 异构计算面临的挑战和未来发展趋势
异构计算面临的挑战和未来发展趋势

导读
超异构和异构的本质区别在哪里?
这篇文章通过对异构计算的历史、发展、挑战、以及优化和演进等方面的分析,来进一步阐述从异构走向异构融合(即超异构)的必然发展趋势。
1、异构计算的历史发展
1.1 并行计算的兴起
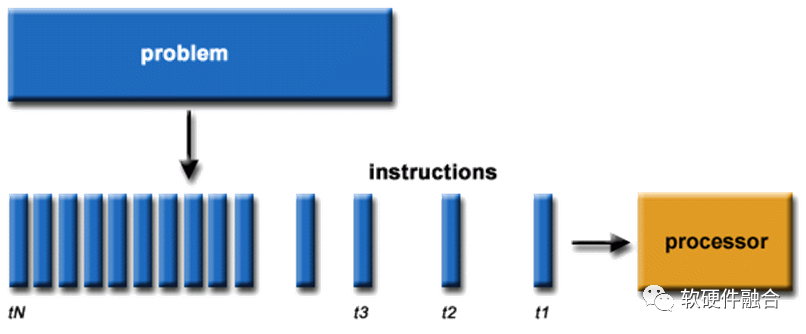
1971年Intel发明全球第一款商用的CPU处理器,在之后的上世纪70-90年代,CPU(核)经历了翻天覆地的变化:
- 宏观架构有精简RISC和复杂CISC路线之争;
- 各种各样的微架构创新技术,如处理器流水线、乘法/除法器等复杂执行单元、指令多发射、乱序执行、缓存等等;
- 处理器数据位宽从4位到8位到16位到32位,再到目前仍是主流的64位;
- 等等。
经过这些创新之后,逐步的触达了(架构/微架构层次的)CPU(核)性能的上限。不考虑工艺升级的影响,单个处理器核的性能几乎挖掘到极致,持续增加性能的希望,不得不落在多个处理器核并行的路径上来。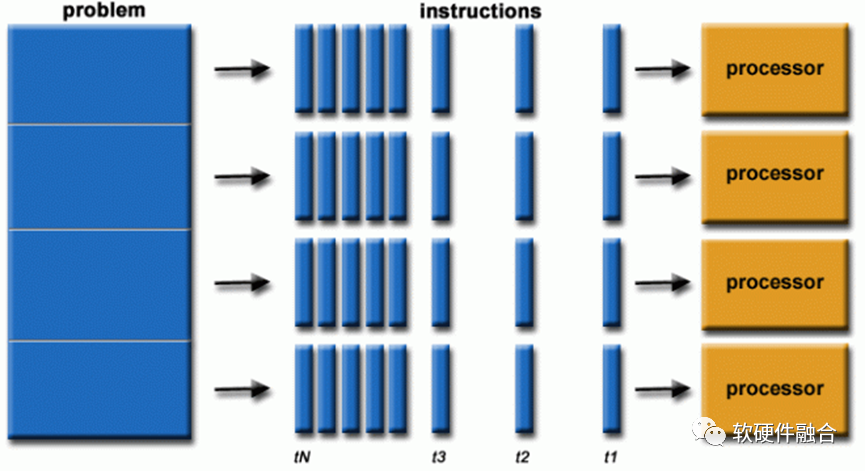 IBM公司于2001年推出IBM Power4双核处理器,是世界上第一款多核处理器。随后,AMD和Intel分别推出了各自的双核处理器。随着时间推移,更多的CPU核心被集成进了CPU芯片。目前,最新的AMD EPYC 9654 CPU具有96个核心192个硬件线程的超高并行能力。
IBM公司于2001年推出IBM Power4双核处理器,是世界上第一款多核处理器。随后,AMD和Intel分别推出了各自的双核处理器。随着时间推移,更多的CPU核心被集成进了CPU芯片。目前,最新的AMD EPYC 9654 CPU具有96个核心192个硬件线程的超高并行能力。
1.2 通用GPU本质上是众核并行
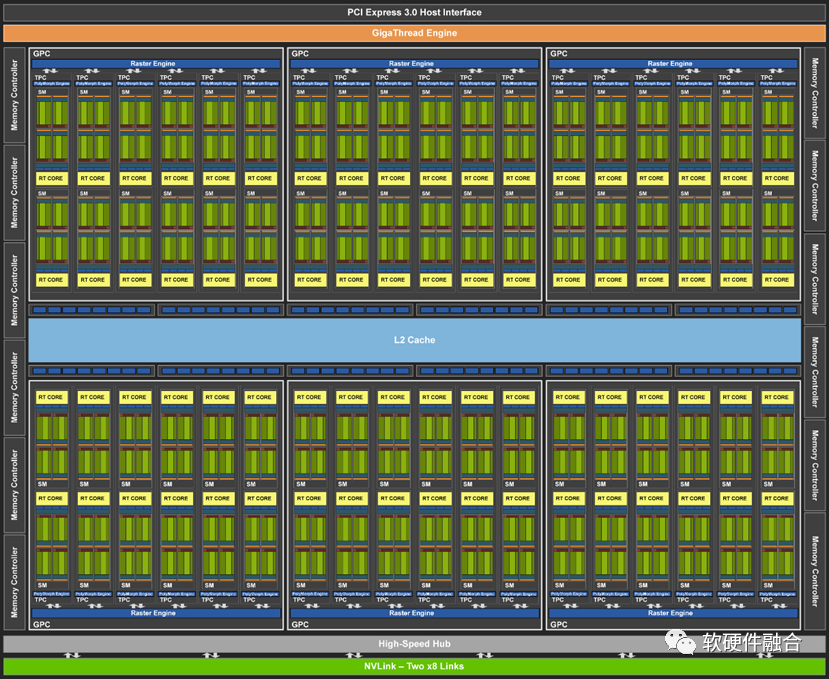
GPGPU本质上是数以百/千计的高效能的小CPU组成的众核并行计算处理器。如NVIDIA的图灵架构GPGPU,总共72个SM,每个SM由64个CUDA核、8个Tensor核、1个RT核、4个纹理单元,总计有4608个CUDA核、576个Tensor核、72个RT核、288个纹理单元。
GPU众核(数千个)和CPU多核(数十个)的区别在于:CPU核是高性能的大核,足够高性能的同时也足够复杂,面积功耗成本等方面的代价也高,单位计算的成本较高;而GPU核是高效能的小核,每个核的性能较低,但数以千计的小核并行起来的性能足够高,单位计算的功耗面积等成本较低,但单核的性能不足以满足通用计算单个线程性能的要求。
1.3 异构计算的架构模式:CPU+xPU
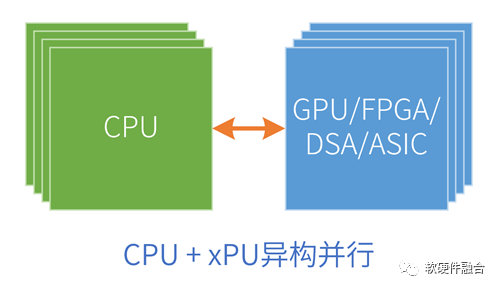 CPU是图灵完备的(在这里,图灵完备可以通俗的理解成可以独立运行的处理器平台),因此CPU可以单独的作为软件系统的运行平台。而GPU等其他加速处理器则不同,这些平台是非图灵完备的,或者说无法独立运行,只能在CPU的协助下才可以运行。也因此,我们通常见到的异构计算系统都是“CPU+xPU加速处理器”的架构(xPU特指其他各类非CPU处理器)。
CPU是图灵完备的(在这里,图灵完备可以通俗的理解成可以独立运行的处理器平台),因此CPU可以单独的作为软件系统的运行平台。而GPU等其他加速处理器则不同,这些平台是非图灵完备的,或者说无法独立运行,只能在CPU的协助下才可以运行。也因此,我们通常见到的异构计算系统都是“CPU+xPU加速处理器”的架构(xPU特指其他各类非CPU处理器)。
2、异构成为计算架构的主流
2.1 CPU性能瓶颈,但算力需求永无止境
上世纪80-90年代,每18个月,CPU性能提升一倍,这就是著名的摩尔定律。如今,CPU性能提升每年只有3%,要想性能翻倍,需要20年。CPU的性能提升已经达到瓶颈,难堪大任。
虽然CPU的性能提升几乎停滞,但对算力(性能是微观,算力是宏观)的需求,是永无止境的:
案例一:2012-2018年共6年时间里,人们对于AI算力的需求增长了超过30万倍。
案例二:目前L2级别的自动驾驶通常需要数百TOPS的算力,NVIDIA将于2024年底正式发布的Thor可以实现2000 TOPS的算力,但要想真正实现L4/L5级别的自动驾驶算力,则需要20000+ TOPS。
案例三:Intel SVP拉加·库德里表示,要想实现元宇宙级别的用户体验,需要当前的算力要再提升1000倍。随着元宇宙概念的兴起,对算力需求猛增,算力成为制约元宇宙发展的最大问题。
算力需求越来越大,异构成为了(架构层次)性能提升的主要手段。
2.2 强大的开发框架和生态,是异构计算成功的关键
实际上,硬件实现同构或异构并行的门槛相对不高。但受限于人类的思维习惯,驾驭并行硬件平台,也即并行编程,的难度较大;特别是异构并行,编程难度更大。异构并行编程不仅仅涉及众多并行线程的编程,还涉及到加速处理器和Host CPU的交互编程,还包括这两者的交叉同步。
在并行系统里,通过(手动)编程实现单个软件内部多个不同线程的并行,这种方式编程难度大,系统复杂,而且对并行资源的利用效率不高,这不是主流的方式。
在CPU同构并行的硬件平台上,更多的是通过操作系统的多线程调度能力以及虚拟化的多系统隔离的方式,实现宏观意义上的多个系统或多个软件的并行,而不是通过(手动)编程实现单个软件内部的线程级并行。
GPU众核编程则要更加复杂。为了降低编程门槛,GPU上运行的程序并不是完全“自由”的,而且强加了一些约束或底层细节屏蔽,以此来降低编程难度。比如SIMD方式的单线程多处理器并行执行(多个处理器执行的是相同的程序),再比如通过底层的软件或硬件机制实现统一内存,还比如通过框架和开发库等方式进一步降低开发难度,等等。通过这些方式,可以显著的提高异构并行的性能利用效率、提高编程效率、降低编程难度等。
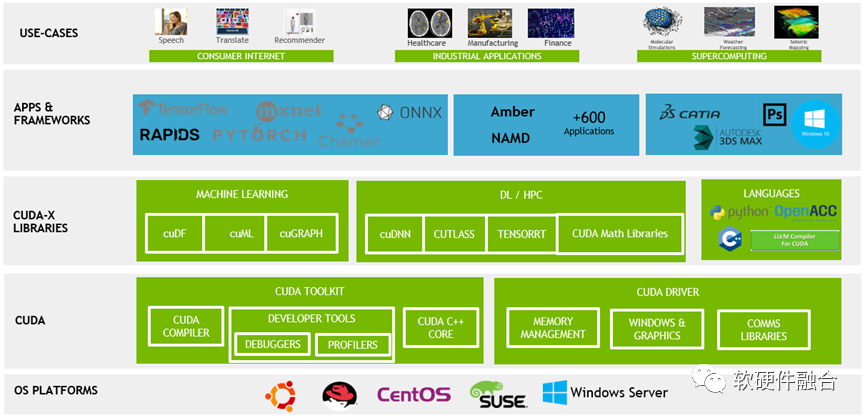
2006 年 11 月,NVIDIA推出了CUDA框架,这是一种通用并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎以比CPU更有效的方式解决许多复杂的计算问题。经过十多年的发展,NVIDIA建立了基于其GPGPU的非常强大的CUDA异构编程框架和生态。
随着AI大潮的到来,对算力的需求不断快速增长,传统CPU的算力平台越来越难以满足业务算力的需要。这进一步推动NVIDIA GPGPU和CUDA成为了炙手可热的行业“明星”,使得NVIDIA成为全球市值最高的芯片公司。
对大算力芯片来说,生态是成功的第一关键。
2.3 DSA,体系结构的黄金年代
DSA是在定制ASIC的基础上回调,使其具有一定的软件可编程灵活性。DSA出现的原因主要有:
- CPU单核性能瓶颈,摩尔定律逐渐失效;
- 随着集成电路工艺逐渐逼近理论极限,晶体管的电流和电压已经不能继续下降了,丹纳德缩放定律也逐渐失效;
- 阿姆达尔定律表明:并行性的理论性能提升受任务顺序部分的限制。也因此,通过多核并行来提升综合性能的收益也在逐渐递减。
图灵奖获得者John Hennessy和David Patterson在其2017年说,未来十年是体系机构的黄金年代,在CPU性能达到瓶颈的情况下,要大幅提高性能并且优化成本和能耗的唯一途径是DSA,即针对特定领域的特殊需求定制处理器。
2016年发布的谷歌TPU是第一款DSA架构的处理器,从此之后,各种类型的符合DSA概念的加速处理器如雨后春笋般涌现。
3、异构计算存在的主要问题
3.1 DSA的问题
DSA无法包治百病。
所谓“成也萧何败也萧何”,DSA的优势是领域定制,劣势也是领域定制:
- 优势在于:领域定制具有一定的灵活可编程性,能够覆盖比ASIC大得多的场景范围;并且性能跟ASIC相当,性能效率甚至高于ASIC。
- 劣势在于:架构完全碎片化。不同领域是完全不同的硬件平台和软件生态;即使同一领域,不同厂家的架构依然不同;甚至,同一厂家不同代产品的架构都会不同。
DSA还有一个劣势的地方在于:定制的架构,其灵活性不太适合一些应用类型的性能加速,比如AI加速。受限于AI算法多种多样并且许多AI算法仍在快速迭代,DSA性质的AI加速器都跟不上软件的差异性和迭代速度,从而导致AI-DSA芯片的落地困难。
3.2 异构xPU无法兼顾性能和灵活性
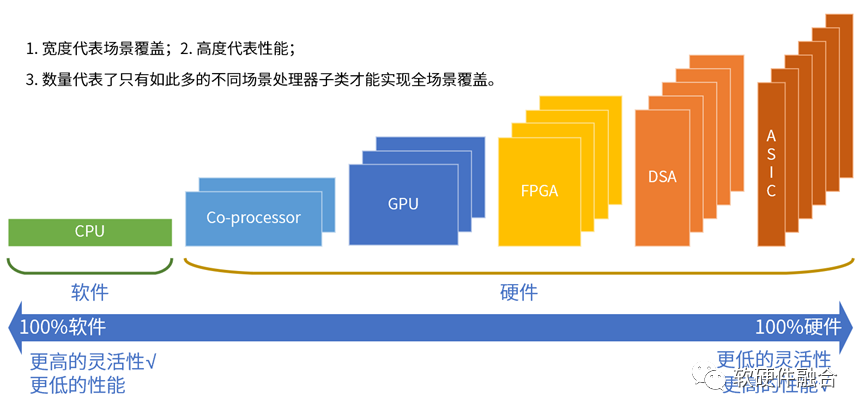
我们依据指令复杂度从简单到复杂,可以把典型的处理器引擎划分为CPU、协处理器、GPU、FPGA、DSA和ASIC。CPU可以理解成纯软件,协处理器是附属于CPU,在硬件上跟CPU是一体的。因此,可以作为加速处理器xPU的处理器引擎类型只有后面四个。异构计算的核心矛盾在于:系统越复杂,越需要选择灵活的处理器;性能挑战越大,越需要选择定制的处理器。本质原因在于,单一处理器无法兼顾性能和灵活性:
GPGPU,通用众核并行计算平台,GPU灵活性较好,适用于性能敏感的业务应用加速;但性能效率不够极致。
DSA,接近于ASIC性能,但灵活性差一些。比较适合基础设施层的任务加速,难以适应复杂业务计算场景对灵活性的要求。
FPGA不仅功耗和成本高,而且需要经过硬件编程之后才能确定其真正的架构类型。FPGA的灵活性来源于硬件可编程性,也意味着架构是变化的,不利于软件生态的形成。FPGA实际落地案例不多。
- ASIC,受限于其完全固化的业务逻辑,在灵活多变的复杂计算场景几乎难以应用。
3.3 异构计算的孤岛问题
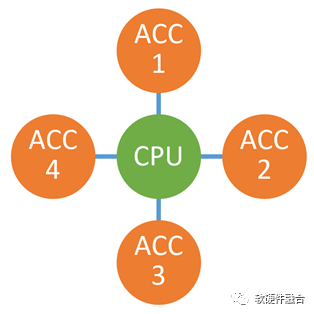 随着异构计算成为计算的主流架构,也随着异构的处理器越来越多,最终的系统一定不是Host+某个唯一的xPU加速处理器,而是Host+很多个xPU加速处理器的模式。这样,多个异构协同计算的问题就出现了:
随着异构计算成为计算的主流架构,也随着异构的处理器越来越多,最终的系统一定不是Host+某个唯一的xPU加速处理器,而是Host+很多个xPU加速处理器的模式。这样,多个异构协同计算的问题就出现了:
最核心的是,每个加速处理器都只考虑特定的场景或领域;反过来说,就是较少考虑与其他加速处理器的协同。如同瞎子摸象,每个人看到扇子、绳子、柱子、墙壁的时候,最终,能组织成“大象”吗?
加速处理器之间的交互困难。所有加速器的交互需要经过CPU,而CPU已经性能瓶颈,还要给它压更重的“担子”,那就是“颈上加颈”。
服务器等计算机设备的物理空间和扩展总线/卡槽有限,很难支持太多的物理加速卡,异构加速处理器需要整合。
4、异构计算的架构优化
4.1 异构计算的优化权衡
维度一:处理器引擎的类型。灵活性和性能是系统架构的核心矛盾,更多的灵活性,也意味着更加易于编程,系统更好驾驭,与此同时却意味着更低的性能。许多设计权衡其实都在根据业务场景的特点,在灵活性和性能的天平上左右摇摆:到底是应该偏向灵活性的CPU多一些,还是偏向极致性能的ASIC多一些。维度二,处理器引擎类型的数量。系统的驾驭难度,也跟处理器类型的数量有关:
同构并行只有一种类型的处理器引擎(CPU),编程要相对简单。
异构的CPU+xPU加速处理器是两种类型的处理器引擎,编程要更复杂一些。
既然异构有两个类型,未来是否还可以有三个、四个,甚至更多的处理器类型组成更复杂的多异构系统?
更多类型的处理器引擎,又是一个艰难的抉择:一方面意味着性能的进一步提升,另一方面意味着更高的编程难度。
4.2 各类型处理器都在拓展自己的能力边界
越来越“卷”,随着处理器引擎越来越多,每个处理器引擎其实都突破了我们通常意义上的各自边界,侵入到其他处理器引擎的领地。例如:
- CPU集成协处理器。CPU不断扩展硬件加速指令集,这些加速指令集的执行单元就是协处理器。例如Intel Xeon支持AVX和AMX。
- GPU集成CUDA核,还集成DSA性质的Tensor核,使得单个GPU引擎具有了DSA性质的能力。
- FPGA集成CPU以及ASIC,例如AMD Xilinx Zynq。
- ASIC不断回调,变成部分可编程的DSA,可以当作是ASIC+DSA。
处理器引擎不断扩展,在引擎内部形成了某种程度上的“异构”能力,这可以看做是异构计算优化权衡的第三个维度。
4.3 异构计算的未来,从单异构走向多异构融合
前面我们从三个维度介绍了异构计算的优(左)化(右)权(摇)衡(摆):要想获得灵活性,势必会降低性能(效率);而要想获得性能,势必会降低系统的灵活性,增加系统的复杂度,使得系统难以驾驭。但考虑到业务应用对算力的渴求,我们不得不“迎难而上”,不断的提升硬件平台的性能。这样势必会增加整个系统的复杂度,也进一步提高了编程的难度。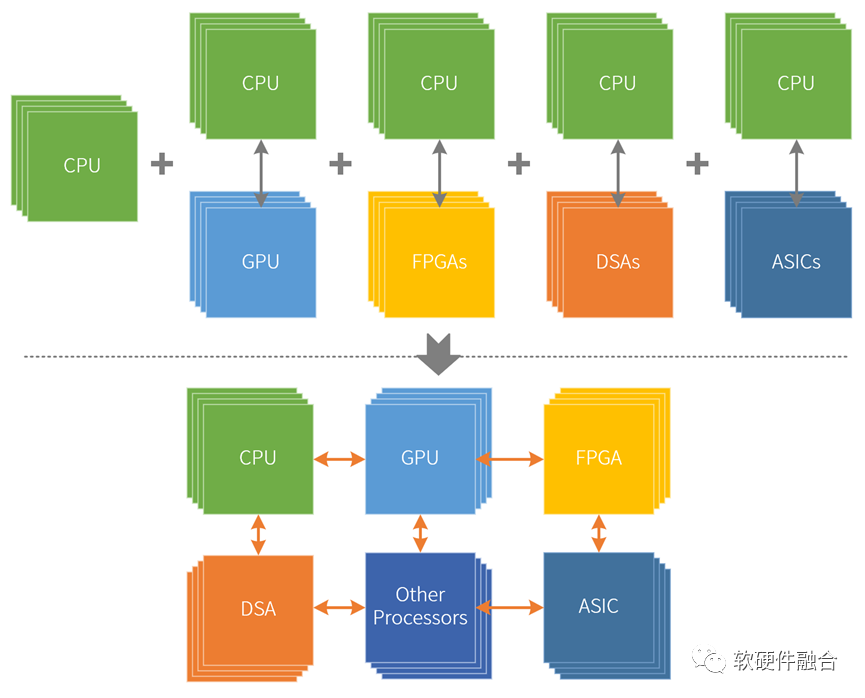 受限于前面提到的异构计算孤岛问题,把多个异构计算系统合并到一起的时候,不能简单的拼凑,而是要重新构建一个新的超异构计算系统。
受限于前面提到的异构计算孤岛问题,把多个异构计算系统合并到一起的时候,不能简单的拼凑,而是要重新构建一个新的超异构计算系统。
接下来,更重要的问题来了:如何驾驭比异构并行更复杂的超异构融合计算?
5、驾驭超异构
串行计算符合人类思维,编程相对最简单;同构并行的编程,就要复杂很多;异构并行,则更是难上加难;那么超异构并行呢?那就是难上加难再加难。要想驾驭超异构,核心的思路跟驾驭异构计算的思路一致,就是要降低软硬件系统的复杂度。接下来,我们详细介绍一些主要的降低复杂度的方法。
5.1 复杂大系统分解成简单小系统
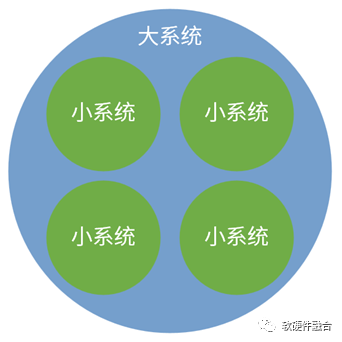 从系统的角度,多个小系统组成一个大系统,多个大系统组成一个宏系统。反过来,复杂大系统可以分解成若干个简单的小的系统,大系统由多个小系统和小系统间的交互组成。
从系统的角度,多个小系统组成一个大系统,多个大系统组成一个宏系统。反过来,复杂大系统可以分解成若干个简单的小的系统,大系统由多个小系统和小系统间的交互组成。
相比大系统,小系统必然更加简单;针对分解后的小系统,则可以更加容易的驾驭。
5.2 依据系统的性能/灵活性特征进行分层
 应用,是完全不可确定的,针对应用,只能采用CPU处理器。如果完全“躺平”(不加约束),并不考虑平台上面运行什么软件任务,那么极端保守的做法就是选用CPU平台。CPU平台什么任务都能支持,但劣势是性能是最差的,成本代价是最高的。一个系统并不都是应用类型的任务。系统可以看作是很多工作任务的组合,这些工作任务都各有特点,我们可以针对任务的特点,把任务进行分类:
应用,是完全不可确定的,针对应用,只能采用CPU处理器。如果完全“躺平”(不加约束),并不考虑平台上面运行什么软件任务,那么极端保守的做法就是选用CPU平台。CPU平台什么任务都能支持,但劣势是性能是最差的,成本代价是最高的。一个系统并不都是应用类型的任务。系统可以看作是很多工作任务的组合,这些工作任务都各有特点,我们可以针对任务的特点,把任务进行分类:
一个极端。在系统中,有很多非常确定性的任务,比如虚拟化、网络、存储等,这些可以称为基础设施型任务。这类任务因为其确定性的特点,特别适合DSA和ASIC级别的加速处理器处理。
另一个极端,即不太好加速的应用部分。在硬件平台上到底会运行什么样的应用,通常是不可预知的,或者说应用是非常不确定的。因此,针对应用,最好是用CPU(+协处理器)平台。CPU平台还有另外一个价值,兜底,凡是无法加速或者不存在合适加速处理器的工作任务都可以放在CPU平台处理。
处于两个极端之间的部分任务,则通常是性能敏感的应用任务,比如AI训练、视频图形处理、语音处理等。这类任务具有一定的确定性,但通常还是需要平台的一些弹性的能力,其性能/灵活性特征处于前面两个极端的中间。因此比较适合GPU、FPGA这样的处理器平台。
针对不同任务的灵活性/性能特征,把任务划分到这三个层次,然后采取各自特征能力相符的处理器平台,可以做到满足整个系统最极致灵活性的同时,实现整个系统最极致的性能。
5.3 开放:让处理器架构和生态收敛,防止碎片化
 架构(硬件的具体实现是微架构,而架构指的是软件看到的硬件架构),也可以称为软硬件接口,是系统架构中最核心的概念。
架构(硬件的具体实现是微架构,而架构指的是软件看到的硬件架构),也可以称为软硬件接口,是系统架构中最核心的概念。
CPU目前有非常流行的RISC-v架构,RISC-v开放架构的价值大家都能够理解。从CPU到ASIC,越往右,处理器的子类型越多,架构的数量也越多。不同类型、不同领域、不同场景、不同厂家、不同架构的处理器,如果不加以约束的话,会导致处理器架构的完全碎片化。越是处理器类型众多,越需要全行业形成共识的开放架构。
5.4 软硬件深度融合,让硬件具有更多软件的能力
软件越来越复杂,业务逻辑变化越来越快,具体的表现就是软件开发者越来越崇尚敏捷开发,两个月一个小迭代,半年一个大迭代。同样由于系统的复杂度提升,硬件却与软件相反,其开发难度越来越大,开发周期1-3年,生命周期5-8年。硬件的迭代周期完全跟不上软件的更新节奏。因此,需要更进一步的系统架构创新,把传统的软件层次的能力融入到硬件中去。这些能力包括功能的扩展性、资源的弹性和近乎无限的资源扩展、完全的硬件虚拟化、硬件高可用等等,通过这些能力来整体的提升硬件的灵活性。
超异构计算,需要“软硬件融合”来驾驭。
-
cpu
+关注
关注
68文章
11327浏览量
225903 -
异构计算
+关注
关注
2文章
112浏览量
17241
发布评论请先 登录
SMT工艺革新:高精度贴装与微型化组装的未来趋势
【「芯片设计基石——EDA产业全景与未来展望」阅读体验】--全书概览
微电网保护的发展趋势是什么?
室外单模光纤技术发展趋势:迈向更高速度、更大容量

AI+工业物联网的未来发展趋势有哪些
[新启航]碳化硅 TTV 厚度测量技术的未来发展趋势与创新方向
![[新启航]碳化硅 TTV 厚度测量技术的<b class='flag-5'>未来</b><b class='flag-5'>发展趋势</b>与创新方向](https://file1.elecfans.com/web3/M00/20/D6/wKgZPGhd-raAI0RYAACIgEePWXY565.png)
AI工艺优化与协同应用的未来发展趋势是什么?

人工智能技术的现状与未来发展趋势
TC Wafer晶圆测温系统当前面临的技术挑战与应对方案

异构计算解决方案(兼容不同硬件架构)
工控机的现状、应用与发展趋势

如何释放异构计算的潜能?Imagination与Baya Systems的系统架构实践启示




评论