 边缘AI开发,如何驶上快车道?
边缘AI开发,如何驶上快车道?

在云计算之后,边缘计算将成为未来十年物联网市场新的增长点,这已经是不争的事实。据市场研究机构Gartner预测,到2025年将有75%的数据产生于网络边缘,也就是说整个智能世界的计算资源分布重心正在移向“边缘”。
不同于传统云计算架构中将所有计算资源都集中在云端的做法,边缘计算将更多的计算任务放到网络边缘端完成,这样的计算架构在减少延迟、避免大量数据传输对带宽的占用、保护本地敏感数据安全等方面有独特的优势。
特别是随着人工智能(AI)应用的普及,“在云端训练,在边缘端推理”的模式已被普遍认同。通过在边缘设备中部署经过训练的机器学习模型,让边缘设备能够快速、高效地完成AI推理工作,可以促使越来越多的AI应用加速落地。
国际电信咨询公司STL Partners预测,边缘计算的潜在市场将从2020年的90亿美元快速攀升至2030年的4,450亿美元,复合年增长率高达48%!而如此蓬勃发展的市场,也给置身其中的玩家提出了更高的要求——想要跟上市场发展的速度,就需要你的边缘AI开发也能够驶入快车道。
边缘AI催生自适应计算
应用开发想要“上高速”,一个先决条件就是要选一台跑得快的好“车”——针对边缘AI开发来讲,就是要挑选一个可以任性“加速”的开发平台。
一个AI推理应用,既需要对AI处理部分进行加速,也需要满足非AI的预处理和后处理等环节的功能要求,也就是说要对整体的应用流程进行优化。
针对这样的开发需求,使用单一架构的通用CPU,虽然灵活可扩展,可以支持不同应用的要求,但对于整体应用流程加速显然会捉襟见肘,力不从心。而如果为AI应用开发专门的ASIC或ASSP,虽然可以提供高度优化的应用实现方案以及高确定性与低时延,但又会面临着开发周期长、研发成本高的困扰。与此同时,采用固定专用芯片架构还面临着一个更严峻的挑战,那就是AI模型的技术迭代速度远远快于芯片开发的周期,这就会导致芯片好不容易开发出来就已经落伍了,成为无可挽回的沉没成本。
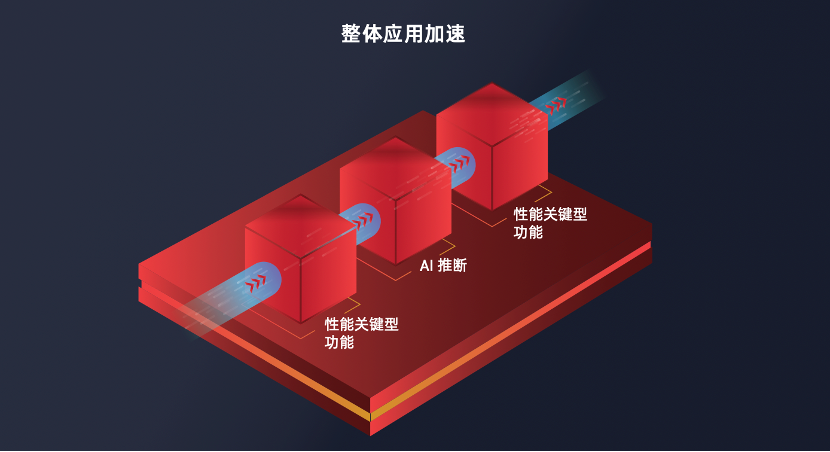
图1:AI推理应用需要全流程的整体应用加速
(图源:AMD)
面对多样化的边缘应用、快速迭代的AI技术,既然通用的CPU和专用的芯片都无法满足要求,就需要一种新的开发平台来补位——这就是基于可编程逻辑的自适应计算平台。
所谓自适应计算平台,就是在不同规模的FPGA结构上集成一个或多个嵌入式CPU 子系统、IO及其他外设模块的异构计算平台。这种平台也被称为自适应SoC或FPGA SoC,它既有嵌入式CPU子系统所具备的灵活性,又可通过硬件编程提供所需的数据处理加速性能,因此开发者能够将正确的任务分配给正确的计算引擎,最终既能够为AI推理进行加速,又可以满足非AI部分的计算要求,进而为各类特定应用提供理想的解决方案。而且,即使工作负载或标准发生演进和变化,自适应SoC仍能根据需要快速配置、灵活适应。
正是因为自适应SoC兼具性能和灵活性的优势,近年来其已经发展成为边缘计算中一个重要的计算架构,也是FPGA厂商在着力打造的一个产品线。比如AMD的ZynqUltraScale+TMMPSoC器件就是其中的代表作。(如图2所示)

图2:ZynqUltraScale+TMMPSoC平台框图
(图源:AMD)
加速自适应计算的应用开发
显而易见,自适应计算SoC可以为用户带来三重自由度,即软件可编程能力、硬件可编程能力以及嵌入式平台的可扩展能力。
不过这种“自由度”对开发者来讲也是一把“双刃剑”——它们虽然比其他嵌入式计算架构更加灵活,但也会令开发变得更加复杂。这种复杂性来自两个方面:其一,FPGA的设计开发流程本身就有较高的门槛,能够熟练掌握的开发者并不多;其二,基于异构平台的整体优化,往往需要多个团队之间的协同工作,使得开发时间和成本不易掌控。
因此,虽然自适应计算SoC对性能的“加速”能力显而易见,但是想让其应用开发过程也得以“加速”,并不是一件简单的事。
不过,聪明的工程师们总有办法让“不简单”的事情变简单。在“为自适应计算应用开发加速”这件事儿上,AMD的工程师就为开发者们提供了一个可行而高效的方法——基于自适应系统模块(SOM)的解决方案。
所谓SOM,想必大家不会陌生,这是一个集成了内核芯片以及外围的存储器、IO接口等功能电路的完整计算系统,它通常不是独立使用的,而是要通过连接器插入到母板(即一个更大型的边缘应用系统)中实现一个特定的完整应用。
SOM为开发者带来的好处,归纳起来主要有三点:
#1
首先,SOM都是经过严格调试、测试和验证的产品,因此开发过程不必从更为底层的芯片进行,可以节省大量的时间和成本。
其次,SOM具有很强的可扩展性,插入不同的系统板,即能实现定制的方案,这就为系统设计带来了更强的灵活性与易用性。
#2
#3
此外,SOM是可量产化的,在性价比、可靠性等方面都经过了全面的优化,因此使用在批量的商用产品中完全没有问题。
而上面这些优势,正是自适应计算应用开发中面临的“痛点”,因此设计一个自适应SOM,并利用其为自适应计算提速,为边缘AI方案赋能,也就成了驶上边缘AI“高速公路”的关键“入口”。
AMD的自适应SOM
AMD的Kria K26 SOM就是大家在驶入边缘AI快车道时,在寻找的这个关键“入口”。

图3:Kria K26 SOM
(图源:AMD)
该SOM基于Zynq UltraScale+ MPSoC架构,内置一个64位的四核Arm Cortex-A53应用处理器组,并配套一个32位的双核Arm Cortex-R5F实时处理器和一个Arm Mali-400MP2 3D图形处理器。SOM上还包括4GB的64位DDR4存储器和QSPI与eMMC存储器。
Kria K26 SOM可提供25.6万个系统逻辑单元、1,248个DSP、26.6Mb的片上内存。这使得用户能够获得丰富的资源和设计自由度,以实现不同应用中的视觉功能以及可编程逻辑中额外的机器学习预处理和后处理硬件加速功能。
此外,该SOM还为H.264/H.265提供了内置的视频编解码器,可支持高达32个编码、解码并发流,只要视频总像素在60FPS下不超过3840 x 2160P。
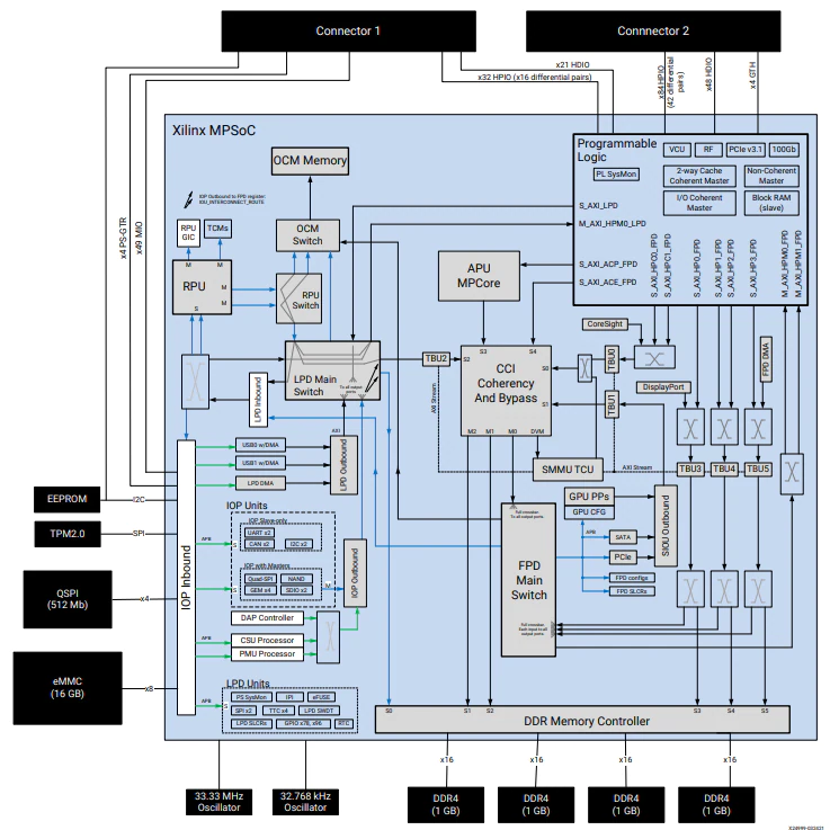
图4:Kria K26 SOM框图
(图源:AMD)
在安全性方面,Kria K26 SOM采用Zynq UltraScale+架构内置的硬件可信根实现的固有的安全启动功能,通过外部TPM2.0扩展用于测量启动并遵循IEC 62443规范。
此外,出色的I/O灵活性也是Kria K26 SOM一大亮点——它拥有大量的1.8V、3.3V单端与差分I/O,四个6Gb/s收发器和四个12.5Gb/s收发器,便于SOM支持更多的图像传感器以及多种传感器接口类型,其中包括通常ASSP和GPU不支持的MIPI、LVDS、SLVS 和SLVS-EC。
此外,用户还能通过可编程逻辑实现DisplayPort、HDMI、PCIe、USB2.0/3.0等标准,以及其他用户自定义的标准。
在外形上,Kria K26 SOM的尺寸为77mm x 60mm x 11mm,紧凑的外形非常便于集成到系统中,且根据规划,未来AMD还将推出更小尺寸的SOM。目前Kria K26 SOM分为商用级和工业级两个版本,用户可以根据终端应用的需要进行选择。
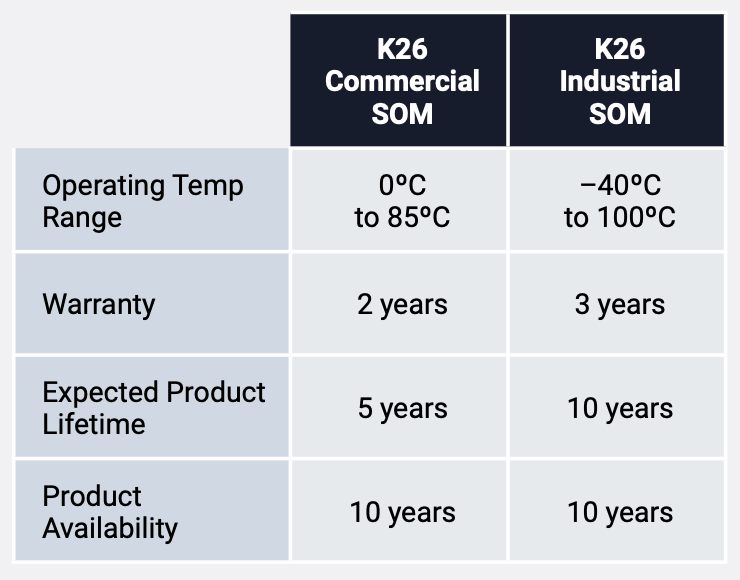
图5:商用级和工业级K26 SOM特性比较
(图源:AMD)
Kria K26 SOM带来的价值
使用Kria K26 SOM会是一种什么样的体验?在设计实战中,Kria K26 SOM的表现如何?想必这是大家都关心的问题。
首先,从简化硬件设计流程来看,与传统的基于器件的设计相比,基于SOM的设计省去了RTL/硬件设计、器件调试、电路板设计等环节,直接从系统级设计开始,因此可以大大简化开发流程——据AMD的分析,基于SOM的设计可以缩短新产品上市时间多达9个月!
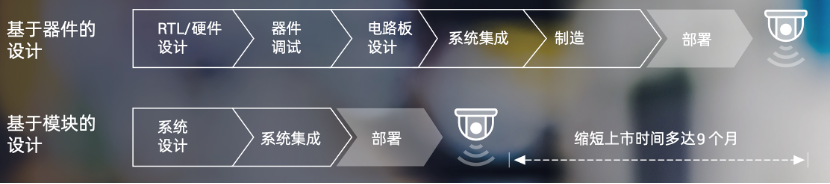
图6:基于SOM的设计与基于芯片的设计过程相比,可以缩短新产品上市时间多达9个月(图源:AMD)
在硬件性能方面,在AMD提供的一个汽车车牌识别(ANPR)应用案例中,基于Kria K26 SOM的解决方案出色地完成了包含视频解码、图像预处理、机器学习(检测)和OCR字符识别在内全流程的加速和优化,与采用GPU架构的SOM方案相比,在计算性能、能效表现、以及每视频流成本上都有明显的优势(如图7)。相信随着K26 SOM应用的扩展,其在性能上的潜质也会被越来越多地挖掘出来。
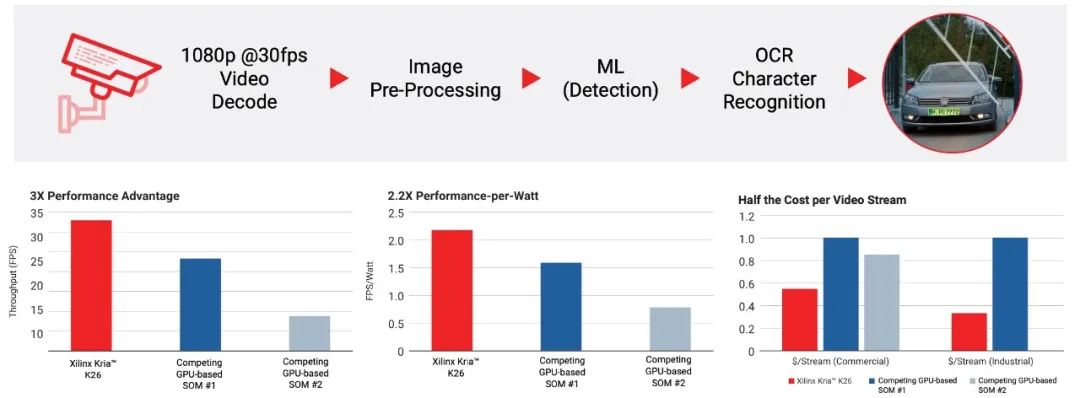
图7:在ANPR案例中,K26 SOM表现出明显性能优势(图源:AMD)
特别值得一提的是,Kria K26 SOM除了可以为硬件开发者带来诸多好处,对软件开发者也是一个福音。随着与Kria K26 SOM配套的边缘AI软件工具、库和框架的发展,一些设计团队可以在无需硬件工程师介入的情况下使用自适应计算。
对于软件开发者而言,Kria K26 SOM和AMD提供的综合软件平台,可以使其在熟悉的Python、C++、TensorFlow和PyTorch等环境下进行开发,为其提供易于使用、开箱即用的体验。再加上AMD生态系统中第三方软件厂商资源的支持,更是可以让边缘AI开发的性能和灵活性提升到一个更高的水平。
快速体验Kria K26 SOM
为了方便开发者快速体验到Kria K26 SOM的强大能力,挖掘Kria K26 SOM的价值,AMD针对一些典型的边缘AI应用,还提供了开箱即用的入门级开发套件。
Kria KV260是专为视觉应用而开发的视觉AI入门套件,它配有非生产版本的Kria K26 SOM,以及安装有风扇散热器的评估载板,可通过onsemi成像器访问系统(IAS)和Raspberry Pi连接器提供多摄像头支持。该开发套件还可由PMOD扩展支持丰富的传感器模块。
基于KV260视觉AI入门套件,软硬件开发人员无需FPGA经验,即可在1小时内启动和运行应用程序,进而在Kria K26 SOM上快速实现视觉AI应用的批量部署。

图8:Kria KV260视觉AI入门套件
(图源:AMD)
Kria KR260机器人入门套件是AMD新推出的一款基于Kria K26 SOM的开发平台,它具有高性能接口和原生ROS 2支持,旨在为机器人和嵌入式开发人员提供快速简便的开发体验。
该开发套件包括Kria K26 SOM、载板和散热系统,以及电源解决方案、多个以太网接口、SFP+连接、SLVS-EC传感器接口和microSD卡,其目标应用包括工厂自动化、通信、控制和视觉,特别是机器人和机器视觉应用。

图9:Kria KR260机器人入门套件
(图源:AMD)
本文小结
云计算已经深刻改变了IT和IoT世界的格局,而边缘计算的兴起正在重塑新的游戏规则。在这一趋势中,如何让越来越多的边缘AI应用快速落地,需要一种不同以往的计算平台,以及与之相适应的开发方法。自适应SOM也就应运而生了。
AMD的Kria K26 SOM可以让你的边缘AI开发驶上快车道,并沿着这条高速公路,将边缘AI应用范围延伸至到更广阔的领域。想要快速起步,即刻上路,就来贸泽电子网站中的Kria K26 SOM专题深入了解一下吧!
Kria K26模块化系统(SOM)专题
>> 点击了解详情 <<
该发布文章为独家原创文章,转载请注明来源。对于未经许可的复制和不符合要求的转载我们将保留依法追究法律责任的权利。
关于贸泽电子贸泽电子(Mouser Electronics)是一家全球知名的半导体和电子元器件授权代理商,分销超过1200家品牌制造商的680多万种产品,为客户提供一站式采购平台。我们专注于快速引入新产品和新技术,为设计工程师和采购人员提供潮流选择。欢迎关注我们!
更多精彩

原文标题:边缘AI开发,如何驶上快车道?
文章出处:【微信公众号:贸泽电子】欢迎添加关注!文章转载请注明出处。
-
贸泽电子
+关注
关注
17文章
1225浏览量
100465
原文标题:边缘AI开发,如何驶上快车道?
文章出处:【微信号:贸泽电子,微信公众号:贸泽电子】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
天数智芯助力DeepLink异构算力训推一体化升级

高速全双工通信:数据世界的“双向快车道”
沐曦股份携手模力方舟正式发布AI技能认证体系
论马斯克的预言:AI使人类边缘化
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
意法半导体STM32 AI模型库助力边缘AI落地应用
出海贸易快车道:50+国际采购团坐镇CES Asia2026 助企业足不出户链全球
【今晚7点半】正点原子 x STM32:智能加速边缘AI应用开发!今晚正点原子B站直播间等你
科大讯飞携多款核心AI产品亮相海外科技峰会
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
教育部力推“AI进课堂”!高交会3E亚洲消费电子展解锁新兴市场AI教育密码!

墨芯人工智能深圳总部乔迁新址
边缘AI的优势和技术基石




评论