 使用Isaac Gym 来强化学习mycobot 抓取任务
使用Isaac Gym 来强化学习mycobot 抓取任务

我现在将介绍一个利用myCobot的实验。这一次,实验将使用模拟器而不是物理机器进行。当尝试使用机器人进行深度强化学习时,在物理机器上准备大量训练数据可能具有挑战性。但是,使用模拟器,很容易收集大量数据集。然而,对于那些不熟悉它们的人来说,模拟器可能看起来令人生畏。因此,我们尝试使用由 Nvidia 开发的 Isaac Gym,它使我们能够实现从创建实验环境到仅使用 Python 代码进行强化学习的所有目标。在这篇文章中,我将介绍我们使用的方法。
1. 简介
1.1 什么是Isaac Gym?
Isaac Gym是Nvidia为强化学习开发的物理模拟环境。基于 OpenAI Gym 库,物理计算在 GPU 上进行,结果可以作为 Pytorch GPU 张量接收,从而实现快速模拟和学习。物理模拟是使用 PhysX 进行的,它还支持使用 FleX 的软体模拟(尽管使用 FleX 时某些功能受到限制)。
截至 2023 年 4 月的最新版本是预览版 3。虽然早期版本有明显的错误,但版本 6000 及更高版本已经看到了改进和添加功能,使其成为一个非常有吸引力的模拟环境。计划与Isaac Sim集成的Omniverse Isaac Gym的未来版本。但是,Isaac Gym本身是独立的,可用于Python中的实验。在之前的博客文章(“GPU 服务器扩展和 A<> 基准测试”)中,提到使用 Omniverse Isaac 模拟器的研究和开发已经开始,但 Isaac Gym 被优先用于强化学习模拟。将Isaac Gym与Omniverse集成的最大好处可能是能够使用逼真的视觉效果进行图像识别和高精度连续身体模拟,例如光线追踪。看到未来如何发展将是令人兴奋的。
PhysX 是由 Nvidia 开发的物理引擎,可在模拟器的 GPU 上进行实时物理计算。虽然 Isaac Gym 使用的版本尚未在公开的 arXiv 或文档中指定,但考虑到它的发布时间和与 FleX 的分离,它很可能基于 PhysX 4。在 Omniverse 中,使用 PhysX 5 并集成了 FleX。
FleX 也是 Nvidia 开发的物理引擎,但与 PhysX 的刚体模拟相比,它能够使用基于粒子的模拟来表示软体和流体。
1.2 本文的目的
我将告诉您我如何使用Isaac Gym轻松创建和学习强化学习任务。作为实际的测试用例
1.3 环境
PC1: Ubuntu 20.04, Python 3.8.10, Nvidia RTX A6000
PC2: Ubuntu 18.04, Python 3.8.0, Nvidia RTX 3060Ti
请注意,需要 Nvidia Driver 470 或更高版本。
2.安装
在本章中,我们将安装 Isaac Gym 和 IsaacGymEnvs。推荐环境为 Ubuntu 18.04、20.04、Python 3.6~3.8、Nvidia Driver==470。请注意,由于 python_requires<3.9 在 Isaac Gym 的 setup.py 中有描述,因此不能按 3.9 及更高版本的原样使用。尚未在 Ubuntu 22.04 上进行测试,但可能没问题。
2.1 Isaac Gym
您可以从 Nvidia的开发人员页面免费下载Isaac Gym主软件包。文档以HTML格式保存在软件包的“docs”目录中(请注意,网站上没有)。下载后,您可以使用以下命令安装它:
$ cd isaacgym/python$ pip install -e .
但是,由于 PyTorch 被指定为“torch ==1.8.0”和“torchvision ==0.9.0”,因此在使用 GPU 时,您应该首先从与您的环境匹配的官方页面安装它。Docker 和 Conda 虚拟环境设置文件也可用。由于我使用 venv 来管理我的 Python 虚拟环境,所以我将继续使用 pip。请注意,由于代码块问题,我用全角字符写了“>”
2.2IsaacGymEnvs
IsaacGymEnvs是一个Python软件包,用于在Isaac Gym中测试强化学习环境。通过参考实现的任务,可以使用 rl-games 中实现的强化学习算法轻松构建强化学习环境。即使对于那些计划编写自己的强化学习算法的人,也建议尝试使用此软件包与 Isaac Gym 一起学习。它最初包含在 Isaac Gym 中,在 Preview3 中分离出来,现在在 GitHub 上公开可用。
$ git clone https://github.com/NVIDIA-Omniverse/IsaacGymEnvs.git$ cd IsaacGymEnvs$ pip install –e .
这样,必要的安装现在就完成了。
3. 演示
当您安装 Isaac Gym 并查看软件包内部时,您会发现有许多示例环境可用。这些也出现在文档中,但在本文中,我们将在第 4 章中重点介绍一些与创建自定义强化学习环境相关的示例。如果已设置环境,最好尝试运行其中一些示例,看看它们可以执行哪些操作。您甚至可能会发现它们提供了有关如何使用 API 完成您有兴趣尝试的事情的一些指导(如果您仍然不确定,请随时通读文档)。
3.1.Isaac Gym
截至预览版 4,有 27 个示例环境可用。
● “1080_balls_of_solitude.py”
“1080_balls_of_solitude.py”脚本生成一组金字塔形的球,这些球会掉下来。在没有选项的情况下运行脚本只允许同一环境(即在同一金字塔内)内球之间的碰撞。“--all_collisions”选项允许与其他环境中的球发生碰撞,而“--no_collisions”选项可禁用同一环境中物体之间的碰撞。此脚本还演示如何配置“create_actor”函数的参数以将对象添加到环境中。
● “dof_controls.py”
该脚本具有一个以3D方式移动的Actor,这是OpenAI Gym中众所周知的Cartpole问题的变体。它演示了如何为机器人的每个自由度 (DOF) 设置控制方法,可以是位置、速度或力。一旦设置,这些控制方法在模拟过程中无法更改,并且只能通过所选方法控制Actor。忘记设置这些控制方法可能会导致执行组件无法移动。
● “franka_nut_bolt_ik_osc.py”
这个脚本展示了Franka Robotics的多关节机器人手臂Panda拿起一个螺母并将其拧到螺栓上。手臂使用反向运动学(IK)进行控制。文件名包括“OSC”,但此脚本中未实现 OSC 控制。但是,脚本“franka_cube_ik_osc.py”包括 OSC 控制。
通过在预览版 4 中添加 SDF 碰撞,可以加载高分辨率碰撞文件,从而可以在螺母和螺栓槽之间精确计算碰撞(图 1)。虽然初始 SDF 加载可能需要一些时间,但后续加载会缓存并快速启动。

图 1:熊猫臂将螺母驱动到螺栓上的模拟
● interop_torch.py
此脚本演示如何使用函数get_camera_image_gpu_tensor直接从 GPU 上的相机获取传感器数据。获得的数据可以使用OpenCV输出为图像文件,就像常规物理相机一样。执行时,该脚本会创建一个名为 interop_images 的目录,并将相机图像保存在该目录。由于仿真数据不在GPU和CPU之间交换,因此可以快速处理图像。但是,如果使用多 GPU 环境,则可能会发生错误。论坛上建议的一种解决方案 是将 GPU 使用率限制为 CUDA_VISIBLE_DEVICES=0,但这在用于此脚本的环境中不起作用。
3.2.Isaac Gym环境
实现了 14 个强化学习任务,可以使用任务目录中的脚本执行基准测试。
● 关于配置文件
为每个任务准备一个用 YAML 编写的配置文件。常用设置位于 cfg 目录的 config.yaml 中,可以使用 Hydra 使用命令行选项更改设置,而无需更改 YAML 文件。每个任务环境和 PhysX 的详细设置都存储在 cfg/task/ 目录中,算法选择和结构存储在 cfg/train/ 目录中。
● 关于算法实现
强化学习算法在Rl游戏中使用PPO实现。尽管 docs/rl_examples.md 提到了选择 SAC 的选项,但它目前未包含在存储库中。
NN 层通常是 MLP,某些模型还包括 LSTM 层作为 RNN 层。尽管也可以添加 CNN 图层,但没有包含 CNN 图层的示例模型。在第 5.2 节中,我们将讨论将 CNN 层添加到模型的经验。
示例代码可以在 train.py 所在的 isaacgymenvs 目录中执行。
● 卡特杆
python train.py task=Cartpole [options]
这是经典的推车任务,目标是以杆子不会掉落的方式移动推车。默认情况下,模型训练 100 个 epoch,在 PC2 RTX 2Ti 环境中大约需要 3060 分钟,在无外设模式下(没有查看器)只需要 15 秒。当使用推理测试模型时,它表现良好,杆子保持直立(经过 30 个时期的训练后,模型经过足够的训练以保持极点直立)。虽然看起来很简单,但模型可以学习成功完成此任务的事实令人放心。
● 弗兰卡立方体堆栈
python train.py task=FrankaCubeStack [options]
这是一项使用熊猫手臂堆叠盒子的任务。7轴臂的关节运动是一步一步学习的。默认设置为 10, 000 个纪元,但手臂运动可以在大约 1, 000 个纪元内学习。在 PC1 RTX A6000 环境中,完成 1, 000 个时期的训练大约需要 20-30 分钟。图 2 和图 3 显示了手臂的前后状态,从随机移动到成功抓取和堆叠盒子。
动作空间由手臂关节的 7 个维度组成,而观察空间共有 26 个维度。奖励函数旨在针对涉及靠近盒子、抬起盒子、将盒子彼此靠近以及成功完成堆叠任务的操作进行不同的缩放。
令人惊讶的是,手臂可以如此容易地学习这种级别的任务。但是,请务必注意,学习假定定义的世界坐标系以及对象的已知位置和方向。因此,将这种学习行为应用于物理机器人可能并不那么简单。
26维观测细分:
● 7 个尺寸,用于移动盒子的位置和方向
● 从被堆叠的盒子到被移动的盒子的矢量的 3 个维度
● 7 种尺寸,用于夹持器的抓取位置和方向
● 9 种尺寸的手臂关节和抓手手指

图 2:训练前的 FrankaCubeStack

图 3:训练后的 FrankaCubeStack
train.py 中的一些常见选项包括:
● 无头(默认值:假):设置为 True 时,不会启动查看器。这对于繁重的训练或捕获相机图像时非常有用,因为观看者可能会显着减慢该过程。
● 测试(默认值:False):设置为 True 时,学习模式将关闭,允许您无需训练即可运行环境。这对于生成环境和检查学习结果很有用。
● 检查点(默认:“):指定要加载的 PyTorch 权重文件。学习结果保存在 runs//nn/.pth 中,此选项用于恢复训练或测试。
● num_envs(默认:int):指定并行学习环境的数量。设置适当的数字以避免在测试期间出现大量查看器非常重要(此选项也可以在训练期间设置,但更改它可能会导致由于批量大小和干扰而导致错误)。
请注意,train.py 配置horizon_length和minibatch_size,但batch_size = horizon_length * num_actors * num_agents,并且batch_size必须能被minibatch_size整除。此外,num_actors 和num_agents与num_envs成正比,因此仅更改num_envs可能会导致错误。
其他样本可以在环境中轻松尝试,因此请尝试一些有趣的测试。
3.3 查看器提示
● 绘制碰撞网格
模拟器通常会渲染对象的视觉网格,但在 Isaac Gym 的查看器中,您可以更改它以渲染碰撞网格体。为此,请转到菜单窗口中的查看器选项卡,然后选中“渲染碰撞网格”。如果对象行为异常,最好检查碰撞网格是否正确加载(有时视觉网格和碰撞网格具有不同的方向,或者网格可能未正确加载或在模拟器中没有足够的细节)。
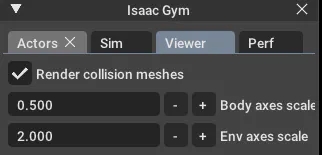
图 4:绘制碰撞网格
● 减少绘图环境
您可以将渲染环境减少到只有一个,而无需更改任何设置。通过在 Actor 菜单中选中“仅显示选定的环境”(如图 5 所示),将仅显示选定的环境。如果有任何奇怪的行为,可以通过输出环境编号并仅呈现该环境来进行调试。这也减轻了渲染负载,并可以提高 FPS。
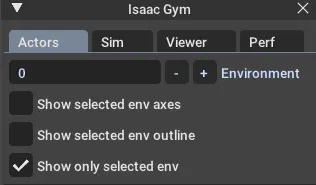
图 5:对绘图环境进行编号
● 更改初始相机位置
初始相机位置和方向可以使用 gymapi 的viewer_camera_look_at(查看器、middle_env、cam_pos、cam_target)进行设置。在用于训练的任务脚本中,需要重写 set_viewer 函数才能进行更改。
4. 原始环境和任务创建
终于到了为主要主题创建原始任务的时候了。
4.1. 准备
准备脚本和配置文件。目标是学习一个简单的任务,使用Mycobot进行物体拾取。因此,我们将继续创建一个名为“MycobotPicking”的任务。我们需要三个文件:
● 任务:主 Python 脚本
● cfg/task:环境和模拟参数的 YAML 配置文件
● cfg/train:用于学习算法、神经网络层和参数的 YAML 配置文件。
我们可以参考前面提到的“FrankaCubeStack”任务并相应地创建这些文件。配置文件特别重要,我们可以根据自己的要求复制和修改它们。
如演示所示,我们可以使用命令行选项从 train.py 文件加载任务脚本。因此,我们需要在 tasks 目录的 init.py 文件中为 task 类添加一个 import 语句,并在传递参数时添加任务名称。
4.2. 环境创建
任务类是通过继承任务/基目录中的 VecTask 类创建的,任务具有以下结构,如图 6 所示。
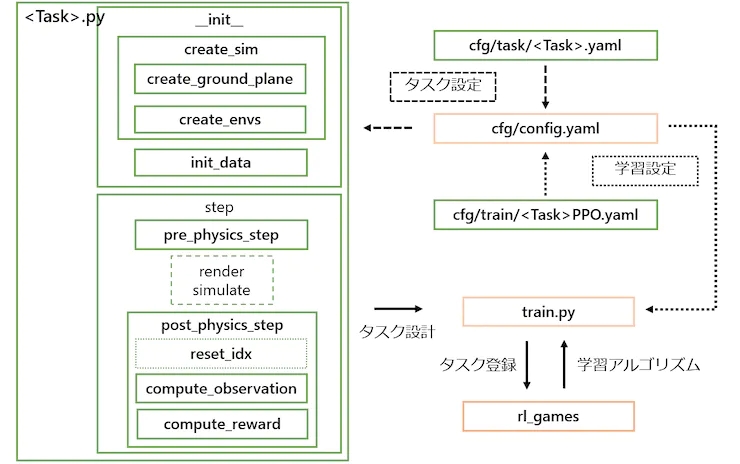
图 6:任务配置。带有橙色框的那些不需要编辑,并且为每个任务创建带有绿色框的那些。
4.2.1. __init__处理
1. 创建模拟器和环境
● create_sim:此函数生成模拟器的实例。过程本身在父类中定义,属性在配置文件中设置,例如重力和步长时间。与FrankaCubeStack类似,该函数使用以下两个函数来生成接地平面和执行组件。
● create_ground_plane:此功能通过输入平面的法线方向生成接地平面。如果要创建不平坦的地形,可以参考terrain_creation示例。
● create_envs:此函数加载并设置角色文件的属性,生成执行组件并并行化环境。在这个任务中,我们从URDF生成了myCobot,从create_box API生成了目标对象。myCobot 的 URDF 基于之前使用 MoveIt 实验中使用的 URDF,我们添加了一个用于拣选的抓手(有关抓手的详细信息在第 5.1 节中解释)。
2. 数据初始化
● init_data:此函数从配置文件定义环境变量,并为 Isaac Gym (PhysX) 处理的数据张量准备缓冲区。计算状态和奖励的必要数据定义为类变量。API 将张量数据加载到缓冲区中,缓冲区通过调用相应的刷新函数每一步更新一次。
4.2.2. 处理步骤
1. 分步处理:
主步骤函数在父类中定义,不需要修改。但是,以下两个步骤作为抽象方法是必需的:
● pre_physics_step:使用动作操纵演员。操作的大小在配置中定义为 [“env”][“numActions”]。对于myCobot的6轴臂和夹持器,我们将其设置为7维。
● post_physics_step:计算观察结果和奖励。还要检查是否重置环境。我们将其设置为在达到最大 500 步或成功提升后重置。
固定步序,应用物理模拟→→观察奖励计算的动作,传递数据进行学习。即使您在这里只写“pass”,也可以在启动查看器时检查环境。
● reset_idx:将环境返回到其初始状态。当然,初始状态的随机性与学习的泛化密切相关。我们将myCobot设置为初始姿势,并随机重置目标对象在myCobot可到达范围内的位置。
2. 状态和奖励计算:
● compute_observation:使用刷新功能更新每个缓冲区,并将所需的状态放入obs_buf。obs_buf的大小在配置中定义为 [“env”][“numObservation”]。
● compute_reward:计算奖励。当抓手接近目标物体的抓握位置(手指之间)时,获得奖励,并且随着目标物体高度的增加而获得更大的奖励。
4.3. 培训的执行
现在任务框架已创建,让我们训练模型。我们可以使用以下命令开始训练模型:
python train.py task=MycobotPicking --headless
200 个 epoch 后,将保存初始权重,如果奖励提高,将保存新的权重。但是,我们创建的任务可能无法完美运行,训练过程可能会停止快速进行。在下一节中,我将讨论我对任务所做的调整,以提高其性能。
4.4. 任务协调
通过使用学习的权重进行测试,您可以调试训练效果不佳的原因。您运行了命令
python train.py task=MycobotPicking test=True checkpoint=runs/MycobotPicking/nn/[checkpoint].pth
以测试模型。但是,您遇到了夹持器移动不佳的问题。尽管您努力解决问题,但您得出的结论是 URDF 不支持闭环结构,因此难以准确模拟夹持器的运动。因此,您决定使用基于规则的方法来控制夹持器的关闭和提升动作。您将夹持器的手指固定在固定链接上,并将操作空间从 7 个维度减少到 6 个维度。您还注意到,在使用模拟器控制机器人手臂时,最好使用没有闭环的抓手,例如熊猫手臂。
您面临的另一个问题是,代理在一定距离处停止接近物体并犹豫是否触摸它,从而导致奖励降低。您修改了奖励系统,方法是使用阈值距离作为阶跃函数增加奖励函数的值,从而在代理到达目标点时最大化奖励。您还删除了任务完成后的环境重置,因为它会导致代理在达到实际目标之前停止学习。相反,您将最大步骤数调整为任务完成所需的数量,从而提高了学习速度。
你还发现,过于严厉地惩罚困难的任务会使强化学习代理过于保守。这给了智能体更像人类的个性,使学习过程更加有趣。最后,您在 FrankaCabinet 基准测试任务中遇到了类似的现象,即代理在将抽屉拉到一定距离后会停止学习,即使完全拉出抽屉可以获得更高的奖励。您没有解决此问题,而是删除了任务完成后的环境重置,并调整了最大步骤数以顺利完成任务。

图 7:myCobot 远离物体
手臂的自相撞被忽略了。虽然我能够到达所需的位置,但手臂现在处于完全忽略自碰撞的位置,就像八字形一样。我试图研究是否可以在文档中设置自碰撞计算,但它效果不佳。首先,将提供的URDF中的所有关节角度限制都设置为-3.14~3.14是不现实的,因此我决定调整每个关节角度的上限和下限以避免自碰撞。关节角度移动到最大可能值的原因仍然未知。

图8:忽略事故碰撞的myCobot
手臂并没有完全停在它应该停的地方,而是在它周围摇摆。我们希望动作在到达目标位置时接近 0,但很难实现,并且手臂在目标位置周围不断振动。我们尝试通过精确设置目标位置来惩罚动作并调整奖励,但这并没有改善结果。我们决定不担心这个问题,因为它可以在实际操作中由基于规则的控制来处理。
虽然这不是必备品,但我们希望抓手朝下以获得更好的外观。因此,我们在奖励函数中添加了一个惩罚项,用于惩罚抓手角度。图 9 显示了微调之前的学习结果。

图 9:在微调之前学习后的 MyCobot
上述调整的结果如图 10 所示。如果可以在实际机器人上达到这种精度水平,它应该能够充分提升物体。

图 10:微调后训练后的 MyCobot
5. 其他
我将介绍不好的故事和我想尝试的故事。
5.1. 自制 URDF 抓手不起作用的故事
myCobot的URDF基于之前尝试移动实际机器人时使用的URDF,但它不包括夹持器。尽管在官方 GitHub 页面上有一个抓手模型,但它只提供了一个带有可视化表示的 DAE 文件,如图 11(a) 所示。要创建可在模拟器中使用的 URDF,需要为每个关节部件提供单独的 3D 模型。因此,使用Blender,我们按关节划分零件(图11(c)),并创建了简化的箱形碰撞零件,因为很难重现复杂的形状(图11(b))。然后,我们在 URDF 文件中描述了链接和关节的结构以完成模型。但是,由于URDF不支持具有开放式链接结构的模型,因此我们从底座上的一个链接中移除了碰撞,并用指尖侧完成了连接。虽然这种方法很粗糙,但我们能够通过以相同角度移动六个关节来重现模拟器中实际机器人的运动。图11(d)显示了完成的模型和实际机器人之间的比较(使用提供的模型,但细节完全不同)。但是,当我们实际尝试移动它时,如第 4.4 节所述,它的效果不佳。原因是在施加外力时无法协调地移动接头(如果正确实施扭矩控制,则可能已经解决)。
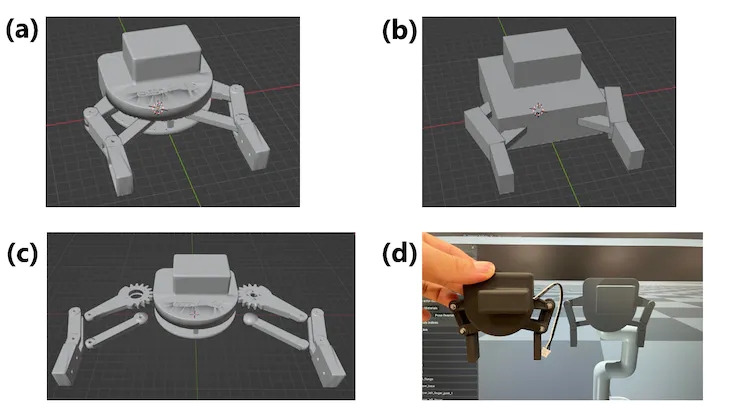
图 11:为 myCobot 创建夹持器 (a) 已发布的夹持器模型 (b) 根据模型创建的碰撞模型零件 (c) 从夹持器模型拆卸的视觉模型部件 (d) 艾萨克健身房 图纸和实际夹持器的比较
5.2. 使用图像识别
在基准测试和MycobotPicking任务中,我们在观察中使用对象位置和方向信息,但在实际任务中获取这些信息并不容易。因此,仅使用2D相机信息和易于获取的伺服关节角度信息进行强化学习将更有价值。
我们试图用图像替换观察结果,并在FrankaCubeStack任务中使用CNN层进行学习。但是,我们只修改了算法以接受图像输入,并且正如预期的那样,学习效果不佳。没有框架将伺服关节角度信息作为一维数据添加到CNN层,直接在CNN层中使用图像信息增加了计算复杂度,限制了环境的并行化。此外,我们需要调整超参数,如学习率和剪辑值,但我们没有追求这一点,因为效果不够有希望。
在这个测试中,我们只确认了添加CNN层进行学习的方法。但是,使用迁移学习对来自易于使用的对象识别模型(如 YOLO 或 ResNet)的抓手和对象识别的特征进行编码,然后使用编码的特征和关节角度进行强化学习,而不是直接将 CNN 层与相机图像一起使用,可能更有效。
5.3. 在实际机器人上使用训练模型
如上一篇文章所述,我尝试使用经过训练的模型以及myCobot和RealSense进行空间识别的Sim2Real实验。但是,它的效果并不好。虽然伸展运动在一定程度上起作用,但运动在接近物体时变得不稳定,并且无法准确地移动到抓住物体的位置。可能的问题包括myCobot没有足够的能力来准确移动到目标姿势,以及由于模拟器在到达当前目标姿势之前预测下一个目标姿势而实际机器人没有,因此积累了微小的差异。关于前者,本实验中使用的myCobot是一种廉价的教育手臂,便携式重量为250g,因此,如果您想更准确地移动,则应使用更高端的机器人手臂,例如用于强化学习的机器人手臂进行拾取。制造myCobot的公司Elephantrobotics也销售具有更强伺服电机的型号,可以承载高达1公斤的重量,所以我也想尝试一下。
6. 总结
这一次,我使用 Isaac Gym 创建了一个强化学习任务,并实际训练了模型。我在 3D 物理模拟器中体验了机器人强化学习问题的设计以及运行训练模型时出现的问题。能够测试学习环境而不必从头开始编写强化学习算法很有吸引力。基准环境的可用性使得比较和验证新的学习算法变得容易,这对于具有各种专业背景的研究人员和分析师来说是一个很大的优势。
ALBERT拥有具有各种专业背景的研究人员和分析师,他们随时准备协助任何技术或业务相关的查询。请随时与我们联系。
审核编辑黄宇
-
机器人
+关注
关注
213文章
30580浏览量
219534 -
NVIDIA
+关注
关注
14文章
5496浏览量
109081 -
大象机器人
+关注
关注
0文章
86浏览量
324
发布评论请先 登录
什么是深度强化学习?深度强化学习算法应用分析

NVIDIA Isaac Lab可用环境与强化学习脚本使用指南

深度学习技术的开发与应用
将深度学习和强化学习相结合的深度强化学习DRL
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

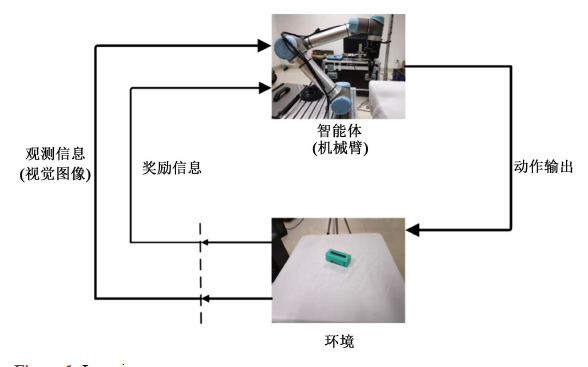
如何使用深度强化学习进行机械臂视觉抓取控制的优化方法概述
对NAS任务中强化学习的效率进行深入思考
强化学习在智能对话上的应用介绍
基于深度强化学习的视觉反馈机械臂抓取系统
NeurIPS 2023 | 扩散模型解决多任务强化学习问题






 工商网监
工商网监
评论