 【AI周报20230317】 OpenAI公布GPT-4、国内存在哪些算力瓶颈
【AI周报20230317】 OpenAI公布GPT-4、国内存在哪些算力瓶颈

嵌入式 AI
AI 简报 20230317 期
1. AI服务器市场规模持续增加,国内存在哪些算力瓶颈?
原文:
https://mp.weixin.qq.com/s/v04vZCBxNzfCUDTy_8iSoA
近年来,在全球数字化、智能化的浪潮下,智能手机、自动驾驶、数据中心、图像识别等应用推动 AI服务器市场迅速成长。根据 IDC 数据,2021 年全球 AI 服务器市场规模已达到 145 亿美元,并预计 2025 年将超过 260 亿美元。
近段时间ChatGPT概念的火热,更是对算力基础设施的需求起到了带动作用。宁畅副总裁兼CTO赵雷此前在接受媒体采访的时候表示,ChatGP的训练和部署,都需要大量智能计算数据存储以及传输资源,计算机基础设施、算力等上游技术将因此受益。
ChatGPT有着多达1750亿个模型参数。在算力方面,GPT-3.5在训练阶段消耗的总算力约3640PF-days。在应用时,ChatGPT仍然需要大算力的服务器支持。ChatGPT的持续爆火也为AIGC带来全新增量,行业对AI模型训练所需要的算力支持提出了更高要求。
宁畅是一家集研发、生产、部署、运维一体的服务器厂商,及IT系统解决方案提供商。该公司早早就开始着重发力于人工智能服务器和液冷服务器。赵雷表示,公司目前在用的、在研的人工智能和液冷服务器,包括明年还将推出的浸没液冷服务器,刚好跟上算力高速增长的市场需求。公司随时准备着为客户提供合适的高算力产品和解决方案。
在人工智能服务器方面,宁畅已经推出多款产品,包括X620 G50、X660 G45、X640 G40、X620 G40。X620 G50适用于机器学习、AI推理、云计算、高性能计算等场景;660 G45是专门为深度学习训练开发的高性能计算平台;X640 G40是兼备训练与推理功能的全能型GPU服务器;X620 G40性能提升的同时支持PCIe 4.0高速总线技术,完美支持NVIDIA各类最新型GPU加速服务,是最为理想的AI推理平台。
在液冷服务器方面,宁畅推出了三款冷板式液冷服务器,包括产品B5000 G4 LP、X660 G45 LP、R620 G40 LP,范围覆盖了高密度、通用机架以及人工智能服务器产品,可满足科学计算、AI训练、云计算等众多IT应用场景,可满足用户不同需求。
作为服务器厂商需要给下游互联网客户提供怎样的产品和服务呢?对于服务器厂商来说,不只是要提供服务器硬件或者基础设施,还要有对应的服务能力。
从服务层面来看,在用户现场会关注什么呢,比如说核心业务,会关注业务的在线率,不管服务器坏不坏,整个业务的运行是要有弹性的、灵活的,不会给客户造成影响的。就以百度、微信这些业务为例,大家几乎不会看到微信不能用了,或者百度搜索不反馈结果了。
赵雷表示,对于服务器厂商来说,要做的是在服务层面能够快速响应,不管是采用现场备件模式,机房备机模式,还是驻场人员巡检的模式,都需要做到24小时的快速响应。这是纯粹的服务方面,也就是说,在互联网搭建业务连续性良好的基础上,服务器厂商能够将故障和快速维修的能力做到极致,有效地支撑客户的前端应用。
从产品层面来看,对于每个硬件子系统在设计研发过程中,都需要从易维修和低故障角度去思考如何将产品做得更好。宁畅在这方面做了很多工作:首先,现在冷却方式是影响故障率比较重要的因素,因为温度太高故障率就会高,宁畅的精密风冷和液冷的方式,能够有效地降低芯片和对应组件的故障率。
其次,其精密六维减震模式,能够有效提升硬盘的性能,降低故障率;接着是,采用DAE的散热器,从散热的维度有效降低光模块的故障率。同时CPU、GPU的液冷可以有效降低CPU、GPU的故障率;通过内存的漏斗,内存的故障筛选或者在线隔离技术,有效地降低内存的故障率;另外还在板卡走线、机箱结构方面进行了优化设计。
此外还有整机BMC易管理特性,赵雷认为,任何东西不可能不坏,有毛病是不可避免的,坏了以后,如何快速通知客户或者维护人员维修时关键。BMC有一个完善的通知机制,邮件自动通知、SMP远程告警、IPMI告警等。宁畅按照互联网客户的需求定制,将其融入整个机房的运维系统,出现故障以后可以第一时间通知去维修。
虽然目前国内有不少优秀的服务器、云厂商等,不过整体来看,国内的算力仍然存在瓶颈,比如,总体算力不够,算力的分布不平均。部分客户算力过剩,部分客户算力不足。或者A时间算力过剩,B时间算力不足,这是算力协调的问题。
短期来看这个问题要靠云技术解决,长期来看是要提供过剩的算力。也就是说,需要云技术去平衡协调算力不均匀的问题,还需要提供算力、算力效率等。
再比如算力成本高的问题,虽然目前每单位算力单价下降了,但是过去几年服务器的平均售价一直上涨。赵雷认为,可能算力类型单一,不太能够有效地支撑高速增长的模式,可能要有各种各样不同类型的算力。比如ChatGPT,是不是可以做针对GPT模型专门的ASIC。算力的应用类型越窄,它的效率就会越高,越通用,效率就越低。
整体而言,过去几年在全球数字化、智能化浪潮下,市场对算力的需求不断增加。ChatGP的出现更是让行业对算力提出了新的要求。国内服务器厂商在对人工智能行业提供算力支持方面已经有所准备。不过从目前的情况来看,国内在算力方面仍然存在一些瓶颈,比如算力分布不均匀,成本高等问题。后续还需业界共同去探讨解决。
2. PyTorch 2.0正式版发布!一行代码提速2倍,100%向后兼容
原文:
https://mp.weixin.qq.com/s/wC0Oixd3hSnH75DsPDTC-g
去年12月,PyTorch基金会在PyTorch Conference 2022上发布了PyTorch 2.0的第一个预览版本。
跟先前1.0版本相比,2.0有了颠覆式的变化。在PyTorch 2.0中,最大的改进是torch.compile。
新的编译器比以前PyTorch 1.0中默认的「eager mode」所提供的即时生成代码的速度快得多,让PyTorch性能进一步提升。

除了2.0之外,还发布了一系列PyTorch域库的beta更新,包括那些在树中的库,以及包括 TorchAudio、TorchVision和TorchText在内的独立库。TorchX的更新也同时发布,可以提供社区支持模式。
-torch.compile是PyTorch 2.0的主要API,它包装并返回编译后的模型,torch.compile是一个完全附加(和可选)的特性,因此2.0版本是100%向后兼容的。
-作为torch.compile的基础技术,带有Nvidia和AMD GPU的TorchInductor将依赖OpenAI Triton深度学习编译器来生成高性能代码,并隐藏低级硬件细节。OpenAI Triton生成的内核实现的性能,与手写内核和cublas等专门的cuda库相当。
-Accelerated Transformers引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。API与torch.compile () 集成,模型开发人员也可以通过调用新的scaled_dot_product_attention () 运算符,直接使用缩放的点积注意力内核。
-Metal Performance Shaders (MPS) 后端在Mac平台上提供GPU加速的PyTorch训练,并增加了对前60个最常用操作的支持,覆盖了300多个操作符。
-Amazon AWS优化了基于AWS Graviton3的C7g实例上的PyTorch CPU推理。与之前的版本相比,PyTorch 2.0提高了Graviton的推理性能,包括对Resnet50和Bert的改进。
-跨TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch和TorchInductor的新原型功能和技术。
3. OpenAI公布GPT-4:可在考试中超过90%的人类
原文:
https://mp.weixin.qq.com/s/YYZNYOUItGW18xAWk7In8Q
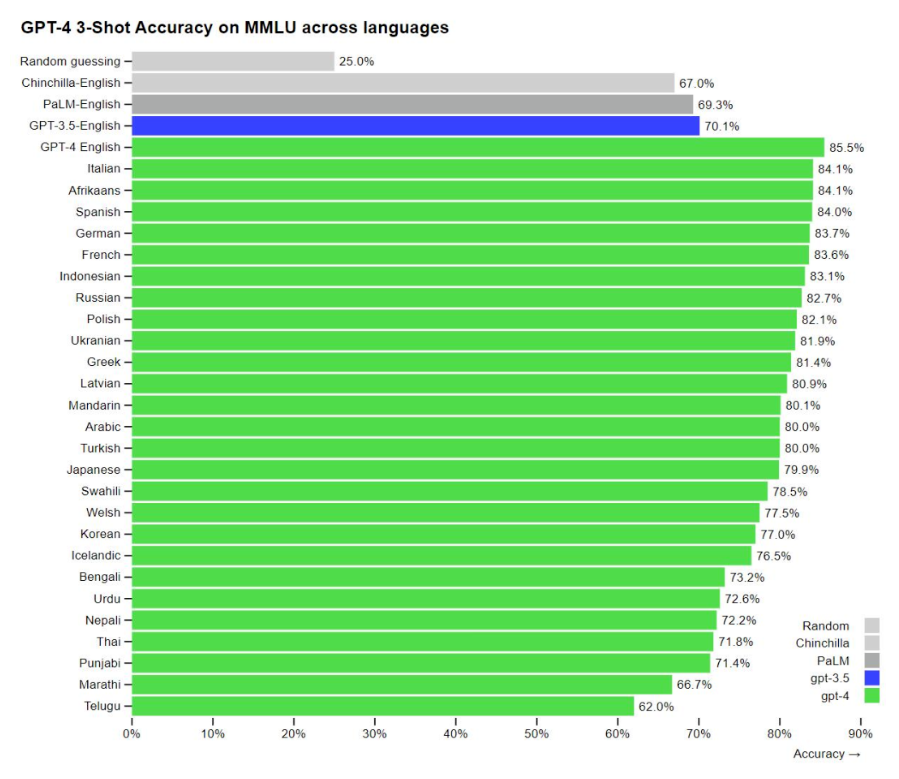
当地时间周二(3月14日),人工智能研究公司OpenAI公布了其大型语言模型的最新版本——GPT-4.该公司表示,GPT-4在许多专业测试中表现出超过绝大多数人类的水平。
OpenAI表示,我们已经创建了GPT-4,这是OpenAI在深度学习规模化方面的最新里程碑。GPT-4是一个大型的多模型模型(接受图像和文本输入、输出文本),虽然在许多现实场景中不如人类聪明,但在各种专业和学术基准测试中表现出人类水平的性能。
看起来,现在的 GPT 已经不会在计算上胡言乱语了:

还是个物理题:

GPT-4 看懂了法语题目,并完整解答:

GPT-4 可以理解一张照片里「有什么不对劲的地方」:

OpenAI于2020年发布了GPT(生成型预训练变换模型)-3(生成型预训练变换模型),并将其与GPT-3.5分别用于创建Dall-E和聊天机器人ChatGPT,这两款产品极大地吸引了公众的关注,并刺激其他科技公司更积极地追求人工智能(AI)。OpenAI周二表示,在内部评估中,相较于GPT-3.5,GPT-4产生正确回应的可能性要高出40%。而且GPT-4是多模态的,同时支持文本和图像输入功能。
OpenAI称,GPT-4比以前的版本“更大”,这意味着其已经在更多的数据上进行了训练,并且在模型文件中有更多的权重,这使得它的运行成本更高。
据OpenAI介绍,在某些情况下,GPT-4比之前的GPT-3.5版本有了巨大改进,新模型将产生更少的错误答案,更少地偏离谈话轨道,更少地谈论禁忌话题,甚至在许多标准化测试中比人类表现得更好。
例如,GPT-4在模拟律师资格考试的成绩在考生中排名前10%左右,在SAT阅读考试中排名前7%左右,在SAT数学考试中排名前11%左右。
OpenAI表示,虽然两个版本在日常对话中看起来很相似,但当任务复杂到一定程度时,差异就表现出来了,GPT-4更可靠、更有创造力,能够处理更微妙的指令。
不过,OpenAI也警告称,GPT-4还不完美,在许多情况下,它的能力不如人类。该公司表示:“GPT-4仍有许多已知的局限性,我们正在努力解决,比如社会偏见、幻觉和对抗性提示。”
OpenAI透露,摩根士丹利正在使用GPT-4来组织数据,而电子支付公司Stripe正在测试GPT-4是否有助于打击欺诈。其他客户还包括语言学习公司Duolingo、Khan Academy和冰岛政府。
OpenAI合作伙伴微软周二表示,新版必应搜索引擎将使用GPT-4。
4. 物理学家狂喜的AI工具开源了!靠实验数据直接发现物理公式,笔记本就能跑
原文:
https://mp.weixin.qq.com/s/0eGiiWdKUyQcg54azY5evg
一个让物理学家狂喜的AI工具,在GitHub上开源了!它名叫Φ-SO ,能直接从数据中找到隐藏的规律,而且一步到位,直接给出对应公式。
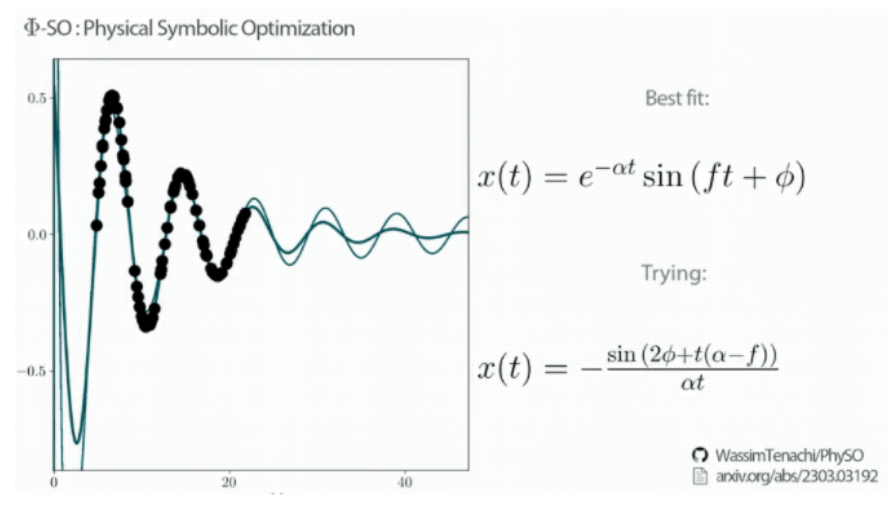
整个过程也不需要动用超算,一台笔记本大概4个小时就能搞定爱因斯坦的质能方程。

这项成果来自德国斯特拉斯堡大学与澳大利亚联邦科学与工业研究组织Data61部门,据论文一作透露,研究用了1.5年时间,受到学术界广泛关注。代码一经开源,涨星也是飞快。
除了物理学者直呼Amazing之外,还有其他学科研究者赶来探讨,能不能把同款方法迁移到他们的领域。
强化学习+物理条件约束
Φ-SO背后的技术被叫做“深度符号回归”,使用循环神经网络(RNN)+强化学习实现。
首先将前一个符号和上下文信息输入给RNN,预测出后一个符号的概率分布,重复此步骤,可以生成出大量表达式。
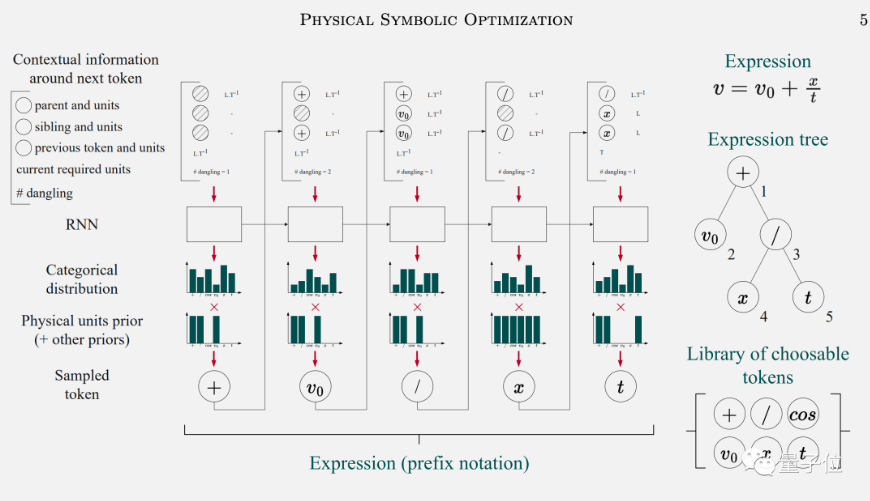
同时将物理条件作为先验知识纳入学习过程中,避免AI搞出没有实际含义的公式,可以大大减少搜索空间。
再引入强化学习,让AI学会生成与原始数据拟合最好的公式。
与强化学习用来下棋、操控机器人等不同,在符号回归任务上只需要关心如何找到最佳的那个公式,而不关心神经网络的平均表现。
于是强化学习的规则被设计成,只对找出前5%的候选公式做奖励,找出另外95%也不做惩罚,鼓励模型充分探索搜索空间。
研究团队用阻尼谐振子解析表达式、爱因斯坦能量公式,牛顿的万有引力公式等经典公式来做实验。
Φ-SO都能100%的从数据中还原这些公式,并且以上方法缺一不可。研究团队在最后表示,虽然算法本身还有一定改进空间,不过他们的首要任务已经改成用新工具去发现未知的物理规律去了。
读到这,小编有一个不成熟的想法….
5. 扩散模型大杀器 ControlNet 解析
原文:
https://mp.weixin.qq.com/s/_7su0EX-eBbeyV0V8o3cLg
标题:Adding Conditional Control to Text-to-Image Diffusion Models
作者:Lvmin Zhang, Maneesh Agrawala
原文链接:
https://arxiv.org/pdf/2302.05543.pdf
代码链接:
https://github.com/lllyasviel/ControlNet
大型文本到图像模型的存在让人们意识到人工智能的巨大潜力,这些模型可以通过用户输入简短的描述性提示来生成视觉上吸引人的图像。然而,对于一些长期存在、具有明确问题表述的任务(例如图像处理),我们可能会有一些问题需要回答。这些问题包括:这种基于提示的控制是否满足我们的需求?在特定任务中,这些大型模型能否应用于促进这些特定任务?我们应该建立什么样的框架来处理广泛的问题条件和用户控制?在特定任务中,大型模型能否保留从数十亿张图片中获得的优势和能力?为了回答这些问题,作者们调查了各种图像处理应用,并得出了三个发现。第一个发现是,在特定任务领域中可用的数据规模并不总是与通用图像-文本领域中相同。第二个发现是,对于一些特定任务,需要更加精细的控制和指导,而不仅仅是简单的提示。第三个发现是,在特定任务中,大型模型可能会面临过拟合和泛化能力不足等问题。为了解决这些问题,作者们提出了一种名为ControlNet的框架,该框架可以根据用户提供的提示和控制来生成高质量的图像,并且可以在特定任务中进行微调以提高性能。
与之相关的主要工作有HyperNetwork和Stable Diffusion。HyperNetwork是一种用于训练神经网络的方法,它可以通过一个小型的神经网络来影响一个更大的神经网络的权重。HyperNetwork已经在图像生成等领域取得了成功,并且已经有多篇相关论文发表。另外,Stable Diffusion是一种用于图像生成和编辑的技术,它可以通过扩散过程来生成高质量、多样化的图像,并且可以通过附加小型神经网络来改变其艺术风格。ControlNet和HyperNetwork之间的相似之处在于它们都可以影响神经网络的行为,从而实现特定任务的目标。具体来说,HyperNetwork使用一个小型的神经网络来影响一个更大的神经网络的权重,从而改变其行为。而ControlNet则是将大型图像扩散模型中的权重克隆到一个“可训练副本”和一个“锁定副本”中,其中锁定副本保留了从数十亿张图像中学习到的网络能力,而可训练副本则在特定数据集上进行训练以学习条件控制。此外,它们在影响神经网络行为方面的共同点是它们都使用了小型神经网络来对大型神经网络进行控制。这种方法可以使得大型神经网络更加灵活和适应性强,并且可以根据不同任务和条件进行调整和优化。ControlNet与其他相关工作之间的优势主要体现在以下几个方面:
-
控制方式不同:ControlNet通过控制神经网络中的输入条件来影响其行为,而其他相关工作则可能采用不同的控制方式,例如直接修改权重或者使用外部约束等。
-
可解释性更强:ControlNet可以通过可视化输入条件和输出结果之间的关系来解释其行为,从而更好地理解神经网络的内部机制。这对于一些需要可解释性的任务非常重要。
-
适应性更强:ControlNet可以根据不同任务和条件进行调整和优化,从而使得神经网络更加灵活和适应性强。这对于一些复杂、多变的任务非常重要。
-
训练效果更好:ControlNet可以通过使用锁定副本来保留从数十亿张图像中学习到的网络能力,并将其与可训练副本进行结合来进行训练。这种方法可以使得训练效果更好,并且可以避免过拟合等问题。
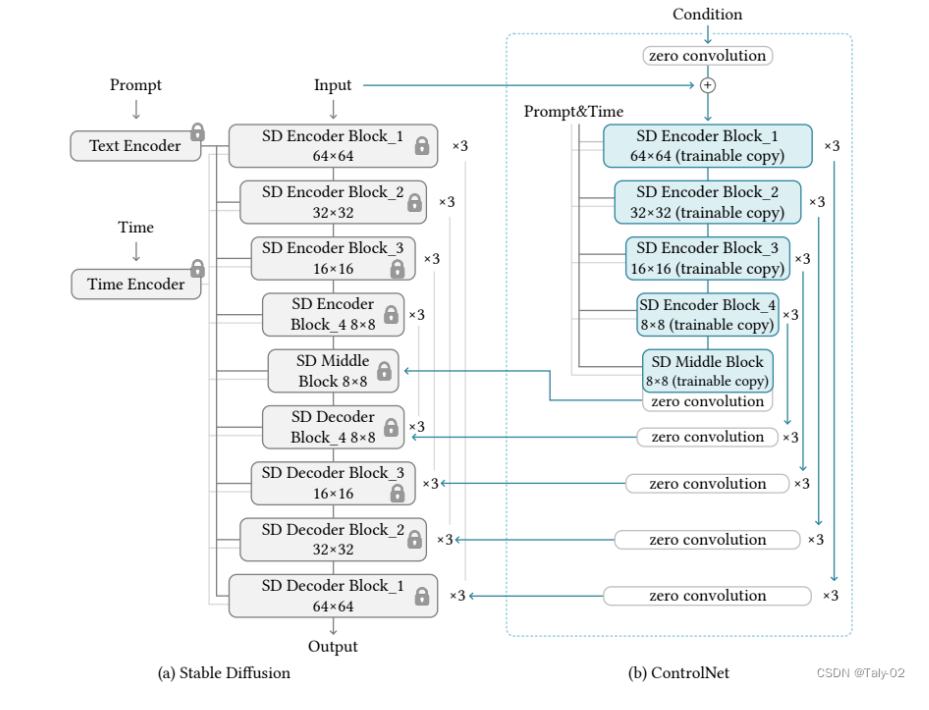
我们尽量少用公式进行表达,主要的技术细节和设定可以参考论文。ControlNet是一种神经网络架构,可以通过特定任务的条件来增强预训练的图像扩散模型。该方法包括几个关键组件,包括预训练模型的“可训练副本”和“锁定副本”,以及一组输入条件,可以用来控制输出。整个过程可以概括如下:
-
克隆预训练模型:ControlNet首先创建了预训练图像扩散模型的两个副本,其中一个是“锁定”的,不能被修改,而另一个是“可训练”的,可以在特定任务上进行微调。ControlNet使用了一种称为“权重共享”的技术,该技术可以将预训练模型的权重复制到两个不同的神经网络中。这样,在微调可训练副本时,锁定副本仍然保留着从预训练中学到的通用知识,并且可以提供更好的初始状态。需要注意的是,在克隆预训练模型之前,需要先选择一个适合特定任务的预训练模型,并对其进行必要的调整和优化。这样才能确保克隆出来的模型能够更好地适应特定任务,并取得更好的效果。
-
定义输入条件:ControlNet然后定义了一组输入条件,可以用来控制模型的输出。这些条件可能包括颜色方案、对象类别或其他特定任务参数。该技术可以将输入条件与预训练模型进行连接,并将其作为额外的输入信息传递给神经网络。这样,在微调可训练副本时,神经网络可以根据这些输入条件来调整输出结果,并更好地适应特定任务。需要注意的是,在定义输入条件之前,需要先确定哪些参数对于特定任务是最重要的,并选择合适的方式来表示这些参数。例如,在图像分类任务中,可能需要考虑对象类别、颜色和纹理等因素,并选择合适的方式来表示它们。同时,还需要确保这些输入条件能够被有效地传递给神经网络,并且不会对模型性能产生负面影响。
-
训练可训练副本:ControlNet然后使用反向传播和其他标准训练技术,在特定数据集上对可训练副本进行训练。很自然的就是一个标准的神经网络训练流程。训练可训练副本之前,需要先选择一个适合特定任务的预训练模型,并将其克隆为可训练副本。同时还需要确定哪些输入条件对于特定任务是最重要的,并将其与预训练模型进行连接。
-
合并输出:最后,ControlNet将两个模型副本的输出组合起来,产生一个最终结果,既包含从预训练中学到的通用知识,也包含从微调中学到的特定知识。
这种方法自然是要看可视化展示的:
总的来说,ControlNet是一种新颖的神经网络架构,可以通过微调预训练模型来适应特定任务,并在多个基准数据集上取得了非常好的性能表现。该方法使用条件控制技术将输入条件与预训练模型进行连接,并将其作为额外的输入信息传递给神经网络,从而帮助神经网络更好地理解输入条件,并取得更好的效果。同时,ControlNet还探讨了不同因素对其性能的影响,例如不同输入条件、不同预训练模型和不同微调策略等。实验结果表明,在多个基准数据集上,ControlNet都取得了非常好的性能表现,并且在图像分类、图像生成和图像检索等任务中也有广泛应用。因此,我们相信ControlNet是一种非常有前景和实用价值的神经网络架构,并且在未来会有更广泛的应用。
6. CVPR 2023|EMA-VFI: 基于帧间注意力提取运动和外观信息的高效视频插帧
https://mp.weixin.qq.com/s/w7xCUBedykOmI9Bq6lQ4Ow
论文链接:
https://arxiv.org/abs/2303.00440
代码链接:
https://github.com/MCG-NJU/EMA-VFI
1. 研究动机
视频插帧(Video Frame Interpolation, VFI)任务的目标是给定连续的两帧,生成这两帧之间的固定时刻的帧或者任意时刻的帧。顾名思义,VFI最直接的用途就是用来提高帧率,经常和视频超分方法用来同时提升视频的空间和时间上的分辨率。VFI和其他常见的视频修复任务(如视频超分、视频去噪等)最大的不同就是VFI任务要生成原本不存在的帧,而其他视频修复任务要修复一张原本存在的帧,这样的不同也让插帧任务的设计思路无法直接借鉴视频复原方法的思路。
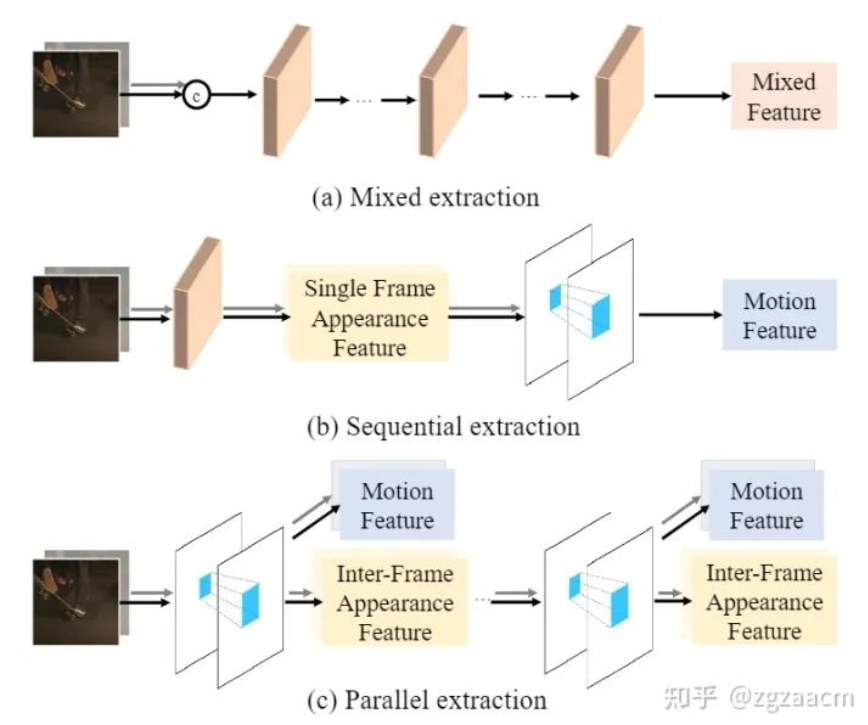
为了生成两帧之间的某一帧,从直觉上理解,VFI算法首先需要建模两帧之间的运动关系,然后将两帧中对应区域的外观信息依靠建立好的运动关系汇聚到要生成的帧上。因此,设计高效地提取两帧之间的运动信息和外观信息的方法对于一个好的VFI算法来说是至关重要的。经过充分调研,我们发现目前VFI算法提取这两种信息的方式可以分为两类,如图1。
第一种范式(如图1中的(a)),也是最常见的一类设计,直接将两帧按通道拼在一起,经过重复的网络模块提取出特征,这个特征既用来建模运动也用来表征外观,我们在此将这样的提取范式称为混合提取(mixed extraction)。尽管混合提取范式设计十分简洁,但因为要隐式地提取两种信息,往往对特征提取模块的设计和容量都有较高的要求。同时,因为没有显示的运动信息,也无法直接得到任意时刻运动建模所需的运动信息,这种范式限制了任意时刻插帧的能力。
第二种范式(如图1中的(b)),采用了串行提取两种信息的思路,首先先提取每一帧的单独的外观信息,再利用两者的外观信息提取运动信息。这种提取范式需要针对每一种信息单独设计提取模块,往往会引入额外计算开销,并且无法像混合提取范式一样只需堆叠相同的模块就可以提升性能。同时,这样得到的外观特征没有很好地进行帧间信息的交互,而这种交互对于生成中间帧是至关重要的。
这里我们提出了疑问:是否存在能够同时显式地提取两种信息,且设计简洁有效的范式呢?如图1中的(c),我们希望设计一个模块,能够同时显式地提取运动信息和两帧之间交互过的外观信息,并且可以像混合提取范式一样只需通过控制模块的个数和容量来控制性能。
2. 方法介绍
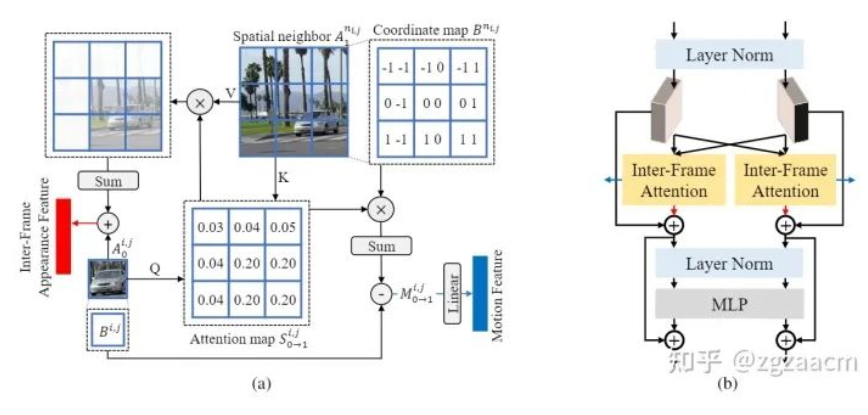
利用帧间注意力(Inter-Frame Attention, IFA)提取两种特征
在本文中,我们提出利用帧间的注意力机制来同时提取运动信息和两帧之间的交互过的外观信息。具体来说,如图2中的(a),对于当前帧中的任何一个区域,我们将其作为注意力机制中的查询(query),并将其在另一帧的空间上的相邻的所有区域作为键和值(key&value)来推导出代表其当前区域与另一帧相邻区域的注意力图。随后,该注意力图被用来汇总邻居的外观特征,并和当前区域的外观特征进行聚合,从而得到同一个区域在两帧不同位置的外观信息的聚合特征(Inter-Frame Appearance Feature)。此外,注意力图也被用来对另一帧的相邻区域的位移进行加权,以获得当前区域从当前帧到相邻帧的近似运动向量(Motion Vector),并经过一个线性层得到两帧之间的运动特征。
这样,通过一次注意力操作,我们通过注意力图的复用同时独立的提取出了两种特征。值得注意的是,这样得到的外观特征没有混淆位置信息,所以可以进一步在此基础上提取新的外观信息和运动信息。遵循目前主流的结构设计思路,我们将帧间注意力机制放在了Transformer的结构中,如图2中的(b)。这样的设计让我们只需要改变特征的通道数和Transformer block的个数就能控制提取的两种特征的质量和多样性。(具体细节请参考原文)
3. 实验结果
关于固定插帧(生成两帧之间的中间帧)的性能比较如图5:
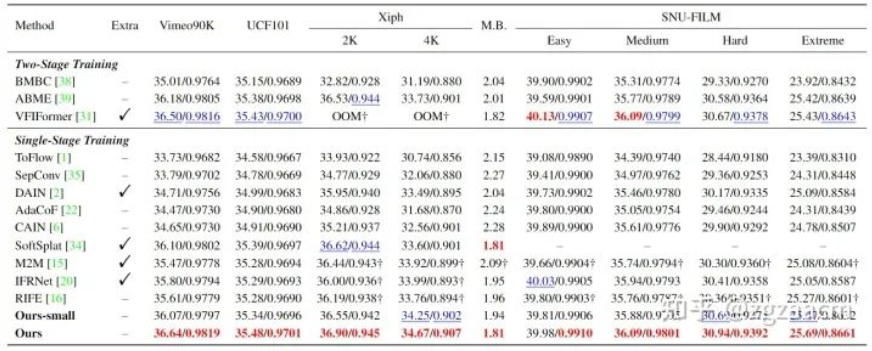
关于任意时刻插帧的性能比较如图6:
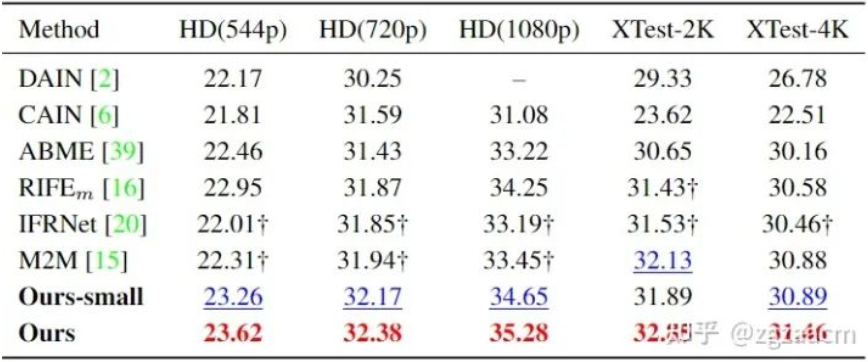
可以从结果看出来我们提出方法在两个子任务的不同数据集上都有较大的性能提升。图7是和之前SOTA方法VFIFormer的运行速度和占用内存的比较,我们的方法随着输入尺寸的增大,计算开销有了成倍的减少:
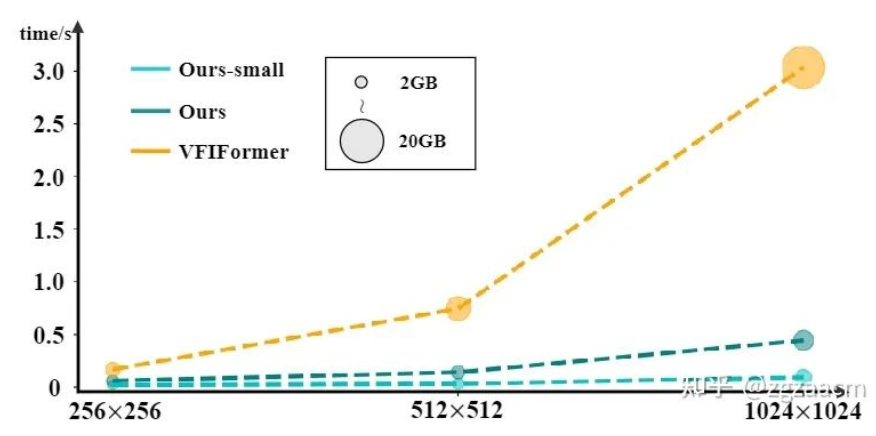
4. 局限&未来展望
虽然我们提出的方法已经取得了不小的改进,但仍有一些局限性值得探索。首先,尽管混合CNN和Transformer的设计可以减轻计算开销,但它也限制了在的高分辨率外观特征下利用IFA进行运动信息的提取。其次,我们的方法的输入仅限于两个连续的帧,这导致无法利用来自多个连续帧的信息。在未来的工作中,我们会尝试在不引入过多计算开销的情况下将我们的方法扩展到多帧的输入。同时,因为我们提出的能够同时提取运动和外观信息的IFA模块对于视频的不同任务都是通用的,我们也将研究如何将帧间注意应用于其他同样需要这两类信息的领域,如动作识别和动作检测。
7. 模型训练过程中,混合精度训练稳定性解决方案
原文:
https://mp.weixin.qq.com/s/9qfyncdq_UfiKGM73ekthQ
混合精度已经成为训练大型深度学习模型的必要条件,但也带来了许多挑战。将模型参数和梯度转换为较低精度数据类型(如FP16)可以加快训练速度,但也会带来数值稳定性的问题。使用进行FP16 训练梯度更容易溢出或不足,导致优化器计算不精确,以及产生累加器超出数据类型范围的等问题。
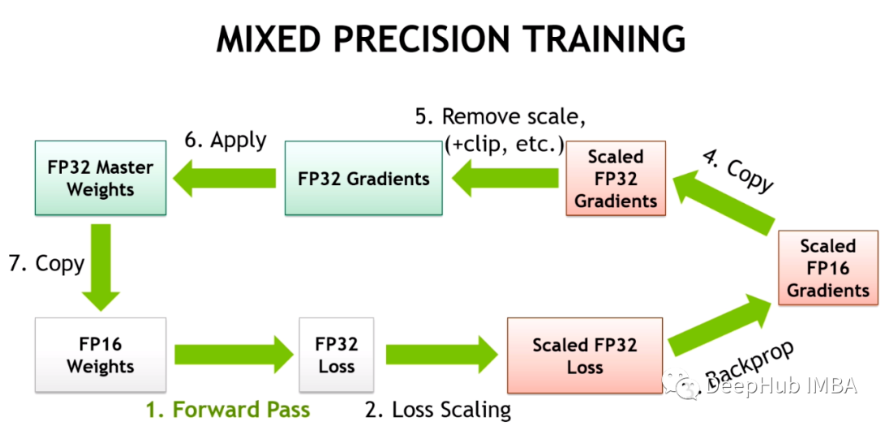
在这篇文章中,我们将讨论混合精确训练的数值稳定性问题。为了处理数值上的不稳定性,大型训练工作经常会被搁置数天,会导致项目的延期。所以我们可以引入Tensor Collection Hook来监控训练期间的梯度条件,这样可以更好地理解模型的内部状态,更快地识别数值不稳定性。在早期训练阶段了解模型的内部状态可以判断模型在后期训练中是否容易出现不稳定是非常好的办法,如果能够在训练的头几个小时就能识别出梯度不稳定性,可以帮助我们提升很大的效率。所以本文提供了一系列值得关注的警告,以及数值不稳定性的补救措施。
混合精度训练
随着深度学习继续向更大的基础模型发展。像GPT和T5这样的大型语言模型现在主导着NLP,在CV中对比模型(如CLIP)的泛化效果优于传统的监督模型。特别是CLIP的学习文本嵌入意味着它可以执行超过过去CV模型能力的零样本和少样本推理,训练这些模型都是一个挑战。
这些大型的模型通常涉及深度transformers网络,包括视觉和文本,并且包含数十亿个参数。GPT3有1750亿个参数,CLIP则是在数百tb的图像上进行训练的。模型和数据的大小意味着模型需要在大型GPU集群上进行数周甚至数月的训练。为了加速训练减少所需gpu的数量,模型通常以混合精度进行训练。
混合精确训练将一些训练操作放在FP16中,而不是FP32。在FP16中进行的操作需要更少的内存,并且在现代gpu上可以比FP32的处理速度快8倍。尽管在FP16中训练的大多数模型精度较低,但由于过度的参数化它们没有显示出任何的性能下降。
随着英伟达在Volta架构中引入Tensor Cores,低精度浮点加速训练更加快速。因为深度学习模型有很多参数,任何一个参数的确切值通常都不重要。通过用16位而不是32位来表示数字,可以一次性在Tensor Core寄存器中拟合更多参数,增加每个操作的并行性。
但FP16的训练是存在挑战性的。因为FP16不能表示绝对值大于65,504或小于5.96e-8的数字。深度学习框架例如如PyTorch带有内置工具来处理FP16的限制(梯度缩放和自动混合精度)。但即使进行了这些安全检查,由于参数或梯度超出可用范围而导致大型训练工作失败的情况也很常见。深度学习的一些组件在FP32中发挥得很好,但是例如BN通常需要非常细粒度的调整,在FP16的限制下会导致数值不稳定,或者不能产生足够的精度使模型正确收敛。这意味着模型并不能盲目地转换为FP16。
所以深度学习框架使用自动混合精度(AMP),它通过一个预先定义的FP16训练安全操作列表。AMP只转换模型中被认为安全的部分,同时将需要更高精度的操作保留在FP32中。另外在混合精度训练中模型中通过给一些接近于零梯度(低于FP16的最小范围)的损失乘以一定数值来获得更大的梯度,然后在应用优化器更新模型权重时将按比例向下调整来解决梯度过小的问题,这种方法被称为梯度缩放。
下面是PyTorch中一个典型的AMP训练循环示例。

梯度缩放器scaler会将损失乘以一个可变的量。如果在梯度中观察到nan,则将倍数降低一半,直到nan消失,然后在没有出现nan的情况下,默认每2000步逐渐增加倍数。这样会保持梯度在FP16范围内,同时也防止梯度变为零。
训练不稳定的案例
尽管框架都尽了最大的努力,但PyTorch和TensorFlow中内置的工具都不能阻止在FP16中出现的数值不稳定情况。
在HuggingFace的T5实现中,即使在训练之后模型变体也会产生INF值。在非常深的T5模型中,注意力值会在层上累积,最终达到FP16范围之外,这会导致值无穷大,比如在BN层中出现nan。他们是通过将INF值改为在FP16的最大值解决了这个问题,并且发现这对推断的影响可以忽略不计。
另一个常见问题是ADAM优化器的限制。作为一个小更新,ADAM使用梯度的第一和第二矩的移动平均来适应模型中每个参数的学习率。
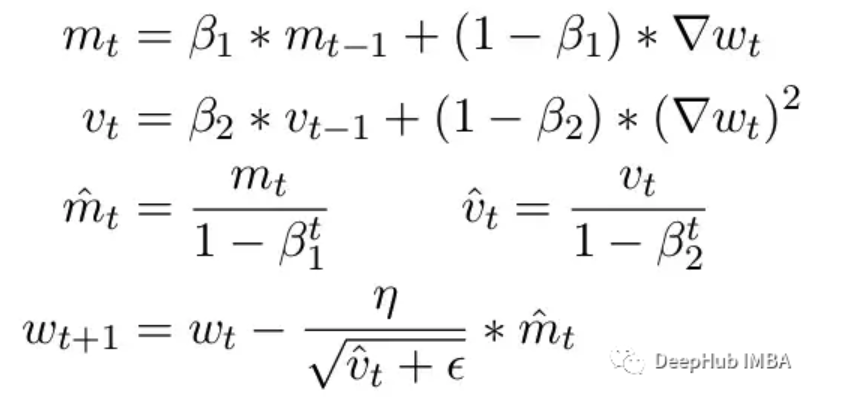
这里Beta1 和 Beta2 是每个时刻的移动平均参数,通常分别设置为 .9 和 .999。用 beta 参数除以步数的幂消除了更新中的初始偏差。在更新步骤中,向二阶矩参数添加一个小的 epsilon 以避免被零除产生错误。epsilon 的典型默认值是 1e-8。但 FP16 的最小值为 5.96e-8。这意味着如果二阶矩太小,更新将除以零。所以在 PyTorch 中为了训练不会发散,更新将跳过该步骤的更改。但问题仍然存在尤其是在 Beta2=.999 的情况下,任何小于 5.96e-8 的梯度都可能会在较长时间内停止参数的权重更新,优化器会进入不稳定状态。
ADAM的优点是通过使用这两个矩,可以调整每个参数的学习率。对于较慢的学习参数,可以加快学习速度,而对于快速学习参数,可以减慢学习速度。但如果对多个步骤的梯度计算为零,即使是很小的正值也会导致模型在学习率有时间向下调整之前发散。
另外PyTorch目前还一个问题,在使用混合精度时自动将epsilon更改为1e-7,这可以帮助防止梯度移回正值时发散。但是这样做会带来一个新的问题,当我们知道梯度在相同的范围内时,增加ε会降低了优化器适应学习率的能力。所以盲目的增加epsilon也不能解决由于零梯度而导致训练停滞的情况。
关于这一主题,还有非常多需要注意和学习的地方,感兴趣的小伙伴可以点击查看原文。
8. YOLOv7默默更新Anchor-Free,无痛再涨1.4个mAP!
原文:
https://mp.weixin.qq.com/s/z-lx-yYvI5kFKdLfbDoSOA
YOLOv7-u6分支的实现是基于Yolov5和Yolov6进行的。并在此基础上开发了Anchor-Free方法。所有安装、数据准备和使用与Yolov5相同,大家可以酌情尝试,如果电费不要钱,那就不要犹豫了!!!
先看原始的YOLOv7的精度
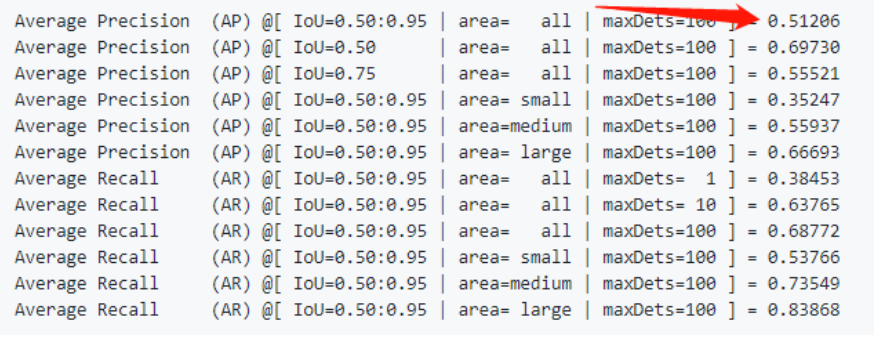
当时原始版本就是无敌的存在,YOLOv7的base版本就有51.2的精度了!!!
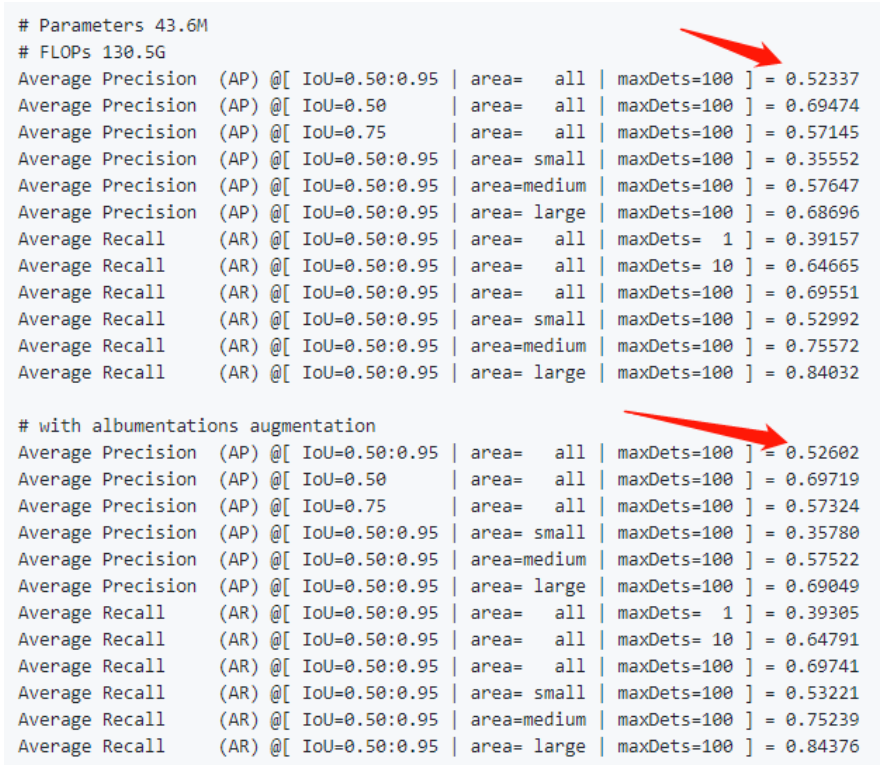
再看原作复现的Anchor-Free版本,相对于原始版本的51.2的精度,分别提升了1.1个点和1.4个点(使用了albumentation数据增强),可以看出还是很给力的结构。
架构改进部分
其实,关于复现的YOLOv7-u6(Anchor-Free),Backbone和Neck部分是没有发生变化的,下面看一下Head部分的变化。
1、YOLOv7的Anchor-Base Head
通过下图的YAML知道,YOLOv7的head使用了重参结构,并且也加入了隐藏知识Trick的加入。

2、YOLOv7的Anchor-Free Head
去除了RepConv卷积,使用了最为基本的Conv模块,同时检测头换为了YOLOv6的Head形式,同时加入了IDetect的隐藏知识Implicit层思想。
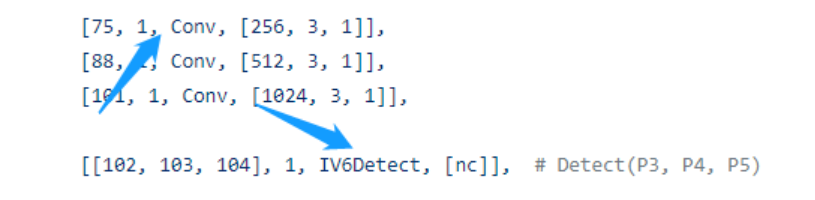
3、IV6Detect的实现如下
classIV6Detect(nn.Module):
dynamic=False#forcegridreconstruction
export=False#exportmode
shape=None
anchors=torch.empty(0)#init
strides=torch.empty(0)#init
def__init__(self,nc=80,ch=(),inplace=True):#detectionlayer
super().__init__()
self.nc=nc#numberofclasses
self.nl=len(ch)#numberofdetectionlayers
self.reg_max=16
self.no=nc+self.reg_max*4#numberofoutputsperanchor
self.inplace=inplace#useinplaceops(e.g.sliceassignment)
self.stride=torch.zeros(self.nl)#stridescomputedduringbuild
c2,c3=max(ch[0]//4,16),max(ch[0],self.no-4)#channels
self.cv2=nn.ModuleList(
nn.Sequential(Conv(x,c2,3),Conv(c2,c2,3),nn.Conv2d(c2,4*self.reg_max,1))forxinch)
self.cv3=nn.ModuleList(
nn.Sequential(Conv(x,c3,3),Conv(c3,c3,3),nn.Conv2d(c3,self.nc,1))forxinch)
#DFL层
self.dfl=DFL(self.reg_max)
#Implicit层
self.ia2=nn.ModuleList(ImplicitA(x)forxinch)
self.ia3=nn.ModuleList(ImplicitA(x)forxinch)
self.im2=nn.ModuleList(ImplicitM(4*self.reg_max)for_inch)
self.im3=nn.ModuleList(ImplicitM(self.nc)for_inch)
defforward(self,x):
shape=x[0].shape#BCHW
foriinrange(self.nl):
x[i]=torch.cat((self.im2[i](self.cv2[i](self.ia2[i](x[i]))),self.im3[i](self.cv3[i](self.ia3[i](x[i])))),1)
box,cls=torch.cat([xi.view(shape[0],self.no,-1)forxiinx],2).split((self.reg_max*4,self.nc),1)
ifself.training:
returnx,box,cls
elifself.dynamicorself.shape!=shape:
self.anchors,self.strides=(x.transpose(0,1)forxinmake_anchors(x,self.stride,0.5))
self.shape=shape
dbox=dist2bbox(self.dfl(box),self.anchors.unsqueeze(0),xywh=True,dim=1)*self.strides
y=torch.cat((dbox,cls.sigmoid()),1)
returnyifself.exportelse(y,(x,box,cls))
defbias_init(self):
m=self#self.model[-1]#Detect()module
fora,b,sinzip(m.cv2,m.cv3,m.stride):#from
a[-1].bias.data[:]=1.0#box
b[-1].bias.data[:m.nc]=math.log(5/m.nc/(640/s)**2)
关于损失函数与样本匹配的穿搭
一句话吧,其实就是YOLOv8本来的样子,也可能YOLOv8是原来YOLOv7-u6本来的样子。使用了TaskAligned Assigner,BCE Loss、CIOU Loss以及DFL Loss。可以说是标准搭配了!!!关于损失函数与样本匹配的穿搭
classComputeLoss:
def__init__(self,model,use_dfl=True):
device=next(model.parameters()).device#getmodeldevice
h=model.hyp#hyperparameters
#Definecriteria
#分类损失
BCEcls=nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]],device=device),reduction='none')
#Classlabelsmoothinghttps://arxiv.org/pdf/1902.04103.pdfeqn3
self.cp,self.cn=smooth_BCE(eps=h.get("label_smoothing",0.0))#positive,negativeBCEtargets
#Focalloss
g=h["fl_gamma"]#focallossgamma
ifg>0:
BCEcls=FocalLoss(BCEcls,g)
m=de_parallel(model).model[-1]#Detect()module
self.balance={3:[4.0,1.0,0.4]}.get(m.nl,[4.0,1.0,0.25,0.06,0.02])#P3-P7
self.BCEcls=BCEcls
self.hyp=h
self.stride=m.stride#modelstrides
self.nc=m.nc#numberofclasses
self.nl=m.nl#numberoflayers
self.device=device
#正负样本匹配
self.assigner=TaskAlignedAssigner(topk=int(os.getenv('YOLOM',10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA',0.5)),
beta=float(os.getenv('YOLOB',6.0)))
#回归损失函数
self.bbox_loss=BboxLoss(m.reg_max-1,use_dfl=use_dfl).to(device)
self.proj=torch.arange(m.reg_max).float().to(device)#/120.0
self.use_dfl=use_dfl
———————End———————
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
你也可以把文章转给学校老师等相关人员,让RT-Thread可以惠及更多的开发者
-
RT-Thread
+关注
关注
32文章
1640浏览量
45211
原文标题:【AI周报20230317】 OpenAI公布GPT-4、国内存在哪些算力瓶颈
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
5W功耗实现25TOPS算力,LM2-100-V0算力模组破解AI安防核心难题

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
阿里云全光互联架构,突破AI算力瓶颈

中国算力芯片的拐点时刻

AI算力爆发催生元器件短缺,智芯谷一站式供应如何破局?


应对端侧AI算力、内存、功耗“三堵墙”困境,安谋科技Arm China “周易”X3给出技术锦囊


从CPU、GPU到NPU,美格智能持续优化异构算力计算效能

GPT-5.1发布 OpenAI开始拼情商
什么是AI算力模组?

什么是AI算力模组?





评论