 基于医学知识增强的基础模型预训练方法
基于医学知识增强的基础模型预训练方法

近年来,基于大数据预训练的多模态基础模型 (Foundation Model) 在自然语言理解和视觉感知方面展现出了前所未有的进展,在各领域中受到了广泛关注。在医疗领域中,由于其任务对领域专业知识的高度依赖和其本身细粒度的特征,通用基础模型在医疗领域的应用十分有限。因此,如何将医疗知识注入模型,提高基础模型在具体诊疗任务上的准确度与可靠性,是当前医学人工智能研究领域的热点。 在此背景之下,上海交通大学与上海人工智能实验室联合团队探索了基于医学知识增强的基础模型预训练方法,发布了首个胸部 X-ray 的基础模型,即 KAD(Knowledge-enhanced Auto Diagnosis Model)。该模型通过在大规模医学影像与放射报告数据进行预训练,通过文本编码器对高质量医疗知识图谱进行隐空间嵌入,利用视觉 - 语言模型联合训练实现了知识增强的表征学习。在不需要任何额外标注情况下,KAD 模型即可直接应用于任意胸片相关疾病的诊断,为开发人工智能辅助诊断的基础模型提供了一条切实可行的技术路线。
KAD 具有零样本(zero-shot)诊断能力,无需下游任务微调,展现出与专业医生相当的精度;
KAD 具有开放疾病诊断(open-set diagosis)能力,可应用于胸片相关的任意疾病诊断;
KAD 具有疾病定位能力,为模型预测提供可解释性。
研究论文《Knowledge-enhanced Visual-Language Pre-training on Chest Radiology Images》已被知名国际期刊《自然 - 通讯》(Nature Communications)接收。论文作者为张小嫚、吴超逸、张娅教授,谢伟迪教授(通讯),王延峰教授(通讯)。
论文链接:https://arxiv.org/pdf/2302.14042.pdf
代码模型链接:https://github.com/xiaoman-zhang/KAD
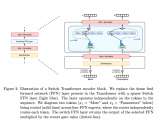
模型介绍 KAD 模型的核心是利用医学先验知识引导基础模型预训练,第一阶段,该研究利用医学知识图谱训练一个文本知识编码器,对医学知识库在隐空间进行建模;第二阶段,该研究提出放射报告中提取医学实体和实体间关系,借助已训练的知识编码器来指导图像与文本对的视觉表征学习,最终实现了知识增强的模型预训练。具体流程如图 1 所示。
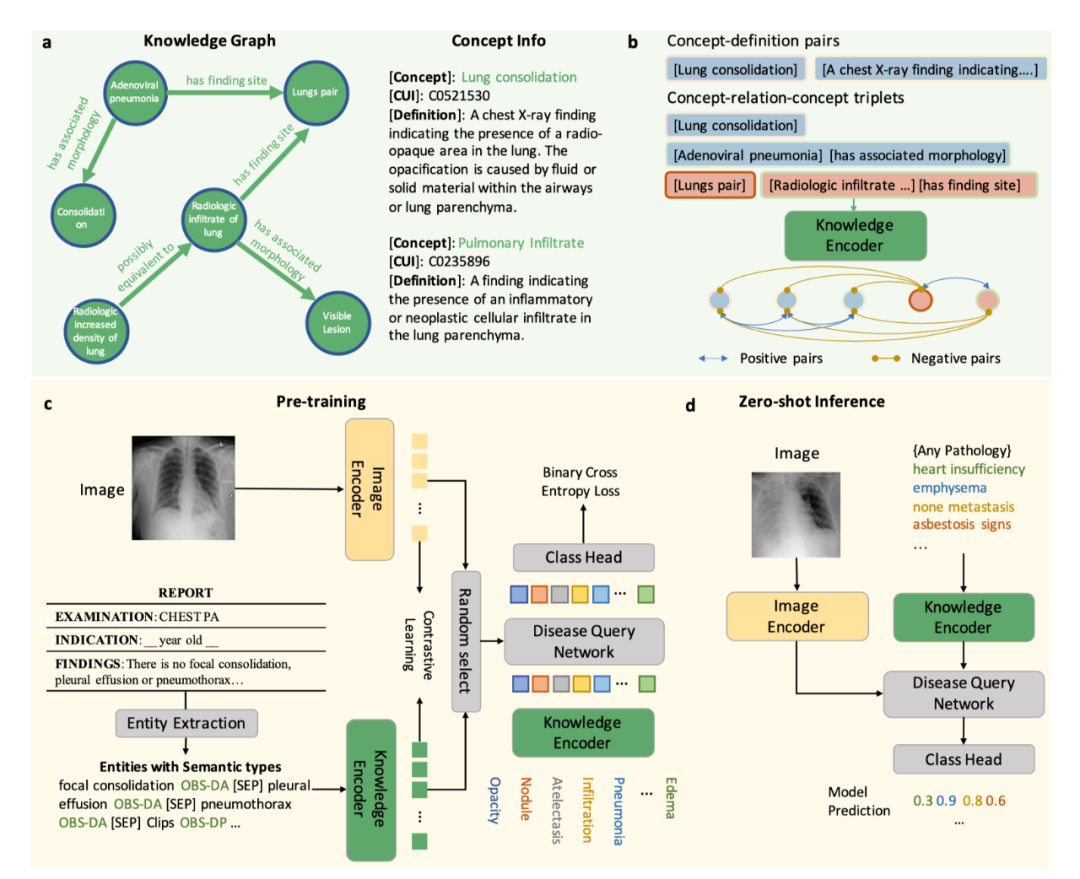
图 1:KAD 的模型架构 知识编码器 知识编码器的核心是在特征空间隐式地建立医学实体之间的关系。具体来说,该研究将统一医学语言系统 (Unified Medical Language System,UMLS) 作为医学知识库,如图 1a 所示;通过对比学习训练文本编码器,将医学知识注入模型,如图 1b 所示。 知识引导的视觉表征学习 知识编码器训练完成后,模型在文本特征空间已经建立了医学实体之间的关系,即可用于引导视觉表征学习。具体来说,如图 1c 所示,基于胸片 - 报告对的数据,首先进行实体提取,得到常见疾病的集合及其标签,该研究尝试了三种方法:基于 UMLS 启发式规则的实体提取、基于报告结构化工具 RadGraph 的实体提取以及基于 ChatGPT 的实体提取;在模型层面,该研究提出了基于 Transformer 架构的疾病查询网络(Disease Query Networks),以疾病名称作为查询 (query) 输入,关注 (attend) 视觉特征以获得模型预测结果;在模型训练过程中,该研究联合优化图像 - 文本对比学习和疾病查询网络预测的多标签分类损失。 经过上述两阶段的训练,在模型使用阶段,如图 1d 所示,给定一张图像以及查询的疾病名称,分别输入图像编码器和知识编码器,经过疾病查询网络,即可得到查询疾病的预测。同时可以通过疾病查询网络得到注意力图对病灶进行定位,增强模型的可解释性。 实验结果 研究团队将仅在 MIMIC-CXR [1] 上使用图像和报告预训练的 KAD 模型,在多个具有不同数据分布的公开数据集上进行了系统性评测,包括 CheXpert [2], PadChest [3], NIH ChestX-ray [4] 和 CheXDet10 [5]。MIMIC-CXR 数据收集于贝斯以色列女执事医疗中心(Beth Israel Deaconess Medical Center,BIDMC)是,CheXpert 数据收集于美国斯坦福医院(Stanford Hospital),PadChest 数据收集于西班牙圣胡医院(San Juan Hospital),NIH ChestX-ray 和 CheXDet10 数据来自于美国国立卫生研究院(National Institutes of Health)临床 PACS 数据库。 (1) KAD 零样本诊断能力与专业放射科医生精度相当 如图 2 所示,该研究将预训练的 KAD 模型在 CheXpert 数据上进行评测,在其中的五类疾病诊断任务与放射科医生进行了比较,图中 Radiologists 表示三名放射科医生的平均结果。KAD 在五类疾病诊断任务上的平均 MCC 超过了 Radiologists,且在其中三类疾病的诊断结果显著优于放射科医生,肺不张 atelectasis (KAD 0.613 (95% CI 0.567, 0.659) vs. Radiologists 0.548);肺水肿 edema (KAD 0.666 (95% CI 0.608, 0.724) vs. Radiologists 0.507);胸腔积液 pleural effusion (KAD 0.702 (95% CI 0.653, 0.751) vs. Radiologists 0.548)。该结果证实了基于知识增强的模型预训练的有效性。
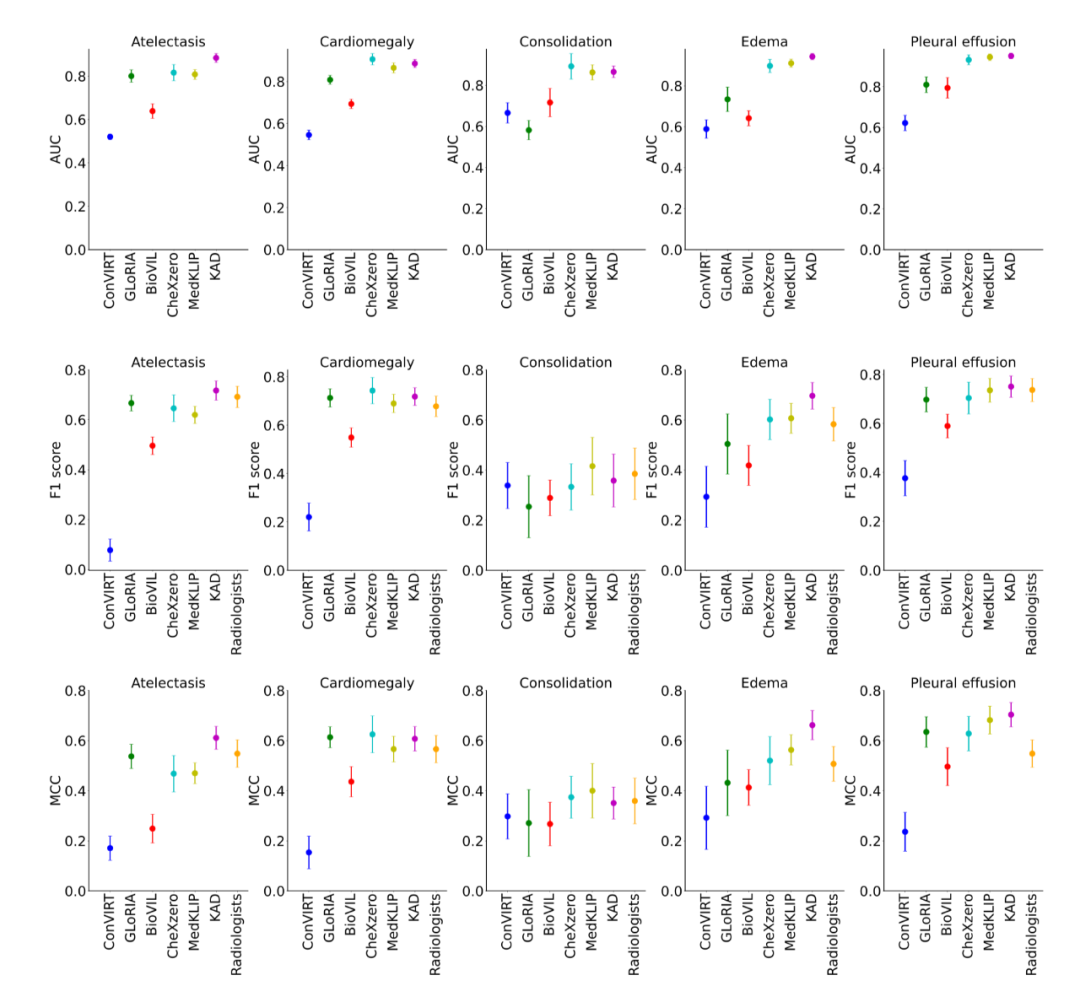
图 2:KAD 在 CheXpert 数据集上与基线模型以及放射科医生的比较 (2) KAD 零样本诊断能力与全监督模型相当,支持开放集疾病诊断 如图 3a 所示,在 PadChest 上的零样本诊断性能大幅度超越此前所有多模态预训练模型(例如 Microsoft 发布的 BioVIL [6],Stanford 发布的 CheXzero [7]),与全监督模型 (CheXNet [8]) 相当。此外,全监督的模型的应用范围受限于封闭的训练类别集合,而 KAD 可以支持任意的疾病输入,在 PadChest 的 177 个未见类别的测试中,有 31 类 AUC 达到 0.900 以上,111 类 AUC 达到 0.700 以上,如图 3b 所示。
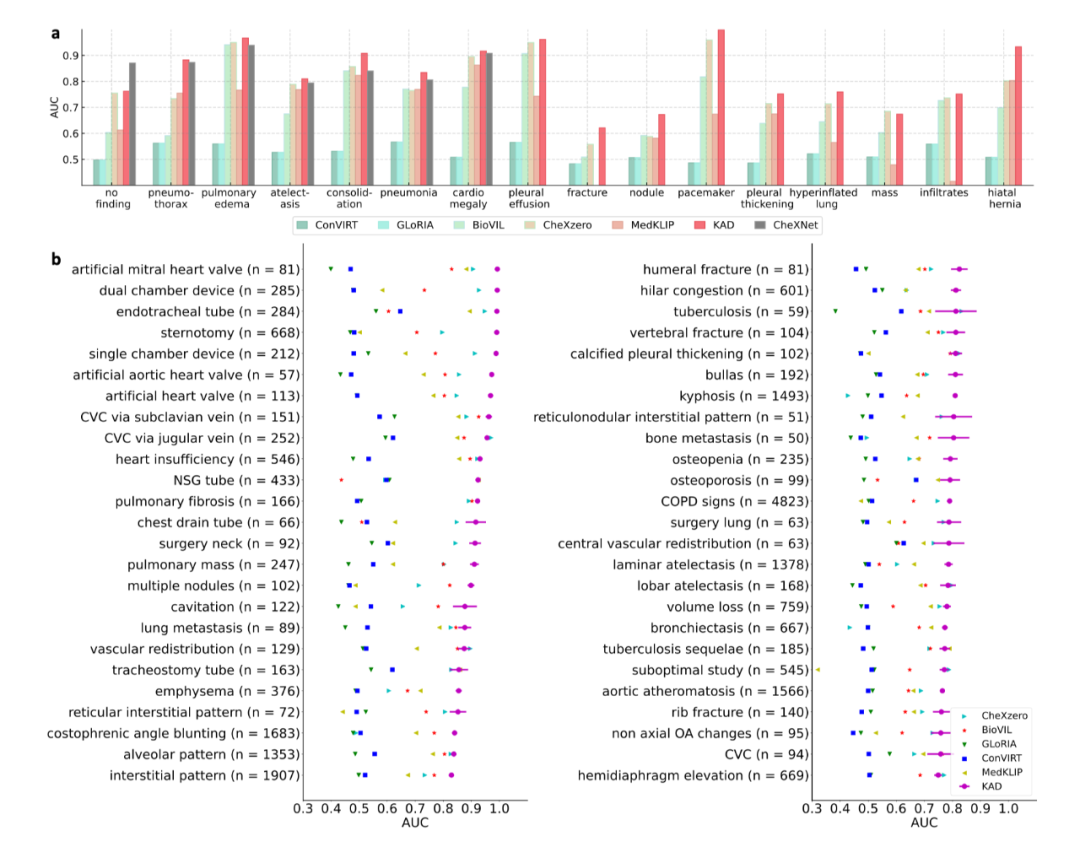
图 3:KAD 在 PadChest 数据集上与基线模型的比较 (3) KAD 具有疾病定位能力,为模型预测提供可解释性 除了自动诊断能力,可解释性在人工智能辅助医疗的作用同样关键,能够有效帮助临床医生理解人工智能算法的判断依据。在 ChestXDet10 数据集上对 KAD 的定位能力进行了定量分析与定性分析。如图 4 所示,KAD 的定位能力显著优于基线模型。图 5 中,红色方框为放射科医生提供的标注,高亮区域为模型的热力图,从中可以看出模型所关注的区域往往能与医生标注区域对应上,随着输入图像的分辨率增加,模型的定位能力也显著增强。 需要强调 这是模型设计的优势,是在无需人工病灶区域标注情况下获得的副产品。
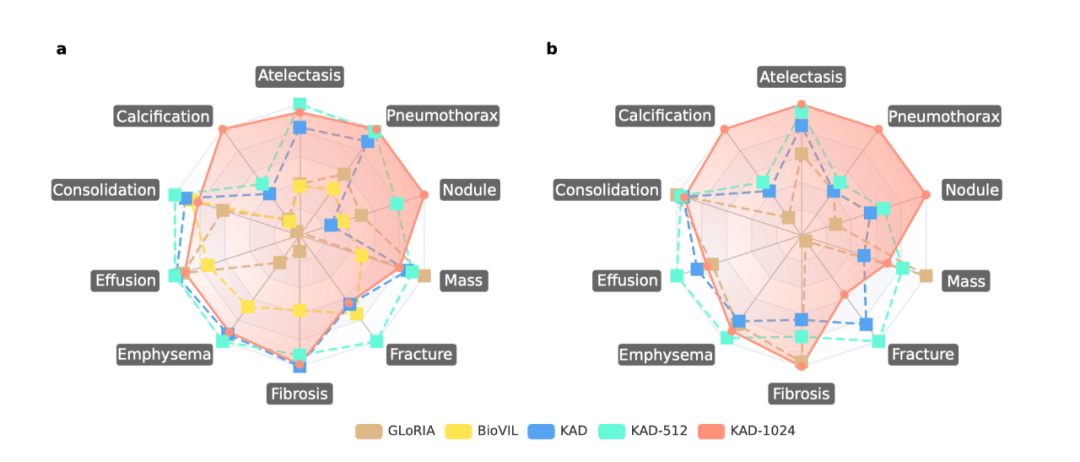
图 4: KAD 在 ChestXDet10 数据集上与基线模型的比较
图 5:KAD 的定位结果可视化 总结 医疗领域的专业性,导致通用基础模型在真实临床诊疗场景下的应用十分受限。KAD 模型的提出为基于知识增强的基础模型预训练提供了切实可行的解决方案。KAD 的训练框架只需要影像 - 报告数据,不依赖于人工注释,在下游胸部 X-ray 诊断任务上,无需任何监督微调,即达到与专业放射科医生相当的精度;支持开放集疾病诊断任务,同时以注意力图形式提供对病灶的位置定位,增强模型的可解释性。值得注意的是,该研究提出的基于知识增强的表征学习方法不局限于胸部 X-ray,期待其能够进一步迁移到医疗中不同的器官、模态上,促进医疗基础模型在临床的应用和落地。
-
编码器
+关注
关注
45文章
4018浏览量
143620 -
模型
+关注
关注
1文章
3854浏览量
52310 -
大数据
+关注
关注
64文章
9107浏览量
144139
原文标题:Nature子刊!上海交大&上海AI Lab提出胸部X-ray疾病诊断基础模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文详解知识增强的语言预训练模型
【大语言模型:原理与工程实践】大语言模型的预训练
微软在ICML 2019上提出了一个全新的通用预训练方法MASS

新的预训练方法——MASS!MASS预训练几大优势!

检索增强型语言表征模型预训练
一种侧重于学习情感特征的预训练方法


利用视觉语言模型对检测器进行预训练
介绍几篇EMNLP'22的语言模型训练方法优化工作
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

基于生成模型的预训练方法

混合专家模型 (MoE)核心组件和训练方法介绍



评论