 在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了

该论文介绍了一种名为 ReMax 的新算法,专为基于人类反馈的强化学习(RLHF)而设计。ReMax 在计算效率(约减少 50% 的 GPU 内存和 2 倍的训练速度提升)和实现简易性(6 行代码)上超越了最常用的算法 PPO,且性能没有损失。

论文链接:https://arxiv.org/abs/2310.10505
作者:李子牛,许天,张雨舜,俞扬,孙若愚,罗智泉
机构:香港中文大学(深圳),深圳市大数据研究院,南京大学,南栖仙策
开源代码:https://github.com/liziniu/ReMax
如未额外说明,所有图片来自于论文。 背景 今年,以 ChatGPT 为首的大语言模型(Large Language Models, LLMs) 在各个方面大放光彩,由此引发了学术界和商业界对 GPU 等计算资源的需求剧增。
比如监督训练地调优 (supervised fine-tuning, SFT) 一个 Llama2-7B 的模型,需要消耗 80GB 以上的内存。而这往往不够,为了和人类对齐(alignment),大语言模型还要经过 RLHF (reinforcement learning from human feedback) 的训练。RLHF 的 GPU 消耗往往是 SFT 的 2 倍以上,训练时间更能达到 6 倍以上。 近日,美国政府宣布限制英伟达 GPU 产品 H100, H800等进入中国市场。这项条款无疑为中国发展大语言模型(LLMs) 和人工智能增添了很多阻力。减小 RLHF 的训练成本(GPU 消耗和训练时间)对 LLMs 的发展非常重要。 动机 RLHF 包含三个阶段: 1. 监督式地调优(Supervised Fine-Tuning, SFT)。 2. 从对比数据中学习奖励模型(reward model)。 3. 利用强化学习(RL)算法来最大化奖励。
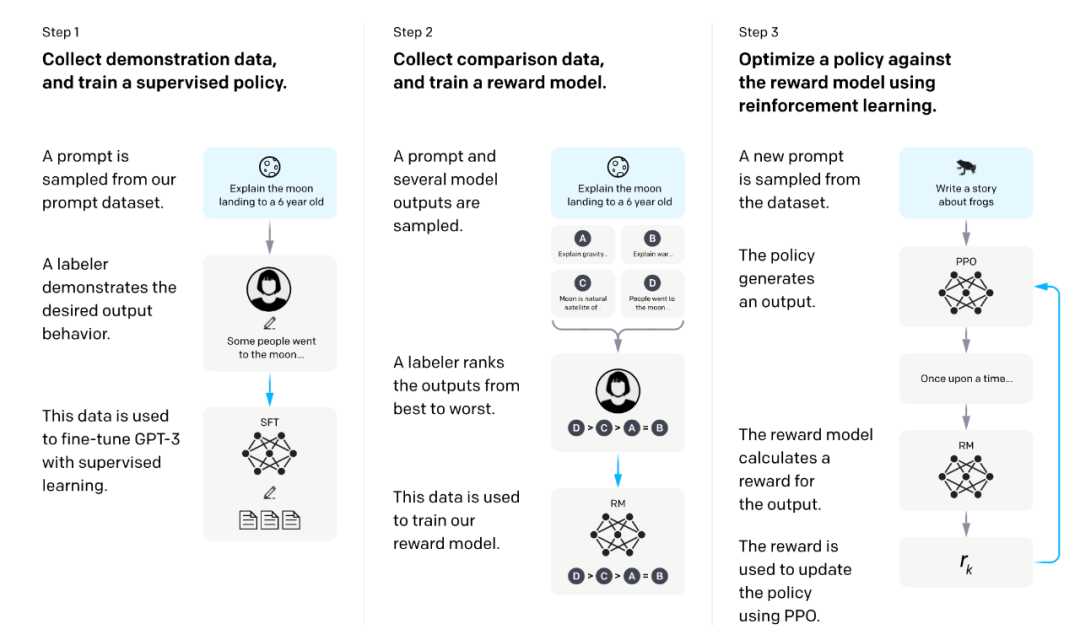
图片来源自 InstructGPT 论文 我们发现 RLHF 的主要计算开销来源于第三阶段(奖励最大化)。这一点可以从 DeepSpeed-Chat 的报告里看到,第三阶段的训练时间是前两个阶段时间总和的 4 倍以上。而且,根据我们的经验,第三阶段的 GPU 消耗是前两阶段的 2 倍以上。

图片来自 DeepSpeed-Chat 技术报告 目前 RLHF 第 3 阶段的主要计算瓶颈是什么? 我们发现该阶段的计算瓶颈主要来源用来目前使用的 RL 算法:PPO 算法。PPO 算法是用来解决普适 RL 问题的最流行的算法之一,有非常多成功的案例。我们在这里省略 PPO 的技术细节,着重介绍 PPO 的一个关键组件:价值模型 (The value model)。价值模型是一个需要被训练的神经网络,能够有效地估计给定策略的预期长期回报。尽管价值模型为 PPO 带来了良好的性能,但它在 RLHF 任务中也引入了沉重的计算开销。例如,为了更好地与人类偏好对齐,PPO 中的价值模型通常与 LLM 大小相似,这使存储需求翻了一番。此外,价值模型的训练需要存储其梯度、激活和优化器状态,这进一步增加了近 4 倍的 GPU 存储需求。总结来说,PPO 和它的价值模型(以及其训练相关部分)已成为 RLHF 奖励最大化阶段的主要计算障碍。
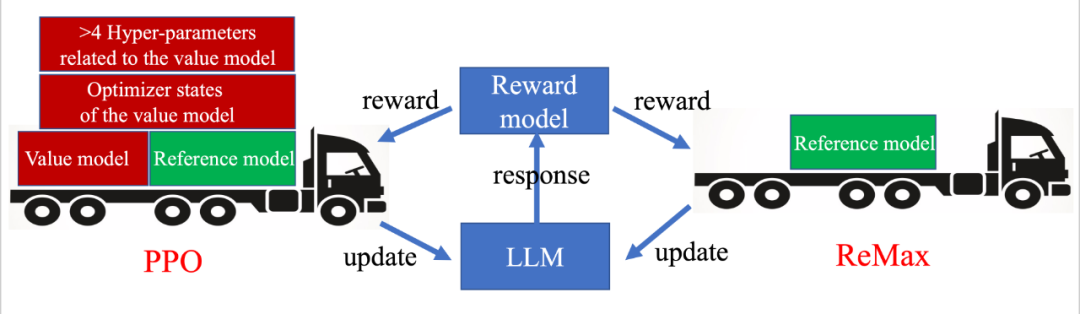
相比 PPO,ReMax 是轻量级算法 思路是否有可能找到比 PPO 更适配 RLHF 的算法? 我们得出的答案是肯定的。这是因为 PPO 和价值模型是为通用 RL 问题设计的,而不是针对像 RLHF 这样的特定问题(RLHF 只是 RL 问题中的一个子类)。有趣的是,我们发现 RLHF 具有三个在 PPO 中未使用的重要结构: 1. 快速模拟(fast simulation): 轨迹(即 LLM 中的整个响应)可以在很短的时间内迅速执行(小于 1s),几乎没有时间开销。 2. 确定性转移(deterministic transitions):上下文确定性依赖于过去的标记和当前生成的标记。 3. 轨迹级奖励(trajectory-level rewards):奖励模型只在响应完成时提供一个奖赏值。 通过这三个观察,我们不难发现 value model 在 RLHF 的问题中是 “冗余” 的。这是因为 value model 设计的初衷是为了随机环境下的样本效率和慢仿真环境的计算效率。然而这在 RLHF 中是不需要的。
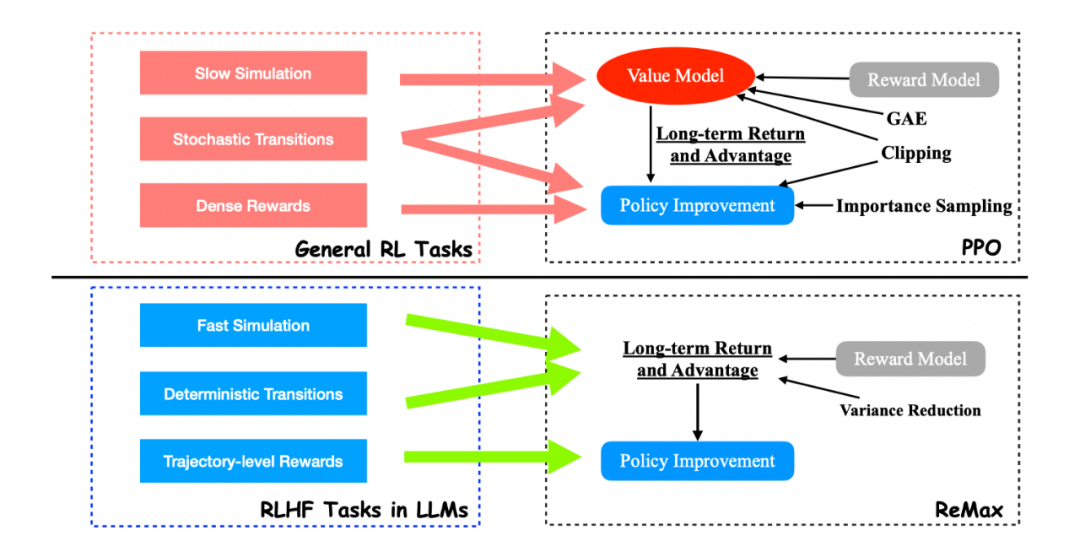
ReMax 是针对 RLHF 设计的算法,PPO 则是为通用 RL 设计的算法 方法ReMax ReMax 算法基于一个古老的策略梯度算法 REINFORCE,REINFORCE 使用的策略梯度估计器如下图所示:
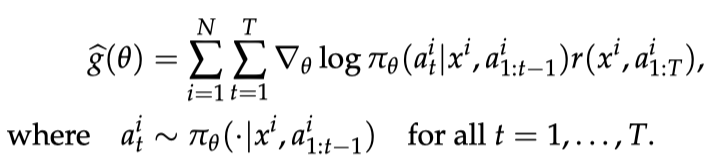
REINFORCE 梯度估计器
REINFORCE可以在计算层面利用好RLHF任务的三个性质,因为REINFORCE直接利用一个响应的奖励来进行优化,不需要像一般的RL算法一样需要知道中间步骤的奖励和值函数。然而,由于策略的随机性, REINFORCE梯度估计器存在高方差问题(在Richard Sutton的RL书里有指出),这一问题会影响模型训练的有效性,因此REINFORCE在RLHF任务中的效果较差,见下面两张图片。
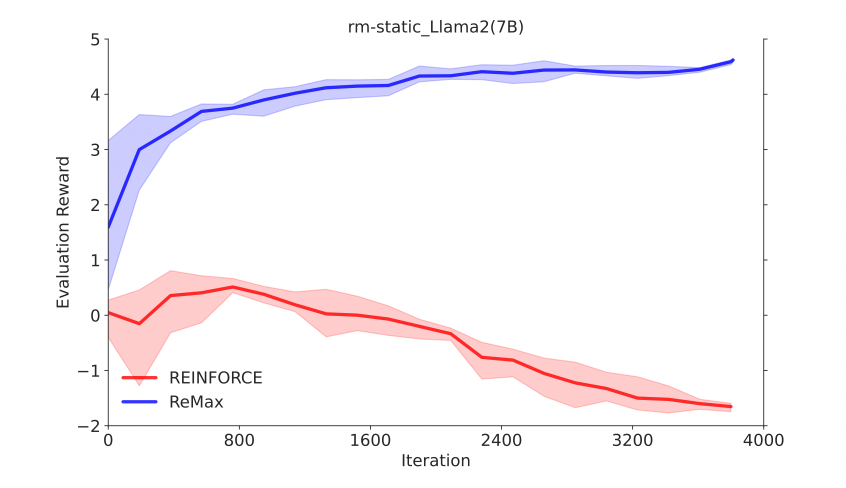
REINFORCE 的计算代价小,但性能差
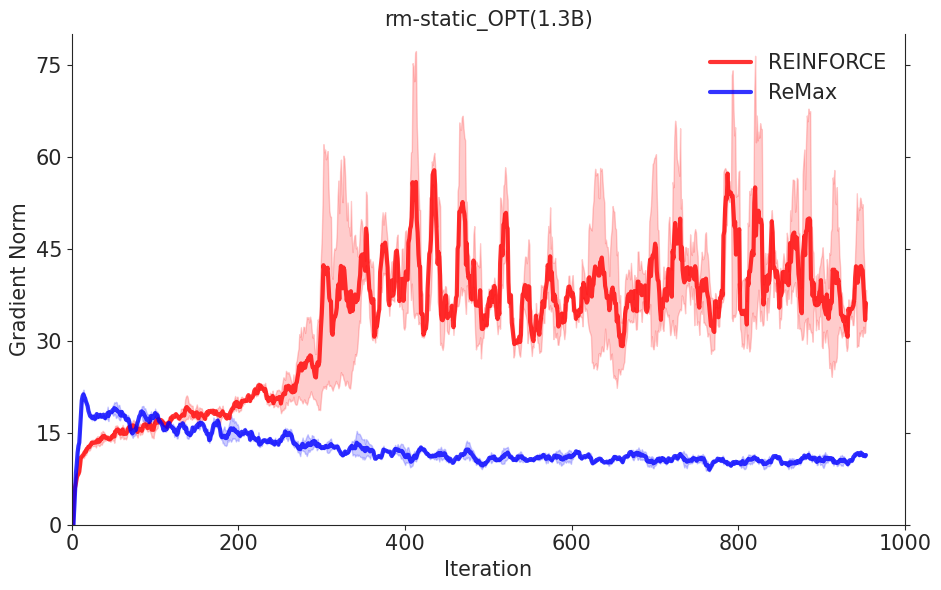
REINFORCE 的(随机)梯度值远远大于 ReMax 为解决这一问题,ReMax 使用贪婪生成的回答(greedy response)的奖励作为基准值(baseline value)来构建梯度估计器,具体公式如下:
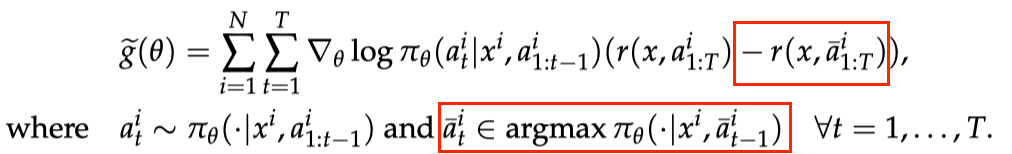
ReMax 梯度估计器 注意到,贪婪回复的奖励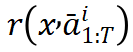 可以看作为期望奖励
可以看作为期望奖励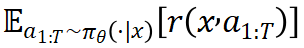 的好的近似。在理想情形下(
的好的近似。在理想情形下(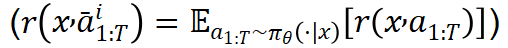 ),对于随机变量
),对于随机变量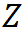 ,
,
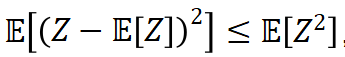
,因此我们能够期望估计器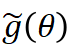 具有更小的方差。 下图展示了 ReMax 的算法流程,红色方框中的是核心算法改变。
具有更小的方差。 下图展示了 ReMax 的算法流程,红色方框中的是核心算法改变。

ReMax 算法流程 理论保证 我们证明了 ReMax 使用的梯度估计器仍然是真实策略梯度的一个无偏估计器。 详细理论介绍见论文。 算法优点
ReMax 的核心部分可以用 6 行代码来实现。相比之下,PPO 要额外引入重要性采样(importance sampling),广义优势估计(generalized advantage estimation,GAE),价值模型学习等额外模块。
ReMax 的超参数很少。相比之下,PPO 有额外的超参数,例如重要性采样剪切阈值(importance sampling clipping ratio)、GAE 系数、价值模型学习率,离策略训练轮次(off-policy training epoch)等,这些超参数都需要花大量时间去调优。
ReMax 能理论上节省约 50% 内存。相比于 PPO,ReMax 成功移除了所有和价值模型相关的部件,大大减小了内存开销。通过计算,我们发现相比于 PPO,ReMax 能节省约 50% 内存。
效果有效性
ReMax 可以像 PPO 一样有效地最大化奖励
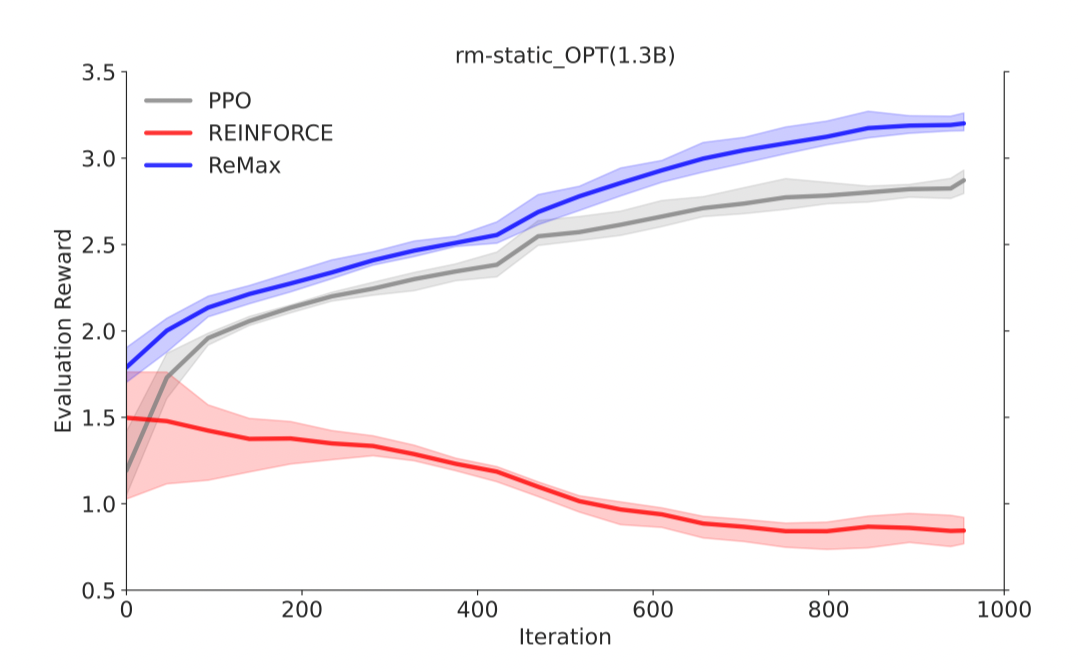
在 OPT-1.3B 上,ReMax 可以有效地最大化奖励
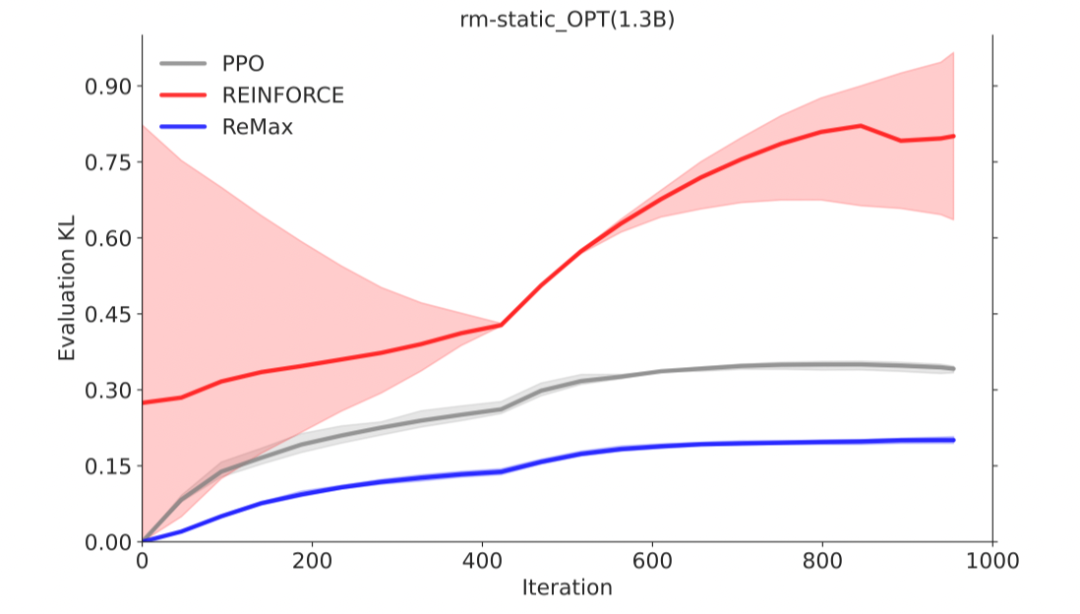
在 OPT-1.3B 上,ReMax 的训练非常稳定
在 GPT-4 评估下(LIMA Test Questions),ReMax 得到的策略比 SFT 和 PPO 会更好
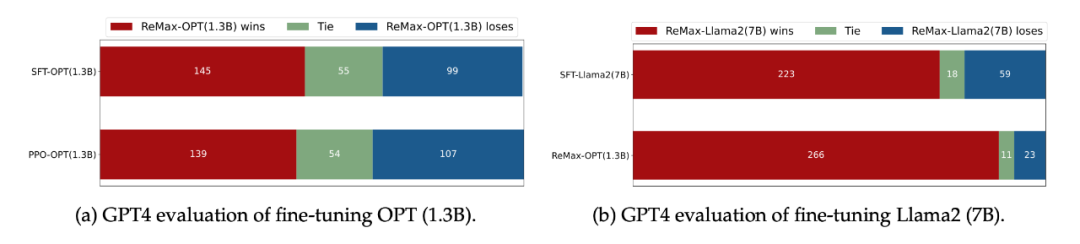
GPT4 打分显示 ReMax 得到的模型会更好 高效性
ReMax 能节省近 50% 的 GPU 内存。ReMax 移除掉了价值模型和它的训练部分(梯度,优化器,激活值),从而极大节省了 GPU 内存需求。考虑 Llama2-7B,PPO 无法在 8xA100-40GB 的机器上跑起来,但是 ReMax 可以。
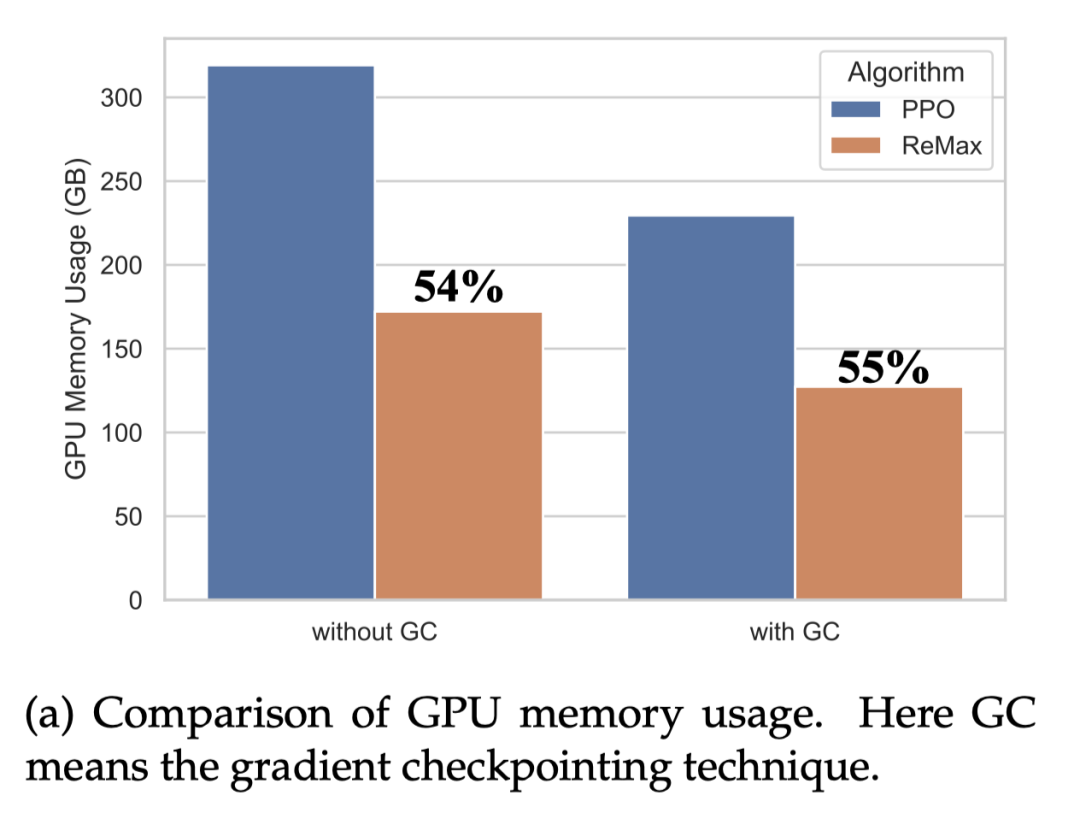
在 Llama2-7B 上,ReMax 可以节省近 50% 的 GPU 内存
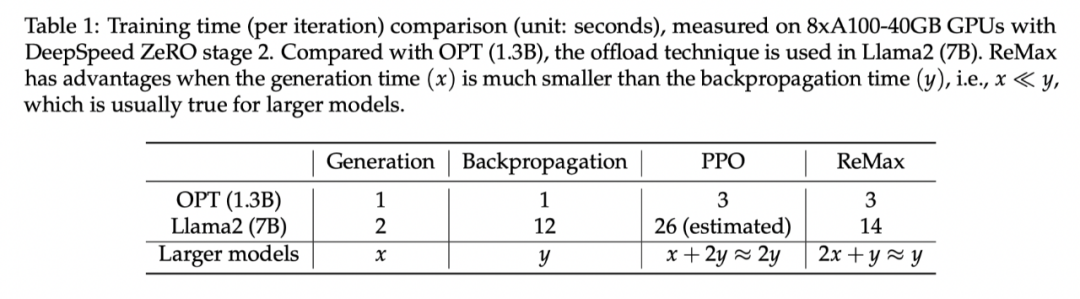
ReMax 能加快 2 倍的训练速度。在每一轮中,ReMax 调用 2 次生成(generation),1 次反向传播(backpropagation);而 PPO 使用 1 次生成,2 次反向传播。对于大模型而言,生成会比反向传播的时间小,从而 ReMax 可以实现理论上接近 2 倍的训练加速。
通用性 除了 RLHF 任务,作为一个 RL 算法,ReMax 对于经典的 NLP 任务也适用。本文考虑了在 GPT-2 上进行一个电影评论续写的任务,这里奖励模型不是从对比数据学习的。实验观测到,ReMax 可以实现 2.2 倍的训练加速和 60% 的 GPU 内存节省。
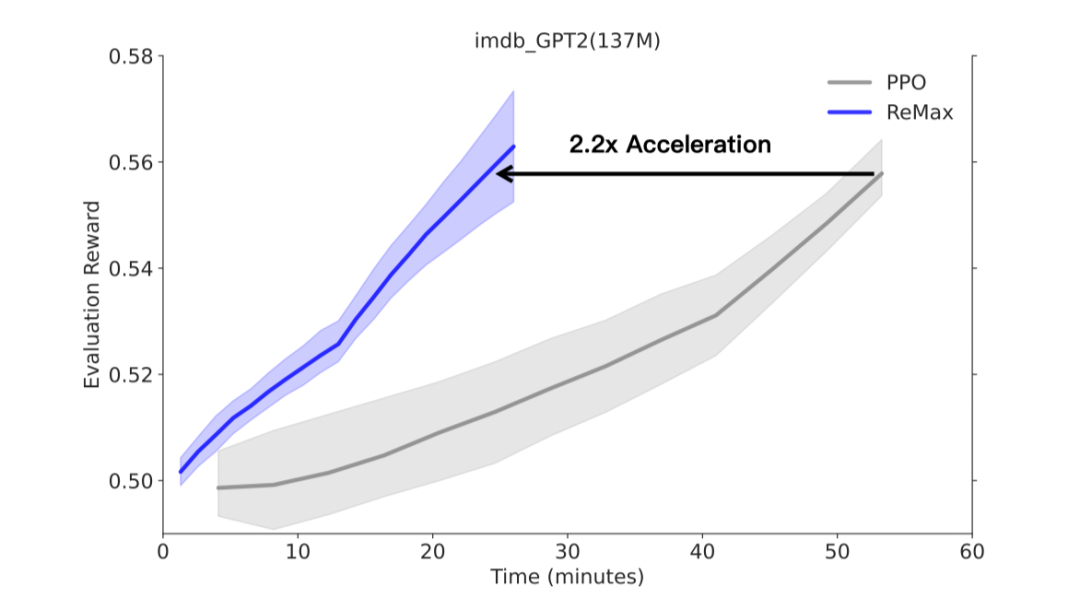
在经典的 NLP 任务(文本续写)上,ReMax 相比 PPO 实现了 2.2 倍加速 总结 最后,我们从实验中简要总结了 ReMax 相对于 PPO 的主要优势。
更简单的实现: ReMax 的核心部分 6 行代码即可实现。这与 PPO 中的众多复杂的代码构建块形成鲜明对比。
更少的内存开销:由于移除了价值模型及其全部训练组件,相比 PPO,ReMax 节省了大约 50% 的 GPU 内存。
更少的超参数: ReMax 成功移除了所有和价值模型训练相关的超参数,其中包括:GAE 系数、价值模型学习率、重要性采样时期、小批量(mini-batch)大小。这些超参数往往对问题敏感且难以调整。我们相信 ReMax 对 RLHF 研究者更加友好。
更快的训练速度:在 GPT2(137M)的实验中,我们观察到 ReMax 在真实运行时间方面相比于 PPO 有 2.2 倍的加速。加速来自 ReMax 每次迭代中较少的计算开销。通过我们的计算,该加速优势在更大的模型上也能维持(假设在足够大的内存下 PPO 可以被成功部署)。
优异的性能:如前所示,ReMax在中等规模实验中与PPO实现了相当的性能,并且有时甚至超越它(可能是由于 ReMax 更容易找到合适的超参数)。我们推测这种良好的性能可以拓展到更大规模的模型中。
-
语言模型
+关注
关注
0文章
576浏览量
11393 -
ChatGPT
+关注
关注
31文章
1611浏览量
10504 -
大模型
+关注
关注
2文章
3912浏览量
5348
原文标题:在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
拆解大语言模型RLHF中的PPO算法
NVIDIA已限制RTX 3060的挖矿性能
浅析RTX 4090极限功耗高达616W
4090显卡全面下架 AI芯片出口管制趋严
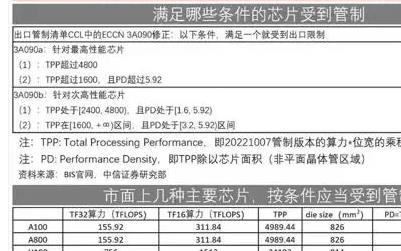
英伟达RTX 4090显卡将被限制对华出口 11月17日起执行
英伟达RTX 4090显卡下架!中文官网已移除产品信息
英伟达RTX 4090D显卡爆料:全新GPU芯片,符合出口管制
英伟达为中国游戏玩家开发专用显卡:RTX 4090 D ,喜迎龙年?

英伟达为中国市场量身打造RTX 4090 D显卡,规避美国出口限制
NVIDIA发布中国定制版RTX 4090D

英伟达RTX 4090D正式发布:整体性能或降低10%!
影驰RTX 4090D金属大师独立显卡测试

英伟达RTX 4090停产 市场价格急剧上涨
$1999 的 RTX 5090 来了



评论