 强化学习推进人工智能应用发展
强化学习推进人工智能应用发展
前言
几年前,那些能够感知环境、探测重要细节(忽视其它部分)且使用这些细节来完成任务的技术应用似乎只存在于科幻小说里。然而在2020年,我们看到不少技术的突飞猛进不仅上了头条新闻,也成为我们日常生活的组成部分:智能语音助手能够解读并对人类语音的细微差别作出回应;相较于医生使用的影像检测,医疗应用能够更准确地预测癌症;无人驾驶车辆甚至能够在动态环境中行驶。
三类机器学习之一的强化学习,正在驱动这些技术进步。一般原则促使计算机通过识别其所在环境的关键特性来作出最佳决定,而这项技能直到最近才成为可能。强化学习(RL)、人工神经网络(ANN) 和深度学习(DL) 既展示了人工智能应用全新的潜力, 也体现了其达到人类水平的难度。
机器学习的方法
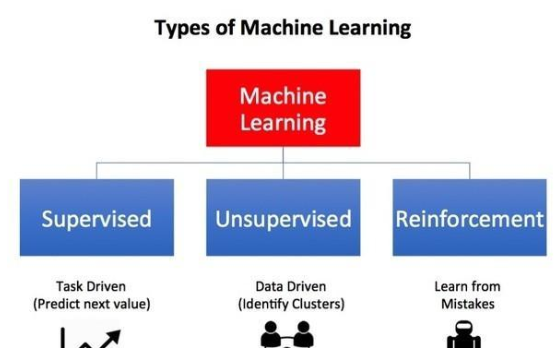
机器学习是人工智能的一个子集,它促使计算机从实例和经验中学习。在机器学习的三个种类中,针对在相对容易预测的环境中解决明确界定的问题,监督学习和无监督学习或许是最广为人知的方式。
监督学习方法 (SL) 用来解决有标记输入数据的问题。监督学习算法尝试通过对这些已知实例模式和关联的学习,对未知实例进行正确处理。一个经典的例子就是图像识别。附加人工注解的图像被用来分析训练模型数据,从而准确分类新捕捉的图像。
无监督学习方法 (UL) 在无标记的数据集中推断隐藏的结构或关系。一般来说这样的学习方法不用过多的事先准备工作,而更具描绘性和解释性的特征。它通常用来为受监督的方法做铺垫。常见的例子是在交易数据中识别不同的客户群,以便稍后规划并开展有针对性的营销活动。
机器学习的第三个方法是强化学习 (RL)。这也是目前在头条新闻中大家看到的最复杂且类似于人的应用。深度学习是一种能够通过奖励和惩罚评估个体行动及加权输入变量的机器学习,目的是在此基础上规划未来行动。RL努力最大化奖励, 最小化惩罚, 并没有被明确告知如何解决问题。它并非仅限于解决特定的问题或限制特别的环境,而是聚焦于那些能够基于来自动态环境中的复杂数据选择最优决策的机器。
强化学习
强化学习的基本理念是以接近人类(或任何足够聪明的生物)处理的方式模型化学习,即用已具备的技能和工具试图达成一个特定的目标(和奖励相关),但无清晰的指令如何解决问题。举个简单的例子:机器人可以把手张开和握紧来把球放进盒子里。要想做到这一点,它必须学习如何抓住球,把手臂移动到合适的位置,再让球落下。这项训练需要多次迭代和重启实验;机器人获得的唯一反馈是它的行为是否成功,从而调试动作直到目标达成。
这和监督学习形成了鲜明的对比, 因为SL需要很多的例子(比如一组庞大且多样的猫的已标记图像)来以多种维度描述问题本身。只有这样,算法才能学习到底哪些特征 (比如形状或颜色)和最佳决定的作出有关。回到之前所举的机器人例子,同样,它需要准确且谨慎地描述过程的每一个步骤, 比如把手放到哪儿,施加多少压力等等。对于低变量的实例来说,做到这种程度的细节是可能的,但如果变量有差,就必须重新学习。球稍大点,机器人就可能犯错。
在现实应用里,输入、输出和训练数据的方程式出人意料的复杂。例如,无人驾驶车辆要处理大量几乎实时的传感器数据。错过任何一个环境的细微差别都会造成不可想象的后果,因此风险很大。这就是为什么当创造训练实例或指令在某一个环境中难以负担或不可能时,强化学习是在这种背景下作决策的首选工具。
强化学习的子类型
和其它的机器学习方法一样,强化学习有不同的子类型为未来铺平道路(图表 1 -下方)。尤其是特征学习 (FL) 让系统能够识别输入数据的不同细节。人工神经网络 (ANN) 和深度学习 (DL) 为高级解析、处理和学习提供了必要的框架,并使深度强化学习 (DRL) 得以实现。
特征学习
特征学习(也被称为表示学习)是一种机器学习技术,让机器能够识别输入数据的特征和独立组成部分,而这些信息通常无法在算法中体现。比如,在一辆无人驾驶汽车里,环境是由不同的摄像头、雷达和传感器所感知的。即使有众多信息帮助你决定下一步怎么走,相关的信息其实少之又少。比如,天空的颜色通常无关紧要,而红绿灯的颜色则息息相关。 一只鸟飞过的速度和一个路人走到路边的速度都无关痛痒。
具有体现这种程度的输入功能的能力究竟为何如此重要? 用于训练目的的数据集在模型的准确性上扮演着关键的角色:训练数据越多越好,尤其是数据集里具备差异性大且特征清晰的实例。也就是说,正是那些输入数据中独一无二的独立特征帮助计算机弥补已学和未学内容之间的差距,从而在任何情境下保证百分之百的准确性和连贯性。对差异因素的识别能力也有助于避免可能被忽视的特征和异常点, 因为随着时间的推移,这将大幅减少数据的数量。
人工神经网络和深度学习
变数大的应用需要一个稳健且可扩展的框架。尤其在监督学习领域,受到高度关注的一种学习方法要数深度学习了。与强化学习的原则相结合,我们称之为深度强化学习。
人工神经网络 (Artificial Neural Networks, ANN) 的最初设想要追溯到上世纪六十年代,笼统地建立在类似于网络的人类大脑神经结构的基础之上。ANN由一个庞大的人类神经原网络所组成,这些神经原叫做感知器,能够接受输入信号,权衡输入的不同特征,然后将信号导入网络中,直到抵达输出信号端。
网络的属性由神经原的数量、其连接的强度和数量及激活上限来定义。输入信号必须具有此强度才能被传送。ANN拥有包含多种输入层和输出层的可升级结构,使用中间“隐藏"层把输入转化成输出层可使用的内容。深度学习的专用名词正是来自于由大量接连层级的神经原网络,因此是“深度的”。
为什么它被视为在复杂的输入数据和动态的环境中创造最佳答案的最合适方法呢?答案就在它的学习方式:反向传播。对于任何已给的训练信号,比如描述向量坐标或一张图像的颜色值,网络会先检查已生成的输出正确与否,然后对权重稍作调整以实现想要的结果。经过足够的训练迭代,网络不仅稳定性增加,而且能够识别之前未知的情况。
人工神经网络、深度学习和强化学习的局限性
由于人工神经网络和深度学习有能力体现特征并在动态环境中得出最佳答案,因此他们的潜力不可估量。即便如此,它们的技能却指向更多的挑战,也呈现出与模仿人类智慧中的某些方面仍然存在的差距。
需要百万千万个节点、连接和训练迭代
模块化相关问题要求人工神经网络具备足够数量的节点和连接来处理(分析和存储)百万千万计的变量。现代计算机直到最近才能够做到这一点。同样,训练环路的数量可多达十亿百亿,且随着环境变量的大小呈指数增长。强化学习的首次重大突破出现在像围棋这样的游戏中并非偶然,一个叫做阿尔法的围棋机器人(AlphaGo)击败了人类最棒的职业围棋选手:游戏的规则和目标非常明确,因此很容易让人工智能通过和自己对战快速模拟多轮游戏。下一步革命性的突破要数超级玛丽或星际争霸这样的电子游戏。虽然行动和结果之间的关系更加复杂,但环境的局限性让快速模拟多次迭代成为可能。
像无人驾驶这样的现实问题的属性则完全不同。制定安全到达目的地的这类高级任务本身难度并不高。然而环境的多样性要求模拟必须更加成熟,才能更有效地学习实际问题。归根结底,模拟驾驶最终还必须被现实驾驶所替代,以通盘考虑到所有其它无法被模块化的因素,同时在与人类水平相当的驾驶表现目标实现以前,密切监控必不可少。举例来说,2020年,自动驾驶汽车研发公司Waymo在一份新闻发布稿中提到,它们的汽车要想和人类一争高下,还需要累计一千四百年的驾驶经验。这和我们只花几周时间练习就能上路相比简直不可想象。那么为何强化学习无法做到这一点呢?还是这并非不可能……?
与抽象和推理相关的技能
人类能够快速学习如何玩游戏或开车的一个重要原因是,我们通过抽象化和推理来学习。通过这种学习方式,驾驶员能够以不同的角度或在不同的情境下想象红绿灯是什么样子,这依赖于人类与生俱来的空间意识。我们也可以在路上看见并判断与以往看到的颜色不同的汽车,从观察和经验中得出结论。
而这些功能直到最近才在人工神经网络中得以探索。即便不同的网络层级能够捕捉输入数据的不同维度,例如 形状和颜色,网络还是只能处理那些训练数据里明确容纳的特征。假设人工智能的受训时间是白天,那么模型将很难应付夜晚的各种情况。即使应用深度学习,在训练数据中还是应该考虑到诸如此类的差异,那么来自训练数据中可接受的偏差程度仍然非常低。
目前我们正在探索很多不同的通过抽象和推断进行学习的技术,而这些技术甚至显露了更多的挑战性和局限性。人工神经网络失误的一个著名例子是,有一种计算机视觉系统能够识别西伯利亚哈士奇犬,而且可信度相较于对于其它犬类的辨识高出很多。实际上,更仔细的分析表明,网络仅锁定了几乎所有哈士奇图像中出现的雪,而几乎忽视了狗本身。换句话说,模型并没有认知地面颜色并非狗的先天特征之一,而这一细节对人类来说却是微不足道的。
虽然这个例子稍显牵强,但现实生活中的后果可能会是可怕的。我们不妨再次以无人驾驶车辆为例,虽然事故很少发生,但却可追根溯源到情境的模糊性。2018年的一场车祸中,推着一辆自行车穿过四车道高速的路人丧生。人类驾驶员可能很容易地避免事故的发生,而人工神经网络的失误却导致了致命的车祸。由于当时的情况并没有出现在很多小时的训练中,网络并没有执行以“如果你不知道该怎么做,就停车!”为命令的故障切换。因此系统开始阵脚大乱,原因是它实际上缺乏人类智慧的基石。
更糟的是,不怀好意的人可能会钻人工智能盲点的空子。举例来说,如果有人在训练过程中插入经操纵的图像,那么图像分类就会被误导。如果说图像中细小的变更对人类来说微乎其微,同样的变更在ANN中则可能以不同的方式被认知和解读。一个未加注解贴纸的停字牌可能被错误地认为其它交通标志。如果这一受训模型被用在一辆真正的车里,那可能会造成交通事故。 反之,人类驾驶员肯定会毫无问题地认出停字牌。
跨越障碍和局限
这些障碍和其它的局限令我们不禁产生疑问,下一步该怎么走才能驱使人工神经网络继续在作出最佳决策上弥补不足? 简单的答案是:“更多的训练”。倘若训练数据的差异性和质量够高,失误率就能缩小到模型的准确率是可接受的程度。事实上现今的自动驾驶汽车事故率比人类驾驶员要低,但“令人惊恐失色的事故”的潜在性还是阻碍了其被更为广泛的公众所接受。
另一个系统性方法是对所需的背景知识进行明确编码,并在机器学习过程中可用。比如,由Cycorp创造的知识库已经存在了很多年,涵盖了数百万的概念和关系,也包括了我们之前所说的停字牌的意义。目的是对人类知识以机器可读的格式进行人工编码,从而使人工智能不仅仅依赖于训练数据,还能够自行作出结论, 且至少以类似人类直觉的方式评估部分未知的情况。
总结
能够感知环境、认知关键的细节并优化决策的技术已经不只存在于科幻小说中。机器学习三种类型之—的强化学习,为我们处理高维变量且与动态环境交互提供了工具和框架。然而,这些解决方案也带来了新的挑战,尤其是对于大量神经网络、全面培训和通过抽象化处理及推导从而模仿人类学习能力的需要,从而适应新情况。虽然目前人工智能已经取得了长足进展,也日益成为许多实际应用中不可或缺的一部分, 但是离达到人类水平的学习技能还相去甚远。经历并体验中间的过程可能比科幻小说本身更有意思。
审核编辑:郭婷
-
人工智能
+关注
关注
1776文章
43871浏览量
230620 -
机器学习
+关注
关注
66文章
8126浏览量
130570 -
无人驾驶
+关注
关注
97文章
3882浏览量
118967
发布评论请先 登录
相关推荐
人工智能发展的好与坏
人工智能和机器学习技术在2021年的五个发展趋势
人工智能芯片是人工智能发展的
人工智能汽车标定方案
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步
机器学习和人工智能有什么区别?
将深度学习和强化学习相结合的深度强化学习DRL
如何深度强化学习 人工智能和深度学习的进阶
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?







 工商网监
工商网监
评论