 每日一课 | 智慧灯杆视觉技术之语义分割
每日一课 | 智慧灯杆视觉技术之语义分割
3.2.4语义分割
图3-7所示为机器视觉语义分割示例。
计算机视觉的核心是分割,它将整个图像分成一个个像素组,然后对其进行标记和分类。语义分割试图在语义上理解图像中每个像素的角色(例如,识别它是道路、汽车还是其他类别)。如图3-7所示,除识别人、道路、汽车、树木等外,还必须确定每个物体的边界。因此,与分类不同,需要用模型对密集的像素进行预测。
与其他计算机视觉任务一样,卷积神经网络在分割任务上取得了巨大成功。最流行的原始方法之一是通过滑动窗口进行块分类,利用每个像素周围的图像块,对每个像素
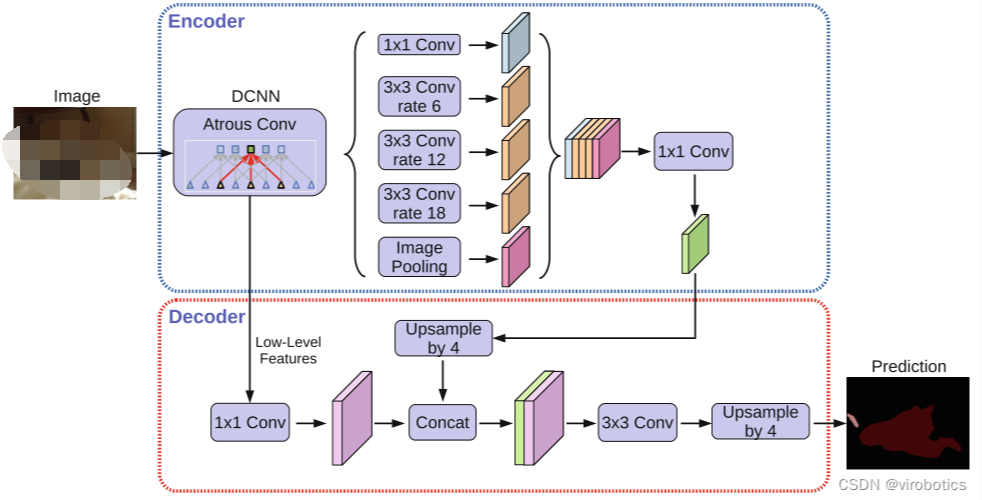
分别进行分类。但是其计算效率非常低,因为我们不能在重叠块之间重用共享特征。解决方案之一就是加州大学伯克利分校提出的全卷积网络(FCN),它提出了端到端的卷积神经网络体系结构,在没有任何全连接层的情况下进行密集预测,如图3-8所示。
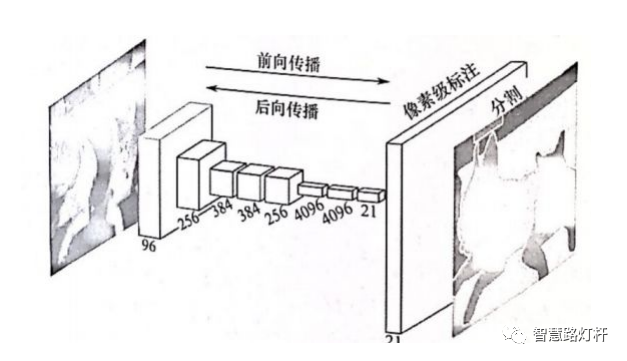
图3-8 全卷积网络(FCN)实现像素分类演示
这种方法允许针对任何尺寸的图像生成分割映射,并且比块分类算法快得多,几乎后续所有的语义分割算法都采用了这种范式。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
智慧灯杆
+关注
关注
1文章
769浏览量
11598
发布评论请先 登录
相关推荐
三项SOTA!MasQCLIP:开放词汇通用图像分割新网络
MasQCLIP在开放词汇实例分割、语义分割和全景分割三项任务上均实现了SOTA,涨点非常明显。这里也推荐工坊推出的新课程《彻底搞懂视觉-惯
一种在线激光雷达语义分割框架MemorySeg
本文提出了一种在线激光雷达语义分割框架MemorySeg,它利用三维潜在记忆来改进当前帧的预测。传统的方法通常只使用单次扫描的环境信息来完成语义分割任务,而忽略了观测的时间连续性所蕴含
机器视觉(六):图像分割
基于阈值的分割方法是一种应用十分广泛的图像分割技术,其实质是利用图像的灰度直方图信息获取用于分割的阈值,一个或几个阈值将图像的灰度级分为几个部分,认为属于同一部分的像素是同一个物体。

深度学习图像语义分割指标介绍
深度学习在图像语义分割上已经取得了重大进展与明显的效果,产生了很多专注于图像语义分割的模型与基准数据集,这些基准数据集提供了一套统一的批判模型的标准,多数时候我们评价一个模型的性能会从
发表于 10-09 15:26
•165次阅读

【每日一练】参与FPGA技术社区每日学习,轻松掌握Verilog语法!
活动介绍:
每日一练活动主要针对 Verilog 入门常用语法及常用技巧的练习,30个关于语法练习的题目,每天更新一个题目及公布前一天的参考答案及相关解析
活动规则:
发表于 08-01 10:37
CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构
Adapter Network (SAN)的新框架,用于基于预训练的视觉语言模型进行开放式语义分割。该方法将语义分割任务建模为区域识别问题

CVPR 2023 中的领域适应: 一种免反向传播的TTA语义分割方法
TTA 在语义分割中的应用,效率和性能都至关重要。现有方法要么效率低(例如,需要反向传播的优化),要么忽略语义适应(例如,分布对齐)。此外,还会受到不稳定优化和异常分布引起的误差积累的困扰。
PyTorch教程-14.9. 语义分割和数据集
,语义分割中标记的像素级边界明显更细粒度。
图 14.9.1语义分割中图像的狗、猫和背景的标签。¶
14.9.1。图像分割和


常见的语义分割模型
计算机视觉(Computer Vision)是指让机器通过数字图像或视频等视觉信息来模拟人类视觉的过程,以达到对物体的理解、识别、分类、跟踪、重建等目的的技术。它是人工智能领域中的一个






 工商网监
工商网监
评论