 XGBoost中无需手动编码的分类特征
XGBoost中无需手动编码的分类特征

XGBoost 是一种基于决策树的集成 机器学习算法,基于梯度增强。然而,直到最近,它还不支持分类数据。分类特征在用于训练或推理之前必须手动编码。
在序数类别的情况下,例如学校成绩,这通常使用标签编码来完成,其中每个类别都分配一个与该类别的位置相对应的整数。等级 A 、 B 和 C 可分别分配整数 1 、 2 和 3 。
对于基数类别,类别之间没有序数关系,例如颜色,这通常使用一个热编码来完成。这是为类别特征包含的每个类别创建新的二进制特征的地方。具有红色、绿色和蓝色类别的单个分类特征将是一个热编码为三个二进制特征,一个代表每种颜色。
>>> import pandas as pd >>> df = pd.DataFrame({"id":[1,2,3,4,5],"color":["red","green","blue","green","blue"]}) >>> print(df) id color 0 1 red 1 2 green 2 3 blue 3 4 green 4 5 blue >>> print(pd.get_dummies(df)) id color_blue color_green color_red 0 1 0 0 1 1 2 0 1 0 2 3 1 0 0 3 4 0 1 0 4 5 1 0 0
这意味着具有大量类别的分类特征可能会导致数十甚至数百个额外的特征。因此,经常会遇到内存池和最大 DataFrame 大小限制。
对于 XGBoost 这样的树学习者来说,这也是一种特别糟糕的方法。决策树通过找到所有特征的分裂点及其可能的值来训练,这将导致纯度的最大提高。
由于具有许多类别的一个热编码分类特征往往是稀疏的,因此分割算法 经常忽略 one-hot 特性有利于较少稀疏的特征,这些特征可以贡献更大的纯度增益。
现在, XGBoost 1.7 包含了一个实验 特征,它使您可以直接在分类数据上训练和运行模型,而无需手动编码。这包括让 XGBoost 自动标记编码或对数据进行一次热编码的选项,以及 optimal partitioning 算法,用于有效地对分类数据执行拆分,同时避免一次热解码的缺陷。 1.7 版还支持缺失值和最大类别阈值,以避免过度拟合。
这篇文章简要介绍了如何在包含多个分类特征的示例数据集上实际使用新特征。
使用 XGBoost 的分类支持预测恒星类型
要使用新功能,必须首先加载一些数据。在本例中,我使用了 Kaggle star type prediction dataset 。
>>> import pandas as pd >>> import xgboost as xgb >>> from sklearn.model_selection import train_test_split >>> data = pd.read_csv("6 class csv.csv") >>> print(data.head())
然后,将目标列(星形)提取到其自己的系列中,并将数据集拆分为训练和测试数据集。
>>> X = data.drop("Star type", axis=1)
>>> y = data["Star type"]
>>> X_train, X_test, y_train, y_test = train_test_split(X, y)
接下来,将分类特征指定为category数据类型。
>>> Y_train = y_train.astype("category")
>>> X_train["Star color"] = X_train["Star color"].astype("category")
>>> X_train["Spectral Class"] = X_train["Spectral Class"].astype("category")
现在,要使用新功能,必须在创建XGBClassifier对象时将enable_categorical参数设置为True。之后,继续训练 XGBoost 模型时的正常操作。这适用于 CPU 和 GPU tree_methods。
>>> clf = xgb.XGBClassifier(
tree_method="gpu_hist", enable_categorical=True, max_cat_to_onehot=1
)
>>> clf.fit(X_train, y_train)
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=True,
eval_metric=None, gamma=0, gpu_id=0, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.300000012, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=6, max_leaves=0,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1,
objective='multi:softprob', predictor='auto', random_state=0,
reg_alpha=0, ...)
最后,您可以使用您的模型生成预测,而无需对分类特征进行一次热编码或编码。
>>> X_test["Star color"] = X_test["Star color"]
.astype("category")
.cat.set_categories(X_train["Star color"].cat.categories)
>>> X_test["Spectral Class"] = X_test["Spectral Class"]
.astype("category")
.cat.set_categories(X_train["Spectral Class"].cat.categories)
>>> print(clf.predict(X_test))
[1 0 3 3 2 5 1 1 2 1 4 3 4 0 0 4 1 5 2 4 4 1 4 5 5 3 1 4 5 2 0 2 5 5 4 2 5
0 3 3 0 2 3 3 1 0 4 2 0 4 5 2 0 0 3 2 3 4 4 4]
总结
我们演示了如何使用 XGBoost 对分类特征的实验支持,以改善 XGBoost 在分类数据上的训练和推理体验。。
-
NVIDIA
+关注
关注
14文章
5682浏览量
110102 -
AI
+关注
关注
91文章
40982浏览量
302534 -
机器学习
+关注
关注
67文章
8561浏览量
137208
发布评论请先 登录
基于xgboost的风力发电机叶片结冰分类预测 精选资料下载
基于快速低秩编码与局部约束的图像分类算法
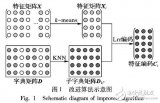
基于栈式自编码的恶意代码分类算法
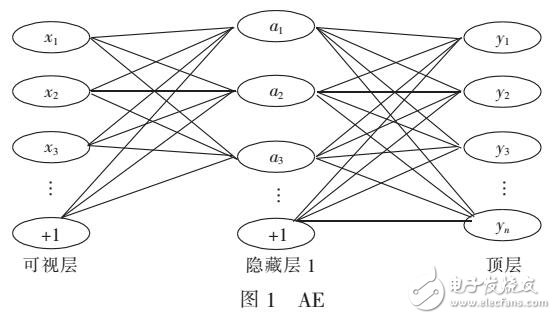
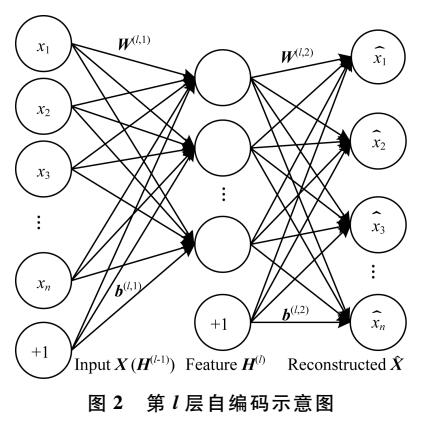
一种新的目标分类特征深度学习模型
面试中出现有关Xgboost总结
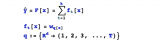
基于XGBoost的树突状细胞算法综述
XGBoost 2.0介绍



评论