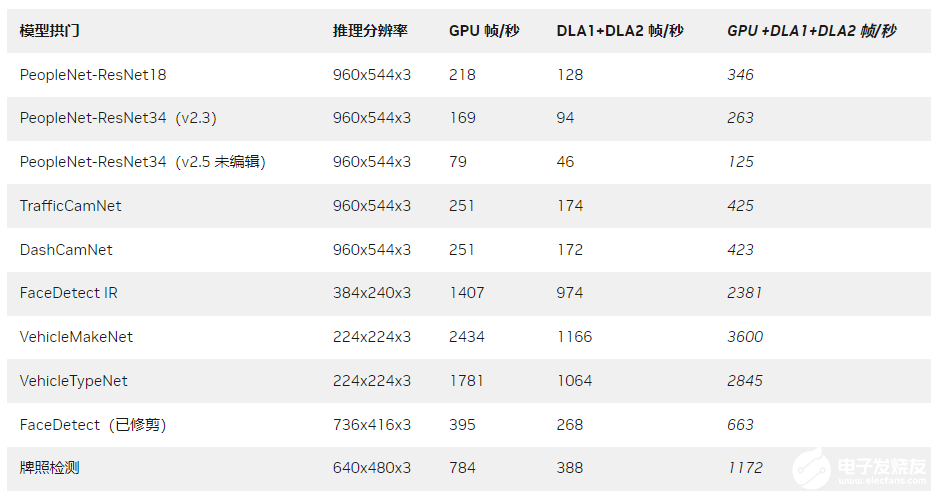
表 2. Model Zoo 网络样本
及其在 DLA 上的吞吐量
开始使用深度学习加速器
准备好深入了解了吗?有关详细信息,请参阅以下资源:
-
Jetson DLA 教程演示了基本的 DLA 工作流,帮助您开始将 DNN 部署到 DLA:https://github.com/NVIDIA-AI-IOT/jetson_dla_tutorial
-
DLA-SW GitHub存储库中有一系列参考网络,您可以使用它们来探索在 Jetson Orin DLA 上运行 DNN:https://github.com/NVIDIA/Deep-Learning-Accelerator-SW/tree/main/scripts/prepare_models
-
示例页面提供了关于如何使用 DLA 充分利用 Jetson SoC 的其他示例和资源:https://github.com/NVIDIA/Deep-Learning-Accelerator-SW/
-
DLA 论坛有其他用户的想法和反馈:https://forums.developer.nvidia.com/tag/dla
SIGGRAPH 2023
NVIDIA 精彩发布
SIGGRAPH 2023 | NVIDIA 主题演讲重磅发布精彩回顾,探索 AI 无限未来!
敬请持续关注...
SIGGRAPH 2023 NVIDIA 主题演讲中文字幕版已上线 !扫描下方海报二维码,或点击“阅读原文”即可观看,与 NVIDIA 创始人兼首席执行官黄仁勋一起探索 AI 的未来!
原文标题:使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度学习性能
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4143浏览量
99865
原文标题:使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度学习性能
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

NVIDIA Jetson模型赋能AI在边缘端落地

如何在NVIDIA Jetson AGX Thor上部署1200亿参数大模型

如何在NVIDIA Jetson Thor上提升机器人感知效率
NVIDIA Jetson系列开发者套件助力打造面向未来的智能机器人
如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务

NVIDIA Jetson AGX Thor Developer Kit开发环境配置指南
通过NVIDIA Jetson AGX Thor实现7倍生成式AI性能
NVIDIA Jetson AGX Thor开发者套件重磅发布
基于 NVIDIA Blackwell 的 Jetson Thor 现已发售,加速通用机器人时代的到来

使用u-blox NORA-W4 Wi-Fi 6模块提高工业物联网性能




评论