 理解指向,说出坐标,Shikra开启多模态大模型参考对话新维度
理解指向,说出坐标,Shikra开启多模态大模型参考对话新维度

在人类的日常交流中,经常会关注场景中不同的区域或物体,人们可以通过说话并指向这些区域来进行高效的信息交换。这种交互模式被称为参考对话(Referential Dialogue)。
如果 MLLM 擅长这项技能,它将带来许多令人兴奋的应用。例如,将其应用到 Apple Vision Pro 等混合现实 (XR) 眼镜中,用户可以使用视线注视指示任何内容与 AI 对话。同时 AI 也可以通过高亮等形式来指向某些区域,实现与用户的高效交流。
本文提出的Shikra 模型,就赋予了 MLLM 这样的参考对话能力,既可以理解位置输入,也可以产生位置输出。

-
论文地址:http://arxiv.org/abs/2306.15195
-
代码地址:https://github.com/shikras/shikra
核心亮点
Shikra 能够理解用户输入的 point/bounding box,并支持 point/bounding box 的输出,可以和人类无缝地进行参考对话。
Shikra 设计简单直接,采用非拼接式设计,不需要额外的位置编码器、前 / 后目标检测器或外部插件模块,甚至不需要额外的词汇表。

如上图所示,Shikra 能够精确理解用户输入的定位区域,并能在输出中引用与输入时不同的区域进行交流,像人类一样通过对话和定位进行高效交流。

如上图所示,Shikra 不仅具备 LLM 所有的基本常识,还能够基于位置信息做出推理。

如上图所示,Shikra 可以对图片中正在发生的事情产生详细的描述,并为参考的物体生成准确的定位。

尽管Shikra没有在 OCR 数据集上专门训练,但也具有基本的 OCR 能力。
更多例子

其他传统任务

方法
模型架构采用 CLIP ViT-L/14 作为视觉主干,Vicuna-7/13B 作为基语言模型,使用一层线性映射连接 CLIP 和 Vicuna 的特征空间。
Shikra 直接使用自然语言中的数字来表示物体位置,使用 [xmin, ymin, xmax, ymax] 表示边界框,使用 [xcenter, ycenter] 表示区域中心点,区域的 xy 坐标根据图像大小进行归一化。每个数字默认保留 3 位小数。这些坐标可以出现在模型的输入和输出序列中的任何位置。记录坐标的方括号也自然地出现在句子中。
实验结果
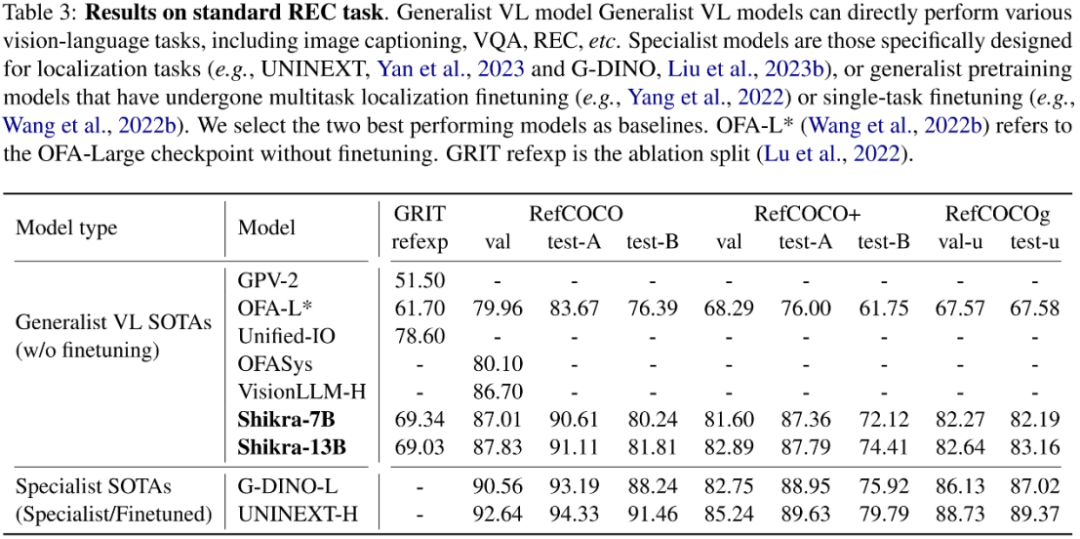
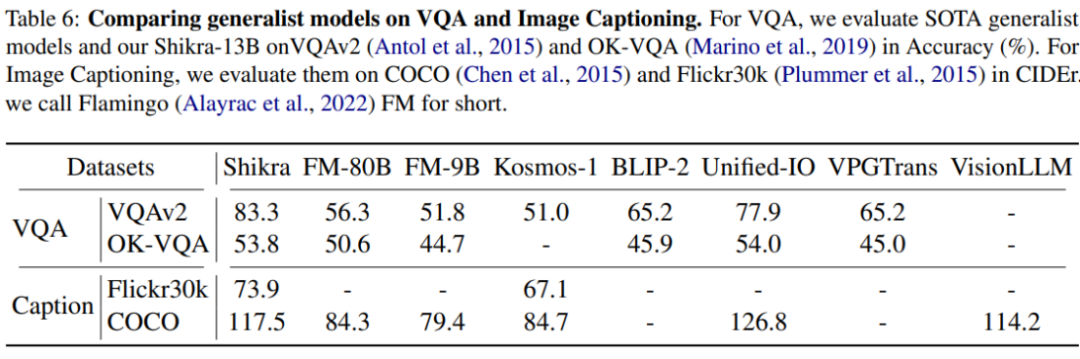
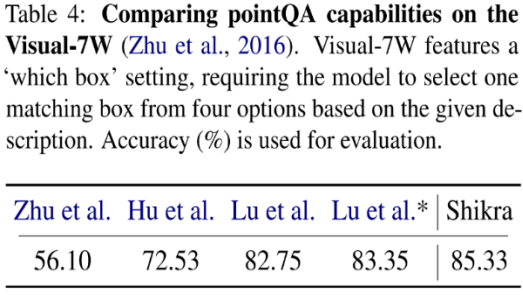
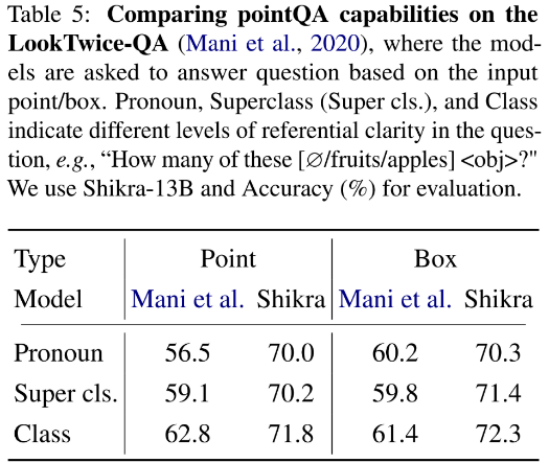
Shikra 在传统 REC、VQA、Caption 任务上都能取得优良表现。同时在 PointQA-Twice、Point-V7W 等需要理解位置输入的 VQA 任务上取得了 SOTA 结果。
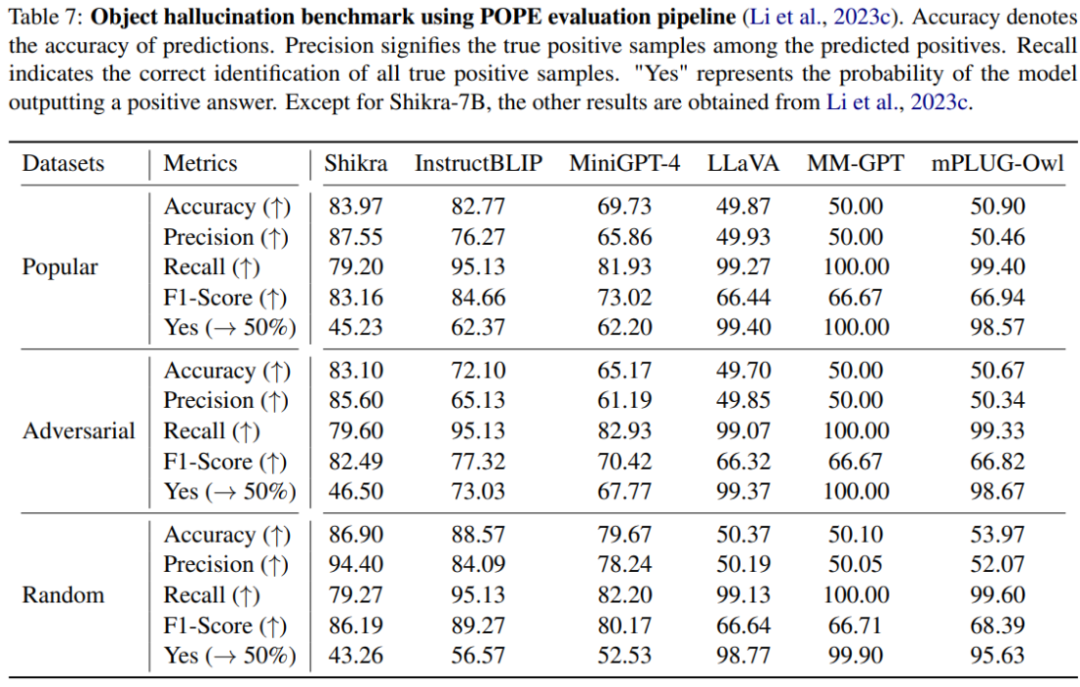
本文使用 POPE benchmark 评估了 Shikra 产生幻觉的程度。Shikra 得到了和 InstrcutBLIP 相当的结果,并远超近期其他 MLLM。
思想链(CoT),旨在通过在最终答案前添加推理过程以帮助 LLM 回答复杂的 QA 问题。这一技术已被广泛应用到自然语言处理的各种任务中。然而如何在多模态场景下应用 CoT 则尚待研究。尤其因为目前的 MLLM 还存在严重的幻视问题,CoT 经常会产生幻觉,影响最终答案的正确性。通过在合成数据集 CLEVR 上的实验,研究发现,使用带有位置信息的 CoT 时,可以有效减少模型幻觉提高模型性能。

结论
本文介绍了一种名为 Shikra 的简单且统一的模型,以自然语言的方式理解并输出空间坐标,为 MLLM 增加了类似于人类的参考对话能力,且无需引入额外的词汇表、位置编码器或外部插件。
THE END
原文标题:理解指向,说出坐标,Shikra开启多模态大模型参考对话新维度
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
-
物联网
+关注
关注
2950文章
48127浏览量
418510
原文标题:理解指向,说出坐标,Shikra开启多模态大模型参考对话新维度
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
海光DCU完成Qwen3.5多模态MoE模型全量适配
商汤科技正式开源多模态自主推理模型SenseNova-MARS

商汤科技日日新V6.5荣获2025年多模态大模型全国第一


商汤科技正式发布并开源全新多模态模型架构NEO

格灵深瞳多模态大模型Glint-ME让图文互搜更精准

亚马逊云科技上线Amazon Nova多模态嵌入模型

商汤日日新V6.5多模态大模型登顶全球权威榜单
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
浅析多模态标注对大模型应用落地的重要性与标注实例
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测

研华科技携手创新奇智推出多模态大模型AI一体机




评论