 语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务

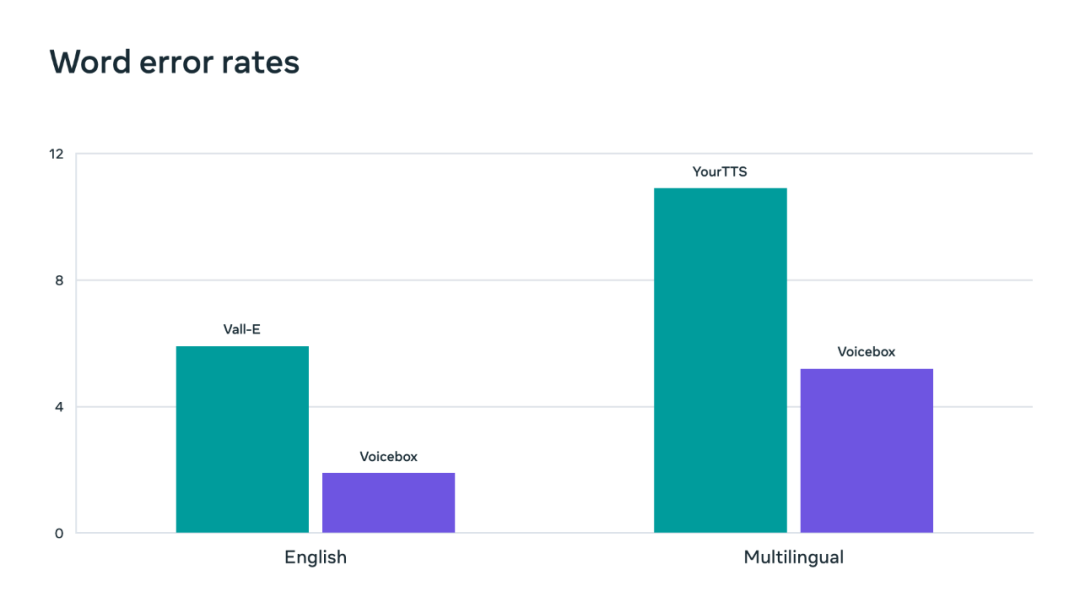
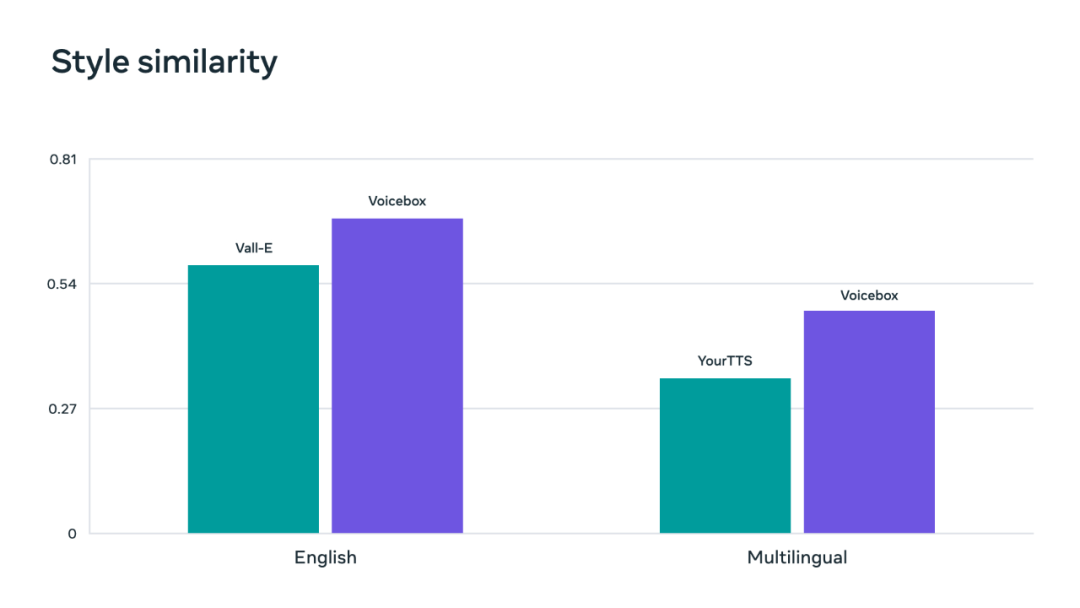
我们知道,GPT、DALL-E 等大规模生成模型彻底改变了自然语言处理和计算机视觉研究。这些模型可以生成高保真文本或图像,而且它们有个重要特点就是「通才」,可以解决没训过的任务。相比之下,语音生成模型在规模和任务泛化方面一直没有「突破性」成果。 今日,Meta 介绍了一种「突破性」的生成式语音系统,它可以合成六种语言的语音,执行噪声消除、内容编辑、转换音频风格等。Meta 称之为最通用的语音生成 AI。继开源 LLaMA 之后,Meta 在生成式 AI 方向又公布一项重大研究。

原文标题:语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2951文章
48348浏览量
420316
原文标题:语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
GPT-5震撼发布:AI领域的重大飞跃
跃升重新定义了人工智能的能力边界。OpenAI首席执行官山姆·奥特曼在发布会上直言:“这不仅是模型的升级,更是通往通用人工智能(AGI)的关键里程碑。” GPT-5:集成

《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
技术,需要开发者同时具备模态编码、跨模态对齐、系统优化等跨领域能力。从算法原理到项目落地,关键在于理解不同模态的互补性,并通过合理的融合策略释放多模态数据的协同价值。随着大模型与多模态
发表于 05-01 17:46

上海交大发布国产光学大模型Optics GPT
电子发烧友网综合报道 1月25日,上海交通大学正式推出光学领域垂直大语言模型——Optics GPT(光学大模型),这是一款完全自主研发的国

端侧大模型上车:从“语音助手”到“车内 AI 智能体”的跃迁革命
2025年,智能汽车的座舱不再只是“语音助手”的舞台,而是一个搭载生成式AI和大语言模型(LLM
今日看点:消息称已有模组企业调整原定产品规划;华为将发布 AI 领域突破性技术
华为将发布 AI 领域突破性技术 业内消息指出,华为将于 11 月 21 日发布一项 AI 领域
发表于 11-17 10:47
•1383次阅读
GPT-5.1发布 OpenAI开始拼情商
OpenAI正式上线了 GPT-5.1 Instant 以及 GPT-5.1 Thinking 模型;有网友实测发现OpenAI新发布的GPT
openDACS 2025 开源EDA与芯片赛项 赛题七:基于大模型的生成式原理图设计
智能生成。
4. 赛题内容
4.1赛题描述
本赛题要求参赛队伍构建合理规模的知识库,运用提示词工程,构建一个完整的生成式原理图设计
发表于 11-13 11:49
广州唯创电子WT588E02B-B2语音芯片:支持远程更换语音,引领汽车电子、医疗器械等多领域创新
推动着多个行业的智能化创新进程。突破性远程语音更换功能,重塑产品维护体验WT588E02B-B2语音芯片的最大亮点在于支持远程语音更换,彻底改变了传统

突破性创新:WTN6 F系列CMOS语音芯片IC重塑行业性价比标杆
在成本与性能的平衡中寻求突破,广州唯创电子WTN6F系列以宽电压工作与可重复烧写特性,开启语音芯片应用新纪元01核心技术突破:重新定义语音芯片价值标准1.1革命

摩尔线程发布大模型训练仿真工具SimuMax v1.0
近日,摩尔线程正式发布并开源大模型分布式训练仿真工具SimuMax 1.0版本。该版本在显存和性能仿真精度上实现突破性提升,同时引入多项关键

端到端语音交互数据 精准赋能语音大模型进阶
在语音大模型从“能识别”向“懂语境”跨越的关键阶段,高质量场景化语音数据已成为制约技术突破的核心瓶颈。传统语音识别数据集采用孤立标注,在
广和通发布自研端侧语音识别大模型FiboASR
7月,全球领先的无线通信模组及AI解决方案提供商广和通,发布其自主研发的语音识别大模型FiboASR。该模型专为端侧设备上面临的面对面实时对话及多人会议场景深度优化,在低延迟
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
1Whisper简介Whisper是OpenAI开源的,识别语音识别能力已达到人类水准自动语音识别系统。Whisper作为一个

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
Whisper是OpenAI开源的,识别语音识别能力已达到人类水准自动语音识别系统。Whisper作为一个



评论