 技术速递 | 论文分享《Holistic Evaluation of Language Models》
技术速递 | 论文分享《Holistic Evaluation of Language Models》

1. 在所有被评估的模型中,InstructGPT davinci v2(175B)在准确率,鲁棒性,公平性三方面上表现最好。论文主要聚焦的是国外大公司的语言大模型,而国内的知名大模型,如华为的Pangu系列以及百度的文心系列,论文并没有给出相关的测评数据。下图展示了各模型间在各种NLP任务中头对头胜率(Head-to-head win rate)的情况。可以看到,出自OpenAI的InstructGPT davinci v2在绝大多数任务中都可以击败其他模型。最近的大火的ChatGPT诞生于这篇论文之后,因此这篇论文没有对ChatGPT的测评,但ChatGPT是InstructGPT的升级版,相信ChatGPT可以取得同样优异的成绩。在下图中,准确率的综合第二名由微软的TNLG获得,第三名由初创公司Anthropic获得。同时我们也可以看到,要想在准确率额上获得55%及以上的胜率,需要至少50B的大小,可见大模型是趋势所向。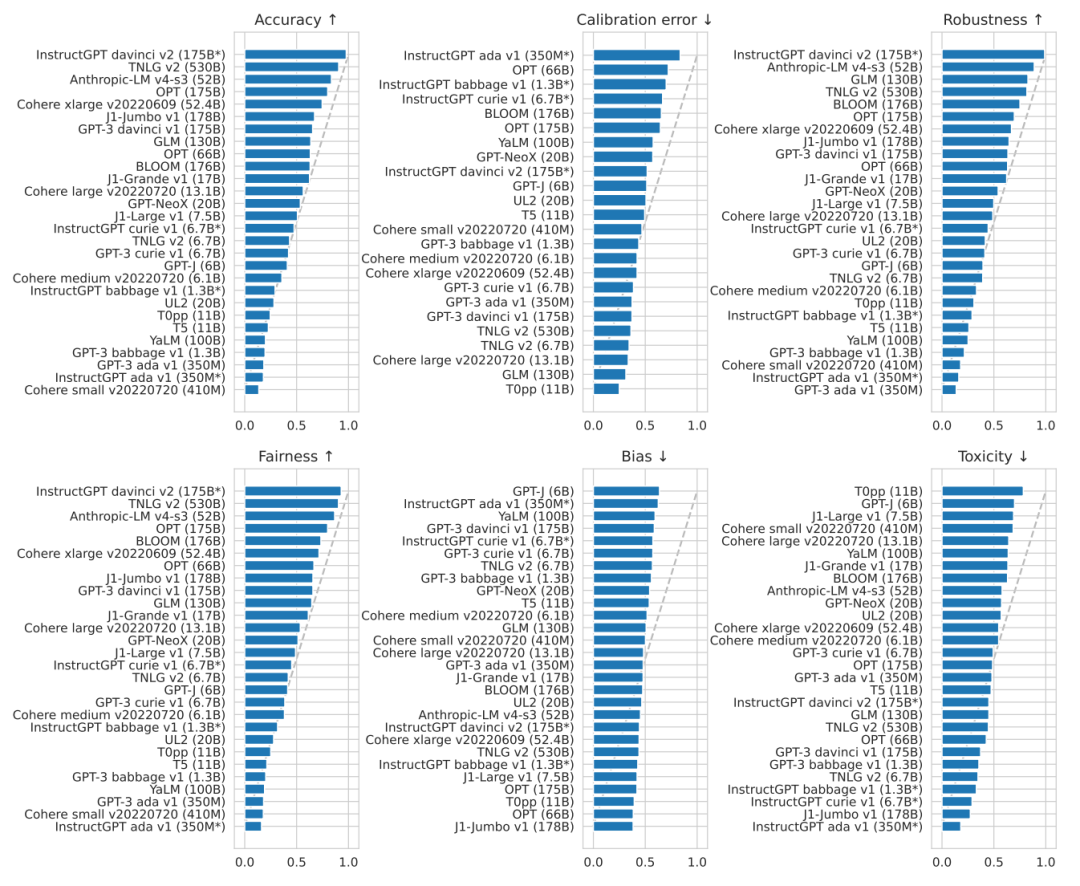
2. 由于硬件、架构、部署模式的区别,不同模型的准确率和效率之间没有强相关性。而准确率与鲁棒性(Robustness)、公平性(Fairness)之间有一定的正相关关系(如下图所示)。
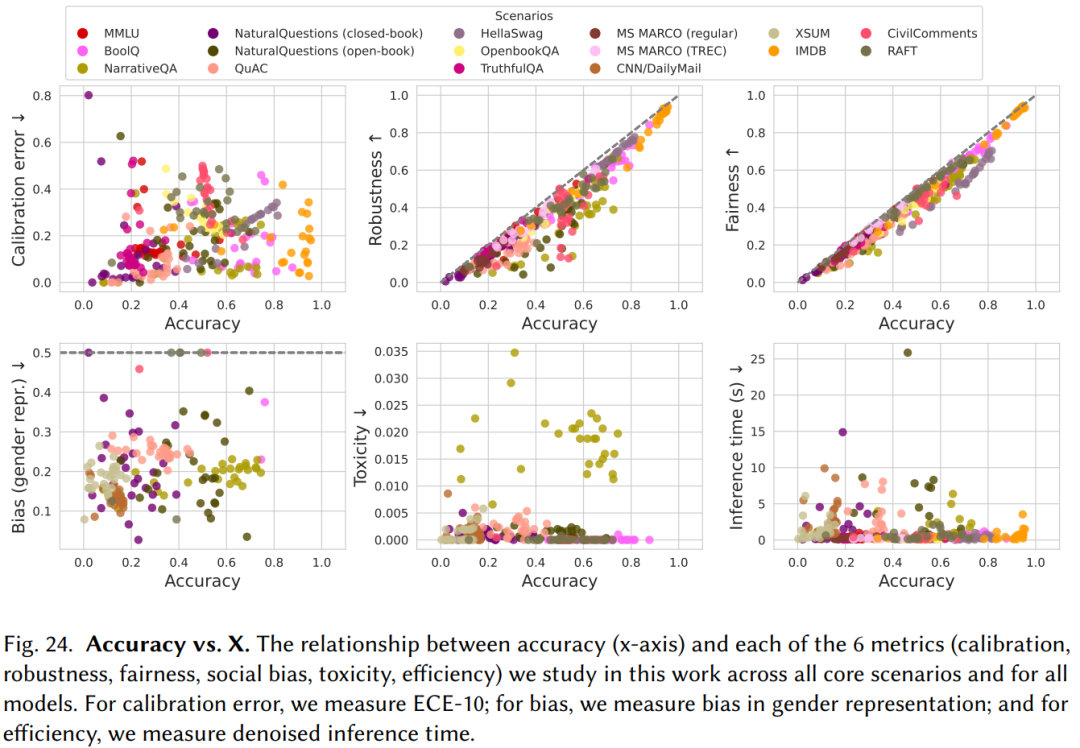
如今,大模型的参数规模都非常巨大。GPT-3具有1750亿个参数,部署这样一个大模型,无论在成本上还是工程上都是极大的挑战。同时,由于需要开放API给用户使用,OpenAI还需要考虑GPT-3的推理速度。文章的测试结果显示,GPT-3的推理速度并没有显著地比参数更少地模型慢,可能是在硬件、架构和部署模式上都有一定地优势,足以弥补参数规模上的劣势。
3. InstructGPT davinci v2(175B)在知识密集型的任务上取得了远超其他模型的成绩,在TruthfulQA数据集上获得了62.0%的准确率,远超第二名Anthropic-LM v4-s3 (52B) 36.2%的成绩。(TruthfulQA是衡量语言模型在生成问题答案时是否真实的测评数据集。该数据集包括817个问题,涵盖38个类别,包括健康,法律,金融和政治。作者精心设计了一些人会因为错误的先验知识或误解而错误回答的问题。)与此同时,TNLG v2(530B)在部分知识密集型任务上也有优异的表现。作者认为模型的规模对学习真实的知识起到很大的贡献,这一点可以从两个大模型的优异表现中推测得到。
4. 在推理(Reasoning)任务上,Codex davinci v2在代码生成和文本推理任务上表现都很优异,甚至远超一些以文本为训练语料的模型。这一点在数学推理的数据上表现最明显。在GSM8K数据集上,Codex davinci v2获得了52.1%的正确率,第二名为InstructGPT davinci v2(175B)的35.0%,且没有其他模型正确率超过16%。Codex davinci v2主要是用于解决代码相关的问题,例如代码生成、代码总结、注释生成、代码修复等,它在文本推理任务上的优秀表现可能是其在代码数据上训练的结果,因为代码是更具有逻辑关系的语言,在这样的数据集上训练也许可以提升模型的推理能力。
5. 所有的大模型都对输入(Prompt)的形式非常敏感。论文主要采用few-shot这种In-context learning的形式增强输入(Prompt)。
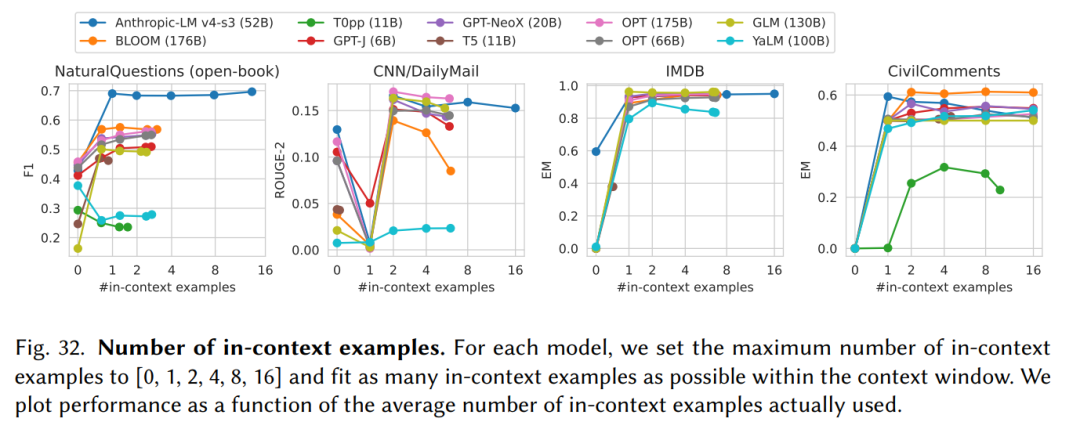
如上图所示,在不同任务上,in-context examples的数量影响不同,在不同的模型上也是如此。由于有些任务比较简单,例如二分类的IMDB数据库,增加in-context examples并不会对结果有明显的影响。在模型方面,由于window size的限制,过多的in-context examples可能导致剩余的window size不足以生成一个完成答案,因而对生成结果造成负面的影响。
点击“阅读原文”,了解更多!
原文标题:技术速递 | 论文分享《Holistic Evaluation of Language Models》
文章出处:【微信公众号:华为DevCloud】欢迎添加关注!文章转载请注明出处。
-
华为
+关注
关注
218文章
36189浏览量
262671
原文标题:技术速递 | 论文分享《Holistic Evaluation of Language Models》
文章出处:【微信号:华为DevCloud,微信公众号:华为DevCloud】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
地平线11篇论文强势入选CVPR 2026

谷东智能光学技术推动AR眼镜迈向大规模应用
DeepSeek开源Engram:让大模型拥有"过目不忘"的类脑记忆
梁文锋署名DeepSeek新论文:突破GPU内存限制的技术革命
TDK Joystick Evaluation Platform:HAL 3900的全方位解析
Nullmax端到端轨迹规划论文入选AAAI 2026
vivado的hardware manager找不到HummingBird Evaluation kit,是什么原因?
华为、中国科学院计算技术研究所联合开发论文获USENIX收录

智芯公司荣获ICEPT 2025优秀论文奖
你发文,我奖励!Aigtek安泰电子新周期论文奖励活动正式开启!

使用CYW955913EVK-01_Evaluation_Kit,可以烧写程序但无法启动如何解决?
理想汽车八篇论文入选ICCV 2025
后摩智能四篇论文入选三大国际顶会
老板必修课:如何用NotebookLM 在上下班路上吃透一篇科技论文?



评论