 了解NeRF 神经辐射场
了解NeRF 神经辐射场

介绍
NeRF(Neural Radiance Fields)是一种先进的计算机图形学技术,能够生成高度逼真的3D场景。它通过深度学习的方法从2D图片中学习,并生成连续的3D场景模型。NeRF的工作原理是自监督的,通过在有限的输入视图上训练数据,可以用较少的数据集生成高质量的渲染。相比传统方法中使用离散化的网格或体素表示场景,NeRF的连续函数表示具有优势,并能够从任意角度渲染,产生令人惊叹的高质量渲染效果。
NeRF的引入在2020年由 Ben Mildenhall 等人的论文 "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis"中提出。这项研究是在加州大学伯克利分校与谷歌的联合项目中完成的。NeRF不仅可以从训练时使用的输入视图角度渲染场景,还能够从任意角度进行渲染,创造出优于现有渲染方法的高质量可视效果。
NeRF 提出的动机
NeRF的出现源于对传统的3D重建技术的局限性的观察。传统的3D重建技术,如立体重建和深度学习的3D卷积神经网络,主要依赖于离散的3D体素或点云表示来对3D空间进行建模。这些方法虽然取得了一些进展,但都存在着各种问题,比如模型精细度的限制、处理透明和半透明物体的困难等。
模型精细度的限制:对于基于体素或者点云的方法,它们的精细度往往受到计算能力和内存限制。对于体素,你需要在三维空间中创建一个网格并存储每个格子的信息。如果你想要增加模型的精细度,你需要增加网格的密度,这会使得所需的内存呈立方级增长。对于点云,虽然可以适应不同的形状和大小,但是精细的细节需要大量的点来表示,这也会导致计算和内存的需求增加。
处理透明和半透明物体的困难:传统的3D重建方法通常假设每个3D点都是完全不透明的,即它们完全吸收或反射所有到达的光线。这忽略了物体的透明度或半透明度,因此在处理玻璃、水或气体等物体时会导致错误的结果。
NeRF是为了解决现有3D重建方法的一些局限性而提出的。传统的3D重建方法通常需要在离散的3D体素或三角网格上操作,这可能导致模型的分辨率和细节程度受到限制。而NeRF的方法是在连续的3D空间中操作,这意味着它可以生成具有任意分辨率和任意细节的模型。
此外,NeRF的方法还可以自然地处理场景中的透明度和混合色,这是许多传统方法难以处理的问题。另外,由于NeRF使用的是神经网络,所以它可以利用深度学习的强大能力,从一系列2D图像中学习出复杂的3D场景。
具体来说:
对于模型精细度的限制:NeRF通过将场景建模为连续的辐射场并使用神经网络进行参数化,避免了离散表示带来的精细度限制。神经网络能够学习到连续的函数,所以可以以任意精度渲染场景。此外,所有的信息都嵌入到神经网络的权重中,所以内存使用量主要取决于网络的大小,而不是场景的复杂度或分辨率。
对于处理透明和半透明物体的困难:NeRF通过为每个3D位置分配一个密度值来解决这个问题。这个密度值描述了光线通过该位置时的衰减程度,所以可以自然地表示透明和半透明效果。在体积渲染过程中,NeRF会考虑到每个3D位置上的密度值,并计算光线在通过场景时的累积影响,从而能够准确地渲染透明和半透明物体。
总的来说,NeRF通过使用神经网络和体积渲染的方法,克服了传统3D重建方法的一些主要限制,从而能够以高精度和高细节级别重建和渲染3D场景。

什么是3D辐射场(Radiance Field)?
在深入地理解3D辐射场之前,首先需要理解“辐射”和“辐射场”的概念。
“辐射”
在光学中,“辐射”一词通常用于描述光(或更一般地,电磁波)的传播。具体来说,给定空间中的一个点和一个方向,"辐射"描述的是从这个点沿这个方向传播的光的强度或能量。在许多情况下,我们更关心的是“光度”,即人眼对光的感知,这包括光的颜色和亮度。
“辐射场”
“辐射场”则是一个更高级别的概念。一个辐射场实际上是一个定义在空间中的函数,它给出了在每一个空间点、每一个方向上的辐射(或光度)。这就是3D辐射场的定义。
举个例子,假设你在一个室内环境中,有一个亮度和颜色都在变化的灯光源。你现在想要用一个函数来描述整个空间中的光度情况。这个函数应该能告诉你在每个位置,从每个方向看过去的光的颜色和亮度是什么。这个函数就是3D辐射场。
具体到计算机图形学和计算机视觉中,3D辐射场被用来表示和渲染3D场景。
它能够准确地描述场景中的光照、阴影、反射和折射等复杂光学现象。
通过对3D辐射场的采样和计算,我们可以从任意视角渲染出场景的图像,甚至可以模拟出透明和半透明物体,以及复杂的光线传播效果,如散射和吸收等。
例如,虚拟现实(VR)和增强现实(AR)就是3D辐射场的一种应用。在VR和AR中,我们需要根据用户的视角动态地渲染3D场景。通过3D辐射场,我们可以快速地从任意视角计算出场景的图像,从而实现实时的、自由的视角切换。
另一个例子是电影制作。在电影中,通常需要创建一些复杂的3D场景,并从不同视角进行渲染。通过使用3D辐射场,我们可以创建出高质量的、具有真实光线传播效果的3D场景,使得电影的视觉效果更加逼真。
3D辐射场描述了 3D空间中光的分布和行为的方式。具体来说,它为3D空间中的每一个点分配了一个颜色和一个透明度(或者说体密度)值。颜色描述了从该点射出的光的颜色,而透明度描述了光线穿过该点时被吸收或散射的程度。
颜色: 对于空间中的一个点p和一个方向 d ,颜色描述了从点p沿着方向d射出的光的颜色。这个颜色是由在点 p 处的所有光源(包括直接的和间接的)在方向d上的光线的颜色组成的。
例如,如果在p处有一个红色的光源,那么 将会包含红色的成分。如果在p处没有光源,但是在d方向上有一个反射面,那么 将会包含反射面反射过来的光的颜色。
体密度(透明度): 体密度 σ(p) 描述了在点p处光线的吸收或散射的程度。
如果 σ(p) 较高,那么在点p处的光线将会被大量吸收或散射,这意味着在p处的物体是不透明的或者是高度散射的(例如雾或云)。
如果 σ(p) 较低,那么在点p处的光线将会被较少吸收或散射,这意味着在p处的物体是透明的或者是低度散射的(例如清晰的空气或水)。
3D辐射场是一个函数 ,其输入是一个3D坐标 p 和一个方向 d ,输出是在那个坐标和方向上的颜色和体密度,即 c(p, d) 和 σ(p) 。这个函数描述了3D空间中的光的分布和行为:它告诉我们在空间中的任意一个点,沿着任意一个方向,我们可以看到什么颜色的光,以及这个光线被吸收或散射的程度。
输入:函数的输入由两部分组成:一个3D空间中的点和一个方向。
这里的3D空间可以是任何你希望描述其光照属性的空间,例如一个室内环境、一个城市街道,或者整个宇宙。方向可以是任何方向,你可以想象这是一个从观察者眼睛发出的光线的方向。
因此,这个函数实际上是在描述:在3D空间中的任何点,沿着任何方向,我们能看到什么。
输出:函数的输出是在输入点和方向上的颜色和体密度值。
颜色值描述了你在指定的点和方向上看到的光的颜色。
体密度值描述了光线穿过指定点时的吸收或散射程度。
更具体地说,如果你在一个3D场景中选择一个点p和一个方向d,那么函数L(p, d)将会告诉你:如果你站在点p,朝着方向d看过去,你将会看到什么颜色的光(c(p, d)),以及这个光线被穿过的物体吸收或散射的程度(σ(p))。
这种描述方法使得3D辐射场可以对3D空间中的光照情况进行高度精细的描述,包括复杂的光线传播效果,如阴影、反射、折射、透明和半透明效果等。这也是为什么3D辐射场在计算机图形学和计算机视觉中如此重要,因为它可以用于渲染高质量、逼真的3D场景。

NeRF 和 3D辐射场之间的关系
NeRF(Neural Radiance Fields)和3D辐射场是紧密关联的,实际上,NeRF就是利用深度神经网络来建模和学习3D辐射场。
NeRF提出的方法是以神经网络来模拟连续的3D辐射场,即将一个3D坐标点和一个视线方向映射到一个颜色和密度。
这种表示方式对应于真实世界的物理特性,使得3D模型可以自然地表达物体的颜色和透明度,也使得3D模型可以以任意的精度和分辨率来表示。
根据前面的描述可知,3D辐射场是一个描述3D空间中光的分布和行为的函数,它将每个3D空间中的点和一个方向映射到一个颜色和体密度值。然而,在实际应用中,我们通常并不能直接得到这个函数,因此我们需要找到一种方法来逼近或学习这个函数。这就是NeRF的任务。
NeRF提出了一种基于深度神经网络的方法,该网络接受一个3D空间中的点和一个方向作为输入,输出该点和方向上的颜色和体密度值。通过在一组2D图片上训练,NeRF能够学习到这个深度神经网络的参数,从而学习到3D辐射场的近似表示。
NeRF的目标是通过一组2D图片重建3D场景。
它不是直接在像素或三维体素上进行操作,而是在连续的三维空间中学习和推断一个函数,这个函数可以用来描述空间中的场景。
NeRF建立了一个完全由神经网络表示的3D场景模型,这个模型旨在描述一个场景中所有3D位置(由世界坐标表示)以及从任何观察角度看到的颜色。
具体来说,NeRF训练的过程是这样的:它将一组2D图片(通常是同一个3D场景的不同视角的图片)作为输入,然后通过优化算法调整网络的参数,使得网络输出的3D辐射场能够最好地重现这组2D图片。训练结束后,我们就得到了一个能够描述3D场景的深度神经网络,这个网络实际上就是3D辐射场的近似表示。
因此,可以说NeRF是一种用深度神经网络来学习和建模3D辐射场的方法。这种方法有许多优点,例如它能够生成连续、全景的3D场景模型,可以自然地表达物体的颜色和透明度,可以以任意的精度和分辨率来表示3D模型,等等。这使得NeRF在3D重建和视图合成等任务上具有非常高的性能。
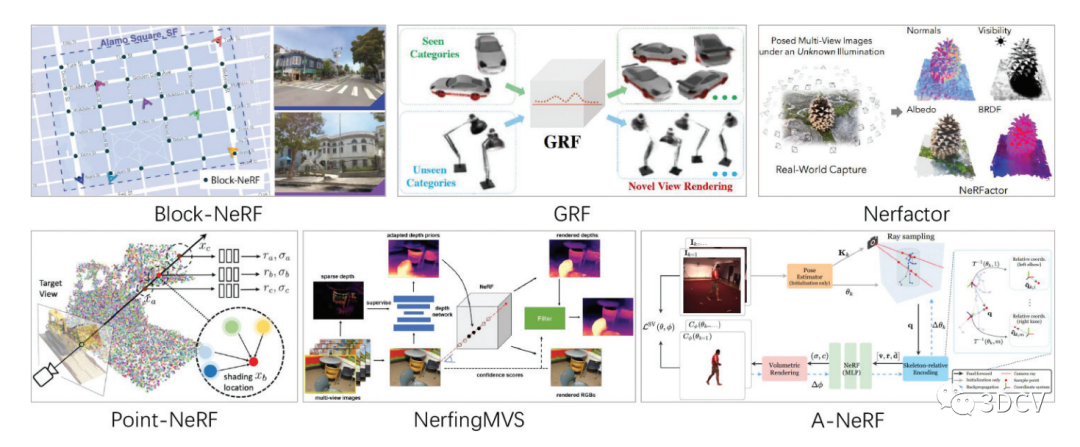
NeRF的核心思想
NeRF(Neural Radiance Fields)的核心思想是使用深度神经网络来学习3D空间中任意一点在给定视线(由观察点和方向定义)下的颜色和体密度。主要依赖于神经网络来建模和学习3D空间中的辐射场,而这个神经网络的学习过程是通过观察一系列2D训练图片来完成的。
NeRF的核心思想可以用以下几点来表述:
建模3D辐射场:NeRF使用深度神经网络来建模3D空间中的辐射场。
这个神经网络接受3D空间中的坐标点和一个方向作为输入,输出对应点和方向的颜色和体密度。在物理上,颜色代表从这个3D坐标点沿着指定方向射出的光的颜色,而体密度则表示光线在穿过这个点时被吸收或散射的程度。
连续的3D场景表示:NeRF的一个关键特点是它对3D场景的表示是连续的,而不是离散的。
这是通过使用全连接的神经网络来实现的,这种网络可以接受任意的实数输入,并输出相应的颜色和体密度。因此,NeRF可以以任意的精度和分辨率来表示3D模型。
视角无关性:NeRF对3D场景的表示是视角无关的。
这是因为它是在3D空间中建模的,而不是在2D图像空间中。这意味着,一旦NeRF模型被训练好,就可以从任何角度对其进行渲染,而不需要重新训练模型。
通过2D图像训练:NeRF通过观察一系列2D训练图片来学习这个深度神经网络的参数。
具体来说,它会将一组2D图片(通常是同一个3D场景的不同视角的图片)作为输入,然后通过优化算法调整网络的参数,使得网络输出的3D辐射场能够最好地重现这组2D图片。
处理透明和半透明物体:NeRF的另一个重要特点是它能够处理透明和半透明物体。
这是通过预测每个3D坐标点的体密度来实现的,体密度可以表示光线在穿过这个点时被吸收或散射的程度。
总的来说,NeRF的核心思想是通过深度学习来学习和预测3D空间中任意一点在给定视线下的颜色和体密度,从而从一系列2D训练图片中生成连续、详细、全景的3D场景表示。这一过程中涉及到对3D辐射场的建模、连续的3D场景表示、视角无关性以及透明度处理等多个关键环节。
全连接神经网络作为场景的连续3D表示:这是NeRF的一项创新,通过神经网络建立了3D坐标点及观察方向与光线密度和颜色之间的映射关系。
这种表示形式可以更好地处理细节,并且在新的视角下更加准确,因为它允许任意的视角插值,而无需再进行训练。
体积渲染公式:NeRF使用体积渲染公式对沿视线路径上的颜色和密度进行积分,以生成最终的2D图像。这考虑了物体透明度的影响,并且可以通过改变路径上的积分步数来适应不同的场景。
分解颜色和体密度的表示:NeRF的另一个关键思想是将颜色和体密度的表示进行分解,颜色与观察方向有关,体密度与观察方向无关。
这允许NeRF可以在视线方向上处理复杂的光线效果,例如高光和反射。
优化和训练:NeRF优化的目标是减小由神经网络生成的图像和训练集图像之间的差异。训练数据是一组同一场景的2D图像,每张图像都有相应的相机参数(包括位置和方向)。这些数据足以训练网络预测3D辐射场,并能够从任意新的视角渲染出场景图像。
NeRF(Neural Radiance Fields)的训练过程通常被认为是自监督学习,因为它使用的监督信号是输入数据自身,而不是外部提供的标签。
具体来说,NeRF的训练过程使用了一组2D图像和相应的相机参数(包括位置和方向)。神经网络的目标是预测能够产生训练图像的3D场景的辐射场。这种情况下,监督信号(即目标输出)就是输入的2D图像自身,因此可以认为这是一种自监督学习。
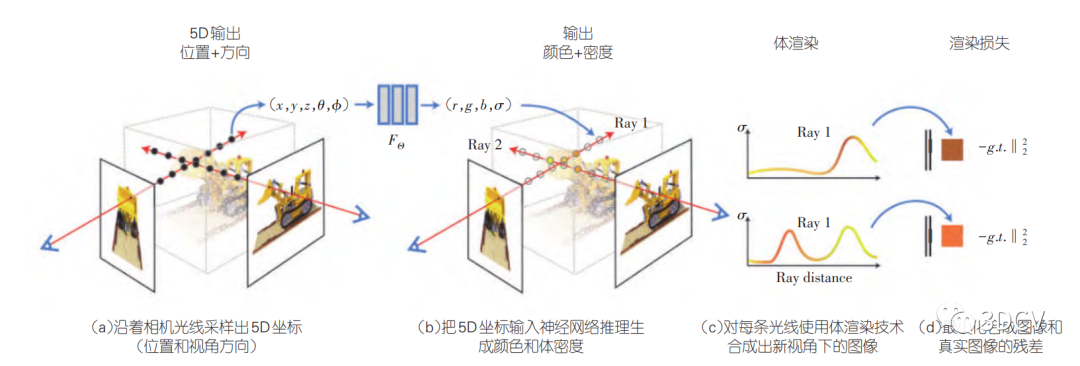
NeRF的实现技术
根据前面的介绍可知,NeRF的主要目标是从一组2D图片中学习出3D场景的连续表示。而这个表示方式被称为3D辐射场,它用一个函数来描述3D空间中光的行为。给定一个3D点和一个视线方向,这个函数可以输出那个3D点在那个视线方向上的颜色以及光线被吸收或者散射的程度。
那么NeRF是如何做到这一点的呢?它采用了深度学习的方法。具体来说,NeRF训练一个深度神经网络,使得这个神经网络能够学习和近似上述的3D辐射场函数。神经网络的输入是一个3D坐标和一个视线方向,输出是那个3D点在那个视线方向上的颜色和体密度。
为了训练这个神经网络,先收集一系列从不同角度和位置拍摄的2D图像,然后用这些图像来训练网络。
通过优化神经网络,使得从训练图像中的每一个像素向场景中射出的光线的颜色和真实图像尽可能一致,神经网络就可以学习到场景的3D表示。
整个NeRF的流程是这样:它通过深度学习的方法学习3D场景的连续表示,然后使用这个表示来从新的视角渲染场景图像。这是一个从2D到3D,再到2D的过程,但是这个过程中获得的是对3D场景的连续和详细的描述,这对于3D场景的重建和渲染都是非常有用的。这个过程可以进一步分解如下:
数据收集:收集一组2D图像,这些图像从不同的角度和位置捕获了同一场景。
这些图片都是对同一3D场景的拍摄,所以在这个场景中,每个物体都会在多个图像中出现,只是视角和位置不同。
预处理:对于每张图像,我们需要知道相机的参数,包括相机的位置和方向。
这些参数可以用来确定从相机位置出发,经过图像上每个像素,向场景中射出的视线的方向。
神经网络训练:我们使用这些数据训练一个深度神经网络。这个网络的目标是能够根据3D坐标和视线方向预测出那个位置的颜色和体密度。
在训练过程中,使网络预测的颜色值和真实的2D图像尽可能一致,神经网络就能学习到场景的3D表示。而为了实现这个目标,我们通过比较网络预测的颜色和图像中的真实颜色来计算误差,然后通过反向传播算法来更新网络的参数。
神经网络的输入是每个3D位置和相应的视线方向,输出是预测的颜色和密度值。
颜色值代表了该3D位置的颜色。
密度值代表了从相机向该3D位置射出的光线在途中被吸收或散射的程度。
渲染:当神经网络训练完毕后,我们就得到了一个可以描述3D场景的模型。我们可以使用训练好的神经网络从任意新的视角渲染场景图像。
给定一个新的视角,我们可以通过这个模型来渲染出新的场景图像。
我们只需要对每个像素确定出一个视线,然后使用神经网络预测沿着这个视线的所有3D点的颜色,最后把这些颜色组合起来,就可以得到新的图像。
体积渲染 (volume rendering)
为了从这个网络生成2D图像,NeRF使用了一种称为体积渲染 (volume rendering) 的技术。这是一种处理半透明物体的技术,它将光线沿视线路径的所有颜色贡献加权求和来生成最终的像素颜色。
简单来说,体积渲染是通过将沿着每个像素的射线上的所有颜色值加权求和(其中权重由密度值决定)来生成图像的。
这个过程可以很自然地处理透明度和混合色,从而生成真实的图像。
这个过程基本上就是沿着每个像素的射线方向,积分所有3D点的颜色和密度。
体积渲染 (volume rendering) 技术是一个关键步骤,因为它允许我们通过从每个像素的射线上积分所有颜色和密度来创建2D图像。
体积渲染过程首先确定出射线路径(从相机位置通过每个像素),然后在这些射线上采样一系列3D点,并通过神经网络获取这些点的颜色和密度值。
然后,将这些颜色值根据相应的密度值进行加权叠加,从而得到最终的像素颜色。这个过程可以很好地处理颜色混合和透明物体。
这个过程充分考虑了光线在物体间传播的物理规则,因此,通过NeRF生成的图像不仅可以高度逼真,而且可以从任何新的视角渲染出来。
这种技术的潜力非常大,因为它不仅可以用于3D渲染和虚拟现实,也可以用于计算机视觉和机器学习等其他领域。
体积渲染是一种处理3D数据的技术,它可以生成从任意视角观察3D场景的2D图像。这种技术在许多领域都有应用,比如医疗成像(例如CT扫描和MRI扫描)、科学可视化(例如气候模型和电子云模型),以及电影和电视特效制作等。
在体积渲染中,每个3D数据点通常有一个或多个属性,比如颜色、透明度、密度或其他的物理性质。渲染的目标是将这些3D数据点转化为2D图像上的像素,同时考虑视点、光线传播和物体间的相互作用。
NeRF(神经辐射场)中的体积渲染方法是一种特殊的体积渲染方法。在这种方法中,3D空间中的每一个点都由神经网络预测的一个颜色值和一个体密度值描述。然后,沿着每个像素的射线,积分所有3D点的颜色和体密度,从而生成2D图像。
具体来说,对于每个像素,首先确定一个射线,然后在射线上采样一系列3D点,对这些点的颜色值进行加权求和,权重由体密度决定,从而得到最终的像素颜色。
需要通过体积渲染来计算像素的颜色。体积渲染的公式可以表示为:
其中:
是渲染出的颜色;
表示的是从相机位置到3D空间点s之间的媒介透射率。
T(s) 是从视点到3D点的透明度函数,可以理解为从相机到当前3D点之间所有点的体密度的指数积;
透射率衡量了光线在通过物质后保持其强度的能力。
在这个公式中,透射率等于路径上所有点的体密度的负指数积分,这意味着密度越大,透射率越小,更多的光线会被吸收。
是3D空间点s的体密度。
是在3D空间点s处视线方向的颜色。
上面的公式是体积渲染的核心公式,它说明了生成每个像素的颜色是如何由沿射线方向的一系列3D点的颜色和体密度决定的。
位置编码和方向编码
为了帮助神经网络捕获微妙的几何细节以及复杂的光线传输现象,如反射和透射,NeRF引入了对3D空间位置和观察方向的编码。位置编码和方向编码是一种强制神经网络学习场景中几何和光线传播细节的方法。
这是NeRF中用于处理3D空间位置和观察方向的技术。它使用正弦和余弦函数对输入的坐标和方向进行编码,从而更好地处理几何细节和光线传播。
在训练网络时,3D位置和观察方向首先会被编码为更高维的向量,然后才输入到神经网络中。
这种编码使用的是一个简单的正弦和余弦函数的系列,这种编码方式可以使得神经网络能够更好地捕捉到细微的空间和方向变化。
通过对输入的3D坐标和视线方向进行一系列正弦和余弦函数变换,生成的多尺度频率编码可以帮助神经网络更好地建模场景的复杂细节。
它的目的是以更高的频率捕获物体的几何细节和光线传播。基于位置和方向的原始坐标和编码坐标,神经网络可以学习到不同的几何和光学特性。
NeRF 利用傅里叶级数来编码输入位置和视线方向。
傅里叶级数是一种分析数学工具,可以将任何周期性函数表示为正弦和余弦的和。
通过对空间和方向进行傅里叶编码,NeRF 增加了神经网络对几何和光照变化的感知能力。
具体来说,对于一个给定的 3D 点位置 和方向 ,它们都可以被分解为其对应的频域表示。这个频域表示就是嵌入向量。嵌入向量包含了原始的点和方向,以及一系列正弦和余弦函数对它们进行编码后的结果。
位置 和方向 转换为嵌入向量 和 ,其位置编码和方向编码公式如下:
其中,决定了编码的频率,这是一个可以调整的超参数,它控制了正弦和余弦函数的频率的上限。一般来说,较大的 会让神经网络学习到更丰富的几何和光照细节,但也会增加计算复杂度。
嵌入向量中的正弦和余弦项给神经网络提供了处理周期性和反射性质的能力,这对于描述复杂的几何形状和光线传播特别重要。
例如,对于一个周期性的纹理,如果只使用原始的点和方向作为输入,神经网络可能很难学习到这个周期性。但如果使用了傅立叶编码,神经网络就可以通过调节对应频率的权重来表示这个周期性。
这种编码方式的灵感来源于傅立叶变换和傅立叶级数的性质,它们能够将任何函数表示为一系列正弦和余弦函数的和。通过将这种性质应用到神经渲染中,NeRF 可以生成更真实的图像,并且对于几何和光照的处理也更加精确。
分层采样策略 (Hierarchical Sampling Strategy)
在渲染过程中,光线会穿过许多不同的体素(体积元素),一条射线可能穿过多个物体或者穿过一个物体的多个部分,每个部分都会对最终像素颜色产生贡献。
由于体积渲染涉及对光线路径上的所有体素进行积分,因此需要对这些体素进行采样。
然而,不是所有的体素对于生成最终的图像都相同重要。
有些体素可能包含了大量的细节信息,比如对象的边缘或是纹理的详细部分,而其他的体素可能只包含了空气或是非常平滑的表面。
对于这后者,我们并不需要进行很密集的采样。
为了解决这个问题,为了有效地利用采样点,NeRF使用了一种分层采样策略来更高效地进行体积渲染。这是一种用于体积渲染的技术,用于优化渲染效率。
NeRF利用分层采样策略对预测的体密度较高的区域进行更密集、更精细的采样采样。在这种策略中,首先在整个射线上均匀地采样一些点,然后在预测的体密度高的区域再进行更细致的采样。
首先进行均匀的粗采样 (coarse sampling) ,获取预测的体密度分布。根据这些粗采样点的密度预测结果,根据这个分布,再在预测的体密度高的区域进行更细粒度的采样 (fine sampling)。
这样可以更有效地使用采样点,更准确地估计每个像素的颜色值。
这种策略可以使得采样过程更加集中在重要的区域,可以将计算资源更有效地分配到图像的重要部分,可以更有效地利用采样点,从而提高渲染效率,并提高渲染质量。
分层采样策略的优点是它可以显著提高渲染的效率和质量。因为它将计算资源集中在了那些对生成图像质量最重要的区域,所以它可以在有限的计算资源下生成更高质量的图像。
这种策略的灵感来源于计算机图形学中的重要性采样技术 (importance sampling)。
重要性采样是一种选择性地对那些对结果有重大影响的部分进行采样的方法。
通过将这种方法应用到体积渲染中,NeRF能够更高效地渲染复杂的3D场景。
光线投射(Ray Casting)
这是一种在3D场景中生成2D图像的技术,它将每个像素看作从相机位置出发的一条光线,并使用神经网络预测沿着光线路径的颜色和体密度。
NeRF使用光线投射来确定每个像素的射线方向。给定相机位置和像素位置,可以计算出射线的起点和方向。
然后,NeRF在射线上采样一系列3D点,并通过神经网络预测这些点的颜色和体密度。
具体来说,将每个像素视为从相机位置出发的一条光线,每个像素都有一条从相机位置出发、通过像素中心、指向场景的射线。然后沿这条光线采样多个3D点,输入神经网络得到颜色和体密度,最后使用体积渲染技术得到最终的像素颜色。这个过程可以形式化为一个积分问题,公式如下:
其中 是射线 的颜色, 是到 3D 点的透射度, 是 3D 点的体密度, 是 3D 点的颜色。
差分渲染(Differential Rendering)
由于NeRF的目标是使生成的图像尽可能接近真实的2D图像,这需要计算图像的梯度并进行反向传播。然而,由于体积渲染是通过积分操作得到像素颜色,直接计算梯度是非常困难的。
差分渲染是指对渲染结果进行微分,得到结果关于输入参数的梯度。这对于神经网络的训练非常重要,因为梯度信息可以用来优化神经网络的参数。
差分渲染是一种重要的计算机图形学技术,允许我们计算图像关于其输入参数(例如光源位置、物体表面材质等)的梯度。
差分渲染在NeRF中的实现,主要涉及对体积渲染公式的微分。NeRF利用差分渲染技术,这使得神经网络生成的图像可以进行反向传播,从而优化网络参数。具体来说,NeRF通过对体积渲染的公式进行微分,得到每个像素颜色关于神经网络参数的梯度,实现了光线的颜色和神经网络参数之间的导数计算。
这样,就可以通过梯度下降算法来优化神经网络,使得生成的图像尽可能接近训练数据中的真实图像。由于神经网络和体积渲染过程都是可微的,NeRF可以计算生成图像与真实图像之间的误差关于神经网络参数的梯度。
我们可以简单地看这个问题为最小化损失函数的问题,其中损失函数定义为生成图像与真实图像之间的误差。如果我们把神经网络的参数表示为,那么我们的目标就是找到一组参数,使得损失函数L最小。为了实现这一目标,我们需要计算损失函数关于参数的梯度,然后通过梯度下降算法来更新参数。
在具体的计算过程中,我们首先需要计算每个像素的颜色c关于体积密度σ和颜色c的导数,然后通过链式法则,可以计算出损失函数L关于网络参数θ的梯度。然后,我们可以使用这些梯度来更新网络参数。这种差分渲染技术使得NeRF可以利用已有的深度学习框架进行训练(如TensorFlow或PyTorch的自动微分功能),同时也使得NeRF可以从少量的2D图像中学习出3D场景的连续表示。
假设神经网络的参数为,光线在处的颜色可以通过下面的公式进行计算:
其中,是光线在处之前的传输函数,是处的体积密度,是处的颜色。
那么,我们的目标就是最小化生成的图像和真实图像之间的差异,也就是最小化损失函数。
然后,我们可以通过计算损失函数关于参数的梯度来更新参数,即,其中,是学习率。
通过这种方法,NeRF可以逐步改进神经网络的性能,使生成的图像越来越接近真实的图像。这种技术的灵感来源于深度学习中的反向传播算法,是一种将神经网络应用于计算机图形学的有效方法。
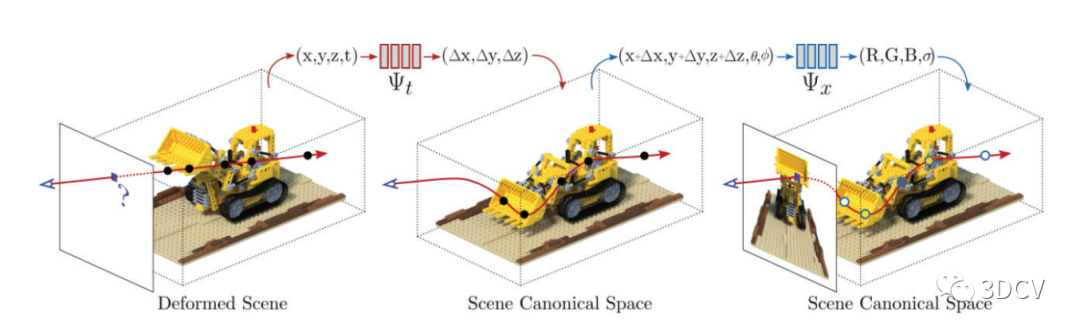
NeRF的基本原理
NeRF的核心概念是用一个深度神经网络来表示一个场景的3D辐射场(radiance field)。这个辐射场可以被理解为一个函数,其输入是一个3D位置和一个视线方向,输出是在该位置和方向下的颜色和密度
NeRF的基本原理其实是建立在经典的体积渲染理论之上,而NeRF的主要创新点在于将一个深度神经网络用于预测3D空间中的颜色和密度信息。
NeRF模型中的主要函数可以表示为:
这里,是一个深度神经网络,它接收一个3D空间点和一个视线方向作为输入,并输出该点的颜色和体密度。
在NeRF的框架中,神经网络是用来学习和表示场景的3D颜色和密度信息的工具。它的输入是一个3D坐标和一个方向,输出是在该坐标处的颜色和体密度。这种表示方式允许网络对3D空间中的每个点进行细粒度的建模,同时保持了对视角的感知,因为颜色输出是依赖于方向的。
函数实际上是神经网络对场景的表示。这里的是神经网络的参数,可以通过训练学习得到。
具体来说,训练过程是这样的:
给定一系列2D图像和对应的摄像机参数(包括摄像机位置和视角等),首先将摄像机参数转换为3D空间中的射线。
对于每一条射线,通过一定的方法(如均匀采样或重要性采样)选取一些点,然后计算出这些点到摄像机的方向。将这些点的坐标和方向作为输入,送入神经网络,得到每个点的颜色和体密度。
在训练过程中,给定一系列2D图像和对应的摄像机参数,我们可以将每个2D图像上的像素想象成从相机位置出发的一条射线。为了预测这条射线的颜色,我们需要在3D空间中沿着这条射线采样多个点。
例如,我们可以选择沿着射线等间距地采样10个点,然后将这10个点的3D坐标和对应的视线方向作为输入,输入到神经网络中,得到这10个点的颜色和体密度。值得注意的是,射线的方向是一个重要的输入,因为在许多场景中,物体的颜色会随着观察的角度变化,这被称为视差效应。
然后,使用上面的体积渲染公式,从这些颜色和体密度计算出射线的颜色。
得到颜色和体密度之后,就可以利用体积渲染公式来计算出射线的颜色。这个公式基本上是将沿射线的所有点的颜色进行加权叠加,其中权重是通过体密度来计算的。具体来说,一个点的体密度越高,它对最终颜色的贡献就越大。
最后,将计算出的射线颜色与2D图像上对应的像素颜色进行比较,计算出误差,通过梯度下降等优化算法来更新神经网络的参数,使得预测的颜色尽可能接近真实的颜色。
将计算出的射线颜色与2D图像上对应的像素颜色进行比较,计算出误差。这个误差可以看作是神经网络预测的颜色与真实颜色之间的差距。通过反向传播这个误差,我们可以计算出神经网络参数的梯度,并使用优化算法(如梯度下降)来更新参数,使得预测的颜色更接近真实的颜色。
通过大量的2D图像和对应的摄像机参数进行训练,神经网络可以逐渐学会如何根据3D位置和视线方向来预测颜色和体密度,实现了从2D图像到3D场景的学习和重建,从而形成对3D场景的理解。
这种方法的好处是,它不需要对场景进行显式的3D建模,而是通过一个可微的神经网络隐式地学习场景的3D表示,这使得它能够处理非常复杂和详细的场景。同时,由于其基于射线的渲染方式,它也能自然地处理复杂的光线效应,如阴影、反射和折射等。
NeRF的整体流程
NeRF方法使得它可以从一系列2D图片中学习并生成一个连续、全景的3D场景模型,能够处理透明度和复杂的光照条件,而且可以以任意的精度和细节级别来表示。这使得NeRF在3D重建和视图合成的领域具有广泛的潜力和应用前景。
数据收集:NeRF使用一系列从不同角度和位置拍摄的2D图片作为输入。这些图片可以是实际拍摄的,也可以是通过计算机图形学生成的。
首先,收集一系列在不同角度和视点下拍摄的2D图像作为输入数据。这些图像应尽可能包含足够的视角覆盖,以覆盖整个3D场景。
神经网络训练:NeRF使用一个深度神经网络来表示3D辐射场(radiance field)。这个网络接收一个3D坐标和一个方向作为输入,输出该坐标处的颜色和体密度。这个网络是通过最小化模型预测的颜色和实际图像的颜色之间的误差来训练的。
在NeRF中,通常使用一个全连接的多层感知机(MLP)神经网络来表达3D空间中的颜色和密度。给定一个3D坐标和一个方向,神经网络会输出在坐标处的颜色和体密度。具体的函数表示如下:
其中代表神经网络,是神经网络的参数。这个网络通过最小化预测的颜色和实际图像的颜色之间的误差来进行训练。
体积渲染:训练好神经网络之后,NeRF会通过体积渲染的技术,从神经辐射场生成2D图像。具体来说,它计算沿每个像素射线方向的颜色和体密度的加权和,生成最终的2D图像。
对于给定的一条射线,我们需要计算出这条射线上每一点对于最后形成的像素颜色的贡献。其颜色计算公式如下:
这个公式表示沿射线的颜色的积分,其中每个位置的颜色被其体密度和沿射线的可见性所加权。
在这个公式中:
这个公式的基本思想是,我们沿着射线方向,对射线上每一点的颜色按照其体密度和透射函数进行加权,然后累积这些颜色,得到的就是射线最终的颜色。这个过程相当于模拟了真实世界中光线穿过物体并被物体颜色影响的过程。
而其中, 表示光线穿过点之前的所有点的累积透明度,计算公式为:
这个公式的意思是,光线在到达某一点时,其颜色已经因为途径点的体积密度而衰减,所以需要一个衰减因子来表示这种衰减。
在这个公式中,是在点的体密度,计算的是从摄像机(在处)到的光线路径中所有点的体密度之和。这个和被认为是光线在到达前被吸收的程度,其负指数就是光线在到达前剩余的光线强度,也就是。
这里,被称为透射函数(transmittance function),代表了从摄像机出发,到达空间中点时,光线的衰减程度。光线在经过某一点前,如果途径的介质(例如空气、水、玻璃、烟雾等)密度较大或者路径较长,那么光线就会发生更大的衰减。
因此,如果路径上的总体密度大(表示有很多物质可以吸收或散射光线),那么就会接近于0,表示光线大部分被吸收;相反,如果路径上的总体密度小(表示只有少量物质吸收或散射光线),那么就会接近于1,表示大部分光线没有被吸收。
表示射线在处的空间坐标。
表示在处的体密度。体密度越大,说明该处物质越密集,对光线的影响也就越大。
表示在处的颜色。
表示从射线起点到点的透射函数,也就是(下面解释)光线衰减程度。
可见性是通过计算光线从摄像机到当前位置之间所有位置的体密度的积分来计算的,表示了光线在到达当前位置之前有多少光被吸收了。
新视图生成:一旦训练好神经网络,就可以根据用户指定的新视点和视角,生成新的2D图像,这些图像可以是从训练数据中未出现过的角度和位置观察的。
由于NeRF的场景表达是全局的和连续的,因此可以很自然地生成新视图,包括训练数据中未曾出现过的视角。这对于许多应用如虚拟现实、增强现实和3D打印等都很有用。
请注意,在实际应用中,可能还需要进行其他一些步骤,例如前处理(如图像对齐和标准化)、后处理(如图像融合和滤波)、超参数调整等。但在概念上,上面这些步骤已经涵盖了NeRF的核心整体流程。
NeRF的优势与局限性
NeRF的主要优势在于其能够生成高度详细和高度真实的3D模型,而且这些模型可以从任何角度渲染出新的2D图像。
这一特性使得NeRF在许多领域有很大的潜力,包括虚拟和增强现实、游戏开发、3D打印、电影制作以及更广泛的图形学应用。
此外,因为NeRF生成的是连续的3D模型,而不是像传统的3D重建方法那样生成离散的3D体素或三角形网格,所以NeRF生成的模型可以具有更高的解析度和更细的细节。
具体如下:
高质量渲染:NeRF通过学习场景的3D辐射场来生成图像,而这种方式可以非常好地恢复场景的细节,如纹理、光照和遮挡等。NeRF在渲染出的图像中,不仅物体的形状和纹理细节表现得生动逼真,而且光照和阴影效果也展现得十分真实,这都得益于NeRF的深度神经网络在学习过程中对场景中的复杂关系进行了高度抽象和理解。
例如,你想生成一张图片,图片的场景是一个装满各种水果的篮子。如果你使用NeRF技术,生成的图片不仅会真实地展现出水果的形状、颜色和纹理,还会准确地展现出阴影和反射等光照效果。你可以清楚地看到水果表面的纹理,例如苹果的光滑表面、橙子的粗糙皮,甚至可以看到篮子的编织细节。这种高质量的渲染效果是因为NeRF通过学习场景的3D辐射场,精确地模拟了物体和光线之间的交互。
连续性:NeRF表示的是一个连续的3D模型,这与传统的3D重建方法(如基于体素或三角网格的方法)有很大区别。这种连续的表示方式使NeRF可以在任意位置给出颜色和体密度的信息,因此能够捕捉到场景中的细微细节,例如物体边缘的微小变化,或者物体表面的精细纹理等。
假设使用NeRF来模拟一座古老的建筑。传统的3D重建方法可能会生成一个由多个小方块(体素)或三角形网格组成的模型,这种模型可能无法准确地展现建筑的某些细节,例如雕刻的线条或砖块的质感。然而,NeRF生成的是一个连续的3D模型,这意味着你可以在任意位置得到颜色和体密度的信息,因此可以清晰地看到建筑表面的每一个细节。
全景场景建模:NeRF使用深度神经网络来表示整个场景的3D辐射场,因此它可以处理全景的场景建模。这一特性使NeRF可以捕捉和重建大范围内的3D场景,包括室内、室外、城市景观等各种环境。
假设有一个项目需要重建一个城市街景。使用NeRF,你可以生成一个完整的3D模型,包括街道、建筑、车辆,甚至是人行道上的灌木和树木。你可以从任何角度查看这个模型,甚至可以像在Google Street View中那样,自由地在街景中移动和旋转。
任意视角渲染:NeRF的另一个重要优点是,一旦训练好,它可以在任意视点和视角生成2D图像。这意味着,我们可以在任意位置、任意角度观察NeRF重建的3D场景,甚至可以在场景中自由移动和旋转,从而观察场景中的不同部分。这对于许多应用,如虚拟现实(VR)、增强现实(AR)等,都是非常有价值的。
例如,你可能有一个3D模型的古堡,并希望生成一系列从不同角度看古堡的图像。使用NeRF,你可以轻松地做到这一点。你甚至可以在古堡的模型中自由移动和旋转,生成从古堡内部看向外部的图像。
对光照和材质的建模:NeRF不仅可以捕捉场景的3D结构,而且可以捕捉场景的复杂光照和材质信息。这意味着,NeRF不仅可以重建物体的形状,还可以重建物体的表面纹理和光照效果。这也是NeRF能够生成高质量渲染图像的一个重要原因。
假设正在重建一个室内场景,场景中有一个木质的桌子和一个金属的灯。使用NeRF,你可以不仅重建出桌子和灯的形状,还可以重建出它们的材质和光照效果。你可以看到木桌的木纹,感受到它的质感;你也可以看到金属灯反射的光线,感受到它的光泽。
无需显式的3D重建:尽管NeRF的内部工作机制是通过学习一个3D辐射场,但在训练和推理过程中,NeRF并不需要进行显式的3D建模,也不需要估计深度信息。这使得NeRF的训练和使用过程更为简单和直接。
例如,可能有一系列从不同角度拍摄的物体的2D图片,你想用这些图片来生成新的视图。使用NeRF,你可以直接输入这些2D图片,然后生成新的视图,而不需要先重建一个3D模型,或者估计图片中的深度信息。这使得NeRF的使用更为简单和直接。
当然,这种方法也有一些局限性,例如训练和渲染过程需要大量的计算资源,而且对于有大量动态内容和复杂反射的场景,NeRF可能无法处理得很好。
NeRF的局限性,主要包括:
计算成本高:NeRF的训练和推理过程需要大量的计算资源。这是因为,NeRF需要对整个3D辐射场进行建模,并且需要渲染大量的2D图像。因此,NeRF在大规模的场景中的应用可能会受到限制。
处理动态场景困难:目前的NeRF主要适用于静态场景,对动态场景的处理能力有限。这是因为,NeRF的训练过程需要大量的时间,而在这个过程中,场景中的物体和光照条件可能会发生变化。
处理反射和透明度复杂的物体困难:虽然NeRF可以处理一些反射和透明度的效果,但对于具有复杂反射和透明度的物体,NeRF可能无法处理得很好。这是因为,这些效果依赖于物体的视角和光照条件,而这些因素在NeRF的训练过程中是难以考虑的。
需求高质量的输入数据:NeRF依赖于高质量的输入数据,如高分辨率的图片和准确的相机参数。如果这些数据的质量不高,那么NeRF的效果可能会受到影响。
训练时间长:尽管NeRF可以生成高质量的渲染图像,但其训练过程通常需要大量的时间和计算资源。这可能会限制NeRF在实时应用中的使用。
NeRF的应用
NeRF(Neural Radiance Fields)是一种新兴的3D重建和视图合成技术,虽然研究起步不久,但已经在许多领域显示出巨大的潜力。至2023年为止,以下是一些NeRF已经应用或可能应用的领域:
影视制作:在电影制作中,特效是非常关键的一部分。传统的3D模型创建和渲染方法通常需要大量的人力和时间,而且结果的质量也会受到限制。
NeRF提供了一种新的方法,可以通过学习一系列照片来自动创建和渲染3D模型。这种方法不仅可以提高效率,而且可以生成非常高质量的结果。例如,NeRF可以用于创建真实的角色或场景模型,然后在任何角度渲染这些模型,以便在电影中使用。
游戏开发:在游戏开发中,环境建模是一个重要的部分。传统的建模方法通常需要大量的手工作业,而且结果的质量也会受到限制。
NeRF提供了一种新的方法,可以通过学习一系列照片来自动创建3D环境模型。这种方法不仅可以提高效率,而且可以生成非常详细和真实的环境模型。例如,NeRF可以用于创建游戏中的城市景观,森林,山脉等环境。
虚拟现实(VR)和增强现实(AR):VR和AR是最能体现NeRF优势的领域。在VR和AR中,用户可以在虚拟世界中自由移动和查看,因此需要在任何角度都能生成高质量的2D图像。
NeRF正好满足这个需求,它可以用来创建高质量的3D场景模型,然后在任何视点和视角渲染这些模型。例如,NeRF可以用于创建VR游戏的场景,或者在AR应用中生成虚拟物体。
3D打印:NeRF生成的3D模型具有高精度和连续性,这使得这些模型非常适合用于3D打印。传统的3D建模方法通常需要大量的手工作业,并且难以捕捉到物体的细微细节。
NeRF提供了一种新的方法,可以通过学习一系列照片来自动创建3D模型,这些模型不仅具有高精度,而且能够捕捉到物体的细微细节。例如,NeRF可以用于创建复杂的工艺品或机械零件的3D模型,然后直接使用这些模型进行3D打印。
这些仅仅是NeRF的几个潜在应用,其在更多领域的应用还在探索和发展中。例如,在建筑设计,地理信息系统(GIS),医疗成像等领域,NeRF都可能发挥重要的作用。
责任编辑:彭菁
-
3D
+关注
关注
9文章
3032浏览量
115815 -
辐射
+关注
关注
1文章
611浏览量
38180 -
建模
+关注
关注
1文章
324浏览量
63532
原文标题:一文详解 | 你还没了解NeRF 神经辐射场吗?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NeRF的基本概念及工作原理
Block nerf:可缩放的大型场景神经视图合成
基于BlockNeRF的大场景规模化神经视图合成
NeRF的研究目的是合成同一场景不同视角下的图像
NerfingMVS:引导优化神经辐射场实现室内多视角三维重建
介绍一种神经场成对配准的技术NeRF2NeRF
基于NeRF的隐式GAN架构
基于神经辐射场(NeRFs)的自动驾驶模拟器

WACV 2023 I从ScanNeRF到元宇宙:神经辐射场的未来

利用PyTorch实现NeRF代码详解
NeurlPS'23开源 | 大规模室外NeRF也可以实时渲染

基于几何分析的神经辐射场编辑方法

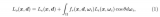



评论