 深度学习在语音增强中的应用
深度学习在语音增强中的应用

随着科学技术的发展,语音作为新一代人机交互方式,成为人和智能设备、语音助手交流的重要接口,然而在真实环境中,语音信号不可避免的被各种噪声所干扰,除了各种环境噪声,声波在封闭空间中的衰减和延时反射所引起的混响等都会影响语音的感知质量,研究者将真实场景下影响语音质量的因素总结为三个方面:环境噪声、房间混响和其他说话人干扰,语音增强的目的就是消除上述三个方面的影响。语音增强是指利用音频信号处理的技术以及算法提高失真语音信号的整体感知质量或者可懂度。
语音去噪
深度学习在语音降噪中的应用广泛,根据处理语音的通道数不同,可以分为单通道降噪和多通道降噪,其中单通道语音的去噪由俄亥俄州立大学的汪德亮团队提出的基于DNN-SVM算法,后来又相继提出CRNN、DP-SARNN和Transformer等算法,Zhang等人[1]人提出了双分支神经网络DBNet同时在时域和频域上解决语音增强的问题。而深度学习在多通道语音增强中常常结合空间信息或者传统算法例如波束形成等实现去噪,例如具有代表性算法的基于掩蔽的波束形成技术[2]。利用深度学习进行语音去的算法一般包括非端到端语音降噪方法和端到端语音降噪算法。其中非端到端语音降噪的算法常用的处理方式有基于掩膜的方法和基于特征映射的方法。
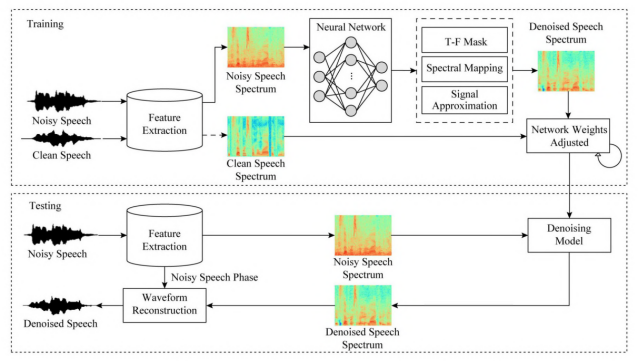
基于深度学习非端到端语音去噪方法框图
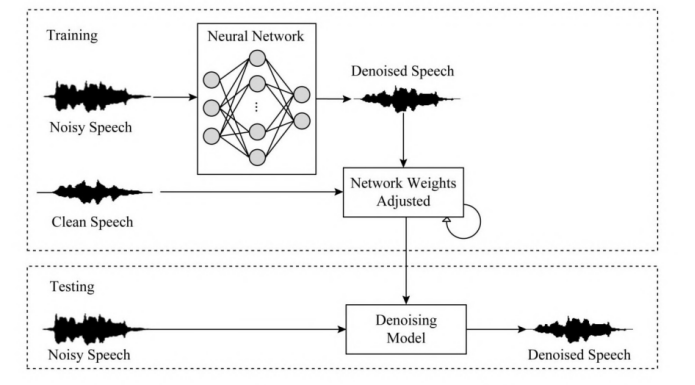
基于深度学习端到端语音去噪算法框图
基于掩膜的语音增强
基于时频掩蔽的语音增强方法将描述纯净语音与噪声之间相互关系的时频掩蔽作为学习目标,该方法假设纯净语音信号与噪声之间有一定的独立性,理想二值掩蔽(Ideal Binary Mask,IBM)是最初被引入语音增强的时频掩蔽方法,该掩蔽方法通过判断某个时频单元内语音与噪声主导情况将连续的时频单元离散化为0或1两种状态,IBM公式如下所示:
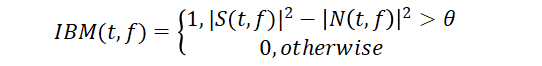
通过IBM的公式可以看出只有0、1两种取值,可以一定程度提高语音质量,但这种方法对于带噪语音的处理过于简单粗暴,会在处理过程中引入较大的噪声。
基于语音和噪声独立假设的情况下,基于比值掩蔽的方法刻画了时频单元内纯净语音能量和带噪语音能量的比值,该类掩蔽方法中常用的有理想比值掩蔽(Ideal Ratio Mask,IRM)。IRM相较于IBM从离散的状态值变为连续的状态值,相较之下可以有效的提升语音的质量和可懂度,但是缺点是利用带噪语音的相位信息对纯净语音进行了重构。
除了上述两种掩蔽方法,仍然有许多的掩蔽方法,例如基于信号能量比值的理想幅度掩蔽(Ideal Amplitude Mask,IAM),考虑相位误差的时频掩蔽方法的相位敏感掩蔽(Phase Sensitive Mask,PSM),广泛应用的复数域的复数理想比率掩蔽(Complex Ideal Ratio Mask,cIRM)以及最佳比例掩膜(Optimal Ratio Mask,ORM)等等。这些掩蔽根据语音以及噪声的幅度谱或者功率谱计算获得,通过网络计算得到估计掩蔽后,将带噪语音信号与时频掩蔽相乘得到纯净语音信号,进而得到干净语音的时域波形。
基于特征映射的方法
基于特征映射的语音增强方法是通过网络完成带噪语音特征和干净语音特征之间的映射关系,常见的特征映射包括目标幅度谱(TMS)、短时傅里叶变换幅度谱(STFT)等,通过带噪语音估计纯净语音特征,将得到的谱图与带噪语音相位结合,从而得到语音波形。另外声学特征也可以被用作特征映射深度学习的目标,例如Chen等人[3]探索了低信噪比下已经被用作语音分离和语音增强的一系列特征的表现,包括了Mel域特征中的MFCC和DSCC,线性预测特征中的PLP特征和RASTA-PLP特征,gamma域中的GF特征、GFCC特征和GFMC特征,信号自相关域中的RAS-MFCC特征、AC-MFCC特征和PAC-MFCC特征,调制域中的GFB特征和AMS特征等。Wang等人[4]提出一种单声道和多声道语音增强的复数频谱映射方法,利用DNN从带噪信号中预测纯净语音的实部和虚部,并融合波束形成算法得到在 CHiME-4语音数据集上WER较好的性能提升。
基于端到端的方法
监督语音增强大部分是在时频域进行的,端到端的语音增强对原始时域波形信号直接进行处理,由于不依赖于频域表示,避免了语音相位信息的丢失以及重构增强语音时使用带噪语音相位可能导致的性能下降问题,使得模型流程简化。Ritwik Giri等人[5]提出了带有注意力机制的U-Net应用于语音增强,在VCTK数据集上测试多信噪比情况下PESQ、SSNR等评价指标都得到了提升。
语音去混响
混响语音为信号和房间冲激响应(Room Impulse Response,RIR)的卷积,这会使得语音信号在时域和频域都发生畸变,导致语音可懂度的下降。利用深度学习的混响消除算法包括三类算法,直接预测、间接预测和联合传统算法。
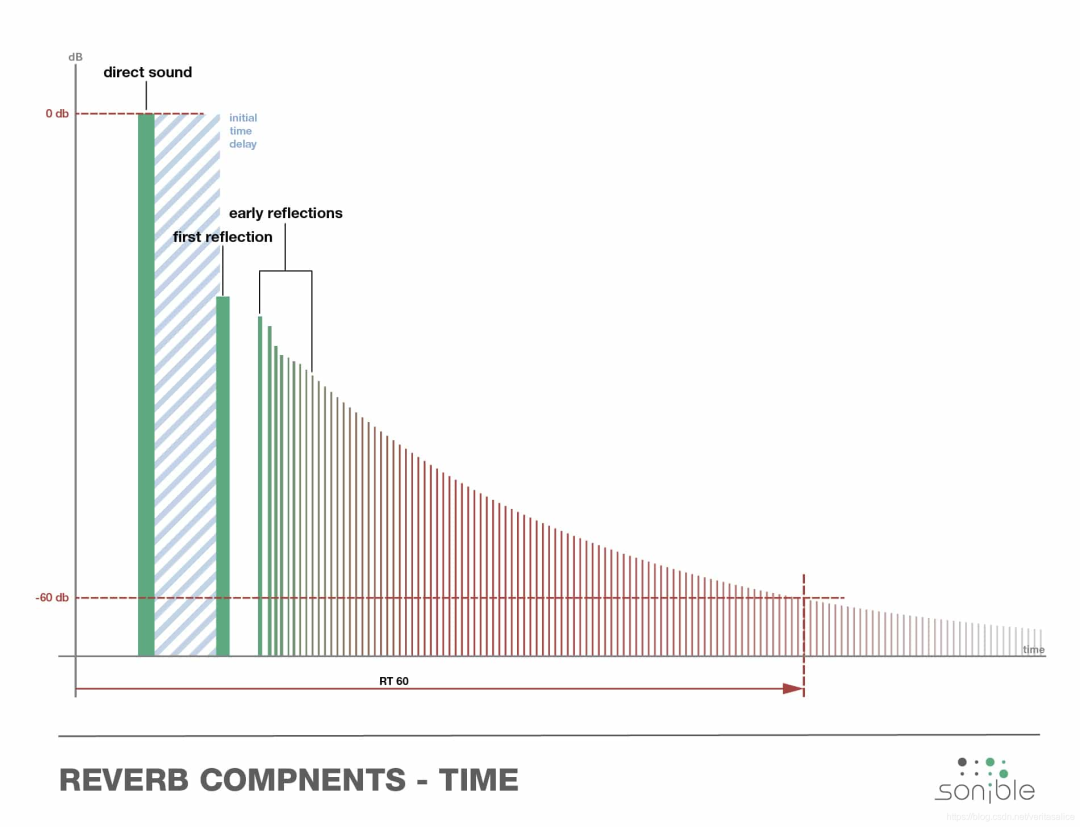
直接预测的方法为混响语音信号直接映射到纯净语音信号,间接预测的方法例如可以通过预测后期混响信号间接性得到目标语音信号,联合传统算法为将DNN与WPE等算法进行结合,通过网络预测WPE算法中间参数从而去除迭代计算的操作。Han等人[6]在2014年首先提出了基于DNN的语音去混响方法,这种方法在耳蜗图上使用谱映射,DNN被训练成从混响语音帧映射到干净语音帧。Zhao等人[7]通过LSTM预测语音信号晚期混响间接得到目标语音信号,Kinoshita K[8]通过LSTM网络预测WPE算法中的中间参数进而实现混响消除。
语音增强作为语音识别中的一项核心关键技术,广泛应用在各种场景之中,国内外研究人员针对语音增强提出了许多算法,深度学习的广泛应用也为来研究领域带来了新的突破,但是语音增强领域仍然有许多问题,例如泛化性能、相位失真问题和低信噪比下的应用效果不理想,未来的语音增强仍然充满挑战。
审核编辑:汤梓红
-
人机交互
+关注
关注
12文章
1299浏览量
58133 -
噪声
+关注
关注
13文章
1162浏览量
49432 -
SVM
+关注
关注
0文章
154浏览量
33730 -
语音增强
+关注
关注
0文章
12浏览量
8912 -
深度学习
+关注
关注
73文章
5608浏览量
124637
原文标题:深度学习在语音增强中的应用
文章出处:【微信号:硬件设计技术,微信公众号:硬件设计技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深度学习在汽车中的应用
什么是深度学习?使用FPGA进行深度学习的好处?
基于分层编码的深度增强学习对话生成
苹果Siri深度学习语音合成技术揭秘
深度学习在轨迹数据挖掘中的应用研究综述


基于深度学习的情感语音识别模型优化策略
GPU在深度学习中的应用与优势




评论