 利用强化学习来探索更优排序算法的AI系统
利用强化学习来探索更优排序算法的AI系统

前言
DeepMind 最近在 Nature 发表了一篇论文 AlphaDev[2, 3],一个利用强化学习来探索更优排序算法的AI系统。
AlphaDev 系统直接从 CPU 汇编指令的层面入手去探索更优的排序算法,因为相对于高级编程语言来说,在汇编指令层级对存储和寄存器的操作可以更加的灵活,所以能发现更多潜在的调优策略。
在 AlphaDev 的论文中,只关注探索短序列排序:
定长序列排序(比如 sort3 算法只能对长度为3的序列进行排序)
变长序列排序(比如 variable sort5 算法可以对长度为1~5的变长序列进行排序)
而对于长序列的排序,可以被分解为短序列的排序。
DeepMind 通过 AlphaDev 发现了比目前人工调优算法更优的定长短序列排序算法 sort3,sort4 和 sort5 ,并且已经将代码提交到了 LLVM 标准 C++ 库[4] 。
简单来说,AlphaDev 将探索更高效排序算法的过程,建模为一个单玩家的汇编游戏(single-player game, AssemblyGame)。
游戏的过程就是玩家从 CPU 汇编指令集合中,选取一系列的指令组合得到一个新的排序算法。不过这个过程是非常有挑战的,玩家需要考虑,汇编指令的组合空间并最终得得到一个正确和高效的算法。
该游戏主要包括以下难点:
汇编游戏的搜索空间和围棋类似(10^700)
只要有一条指令没弄对,可能就会导致整个算法错误
AlphaDev 系统详解
将排序算法表示为 CPU 汇编指令
首先来看一个简单的变长(variable sort2)短排序函数的 C 代码实现,排序结果从小到大:
voidvariable_sort_2(intlength,int*a){
switch(length){
case0:
case1:
return;
case2:
inttmp=a[0];
//a[0]保存两者之间的最小值
a[0]=(a[1]< a[0]) ? a[1] : a[0];
// a[1] 保存两者之间的最大值
a[1] = (a[1] < tmp) ? tmp : a[1];
return;
}
}
通过 gcc 生成对应的汇编代码,我用的 gcc 版本是 11.3.0,命令 gcc -S -O1 -o sort2.s sort2.c
汇编代码只保留了核心部分,生成的结果和论文中的示例有些许不同但是原理是一致的:
variable_sort_2: .LFB0: ; %edi 寄存器保存参数 length 的值 ; cmpl 指令对比 %edi 和 常量 2 cmpl$2, %edi ; 相等就跳转到 .L3 标签处, ; 对应 C 代码的 case 2 je.L3 .L1: ; 不等于 2 就直接返回, ; 对应 C 代码 case 0 和 1 ret .L3: ; 将 a[0] 赋值给寄存器 %edx movl(%rsi), %edx ; 将 a[1] 赋值给寄存器 %eax movl4(%rsi), %eax ; 对比 %edx 和 %eax cmpl%edx, %eax ; 将 %edx 赋值给 %ecx movl%edx, %ecx ; cmov 是条件移动指令根据 cmpl ; 指令的结果判断是否执行 ; 如果 %eax <= %edx ; 则将 %eax 赋值给 %ecx cmovle%eax, %ecx ; 此时 %ecx 保存了最小值 ; 将 %ecx 赋值给 a[0] movl%ecx, (%rsi) ; 如果 %eax 小于 %edx ; 则将 %edx 赋值给 %eax cmovl%edx, %eax ; 此时 %eax 保存了最大值 ; 将 %eax 赋值给 a[1] movl%eax, 4(%rsi) jmp.L1
一般来说汇编程序所做的事情基本都是,将内存的值复制到寄存器,然后对寄存器的值作修改,再将寄存器的值写回到内存中。
而 AlphaDev 系统只关注 x86 处理器架构所支持的汇编指令集合的一个子集。
每条汇编指令的格式均为:操作码<操作数A, 操作数B> 比如:
mov
cmp
cmovX
jX 条件跳转指令,根据 X 和 flag 寄存器的值判断是否执行跳转到指定标记位置操作,A 可以是汇编程序代码中的标记位置,如上面所示汇编代码的 .L1 和 .L3。X 可以是 NE (是否不等于),E (是否等于)或者可以填表示无条件跳转。
将探索更优排序算法表示为强化学习问题
AlphaDev 将 CPU 汇编指令层面的算法优化过程转化为一个单玩家的游戏。
游戏每一步的状态定义为 : St =
其中, Pt 表示游戏到至今为止所生成的算法,Zt 则表示在给定输入的前提下执行完 Pt 里的指令之后,内存和寄存器的状态。
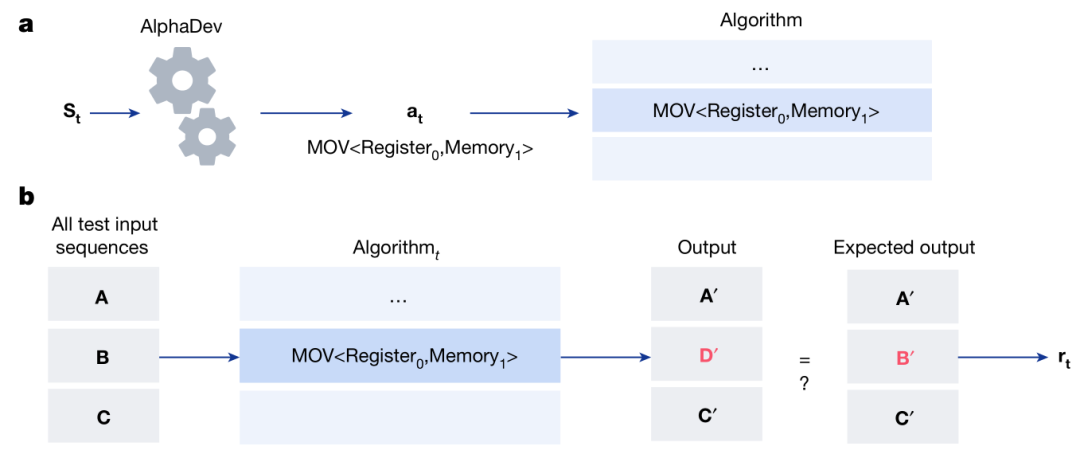
如上图所示,在时间步 t ,AlphaDev 接受到当前状态 St 和 所要执行的动作 at (比如 mov
在添加完指令之后,就是计算奖励分数 rt (包括评估算法的正确性和延迟)。
算法正确性评估
正确性评估就是将 N 组测试序列输入到算法 Pt 中,得到N 组输出,和正确的排序结果最比较来计算奖励分数。
论文中给出了3种正确性评估函数,首先定义 P 为输入序列长度, PCt 为在时间步 t 序列中,位置正确的值的个数,这里我理解应该是和正确的排序结果逐个位置对比,统计相等的个数。
三个函数分别定义如下:
func1 = (P - PCt) / P
func2 = sqrt(func1)
func3 = sqrt(PCt)
论文中提到采用第三个函数效果最好。
延迟评估
延迟分数的计算可以是:
对系统增加代码长度计算惩罚,因为代码的长度一般都是和耗时高度相关
直接计算算法的真实耗时
整个强化学习的游戏在执行有限步骤之后就会被终止。只有生成正确而又低延迟的汇编代码才算赢得游戏。而不管是生成了错误的代码还是正确但低效的实现都视为游戏输了。
AlphaDev 采用的强化学习算法是对 AlphqaZero 算法的扩展,也是采用深度神经网络来引导蒙特卡洛树搜索(MCTS)的规划过程。网络模型的输入是 St ,输出是对动作策略和奖励的预测。
整个游戏过程简单来说就是,用一个固定参数的网络模型,通过给定的当前状态执行一个蒙特卡洛树搜索过程,然后采取下一步动作。然后可以用生成的游戏过程(包含每一步的状态和奖励)去训练和更新网络的参数。
网络模型结构
模型包含两部分:
一个 Transformer 编码器模块,用于建模算法,输入是至今为止生成的汇编指令序列
一个 CPU 状态编码器 MLP 模块,输入当前寄存器和内存的状态
两个网络的输出 embedding 会合并在一起来表示当前的状态。
网络模型整体的结构如下: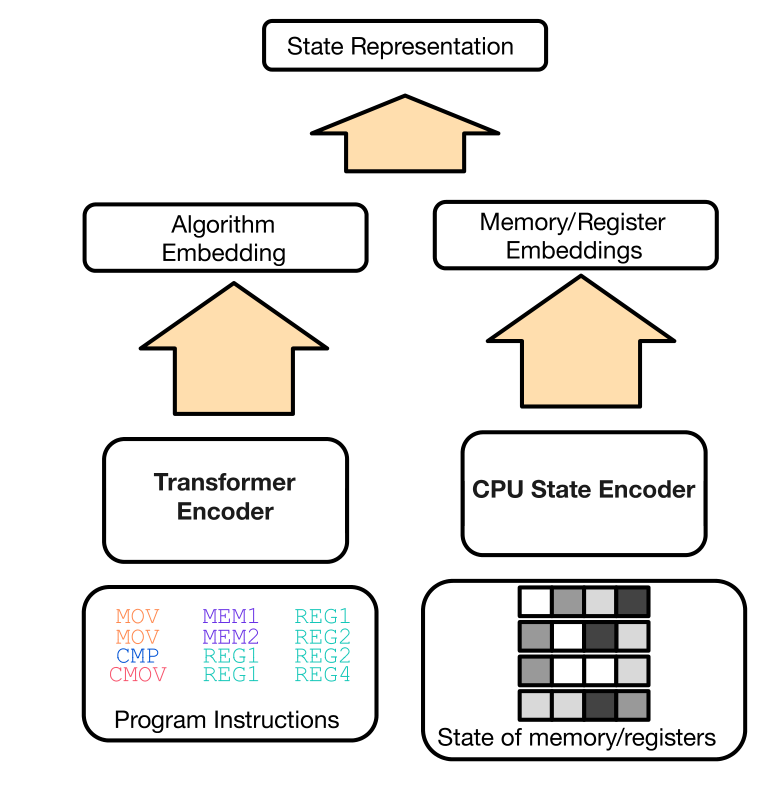
Transformer 编码器模块具体图示
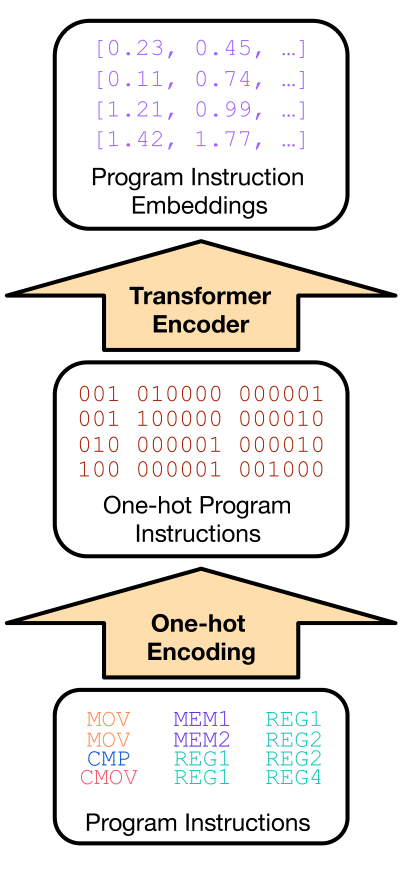
如上图所示,把当前生成的汇编代码序列的每一条指令的操作码和操作数都转换为 one-hot 编码序列,然后输入到网络中。
但是具体的 one-hot 编码规则、词表怎么设置、还有对于 CPU 状态编码网络寄存器和内存的状态是怎么表示为网络的输入的等等,这些细节我在论文里没找到。
然后两个网络的输出 embedding 会合并到一起接着输入到几个函数头里计算,分别是预测下一步策略的函数头,预测算法正确性的函数头和预测算法真实延迟的函数头。
网络参数超参设置
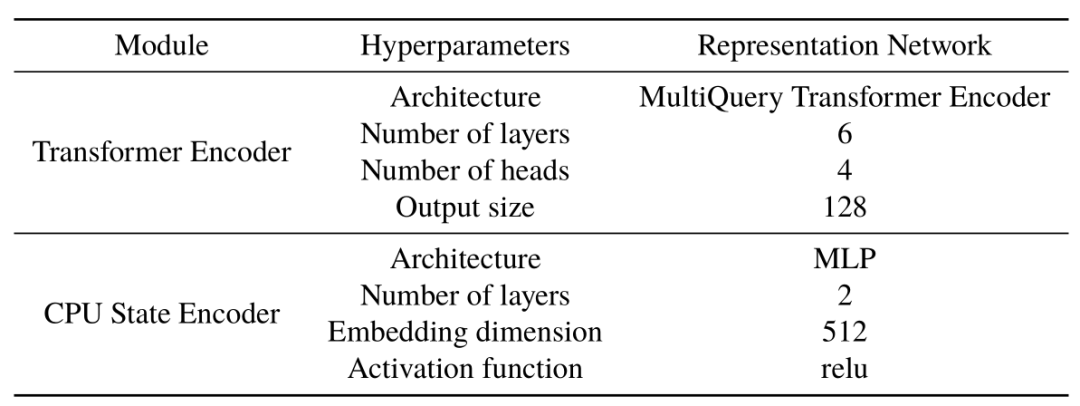

论文的补充资料中提供了网络的参数和三个函数头的具体配置。
而对于策略的预测,论文中提到为了简化问题和提高收敛性,而对动作空间做了一些限制,规则如下:
必须按照升序方式读取内存
寄存器按照升序分配
cmp 和 cmovX 指令的操作数不能出现内存地址
对每个内存位置,只能读取和写入一次
每个寄存器在使用之前,必须初始化
不能连续调用 cmp 指令
训练细节
AlphaDev 的训练采用了 TPU v3,每个 TPU 核的 batch size 是 1024 ,总共用了 16 个 TPU 核,总共训练了 100 万次迭代。而在对于玩游戏积累训练数据来说,则是在 TPU v4 上进行,总共用了 512 个 TPU 核。
实验结果表明,最多只需2天模型就能训收敛。
实验结果
生成的算法和人工调优对比
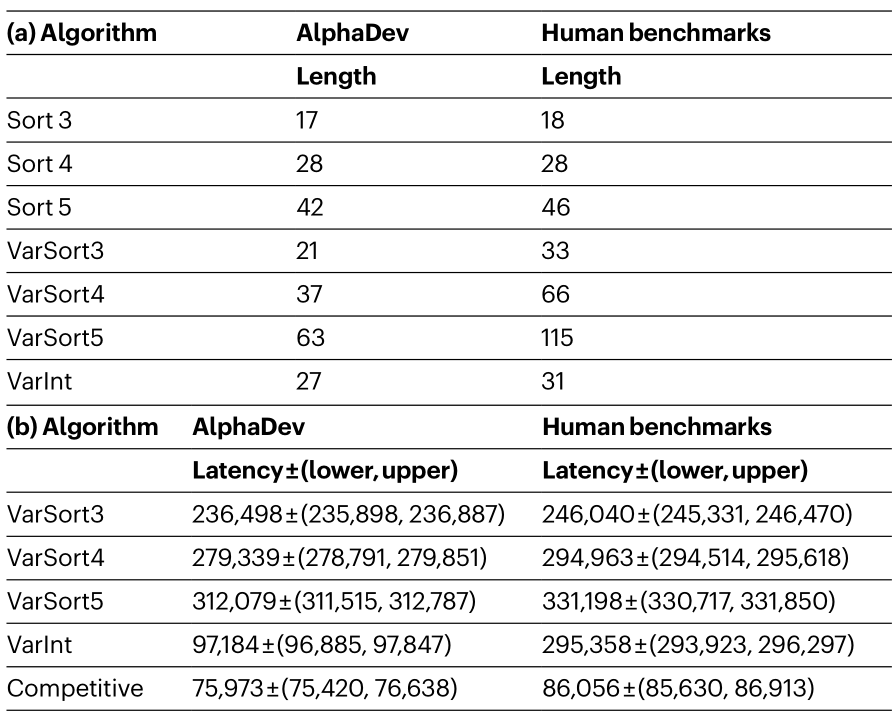
从实验结果表格可以看到,对于短序列排序算法 AlphaDev 生成的代码长度更短,而且平均耗时也更低。
对生成算法延迟的评估方式,比如对于 sort3 则是在 100 台机器上做评估,每台机器随机生成 1000 条 3个数的序列,然后每条序列输入到算法中,对这 1000 次评估取第5百分位数作为最终的评估结果(排除 cache miss 和 任务抢占 等因素)。
耗时采用的是 CPU_CLK_UNHALTED.CORE 这个计数器结果, 其计数值表示在一个特定时间段内,处理器内核的时钟周期数。这个值越高,意味着处理器内核在该时间段内执行了更多的指令。
AlphaDev 发现新的算法
对于定长序列排序,当应用到排序网络算法[6](sorting network algorithm)的时候 AlphaDev 生成的代码中包含了一些有趣指令序列,相对于原始指令序列可以减少一条汇编指令,论文中称之为:
AlphaDev swap move
AlphaDev copy move
啥是排序网络算法?
排序网络算法(Sorting Network Algorithm)是一种能够对一组输入数据进行排序的并行算法,其具有较好的并行性能适用于多处理器或多核心系统。
该算法的特点是,它将所有的比较和交换操作预先规划好形成一个固定的结构,然后将输入数据按照这个结构进行排序。
排序网络由比较器(comparator)和线(wire)组成,如下图所示: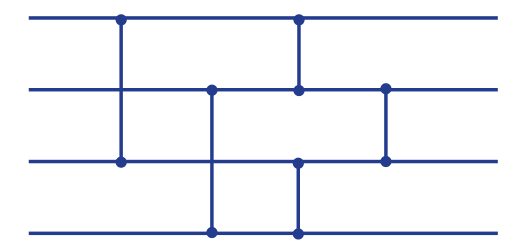
水平线表示 wire,每条水平线持有一个待排序的值。两条 wire 之间的垂直线段就表示一个比较器,比较器对比两条水平线的值,如果比较器下方的值小于上方的值则交换两条横线的值,否则则不交换。
一个优化过的排序网络可以以最少的比较器,并将这些比较器放置在特定位置上,来实现对任意序列进行排序。
下图是对一个构造好的排序网络,输入真实待排序序列的例子: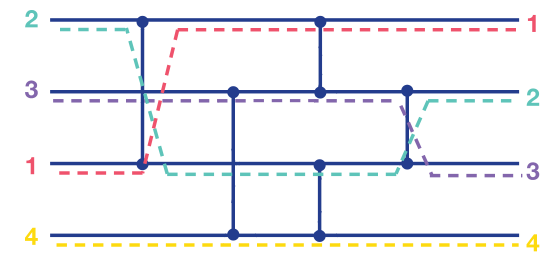
可见初始输入是 [2, 3, 1, 4],这些随机数从左到右按顺序经过这些比较器之后,就得到了排序好的序列 [1, 2, 3, 4]。
AlphaDev swap move
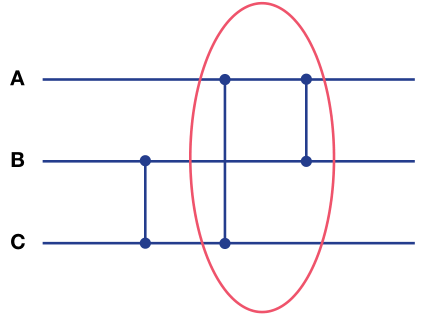 先来看这个排序网络,只看红圈部分的功能就是对给定的输入 [A, B, C] 将其转换为 [min(A,B,C), max(min(A,C),B), max(A,C)]。
先来看这个排序网络,只看红圈部分的功能就是对给定的输入 [A, B, C] 将其转换为 [min(A,B,C), max(min(A,C),B), max(A,C)]。
然后经过 AlphaDev 优化之后,可以将第一个输出的 min(A,B,C) 改为只计算 min(A,B),原因是因为前面的 B 和 C横线之间经过比较器之后已经有了前置条件 B <= C。
而通过这个优化就能省去一条汇编指令,下图是红圈部分的伪代码实现:

左边是原始伪代码实现,右边是经过 AlphaDev 优化之后的实现,可以看到少了一条汇编指令 mov S P。
AlphaDev copy move
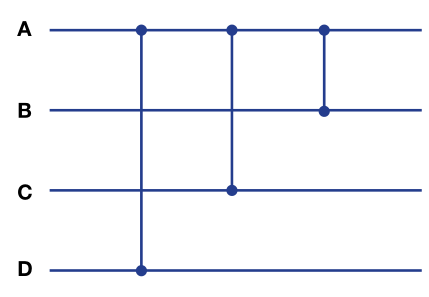
接下来看对4个元素进行排序的排序网络,是在对 sort8 这个算法优化过程中发现的。该排序网络对于输入序列 [A, B, C, D] 转换为 [min(A, B, C, D), max(B, min(A, C, D), max(C, min(A, D)), max(A, D) ]。
该排序网络是 sort8 的一个子排序网络,而根据比较器的放置位置来看,A 和 D 比较之后后续就不再和其他元素比较了,所以D出来的结果就是四个元素中最大的,所以隐含了一个条件就是 D >= min(A, C)。
因此对第二个输出元素的计算可以从 max(B, min(A, C, D)) 改为 max(B, min(A, C)),就可以节省一条汇编指令。
伪代码如下:

左边是原始伪代码实现,右边是经过 AlphaDev 优化之后的实现,可以看到少了一条汇编指令 mov P T。
总结
这篇文章只是对 AlphaDev 论文中的主要内容作解读,对于更多的内容和细节感兴趣的读者可以查阅原论文和论文的补充资料 [2,3],DeepMind 也也开源了一份伪代码实现 [7]。
责任编辑:彭菁
-
建模
+关注
关注
1文章
320浏览量
62738 -
AI
+关注
关注
89文章
38099浏览量
296620 -
排序算法
+关注
关注
0文章
53浏览量
10372
发布评论请先 登录

什么是深度强化学习?深度强化学习算法应用分析

深度强化学习实战
利用强化学习探索多巴胺对学习的作用

什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

对NAS任务中强化学习的效率进行深入思考
基于PPO强化学习算法的AI应用案例
机器学习中的无模型强化学习算法及研究综述

彻底改变算法交易:强化学习的力量
DeepMind新作AlphaDev----强化学习探索更优排序算法






 工商网监
工商网监
评论