 如何训练自己的ChatGPT
如何训练自己的ChatGPT

LLM 这两周不断带给我们震撼与惊喜。GPT-4 的发布让大家对 LLM 的想象空间进一步扩大,而这些想象在本周眼花缭乱的 LLM 应用发布中逐渐成为现实,下面分享一位朋友训练ChatGPT的完整方案,供大家参考~
LLM 相关的开源社区这两周涌现了很多优秀的工作,吸引了很多人的关注。其中,我比较关注的是 Stanford 基于 LLaMA 的 Alpaca 和随后出现的 LoRA 版本 Alpaca-LoRA。原因很简单,便宜 。
Alpaca 宣称只需要 600$ 不到的成本(包括创建数据集),便可以让 LLaMA 7B 达到近似 text-davinci-003 的效果。而 Alpaca-LoRA 则在此基础上,让我们能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
下面是开源社区成员分享的可以跑通的硬件规格及所需时间:
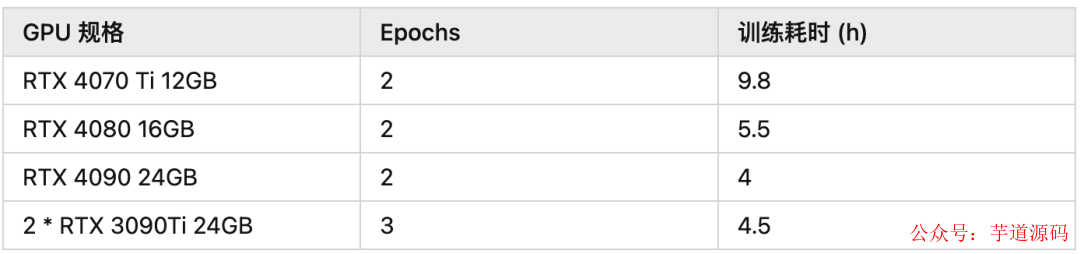
根据大家分享的信息,fine-tune 7B 模型仅需要 8-10 GB vram。因此我们很有可能可以在 Google Colab 上完成你所需要的 fine-tune!
那么,说干就干!
为什么要训练自己的 ChatGPT ?
我想到了以下的方面:
- 对我个人而言,这非常非常 cooooool !
- 让模型能够讲我熟悉的语言
- 让模型替我写注释和测试代码
- 让模型学习产品文档,帮我回答用户提出的小白问题
- ...
计划
那么,为了训练自己的 Chat我们需要做那些事儿呢? 理论上需要如下步骤:
第一步:准备数据集
fine-tune 的目标通常有两种:
- 像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,让模型完成特定任务
- 语言填充,收集文本用于训练,让模型补全 prompt。
以第一种目标为例,假设我们的目标是让模型讲中文,那么,我们可以通过其他 LLM (如 text-davinci-003)把一个现有数据集(如 Alpaca)翻译为中文来做 fine-tune。实际上这个想法已经在开源社区已经有人实现了。
第二步:训练并 apply LoRA
在第一步准备的数据集上进行 fine-tune。
第三步:合并模型(可选)
合并 LoRA 与 base 可以加速推理,并帮助我们后续 Quantization 模型。
第四步:quantization(可选)
最后,Quantization 可以帮助我们加速模型推理,并减少推理所需内存。这方面也有开源的工具可以直接使用。
https://github.com/megvii-research/Sparsebit/blob/main/large_language_models/llama/quantization/README.md
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
实践
柿子挑软的捏,我们从简单的目标开始:让模型讲中文。
为了达成这个目标,我使用的数据集是 Luotuo 作者翻译的 Alpaca 数据集,训练代码主要来自 Alpaca-LoRA。
准备
由于我打算直接使用 Alpaca-LoRA 的代码,我们先 clone Alpaca-LoRA:
gitclonegit@github.com:tloen/alpaca-lora.git
下载数据集:
wgethttps://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json
创建虚拟环境并安装依赖(需要根据不同环境的 cuda 版本调整):
condacreate-nalpacapython=3.9
condaactivatealpaca
cdalpaca-lora
pipinstall-rrequirements.txt
训练
单卡选手很简单,可以直接执行:
pythonfinetune.py
--base_model'decapoda-research/llama-7b-hf'
--data_path'/path/to/trans_chinese_alpaca_data.json'
--output_dir'./lora-alpaca-zh'
双卡选手相对比较麻烦,需要执行:
WORLD_SIZE=2CUDA_VISIBLE_DEVICES=0,1torchrun
--nproc_per_node=2
--master_port=1234
finetune.py
--base_model'decapoda-research/llama-7b-hf'
--data_path'/path/to/trans_chinese_alpaca_data.json'
--output_dir'./lora-alpaca-zh'
在我的环境下(2 * RTX 3090 Ti 24GB),需要额外配置 micro_batch_size 避免 OOM。
--micro_batch_size2
推荐的其他额外参数:
--num_epochs2
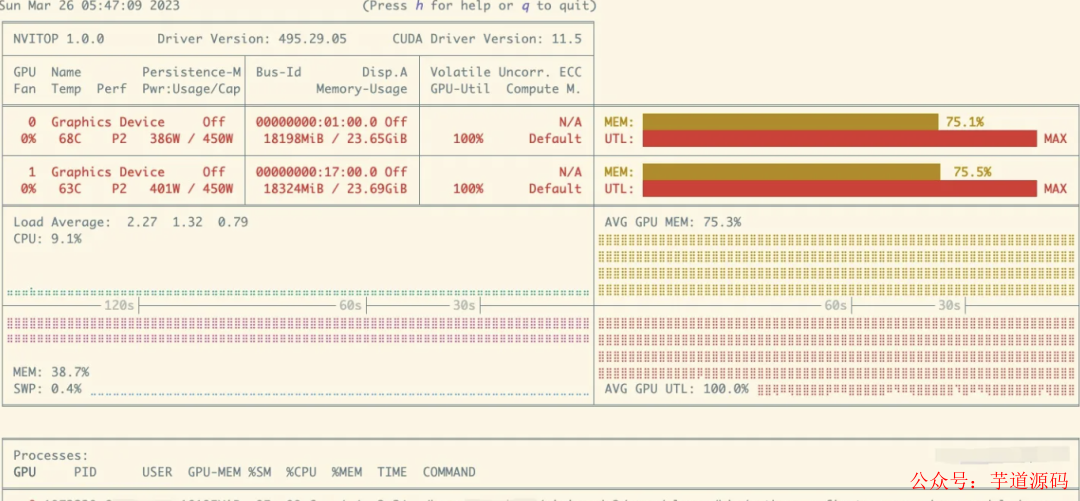
训练的过程比较稳定,我在训练过程中一直在用 nvitop 查看显存和显卡的用量:
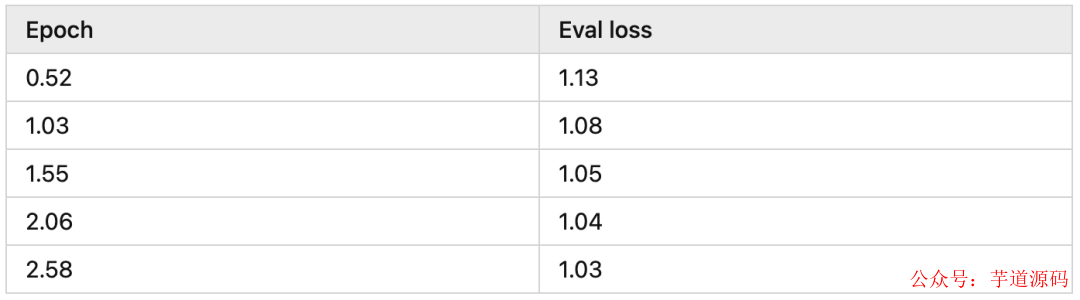
下面是我训练时模型收敛的情况,可以看到差不多 2 epochs 模型就收敛的差不多了:
推理
单卡选手可以直接执行:
pythongenerate.py--base_model"decapoda-research/llama-7b-hf"
--lora_weights'./lora-alpaca-zh'
--load_8bit
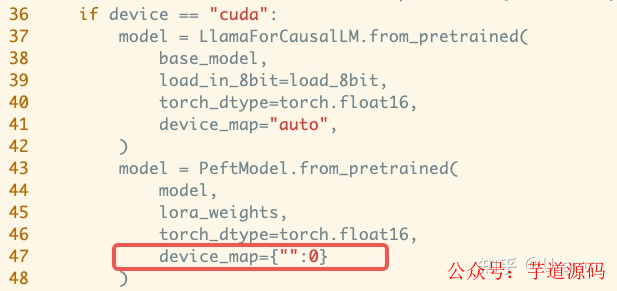
双卡选手还是会麻烦点,由于现在还不支持双卡推理,我手动修改了 generate.py,添加了第 47 行:
而后,执行上面的命令即可。
如果你的推理运行在服务器上,想要通过其他终端访问,可以给 launch 方法添加参数:
server_name="0.0.0.0"
此时打开浏览器,享受你的工作成果吧 :D
加速推理
Alpaca-LoRA 提供了一些脚本,如 export_hf_checkpoint.py 来合并模型。合并后的模型可以通过 llamap.cpp 等项目达到更好的推理性能。
测试
最后,让我们对比下原生 Alpaca 与自己 fine-tune 的 Alpaca,看看 fine-tune 到底有没有让模型学会讲中文吧!
Good Examples
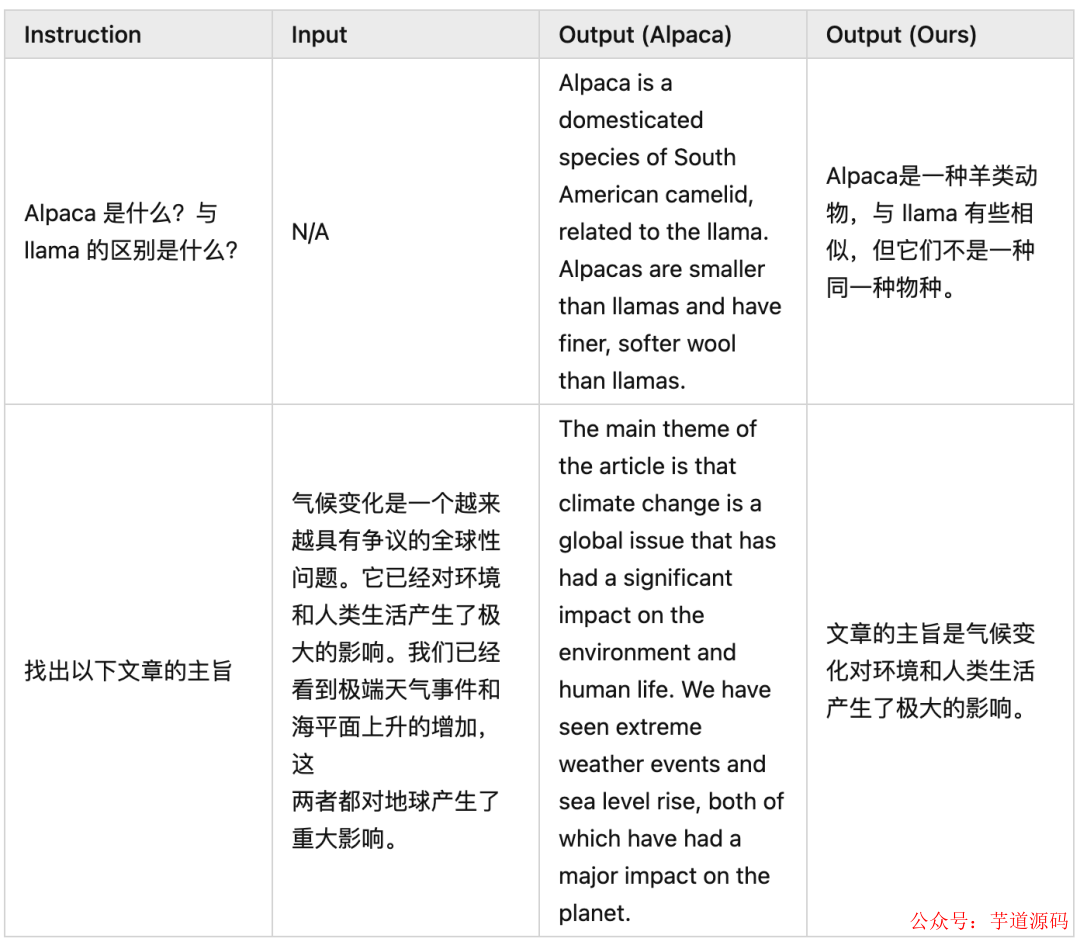
Bad Examples
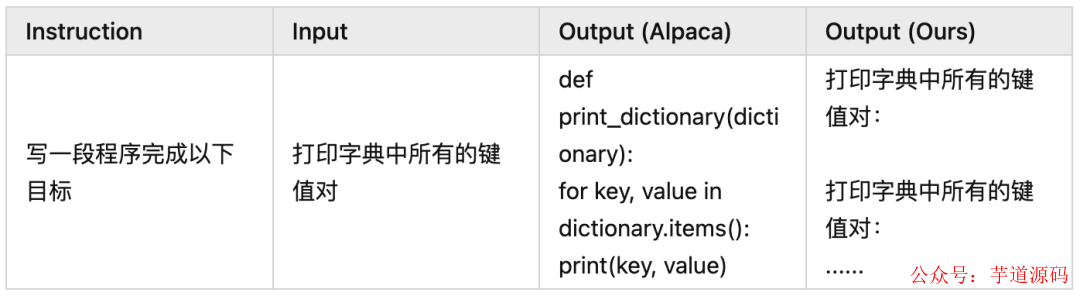
可以看出模型确实在讲中文,也能依据中文的指令和输入完成一些工作。但是由于 LLaMA 本身训练数据大部分为英文以及 Alpaca 数据集翻译后的质量不足,我们的模型有些时候效果不如原生 Alpaca。此时不得不感叹高质量数据对 LLM 的重要性 。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/yudao-cloud
- 视频教程:https://doc.iocoder.cn/video/
总结
作为一个分布式系统方向的工程师,fine-tune 一个 LLM 的过程遇到了不少问题,也有很多乐趣。虽然 LLaMA 7B 展现出的能力还比较有限,我还是很期待后面开源社区进一步的工作。
后续我也打算尝试 fine-tune 特定目的的 LLM,比如让 LLM 教我做饭,感兴趣的朋友可以保持关注!
审核编辑 :李倩
-
模型
+关注
关注
1文章
3818浏览量
52268 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
ChatGPT
+关注
关注
31文章
1600浏览量
10393
原文标题:如何训练自己的ChatGPT
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
类ChatGPT训练需高性能芯片大规模并联,高速接口IP迎红利时代
科技大厂竞逐AIGC,中国的ChatGPT在哪?
ChatGPT系统开发AI人功智能方案
chatgpt怎么用
ChatGPT使用初探

如何训练ChatGPT?中国版ChatGPT下月面世
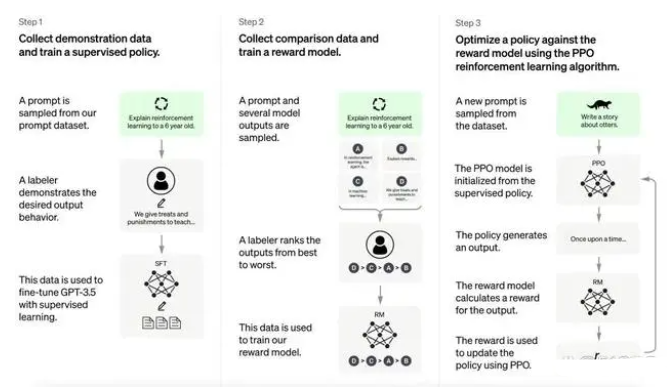
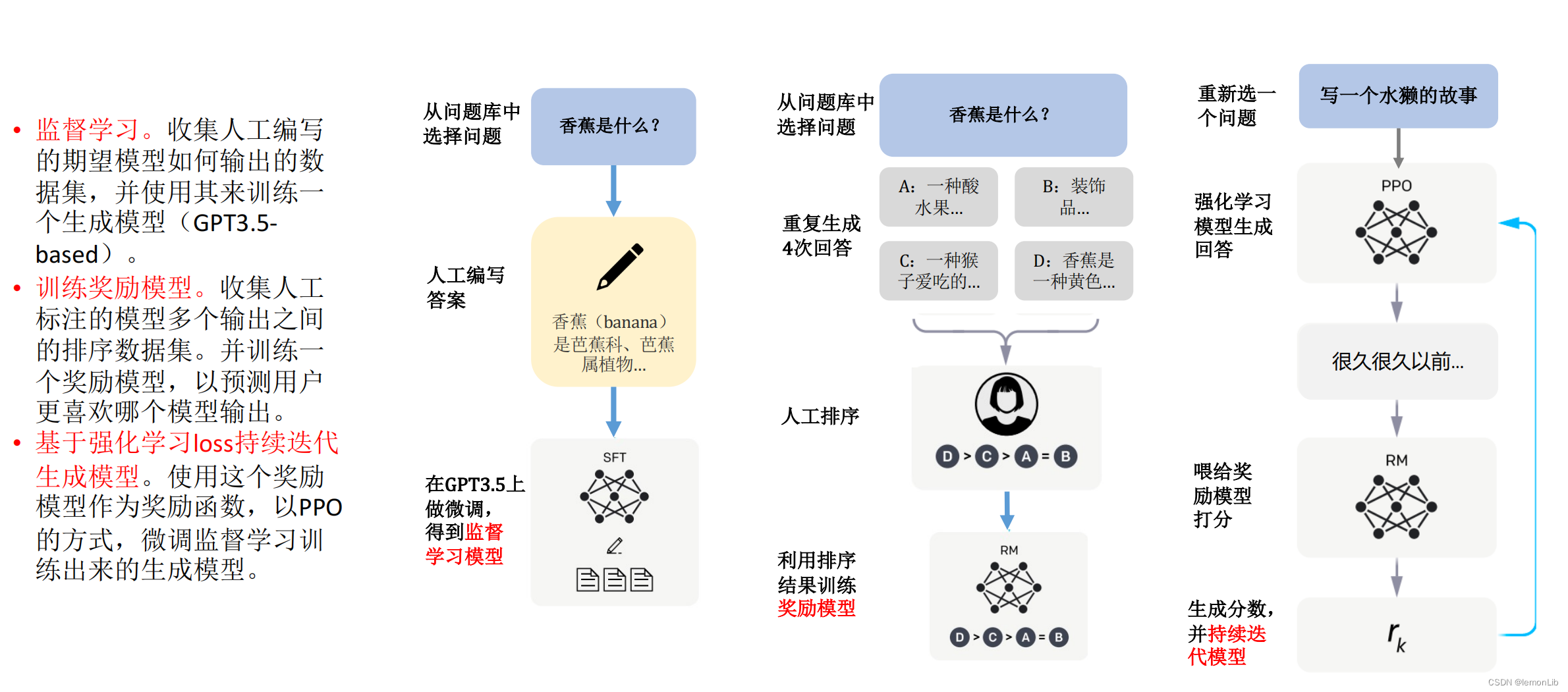
ChatGPT介绍和代码智能
如何打造我们自己的ChatGPT
ChatGPT是什么?ChatGPT写代码的原理你知道吗
chatgpt是什么原理
ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介



评论