 HPM6750 LVGL刷屏性能再提升?大神网友开辟片内新天地
HPM6750 LVGL刷屏性能再提升?大神网友开辟片内新天地

先楫体验官“RSCN”评测了HPM6750的coremark跑分后(原文请至EEWORLD搜索RSCN)又出干货!这次“RSCN”将为我们演示如何优化自己手中的HPM6750使它性能提升。
以下正文转自EEWORLD @RSCN
之前的coremark跑分测评中,在flash和ram运行的性能大致一样,主要的原因还是代码空间小于32K,这刚好是cache的空间范围内,HPM6750有32K ICACHE和32K DCACHE,性能上是最高的,所以跑分上,两者并没有太大的差距。
但是,如果代码空间超过了32K,这时候cache总会有用满的时候,也会有不命中的情况下,这时候需要考虑的正是系统资源和编译整合利用。
下面以littlevgl的benchmark跑分例子要进行性能提升的一个验证方法,当然这仅仅作为参考,并不能决定大多数应用场景。
由于上个贴子说明了SPI的一点缺陷,会导致DMA的辅助功能提升并不大,在实际跑lvgl的时候,code放在flash,编译器使用segger,代码缺省优化,也其实没优化的情况下,生成的代码如下:
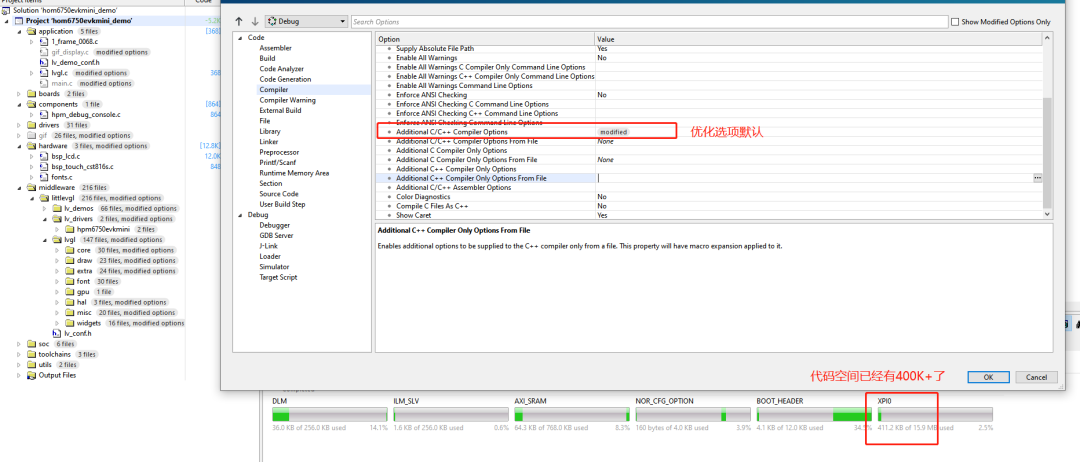
那么按照这样烧录进去,weightied fps大概是120多左右
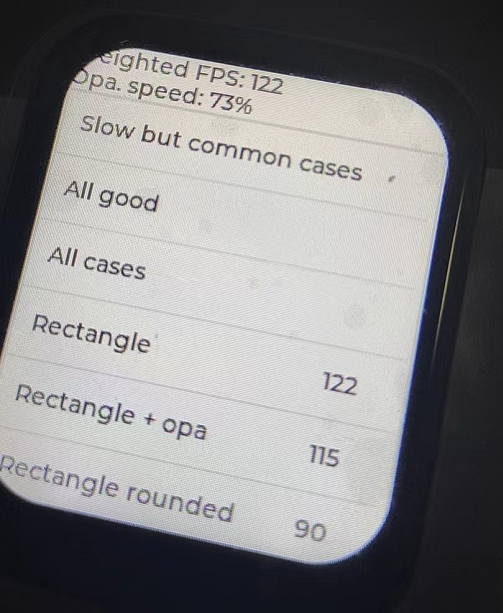
这是有点低了,先从lvgl的配置上去优化,lvgl的刷新周期,从30fps最大刷新率改为100fps刷新率,提升上也并不是很大,大概在160左右变动。

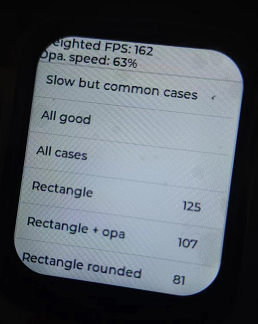
那么开O3优化的效果又是如何,再次烧录进去,weightied fps大概是174多左右
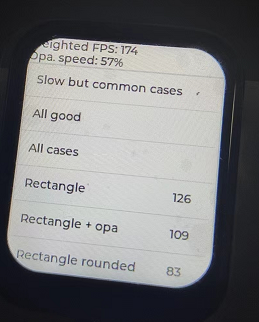
当然也试了以下方法,实验过程也忘了拍照,但是其实效果性能并没有提升多少,也就180左右变动
1、改为全尺寸双缓冲,但是其实这种对MCU屏幕有用,对于SPI屏幕上,效果并没多少。
2、改为非全尺寸双缓冲,大概五分之一局部刷新。
3、改为单缓冲局部刷新和单缓冲全尺寸刷新,效果均不大。
于是试着找了官方的技术,放假期间的,技术也在中午跟着我远程调试了下,换为GCC编译器,以及开启了相关优化,优化提升也不明显,大概也是180fps变动。
在调试的过程中,有个idea让楼主茅塞顿开,也就是官方技术建议把中断isr放在ram运行,但实际提升也不大。
于是楼主照着这个思路来看下性能有没有增加,也就是把核心的代码加载到ram中运行。好在HPM6750有足够的RAM来加载,根据手册可知道,两核心有SLV各512K,SRAM一共1M,这是足够加载很多核心代码。

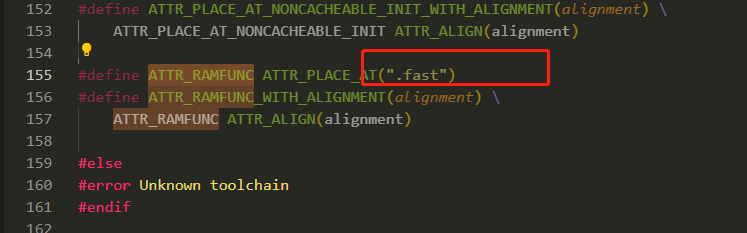
说干就干,在代码上去实现的话,可以使用ATTR_RAMFUNC修饰符放在定义的函数前面,这样编译的时候就会加载到RAM运行。
在实际调试中,单纯几个函数的修饰并不能解决问题。也不可能去手动一个一个修饰,好在与SES可以可视化去操作加载。从ATTR_RAMFUNC,Link文件可看到。
ATTR_RAMFUNC是把函数放在了section的.fast中
从Link可看到,fast是放在了ILM_SLV的256K空间中。

于是我们可以参考Link,自己在copy个link,把fast放在更大的RAM上,也就是SRAM上

那么ses如何去加载这些函数到RAM上了,跟keil类似
右键点击需要加载的文件夹,选择options
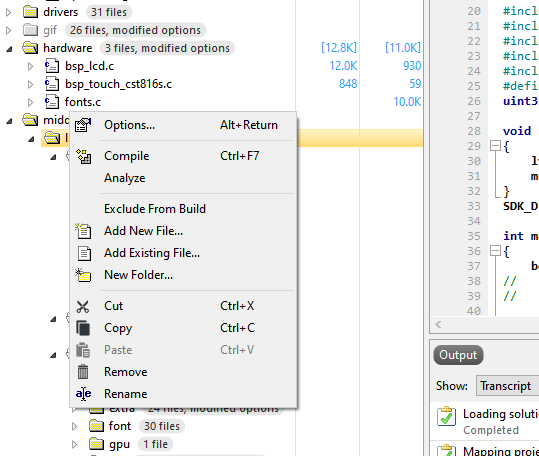
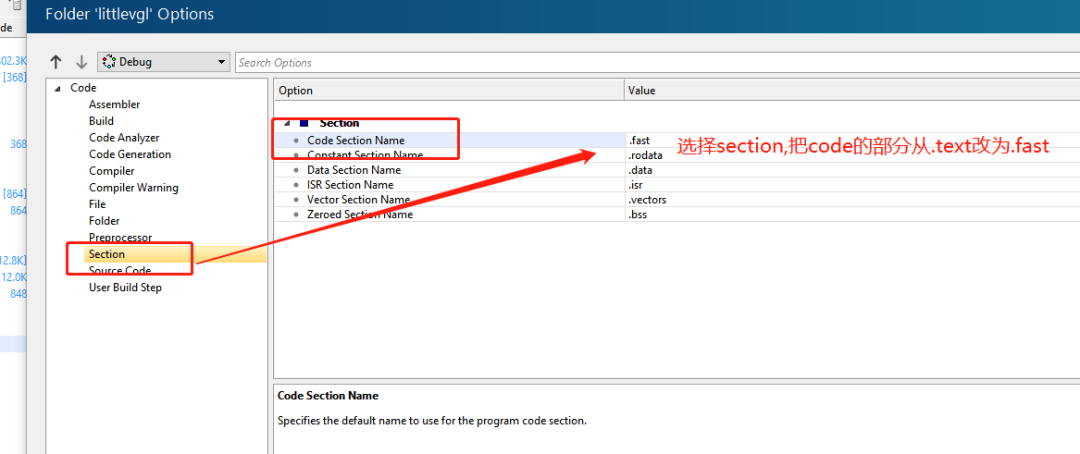
选择code段改为.fast,这样就可以一次搞定加载所有需要到RAM运行的函数。
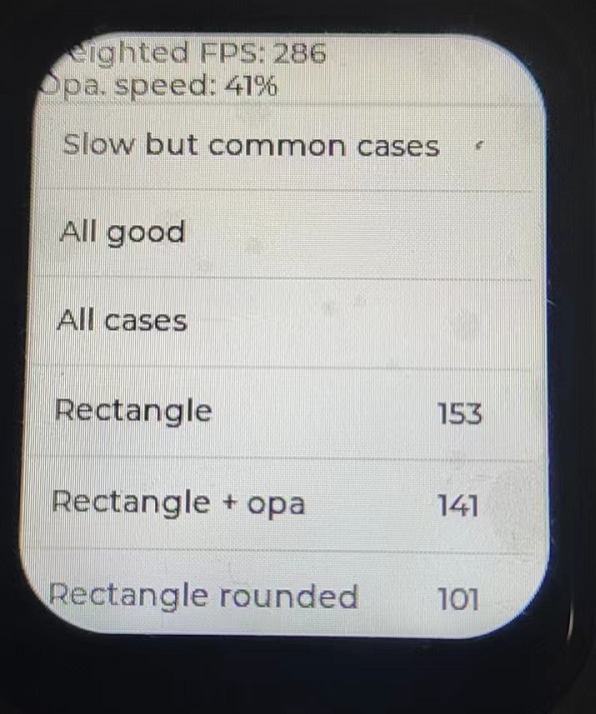
根据之前的调试性能,再加载核心的放在RAM中运行,烧录代码进去,奇迹的时刻,从122fps提升到286,整整提升了两倍性能,这已经对于SPI这个稍微缺陷IP,足够有帮助了。
于此总结:
1、在从代码优化,编译器优化上,可以提高性能。
2、在1的基础上,随着代码空间的增多,32k cache总有用完的时候,xip flash 也会有所损失性能,最好就是可以把主要的代码加载到RAM中运行,更可提高性能。
3、除了32K cache的加持,内部RAM整合也有足够2M,对于系统而言,是足够性能整合的。
-
嵌入式
+关注
关注
5210文章
20726浏览量
338079
发布评论请先 登录
ADRF6750:950 MHz - 1575 MHz 集成式正交调制器的技术解析
请问使用HPM6750连续读取norflash,程序会跑飞,是什么原因?求解
hpm6750 高频发送 udp_send 时 过一段时间就返回ERR_INPROGRESS
固件烧录速度实测:JTAG比UART快6.8倍

hpm6750 两个板载网卡+usbcdc_ecm网卡,多次调用ftp,切换网卡后,报错
瑞萨电子携手LVGL PRO推进嵌入式图形用户界面开发

重大更新,LVGL有UI编辑器用了,2秒内加载,快到飞起!
【上海晶珩睿莓1开发板试用体验】移植LVGL9.3并使用32位色进行显示
基于RTThread nano的LVGL线程卡顿怎么解决?

HPM monitor studio 只能在 hpm芯片+hpm_sdk 的组合下才能用吗?
先楫半导体高性能MCU入驻立创商城,国产芯势力再添新动能

CSC7137B 应用指南:小功率电源管理革新方案
【EASY EAI Orin Nano开发板试用体验】移植LVGL9.1(C语言工程)
【产品介绍】闪射法导热仪LFA 467 HyperFlash




评论