 大模型微调样本构造的trick
大模型微调样本构造的trick

开局一道面试题。
面试官:大模型微调如何组织训练样本?
你:大模型训练一问一答,一指令一输出,问题和指令可以作为prompt输入,答案作为输出,计算loss的部分要屏蔽掉pad token。
面试官:多轮对话如何组织训练样本呢?
你:假设多轮为Q1A1/Q2A2/Q3A3,那么可以转化成 Q1—>A1, Q1A1Q2->A2, Q1A1Q2A2Q3->A3三条训练样本。
面试官:这样的话一个session变成了三条数据,并且上文有依次重复的情况,这样会不会有啥问题?
你:数据中大部分都是pad token,训练数据利用效率低下。另外会有数据重复膨胀的问题,训练数据重复膨胀为 session数量*平均轮次数,且上文有重复部分,训练效率也会低下。
面试官:你也意识到了,有什么改进的方法吗?
你:有没有办法能一次性构造一个session作为训练样本呢?(思索)
面试官:提示你下,限制在decoder-only系列的模型上,利用模型特性,改进样本组织形式。
对于这个问题,我们思考下decoder-only模型有啥特点,第一点很关键的是其attention形式是casual的,casual简单理解就是三角阵,单个token只能看到其上文的信息。
如图所示:
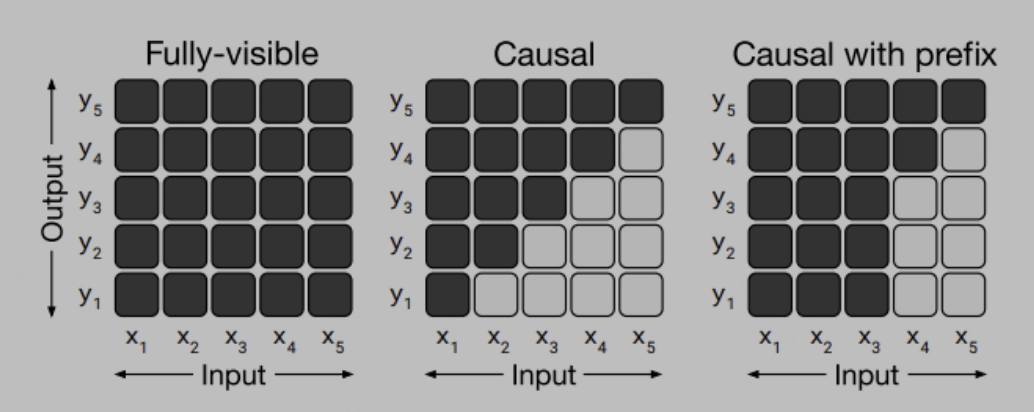
其二是postion_id是只有token次序含义而无需特定指代信息,(区别于GLM模型需要postion_id来标识生成span的位置等特殊的要求)。
有了这两点我们就可以设想,如果构造多轮对话样本的input为 Q1 A1
嗯为什么原来的chatglm不能用这种形式呢,虽然prefix attention可以推广为适应多轮训练的prefix attention形式,如图:

但是由于其postition id 无法简单按次序推广,故不能高效训练,这也是chatglm初代的很大的一个问题,导致后续微调的效果都比较一般。
现在chatglm2的代码针对这两个问题已经进行了改善,可以认为他就是典型的decoder-only模型了,具体表现为推断时候attention 是casual attention的形式,position id也退化为token次序增长。
那么好了,万事具备,只欠东风。我们据此实现了chatglm2-6b的代码微调。其核心代码逻辑为处理样本组织的逻辑,其他的就是大模型微调,大同小异了。
conversation=''
input_ids = []
labels = []
eos_id = tokenizer.eos_token_id
turn_idx = 0
for sentence in examples[prompt_column][i]:
sentence_from = sentence["from"].lower()
sentence_value = '[Round {}]
问:'.format(turn_idx) + sentence["value"] + '
答:' if sentence_from == 'human' else sentence["value"]+'
'
conversation += sentence_value
sentence_ids = tokenizer.encode(sentence_value, add_special_tokens=False)
label = copy.deepcopy(sentence_ids) if sentence_from != 'human' else [-100] * len(sentence_ids)
input_ids += sentence_ids
labels += label
if sentence_from != 'human':
input_ids += [eos_id]
labels += [eos_id]
turn_idx += 1
input_ids=tokenizer.encode('')+input_ids#addgmaskbos
labels = [-100] * 2 + labels# #add padding
pad_len = max_seq_length - len(input_ids)
input_ids = input_ids + [eos_id] * pad_len
labels = labels + [-100] * pad_len
其中有几个关键的地方,就是在开头要加上 bos和gmask,遵循模型原来的逻辑。问答提示词和轮次prompt,还有两个 保持和原模型保持一致,最后屏蔽掉pad部分的loss计算。
实测训练效果如下:
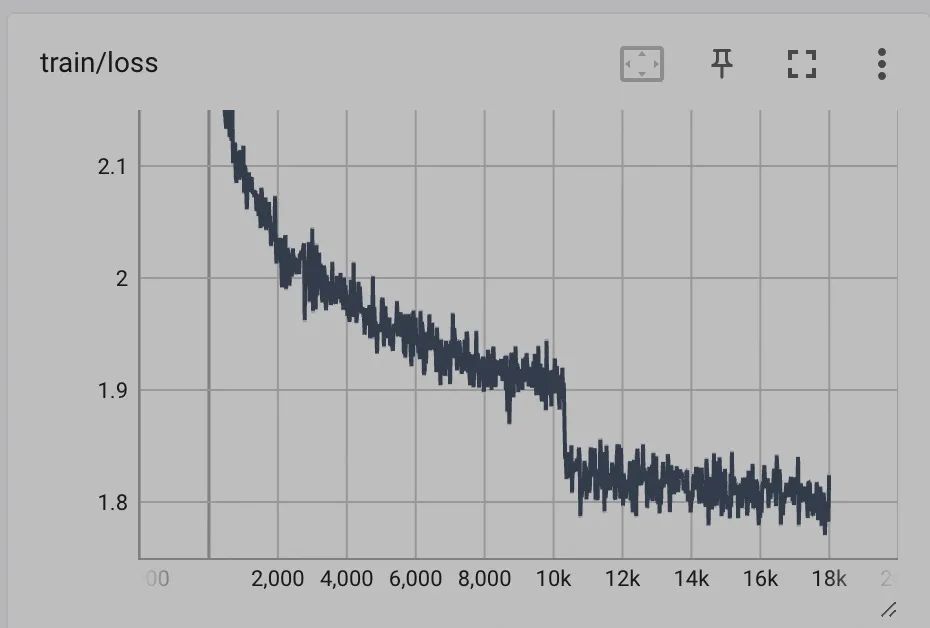
同样的数据在chatglm1上 train loss只能降到2.x左右,同时评估测试集结果,在同样的数据上rouge等指标都有不小的提升。
我们再仔细回顾下,对话session级别训练和拆开训练从原理上有啥区别?
1.session级别训练,效果之一为等价batchsize变大(1个batch可以塞下更多样本),且同一通对话产生的样本在一个bs内。
2. session级别的不同轮次产生的梯度是求平均的,拆开轮次构造训练是求和的,这样除了等价于lr会变大,还会影响不同轮次token权重的分配,另外还会影响norm的计算。
我们用一个简化地例子定量分析下,我们假设两条训练样本分为 1.问:A 答:xx 2.问: A答:xx 问: B答:xx问: C答:xx 则session级别训练影响梯度为 (Ga+(Ga +Gb + Gc)/3)/2。对 A,B,C影响的权重分别为,2/3 1/6 1/6。 拆开训练为(Ga+Ga+ (Ga+Gb)/2+(Ga+Gb+ Gc)/3)/4。对 A,B,C影响的权重分别为,17/24 5/24 1/12。 从上面的权重分布来看,session级别靠后的轮次影响权重要比拆开更大。这也是更合理的,因为大部分场景下,开场白都是趋同和重复的。 一点小福利,以上面试题对应的ChatGLM2-6B微调完整的代码地址为: https://github.com/SpongebBob/Finetune-ChatGLM2-6B
实现了对于 ChatGLM2-6B 模型的全参数微调,主要改进点在多轮对话的交互组织方面,使用了更高效的session级别高效训练,训练效果相比原版ChatGLM-6B有较大提升。
这可能是目前全网效果最好的ChatGLM2-6B全参数微调代码。
-
数据
+关注
关注
8文章
7348浏览量
95020 -
代码
+关注
关注
30文章
4976浏览量
74379 -
大模型
+关注
关注
2文章
3771浏览量
5272
原文标题:大模型微调样本构造的trick
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
推荐一个企业级AI大模型微调项目实战课
AI大模型企业级微调项目实战课
AI大模型微调企业项目实战课

Vishay TSM3微调电阻器技术解析与应用指南
Vishay Sfernice M61系列金属陶瓷微调电位器技术解析
基于Vishay TSM41微调电位器的精密电路设计与应用解析
LLM安全新威胁:为什么几百个毒样本就能破坏整个模型

NVIDIA开源Audio2Face模型及SDK

NVMe高速传输之摆脱XDMA设计27: 桥设备模型设计
模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题





评论