 通过NVIDIA Magnum IO扩展VASP
通过NVIDIA Magnum IO扩展VASP

尽管硅和其他半导体材料可能是当今推动变革的最重要的材料,但研究中还有其他几种材料同样可以推动下一代变革,包括以下任何一种:
高温超导体
光伏
石墨烯电池
半导体是构建芯片的核心,这些芯片能够对这种新型材料进行广泛而复杂的搜索。
本文研究了一种叫做铪或氧化铪( HfO )的材料的性质计算2.).
就其本身而言,铪是一种电绝缘体。它在半导体制造中大量使用,因为在构建动态随机存取存储器( DRAM )存储时,它可以充当高κ介电膜。它还可以作为金属氧化物半导体场效应晶体管( MOSFET )的栅极绝缘体。 Hafnia 对非易失性电阻 RAM 非常感兴趣,这可能会使启动计算机成为过去。
而理想的纯 HfO2.晶体只能用 12 个原子来计算,这只是一个理论模型。这种晶体实际上含有杂质。
有时,必须添加掺杂剂以产生超出绝缘的所需材料特性。这种掺杂可以在纯度水平上进行,这意味着在 100 个合格原子中,一个原子被不同的元素取代。至少有 12 个原子,其中只有 4 个是 Hf 。很快,很明显,这样的计算很容易需要数百个原子。
这篇文章演示了如何在数百甚至数千 GPU 上高效地并行化此类计算。 Hafnia 是一个例子,但这里所展示的原理当然也可以应用于类似大小的计算。
术语定义
Speedup:相对于参考的无维度性能度量。对于这篇文章,参考是使用 8x A100 80 GB SXM4 GPU 而不启用 NCCL 的单节点性能。加速是通过将参考运行时间除以经过的运行时间来计算的。
Linear scaling:完全平行的应用程序的加速曲线。根据 Amdahl 定律,它适用于 100% 并行化且互连速度无限快的应用程序。在这种情况下, 2 倍的计算资源将导致一半的运行时间, 10 倍的计算时间将导致十分之一的运行时间。当绘制与计算资源数量相比的加速时,性能曲线是一条向上向右倾斜 45 度的直线。并行运行的效果优于此比例关系。也就是说,坡度将大于 45 度,这被称为超线性缩放。
Parallel efficiency:以百分比表示的特定应用程序执行与理想线性缩放的接近程度的无量纲度量。并行效率通过将所获得的加速率除以该计算资源数量的线性缩放加速率来计算。为了避免浪费计算时间,大多数数据中心都有最低并行效率目标( 50-70% )的策略。
VASP 用例和区别
VASP 是电子结构计算和第一原理分子动力学中应用最广泛的应用之一。它提供了最先进的算法和方法来预测材料性能,如前面所讨论的。
GPU 加速度使用 OpenACC 实现。 GPU 通信可以使用 NVIDIA HPC-X 或 NVIDIA Collective Communications Library ( NCCL )中的 Magnum IO MPI 库来执行。
混合 DFT 的用例和区别
本节侧重于使用称为密度泛函理论( DFT )的量子化学方法,通过将精确交换计算与 DFT 内的近似值混合,从而实现更高精度的预测,然后称为混合 DFT 。这种增加的精度有助于根据实验结果确定带隙。
带隙是将材料分类为绝缘体、半导体或导体的特性。对于基于铪的材料,这种额外的精度是至关重要的,但计算复杂度会增加。
将这一点与使用多个原子的需求结合起来,证明了在 GPU 加速的超级计算机上扩展到多个节点的需求。幸运的是, VASP 中有更高精度的方法。有关其他功能的更多信息,请参见 VASP6 。
在更高的层次上, VASP 是一种量子化学应用程序,它与 NAMD 、 GROMACS 、 LAMMPS 和 AMBER 等其他高性能计算( HPC )计算化学应用程序不同,甚至可能更为熟悉。这些代码侧重于分子动力学( MD ),通过简化原子之间的相互作用,例如将它们视为点电荷。这使得模拟这些原子的运动(比如因为温度)在计算上变得廉价。
另一方面, VASP 在量子水平上处理原子之间的相互作用,因为它计算电子如何相互作用并形成化学键。它还可以为量子或从头计算 MD ( AIMD )模拟导出力和移动原子。这确实对本文讨论的科学问题很有意思。
然而,这种模拟将包括多次重复混合 DFT 计算步骤。虽然后续步骤可能会更快地收敛,但每个单独步骤的计算轮廓不会改变。这就是为什么我们在这里只显示了一个离子步骤。
运行单节点或多节点
许多 VASP 计算使用的化学系统足够小,不需要在 HPC 设施上执行。一些用户可能会对在多个节点上扩展 VASP 感到不舒服,并在解决方案的过程中遭受痛苦,甚至可能导致停电或其他故障。其他人可能会限制他们的模拟大小,这样运行时就不会像研究更适合的系统大小那样繁重。
有多种原因可以促使您多节点运行仿真:
在一个节点上运行模拟需要不可接受的时间,即使后者可能更有效。
需要大量内存且无法容纳在单个节点上的大型计算需要分布式并行。虽然某些计算量必须在节点之间复制,但大多数计算量都可以分解。因此,每个节点所需的内存量大致由参与并行任务的节点数量决定。
有关多节点并行性和计算效率的更多信息,请参阅最近的 HPC for the Age of AI and Cloud Computing 电子书。
NVIDIA 使用数据集 Si256 _ VJT _ HSE06 发布了 study of multi-node parallelism 。在这项研究中, NVIDIA 提出了一个问题,“对于这个数据集,以及 V100 系统和 InfiniBand 网络的 HPC 环境,我们可以合理地扩展到什么程度?”
Magnum IO 并行通信工具
VASP 使用 NVIDIA Magnum IO 库和技术来优化多 GPU 和多节点编程,以提供可扩展的性能。这些是 NVIDIA HPC SDK 的一部分。
在本文中,我们将介绍两个通信库:
Message Passing Interface ( MPI ):编程分布式内存可扩展系统的标准。
NVIDIA Collective Communications Library ( NCCL ):使用 MPI 兼容的全聚集、全减少、广播、减少、减少分散和点对点例程,实现高度优化的多 GPU 和多节点集体通信原语,以利用 HPC 服务器节点内和跨 HPC 服务器节点的所有可用 GPU 。
VASP 用户可以在运行时选择应该使用什么通信库。当 MPI 替换为 NCCL 时,性能通常会显著提高,这是 VASP 中的默认设置。
在 MPI 上使用 NCCL 时,观察到的差异有两个强烈的原因。
使用 NCCL ,通信由 GPU 启动并具有流感知。这消除了 GPU 到 – CPU 同步的需要,否则,在每个 CPU 启动 MPI 通信之前都需要进行同步,以确保在 MPI 库接触缓冲区之前所有 GPU 操作都已完成。 NCCL 通信可以像内核一样在 CUDA 流上排队,并且可以促进异步操作。 CPU 可以对进一步的操作进行排队,以保持 GPU 忙碌。
在 MPI 情况下, GPU 至少在完成 MPI 通信后 CPU 入队并启动下一个 GPU 操作所需的时间内是空闲的。最小化 GPU 空闲时间有助于提高 parallel efficiencies 。
使用两个单独的 CUDA 流,您可以轻松地使用一个流进行 GPU 计算,另一个流用于通信。鉴于这些流是独立的,通信可以在后台进行,并且可能完全隐藏在计算后面。实现后者是迈向高并行效率的一大步。此技术可用于任何启用双缓冲方法的程序中。
非阻塞 MPI 通信也可以带来类似的好处。但是,您仍然必须手动处理 GPU 和 CPU 之间的同步,并具有所描述的性能缺点。
由于非阻塞 MPI 通信也必须在 CPU 侧同步,因此增加了另一层复杂性。与使用 NCCL 相比,这从一开始就需要更详细的代码。然而,由于 MPI 通信是由 CPU 启动的,因此通常没有硬件资源自动使通信真正异步。
如果您的应用程序有 CPU 内核可供使用,您可以生成 CPU threads 以确保通信进度,但这再次增加了代码复杂性。否则,通信可能仅在进程进入 MPI _ Wait 时发生,这与使用阻塞调用相比没有任何优势。
另一个需要注意的区别是,对于缩减,数据在 CPU 上进行汇总。在单线程 CPU 内存带宽低于网络带宽的情况下,这可能也是一个意外的瓶颈。
另一方面, NCCL 使用 GPU 求和,并了解拓扑结构。在节点内,它可以使用可用的 NVLink 连接,并使用 Mellanox 以太网、 InfiniBand 或类似结构优化节点间通信。
使用 HfO 的计算建模测试用例2.
铪晶体由两种元素构成:铪( Hf )和氧( O )。在没有掺杂剂或空位的理想系统中,对于每个 Hf 原子,将有两个 O 原子。描述无限延伸晶体结构所需的最小原子数是四个 Hf (黄色)和八个 O (红色)原子。图 2 显示了结构。
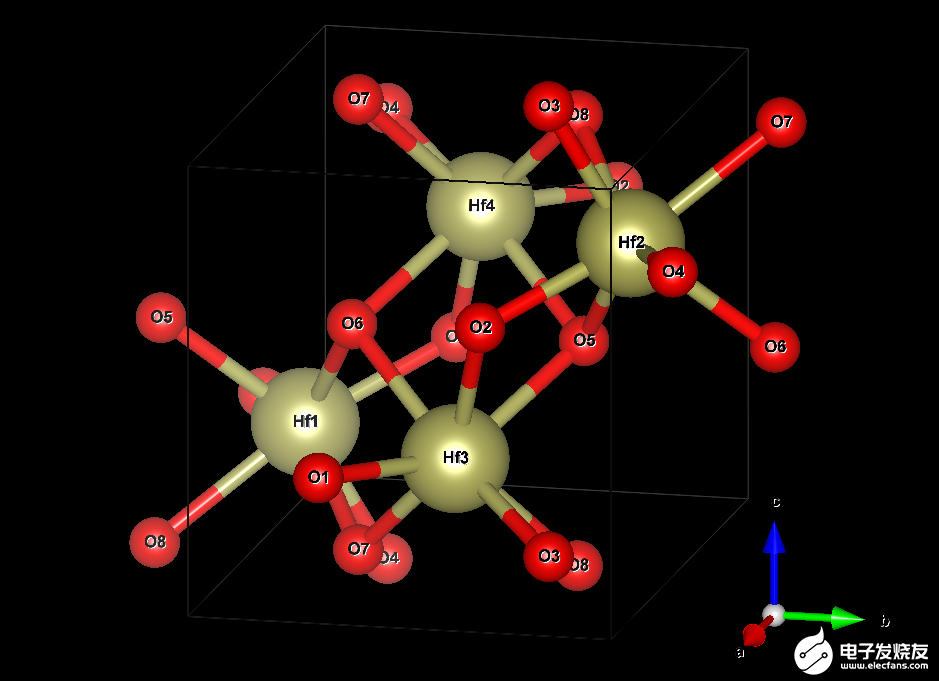
图 2.铪( HfO )晶胞的可视化2.) 晶体
框线框指定所谓的单位单元。它在所有三维空间中重复,产生无限延伸的晶体。这张图片暗示了通过在晶胞外复制原子 O5 、 O6 、 O7 和 O8 来显示它们与 Hf 原子的各自键。该电池的尺寸为 51.4 × 51.9 × 53.2 纳米。这不是一个完美的长方体,因为它的一个角度是 99.7 °而不是 90 °。
最小模型仅明确地处理图 2 中框中的 12 个原子。但是,您也可以将长方体在一个或多个空间方向上延长相应边的整数倍,并将原子的结构复制到新创建的空间中。这样的结果被称为超级细胞,可以帮助治疗在最小模型内无法达到的效果,例如 1% 的氧空位。
当然,用更多的原子处理更大的细胞在计算上要求更高。当您再添加一个单元时,在 a 方向上总共有两个单元,同时保留 b 和 c ,这称为具有 24 个原子的 2x1x1 超级单元。
为了本研究的目的,我们只考虑了成本足以证明至少使用少数超级计算机节点的超级单元:
2x2x2 : 96 个原子, 512 个轨道
3x3x2 : 216 个原子, 1280 个轨道
3x3x3 : 324 个原子, 1792 个轨道
4x4x3 : 576 个原子, 3072 个轨道
4x4x4 : 768 个原子, 3840 个轨道
请记住,计算工作量与原子数或晶胞体积不成正比。本案例研究中使用的粗略估计是,它与任何一个都成立方比例。
当然,这里使用的哈夫尼亚系统只是一个例子。由于基本算法和通信模式不会改变,因此这些经验教训也可以转移到使用类似大小单元和混合 DFT 的其他系统。
如果你想用 HfO 做一些测试2.,您可以 下载输入文件用于本研究。出于版权原因,我们可能不会重新分发 POTCAR 文件。此文件在所有超级单元格中都是相同的。作为 VASP 许可证持有人,您可以通过以下 Linux 命令从提供的文件中轻松创建它:
# cat PAW_PBE_54/Hf_sv/POTCAR PAW_PBE_54/O/POTCAR > POTCAR
对于这些定标实验,我们强制使用恒定数量的晶体轨道,或 bands 。这会略微增加工作量,超出所需的最小值,但不会影响计算精度。
如果没有这样做, VASP 将自动选择一个可以被 GPU 的整数整除的数字,这可能会增加某些节点计数的工作量。我们选择了可被所有 GPU 计数整除的轨道数。此外,为了更好的计算可比性, k 点的数量保持固定为 8 ,即使更大的超级单元在实践中可能不需要这一点。
基于 VASP 的超级电池建模测试方法
以下列出的所有基准测试均使用最新的 VASP 6.3.2 版本,该版本使用 NVIDIA HPC SDK 22.5 和 CUDA 11.7 编译。
作为完整参考,makefile.include已可下载。它们在由 560 个 DGX A100 节点组成的 NVIDIA Selene supercomputer 上运行,每个节点提供八个 NVIDIA A100-SXM4-80GB GPU 、八个 NVVIDIA ConnectX-6 HDR InfiniBand 网络接口卡( NIC )和两个 AMD EPYC 7742 CPU 。
为了确保最佳性能,进程和线程被固定到 CPU 上的 NUMA 节点,这些节点为它们将使用的相应 GPU 和 NIC 提供理想的连接。 AMD EPYC 上的反向 NUMA 节点编号产生以下最佳硬件位置的进程绑定。
| Node local rank | CPU NUMA node | GPU ID | NIC ID |
| 0 | 3 | 0 | mlx5_0 |
| 1 | 2 | 1 | mlx5_1 |
| 2 | 1 | 2 | mlx5_2 |
| 3 | 0 | 3 | mlx5_3 |
| 4 | 7 | 4 | mlx5_6 |
| 5 | 6 | 5 | mlx5_7 |
| 6 | 5 | 6 | mlx5_8 |
| 7 | 4 | 7 | mlx5_9 |
表 1.计算节点 GPU 和 NIC ID 映射
downloadable files 集合中包括一个名为selenerun-ucx.sh的脚本。该脚本通过在工作负载管理器(例如 Slurm )作业脚本中执行以下操作来包装对 VASP 的调用:
# export EXE=/your/path/to/vasp_std # srun ./selenerun-ucx.sh
selenerun-ucx.sh文件必须根据可用的资源配置进行定制,以匹配您的环境。例如,每个节点的 GPU 数量或 NIC 数量可能与 Selene 不同,脚本必须反映这些差异。
为了尽可能缩短基准测试的计算时间,我们通过在 INCAR 文件中设置NELM=1,将所有计算限制为仅一个电子步骤。我们之所以能做到这一点,是因为我们不关心总能量等科学结果,而运行一个电子步骤就足以预测整个运行的性能。这样的运行需要 19 次迭代才能与 3x3x2 超级单元收敛。
当然,每个不同的单元设置可能需要不同的迭代次数,直到收敛。为了对缩放行为进行基准测试,无论如何都需要比较固定的迭代次数,以保持工作负载的可比性。
然而,仅使用一次电子迭代评估跑步的性能会误导您,因为配置文件是不平衡的。与净迭代相比,初始化时间所占的份额要大得多,而像力计算这样的后收敛部分也是如此。
幸运的是,电子迭代都需要同样的努力和时间。您可以使用以下公式预测代表性运行的总运行时间:
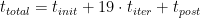
您可以从 VASP 内部 LOOP 计时器中提取一次迭代的时间 ,而迭代后步骤
,而迭代后步骤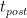 中花费的时间由 LOOP +和 LOOP 计时器之间的差值给出。
中花费的时间由 LOOP +和 LOOP 计时器之间的差值给出。
另一方面,初始化时间是 VASP 中报告为经过时间的总时间与 LOOP +之间的差值。由于一次性分配之类的实例,第一次迭代所需的时间稍长,因此这种预测有一点错误。然而,经检查,误差小于 2% 。
VASP 中混合 DFT 迭代的并行效率结果
我们首先回顾了 96 个原子的最小数据集: 2x2x2 超级电池。如今,这个数据集几乎不需要超级计算机。它的完整运行, 19 次迭代,在一个 DGX A100 上大约 40 分钟内完成。
尽管如此,通过 MPI ,它可以以 93% 的并行效率扩展到两个节点,然后在四个节点上下降到 83% ,甚至在八个节点上降低到 63% 。
另一方面, NCCL 在两个节点上实现了近乎理想的 97% 的缩放,在四个节点上达到了 90% ,甚至在八个节点上也达到了 71% 。然而, NCCL 的最大优势在 16 个节点上得到了明显的证明。与仅使用 MPI 的 6 倍相比,您仍然可以看到> 10 倍的相对加速。
超过 64 个节点的负缩放需要解释。要使用 1024 GPU 运行 128 个节点,还必须使用 1024 个轨道。其他计算只使用了 512 ,因此这里的工作量增加了。不过,我们不想在低节点运行中包含如此多的轨道计数。
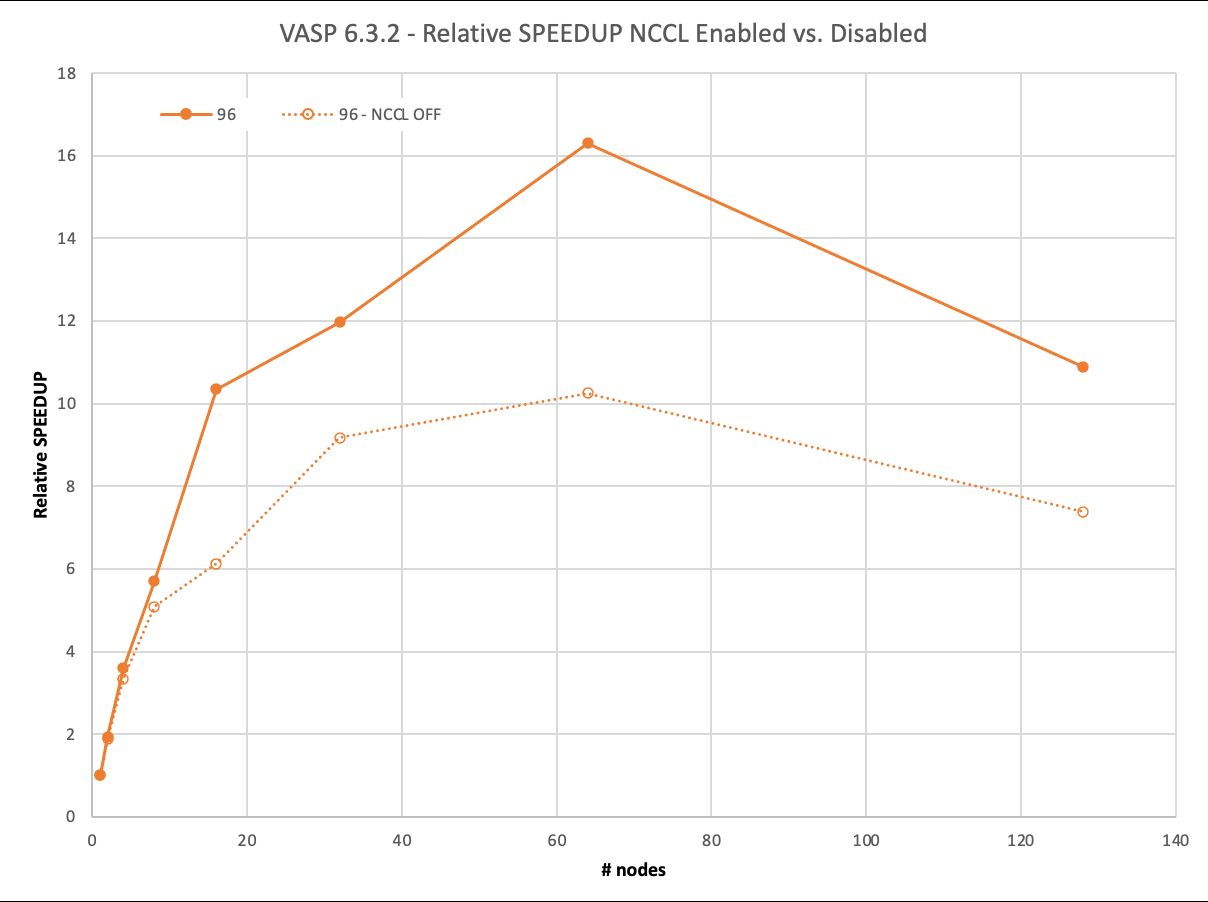
图 4.96 原子情况下的缩放和性能。启用 NCCL 的结果相对于禁用 NCCL 的单节点性能进行了缩放 .
下一个例子已经是一个具有计算挑战性的问题。在单个节点上的 8xA100 上,完成具有 216 个原子的 3x3x2 超级电池的完整计算需要超过 7.5 小时。
随着计算需求的增加,有更多的时间在后台使用 NCCL 异步完成通信。 VASP 在 16 个节点之前保持在 91% 以上,仅在 128 个节点上接近 50% 。
使用 MPI , VASP 无法有效隐藏通信,即使在 8 个节点上也无法达到 90% ,在 64 个节点上已降至 41% 。
对于下一个具有 324 个原子的更大 3x3x3 超级电池,缩放行为的趋势保持不变,这需要一整天的时间才能在单个节点上解决。然而,使用 NCCL 和 MPI 之间的差异显著增加。在使用 NCCL 的 128 个节点上,您可以获得 2 倍的相对加速。
如果是一个更大的 4x4x3 超级电池,包含 576 个原子,那么使用一个 DGX A100 进行完整计算需要等待 5 天以上。
然而,对于如此苛刻的数据集,必须讨论一个新的影响:内存容量和并行化选项。 VASP 提供在 k 点上分配工作负载,同时在这种设置中复制内存。虽然这对于标准 DFT 运行更有效,但也有助于提高混合 DFT 计算的性能,而且无需保留未使用的可用内存。
对于较小的数据集,即使在所有 k 点上进行并行化,也很容易适合 8xA100 GPU ,每个点都有 80GB 的内存。对于 576 原子数据集,在单个节点上,情况不再如此,我们必须减少 k 点的并行性。从两个节点开始,我们可以再次充分利用它。
虽然在图 6 中无法区分,但在 MPI 情况下,两个节点上存在轻微的超线性缩放( 102% 的并行效率)。这是因为在两个或更多节点上提升的一个节点上的并行度必然降低。然而,这也是你在实践中会做的。
对于一个节点和两个节点上有 768 个原子的 4x4x4 超级电池,我们面临着类似的情况,但超线性缩放效应在那里更不明显。
我们将 4x4x3 和 4x4x4 超级单元扩展到 256 个节点。这相当于 2048 A100 GPU 。使用 NCCL ,他们实现了 67% 甚至 75% 的并行效率。这使您能够在不到 1.5 小时的时间内生成结果,而以前在一个节点上几乎需要 12 天的时间! NCCL 的使用使这种大型计算的相对速度比 MPI 快 3 倍。
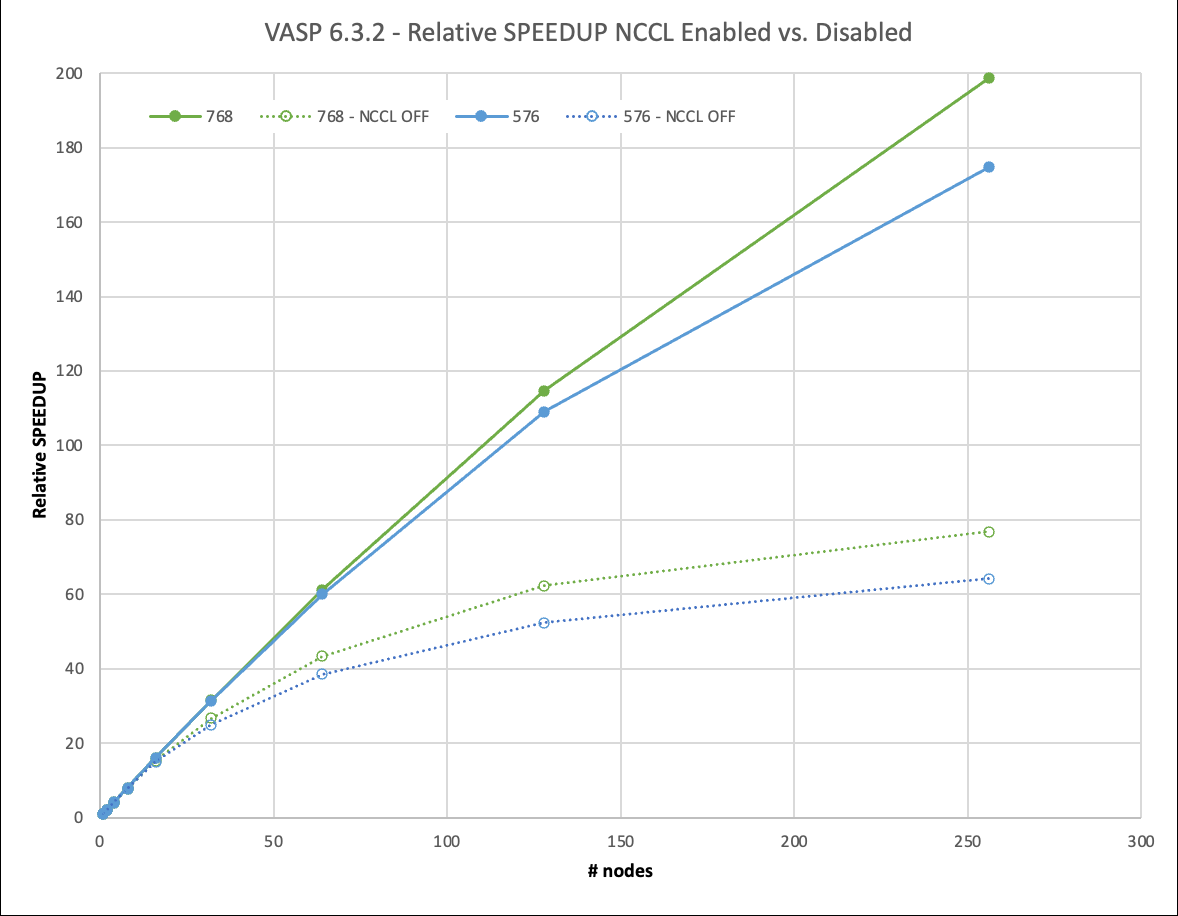
图 6.576 和 768 原子情况下的缩放和性能。启用 NCCL 的结果相对于禁用 NCCL 的单节点性能进行了缩放。
VASP 模拟中使用 NCCL 的建议
VASP 6.3.2 计算 HfO2.当 NVIDIA InfiniBand 网络增强的 NVIDIA GPU 加速 HPC 环境可用时,通过在多个节点上使用 NVIDIA NCCL ,范围从 96 到 768 个原子的超级单元实现了显著的性能。
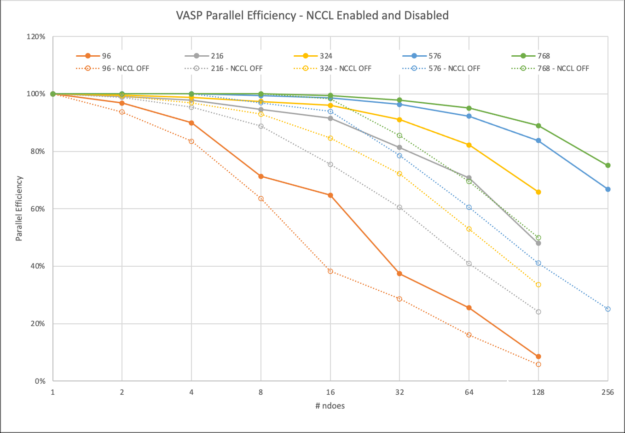
图 7. NCCL 对类似于 HfO 的 VASP 模拟有益的一般指南2.在具有多个 HDR InfiniBand 互连的 A100 GPU 上运行
基于此测试,我们建议有能力访问 HPC 环境的用户考虑以下事项:
使用 GPU 加速度运行除最小计算之外的所有计算。
考虑使用 GPU 和多个节点运行更大的原子系统,以尽量缩短洞察时间。
使用 NCCL 启动所有多节点计算,因为它只会在运行大型模型时提高效率。
初始化 NCCL 时稍微增加的开销值得权衡。
总结
总之,您已经看到 VASP 中混合 DFT 的可伸缩性取决于数据集的大小。鉴于数据集越小,每个个体 GPU 的计算负载越早耗尽,这在某种程度上是意料之中的。
NCCL 也有助于隐藏所需的通信。图 7 显示了具有不同节点数的特定数据集大小的并行效率水平。对于大多数计算密集型数据集, VASP 在 32 个节点上的并行效率达到 80% 以上。对于我们的一些客户要求的最苛刻的数据集,可以在 256 个节点上高效地进行横向扩展。
图 8.作为节点计数函数的并行效率(对数尺度)
VASP 用户体验
根据我们与 VASP 用户的经验,在 GPU 加速基础设施上运行 VASP 是一种积极而富有成效的体验,使您能够考虑更大、更复杂的模型进行研究。
在未加速的场景中,您可能运行的模型比您想要的小,因为您希望运行时增长到无法忍受的水平。使用具有 GPU 的高性能、低延迟 I / O 基础设施,以及具有 Magnum IO 加速技术(如 NCCL )的 InfiniBand ,可以实现高效、多节点并行计算,并为研究人员提供更大的模型。
HPC 系统管理员的好处
HPC 中心,特别是商业中心,通常有禁止用户以低并行效率运行作业的政策。这防止了在短期限内或需要高周转率的用户以牺牲其他用户的工作等待时间为代价使用更多的计算资源。通常情况下,一个简单的经验法则是 50% 的并行效率决定了用户可能请求的最大节点数,从而增加了解决问题的时间。
我们在这里已经表明,通过将 NCCL 作为 NVIDIA Magnum IO 的一部分,加速 HPC 系统的用户可以在效率限制内保持良好状态,并在单独使用 MPI 时比可能的工作扩展得更远。这意味着,在保持 HPC 系统的总体吞吐量处于最高水平的同时,您可以最小化运行时间并最大化模拟次数,以完成新的令人兴奋的科学。
-
NVIDIA
+关注
关注
14文章
5725浏览量
110287 -
AI
+关注
关注
91文章
41972浏览量
303061
发布评论请先 登录
基于PROFIBUS PROFINET远程扩展IO的设计应用
简单介绍单片机IO扩展
dfrobot IO扩展板 传感器扩展板简介

NVIDIA引入云原生超级计算架构
IO扩展芯片PCA9557

Magnum IO存储的优点和实施
使用Magnum IO用于云本机超级计算架构
STM32F43如何通过FPGA扩展IO口
使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率



评论