 NVIDIA NeMo 如何支持对话式 AI 任务的训练与推理?
NVIDIA NeMo 如何支持对话式 AI 任务的训练与推理?

编辑推荐
大模型驱动的对话式 AI 正在引发新一轮的商业增量。对话式机器人正在不同领域发挥着越来越大的作用,帮助企业用户解决客户服务等难题,提高客户的体验。然而,尽管技术已经趋近成熟,门槛大大降低,开发和运行可落地的语音人工智能服务仍然是一项复杂而艰巨的任务,通常需要面临实时性、可理解性、自然性、低资源、鲁棒性等挑战。
本期分享我们邀请到了NVIDIA 的解决方案架构师丁文,分享如何使用 NVIDIA NeMo 进行对话式 AI 任务的训练和推理,从而帮助开发者快速构建、训练和微调对话式人工智能模型。
本文转载自DataFunSummit
01
NeMo 背景介绍
1. NeMo 和对话式 AI 的整体介绍
NeMo 工具是一个用于对话式 AI 的深度学习工具,它可以用于自动语音识别( ASR,Automatic Speech Recognition)、自然语言处理(NLP,Natural Language Processing)、语音合成( TTS,Text to Speech)等多个对话式 AI 相关任务的训练和推理。下面的这张图给出了一个对话式 AI 的全流程。
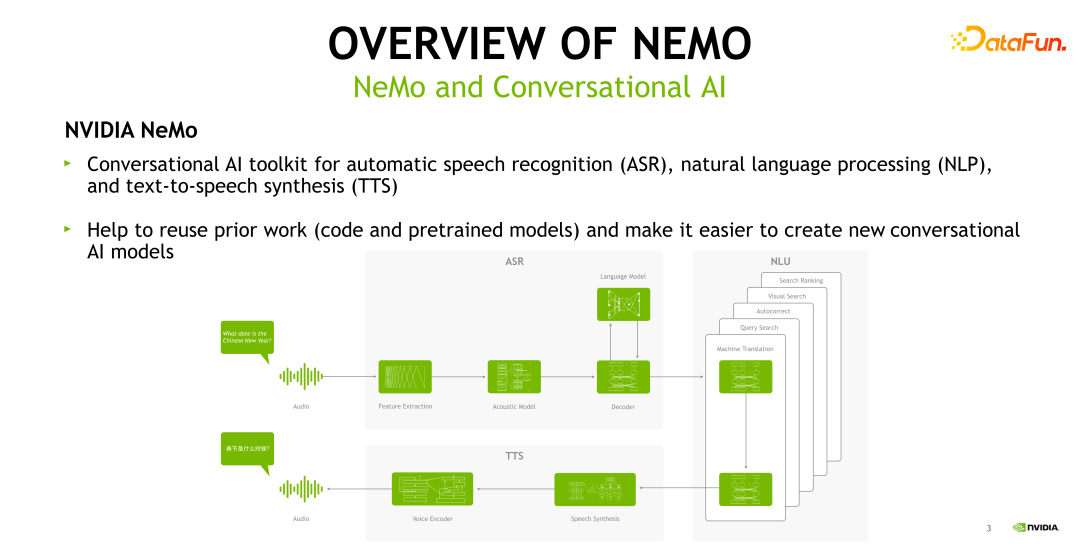
对话式 AI 的输入是一个音频,音频首先会进入 ASR 模块,ASR 模块包括了特征提取、声学模型、语言模型以及解码器,识别出来的文本接着进入 NLU 模块,根据不同的业务需求进行相应的处理,如机器翻译或者是 query 匹配等。以机器翻译为例,我们将英文文本翻译成中文文本,接着将中文文本输入 TTS 模块,最终输出一个语音段。整个 pipeline 均可在 NeMo 中实现。NeMo 希望协助 AI 从业者利用已有的代码或 pretrained模型,加快搭建语音语言相关的任务。整个 pipeline 的开始和结束分别是 ASR 和 TTS。这两个部分属于 speech AI 的一个领域,也是今天重点讨论的范围。
2. Speech AI—— ASR 的背景介绍
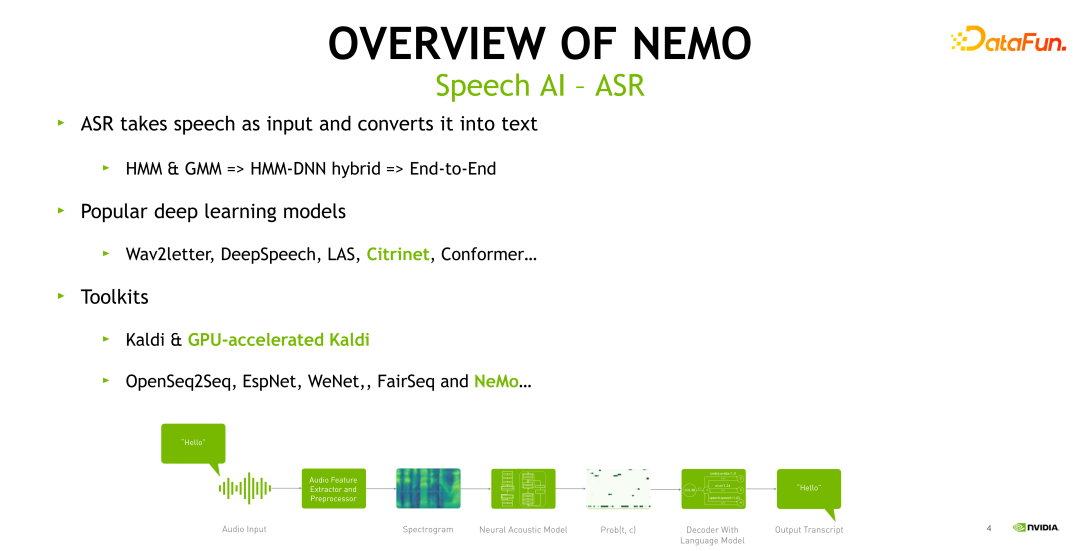
本节主要对 ASR 进行简单的回顾和概述。ASR是将语音转换成文字的一个过程。传统的 ASR 建模方法是基于隐马尔可夫( HMM )和混合高斯模型(GMM)进行建模。2015 年微软首次将神经网络引入到语音识别建模当中,使用神经网络来建模基于给定的音频帧,HMM 状态的后验概率分布,并使用 HMM 进行混合解码得到文本。
近些年,得益于算力和数据的丰富,端到端的 ASR 得到了广泛的关注。端到端的 ASR 也使得整个语音建模过程的 pipeline 更加简洁。上图给出了一个典型 ASR 的 pipeline。输入的语音首先进入特征提取和前处理模块,以获得频谱特征。接着输入到神经网络的声学模型里。最后解码器结合语言模型输出一个文本。近年流行的神经网络模型结构包括 Wav2letter,DeepSpeech,LAS,Citrinet 以及现在非常热门的 Conformer。常见的语音识别工具包括 Kaldi,它也是语音识别当中最重要的工具之一, NVIDIA 针对 Kaldi 做了一系列的优化。Kaldi 主要支持 hybrid 系统及部分常见神经网络的训练。第二类的工具是基于 PyTorch 或者是 Tensorflow 的开源工具,例如 OpenSeq2Seq、EspNet、WeNet 以及 NeMo。
3. NeMo 对 ASR 的支持
下面介绍 NeMo 目前支持的 ASR 的几个方面。

它主要支持的模型结构包括传统的 LSTM 以及由 NVIDIA 的 NeMo 团队提出的 Jasper 家族(包括 Jasper,QuartzNet,Citrinet 等纯 CNN 的结构),以及现在比较主流的模型如 Conformer 和 Squeezeformer 等。
NeMo 支持 CTC 和 Transducer/RNNT 两种,也是目前学术和工业界较为关注的两种解码器。语言模型方面,NeMo 支持 N-gram 进行 LM fusion 以及神经网络语言模型进行 Rescoring 两种方式。此外,NeMo 也支持流式训练及解码,可以配置不同的 chunk size 来适配不同的业务需求。
02
案例:基于 NeMo 训练 ASR 模型
1. ASR 的数据准备

本节中将以语音识别为例,介绍如何在 NeMo 里快速地搭建语音识别模型,会按照前面所提的语音 ASR 各个模块逐一介绍。
NeMo 中通过配置 config 文件来使用不同的模块和参数。首先,需要准备数据集的 manifest,它是一个JSON文件。例子如上图所示,audio_filepath 需提供各条音频地址。Duration 是音频长度,text 是标注好的文本。我们也提供了不同数据集的预处理脚本,例如 Librispeech、中文数据集 Aishell-1/2 等。也可以使用 Kaldi2json 脚本将 Kaldi 格式的数据转换成 NeMo 训练所需要的格式。配置时需要指定 train,validation 和 test 三个部分。上图右下角给出了示例 train_ds 的配置写法。用户根据自己数据的情况来进行相应配置。它主要包括:manifest_filepath 音频的路径;采样率 sample_rate,通常是 16K 或者是 8K;labels 为训练时的建模单元;max_duration 是最大音频长度,中文里我们通常选取 0.1 秒到 20 秒的长度区间,超过则会被丢弃。
NeMo 主要支持字(character)、子词(subword)或者是 BPE(Byte Pair Encoding)作为建模单元。如上图示例所示,左侧一个子词作为一个建模单元,右侧是一个字作为单元。若我们以字作为建模单元,则需要在 labels 处指定字典即可。若我们以子词、BPE 作为建模单元,则需要在 config 中指定对应的 tokenizer。我们也提供从文本中获得 tokenizer 的脚本。详见图片下方的链接,可以直接用来获取根据个人数据训练出的 tokenizer。
2. 特征和增强

准备好数据后,首先需要做特征提取,将语音段转换成特征例如梅尔谱或者是 MFCC 特征。NeMo 中用于特征提取模块有两个:使用 AudioToMelSpectrogramPreprocessor 提取梅尔谱或者使用 AudioToMFCCPreprocessor 提取 MFCC 特征。上图右边给出了一个示例。如使用梅尔谱特征,需要在 preprocessor 模块的 target 部分赋值为 AudioToMelSpectrogramPreprocessor。此外,在 ASR 中常用的特征增强与数据增强的方式,NeMo 也是支持的。例如 Spec Augmentation,只需在target 处赋值为 SpectrogramAugmentation 即可。NeMo 也支持其他的数据增强方式,包括 Speed perturbation 等。
3. 模型结构

处理好特征后,接下来介绍 NeMo 中如何配置神经网络模型。以 Conformer 为例,主要的配置是在 encoder 部分。将 target 设置成 ConformerEncoder。我们可以通过配置不同的 number of layers(n_layers) 和 dimension(d_model) 来构建不同参数量的 Conformer 模型。也可以通过配置 self-attention 相关参数,如 number of heads(n_heads),以直接调整参数量。同时也支持相对位置编码。
NeMo 支持流式的训练和解码。在这里我们可以通过配置 att_context_size 来调整。[-1,-1] 表示左右可以看到的长度为无限长,所以此处是一个离线模型的配置。
右图给出了当前 NeMo ASR 支持的全部模型,以及任务的配置文件的列表。比如想训练一个 Conformer 模型,只需要点开 Conformer 的 folder 就可以看到现在可以支持哪些配置。

NeMo 支持CTC和RNN-Transducer两种 decoder。如果使用的是 CTC loss,需在 decoder 部分的 target 处设置成 Conv ASR Decoder。num_classes 指字典或者是 BPE 的词表大小。如果使用 RNN Transducer loss,需在 decoder 的 target 处设置为 RNNT Decoder,同时需要配置 prediction network(prednet) 的 hidden size(pred_hidden)和 number of layers(pred_rnn_layers),同时还需要配置 joint network。如上图右侧所示,前往 conformer 文件夹下可以看我们能够同时支持 CTC 和 Transducer 的 loss,character 和 BPE 的建模基本单元。另外,若需训练流式 conformer 模型,只需前往 streaming 文件夹内便可看到如何操作。
4. Conformer-CTC 配置

结合上面的介绍,如果想启动一个基于 Conformer CTC 的语音识别模型训练,只需前往 NeMo 的 git 仓库内 examples/ ASR /conf/conformer,选择 conformer_ctc_char.yaml,即可进行相应的配置。需要自行指定的部分,包括最重要的 Dataset。默认 Spec Augment 是开启的。默认 Decoder 是 CTC(因为前面选择了 CTC 配置)。默认的优化器是 Adam。训练使用 PyTorch Lightning。训练时可以指定 GPU 还是 CPU、以及最大的 epoch。此外,其他的训练配置可以在 Exp_manager 里面进行设置。
5. 训练和评估

配置完成后,便可以启动训练。只需要调用 Python 脚本 examples/ASR/ASR_ctc/speech_to_text_ctc.py。config-name 需要设置成前面配置好的 conformer_ctc_char.yaml。
如果有一些其他参数需要配置或者是替代,可以在启动训练时给定一个值。如想替换训练数据集 manifest 的地址,以及指定训练的具体某个 GPU,如果想使用混合精度训练,只需将 trainer.precision 设置成 16,它就会用 FP32 和 FP16 的混合精读训练来加速整个训练流程。
训练好模型后,需要测试评估,主要使用 speech_to_text_eval.py 文件,可以把训练好的 NeMo 的 checkpoint 填入 model_path。dataset_manifest 填入希望去测试的一个集合,格式也是 JSON 文件。如果 metrics 是 CER,这里需要配置 user_cer=True。这样即可使用 CER 来衡量语音识别模型的性能。
6. 部署
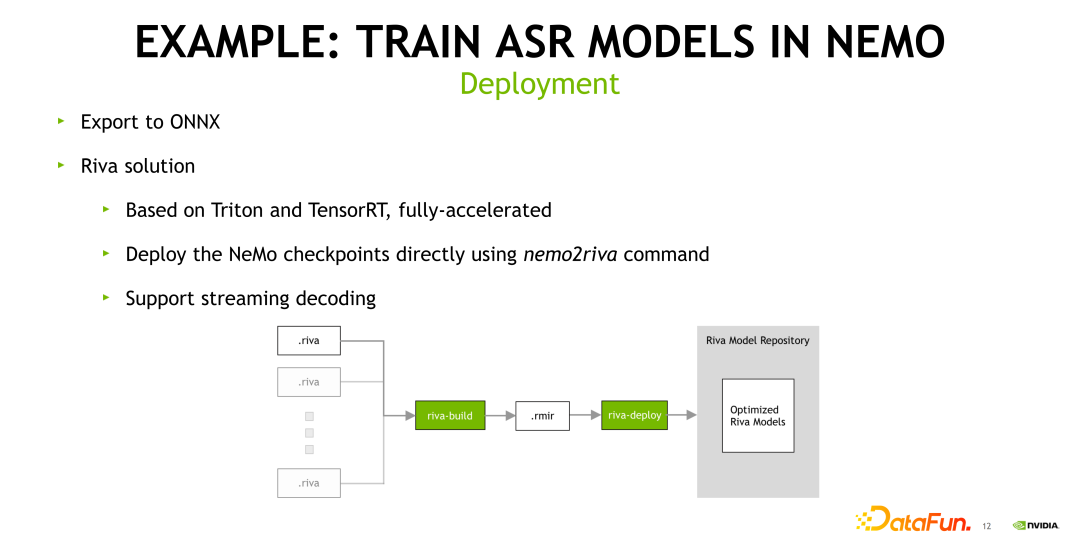
NeMo 具有可以直接部署的方案。NeMo 首先可以支持直接导出到 ONNX。NVIDIA 也有提供相应的模型部署的方案,主要是使用 Riva 这个产品。Riva 使用的是 NVIDIA TensorRT 加速神经网络模型,并且使用 NVIDIA Triton 进行服务。训练好的 NeMo 模型是可以直接使用 NeMo2riva 命令进行转换,从而可以在 Riva 中使用该模型。Riva 中的 ASR 部分也提供流式解码功能,可以满足不同的业务的需求。
03
中文支持
1. NeMo 內的中文模型及应用

下面主要介绍 NeMo 里中文语音支持的情况。首先在 ASR 部分提供了 Aishell-1 和 Aishell-2 两个预处理的脚本,以及一些 pretrained 的模型,包括 Citrinet-CTC 和 Conformer-Transducer。大家可以去 NGC 下载预训练好的模型进行测试或 finetune。上图也给出了现在 Conformer transducer 在 Aishell-2 的性能。总体表现较好。此外,如果想使用其他的网络结构,只需要在配置文件的 labels 处替换成相应的字典或者是 BPE 词表即可。NeMo 加入了对中文的文本正则化的支持(基于 WFST),便于使用者对于一些中文数据的预处理。此外,中文的 TTS 也在计划支持中。
2. Riva 內的中文模型及应用

Riva 主要是支持 Citrinet-CTC 和 Conformer-CTC 两种 ASR 的模型,支持 N-gram LM fusion 的解码方式,也支持中文标点模型。
04
NeMo 对其他 Speech AI 相关应用的支持
接下来需要讨论的是,已经有了一个 ASR 模型,正式去搭建一个语音识别服务时,还需要 Speech AI 其他的哪些功能。
1. 语音端点检测
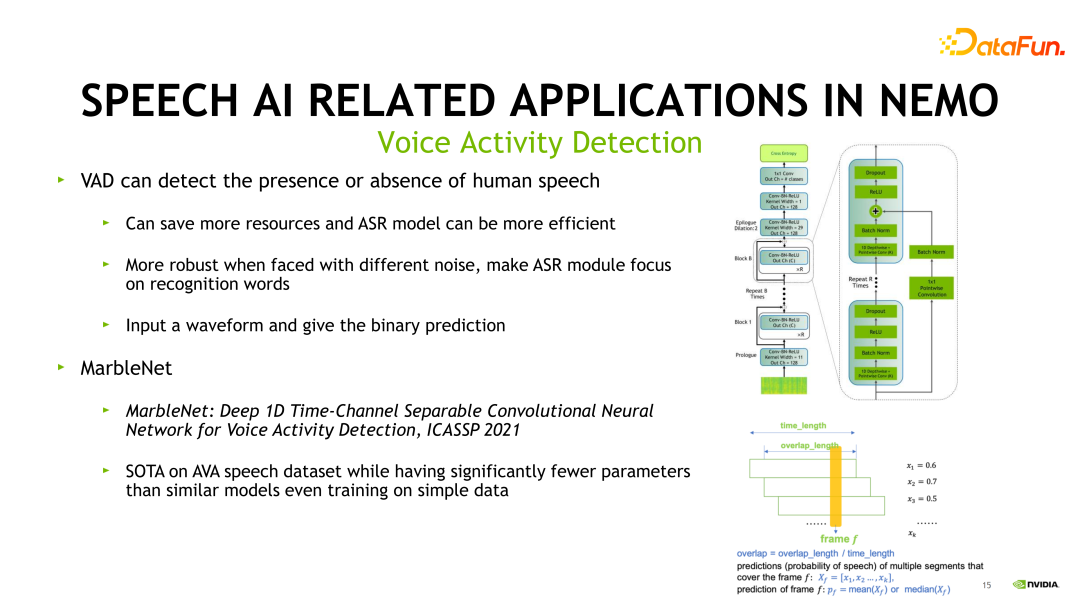
首先需要一个VAD(Voice Activity Detection)模块。VAD 是语音端点检测,可以检测出音频中的人声段,通常是很多语音识别任务的前置模块,用来过滤出有效的人声段。它能够节省很多资源,使 ASR 或者后续的其他语音任务更加高效,同时面对不同噪声能够更加鲁棒,让 ASR 能够 focus 在识别的任务本身。它可以看作是把音频判断出 Label 为“是人声”和“不是人声”的一个二分类任务。在 NeMo 中,我们主要使用的 VAD 模型是 MarbleNet。它的结构见上图右侧,它也是 Jasper 家族的一个变种,一个纯卷积网络的结构,它达到了在 AVA speech 数据集上的一个 SOTA 的结果。并且使用了更少的参数量,取得了更好的性能表现。
2. 说话人日志

第二个要介绍的 speech AI 任务是Speaker Diarization,即说话人日志。它主要想解决的问题是 ” who spoke when?” (什么人在什么时候说话了?)。即给定一段音频,需要给出属于不同说话人的音频段,以及相应的时间戳。这个任务在很多场景中都有应用,例如在会议转写场景里面,SD 模块可给出不同参会者所说出的音频段。
上图右侧给出了 SD 和 ASR 结合的示例。最上侧是一个语音识别模块所做的事情,它识别出了音频中对应的文本。最下侧是 SD 模块,它需要给出 speaker1 说了 “hey” 和 “quite busy” 两段音频,speaker2 说了 “how are you”,并且给出了对应话的在音频段中的开始和结束时间点。SD 模块可以在原始的 ASR 识别出的文本中加入说话人的信息,能够捕捉到不同说话人的特征,并且区分录音中哪一段属于哪个说话人。它通过提取说话人的语音特征,统计说话人的数量,将音频的片段分配给对应的说话人,得到一个索引。
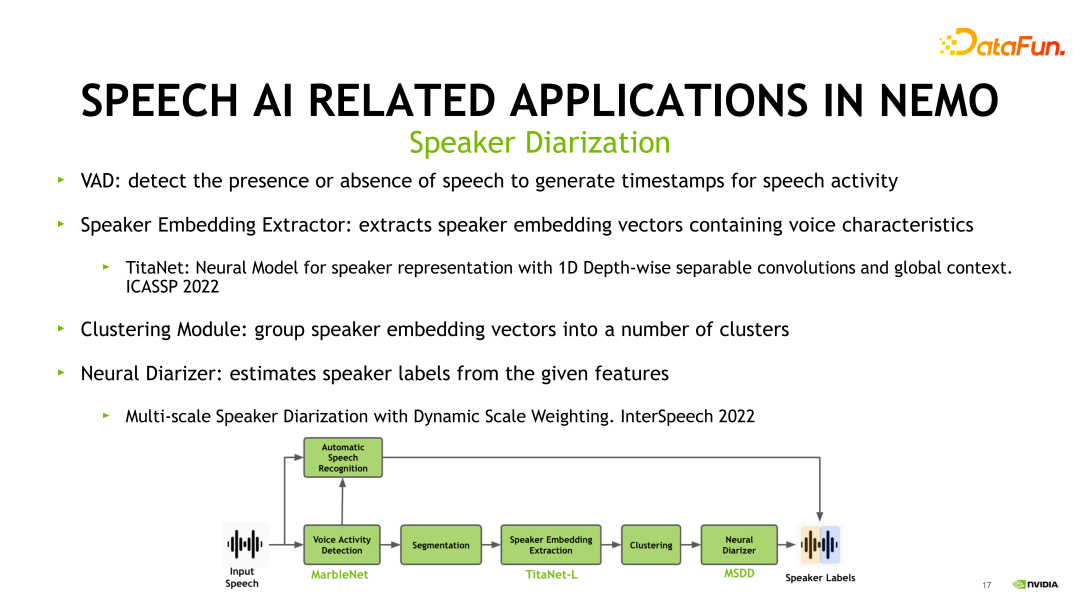
接下来展示 NeMo 中 Speaker Diarization 是如何实现的。上图展示了它的 pipeline。首先是一个前置的 VAD 模块,会从一个长音频中检测出各个人声段的开始和结束。第二步进行说话人的 Embedding 提取。NeMo 当中采用的模型就是 TitaNet,也是在最新发表在 ICASSP 2022 的论文里提出的模型,根据声学特征来提取说话人的信息。接下来是聚类模块,它对提取完毕的说话人的 Embedding 进行聚类,分成不同的类别。
最后一步,我们需要将前面的信息进行汇总,来得到不同的说话人时间戳信息。NeMo 中采用的是 Multi-scale Speaker Diarization 的方式,这也是在我们最新发表在 InterSpeech 2022 的论文内容,感兴趣的同学可以看一下。
3. NeMo 提供的 SD 开源资源
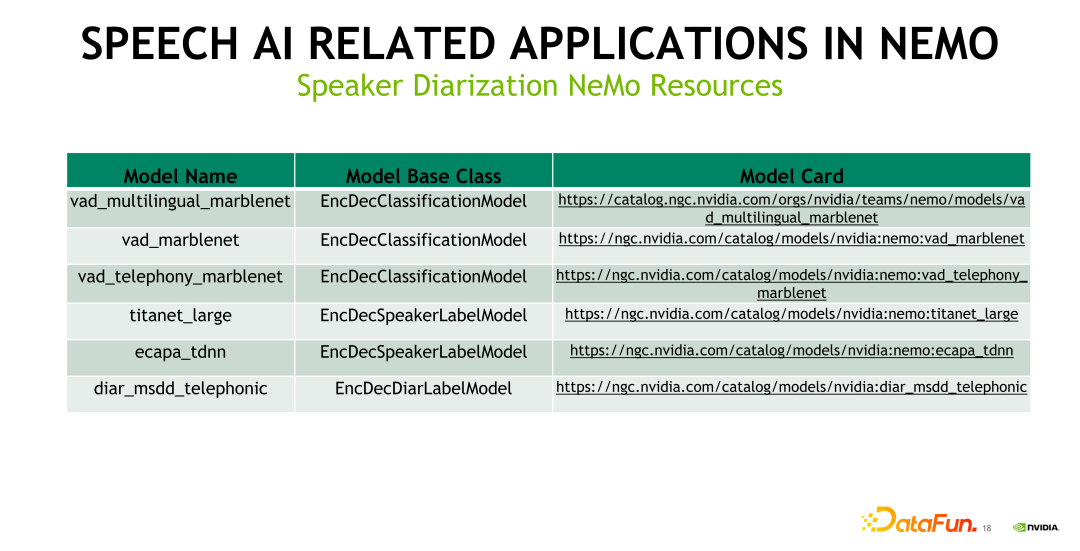
上图中给出了 Speaker Diarization 方向目前由 NeMo 开源出来的 pretrained 模型,包括基于不同数据训练出来的 VAD 模型,以及提取说话人 Embedding 特征 的 Titanet 和 Ecapa_tdnn。前文提到的 Multi-scale Speaker Diarization 模型,也进行了开源,大家可以到对应的 NGC 链接来下载相应的模型进行测试和 finetune。
05
问答环节
Q1:Kaldi 单机多卡训练问题,如何避免任务互相抢占?
A1:把 GPU 的模式设成 Exclusive status,他就不会发生任务互相抢占。
Q2:对中文 TTS 的支持情况如何?
A2:应该是年底就会完成支持。我们已经在去推进这个事情了。
Q3:有什么通用的数据集,如果强行的把词表放在 GPU 显存,会不会给不够?
A3:我们现在 NeMo 里面中文用的是汉字,大概是 5000 个常用字(最核心的应该是 3000 个左右),其实 GPU 是可以放下的。
Q4:MarbleNet 的资源消耗和并发情况如何,以及模型的大小?
A4:它的模型非常小,可能几百 k。其实在 Riva 里面已经支持了 MarbleNet,集成到整个 pipeline 当中。
Q5:NeMo 的 ASR、VAD、SD 如何同时使用,有相关的脚本吗?
A5:有的,在 NeMo 的 tutorial 里面有这样的一个示例,怎么把 VAD 加 SD 串联起来。
Q6:什么是预训练模型?用预训练模型后怎么操作可以快速地满足业务应用语音识别的需求?
A6:比如我们在 Aishell-2 上面训练了一个 Conformer,然后把 Conformer 模型开源出来,大家就可以再根据自己数据的情况或者业务的情况,把它作为一个初始的模型来做 finetune,这样会加速整个模型的迭代和收敛的速度。方便大家做后续的任务。
Q7:在 NeMo 的 pipeline 中,后处理的部分,CTC 测试部分,是用的 GPU 还是 CPU?
A7:我们现在 language model 的 fusion 是放在 CPU 上的,但我们其实也有一些 GPU 的解决方案。
Q8:具备对齐功能吗?效果如何?
A8:没有的,因为我们支持的是 CTC 和 RNNT,没有 hybrid 系统里面的 alignment。
Q9:去噪模型有相应的成果吗?比如预训练模型。
A9:我们默认 Spec Augmentation 都是加的,但是其他的一些数据增强的方式,比如混响,加噪和变速默认都是没有开的。我们的 pretrained 模型一般都是加了 Spec Augmentation 的。
Q10:看大 NeMo 还支持 NLP 相关的任务,请问如果是做关系抽取应该怎么配置?
A10:关系抽取,NLP 上面的一些任务,大家可以直接去 NeMo 的 Github官网上面看。它的 README 里面有写目前支持的模型以及方法。
Q11:ASR 同一模型可以在 inference 时设置 chunk size 同时满足流式和离线吗?
A11:在 inference 的时候,chunk size 需要设置成固定的,是不支持动态的加 chunk size 的。
Q12:NeMo 对变长的输入会做什么特殊处理吗?A12:没有什么特殊处理。我们一般在训练时会对数据做一次排序,这样每个 batch 的长度是基本一致的,padding 就不会打得长度不一致。基本上每个 batch 大小是比较固定的,能够提高吞吐和训练速度。
今天的分享就到这里,谢谢大家。
-
英伟达
+关注
关注
23文章
4113浏览量
99600
原文标题:NVIDIA NeMo 如何支持对话式 AI 任务的训练与推理?
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA 扩展开放模型系列,推动代理式、物理和医疗 AI 下一阶段发展

NVIDIA推出代理式AI蓝图与电信推理模型
AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
NVIDIA DGX SuperPOD为Rubin平台横向扩展提供蓝图
使用NVIDIA Grove简化Kubernetes上的复杂AI推理
通过NVIDIA Jetson AGX Thor实现7倍生成式AI性能
什么是AI模型的推理能力
一文看懂AI训练、推理与训推一体的底层关系




评论