 Jack Dongarra:高性能计算及其未来需求
Jack Dongarra:高性能计算及其未来需求

当前超级计算机主要通过LINPACK测试性能并形成TOP500排行榜,随着人工智能等应用的流行,新的基准测试正显得愈发重要。未来,数据移动将成为越来越重要的因素。
超级计算机的主要特点
传统的科学和工程通常是通过理论和实验完成的。一方面,我们通过观察周围的事物,使用纸和笔推导计算形成理论;另一方面,我们通过大量实验验证理论。当然,实验有时会改进甚至改变理论。然而,这两种科研范式都有其局限性:要么太困难(例如建造大型风洞),要么太昂贵(例如进行引擎鸟击实验),要么太缓慢(例如分析气候变化、星系碰撞),要么太危险(例如设计武器和药物)。计算机为科学研究提供了第三种范式,即基于物理规律和数值计算的方法,利用模拟仿真研究这些困难的问题。为此,我们需要运算速度快的超级计算机来实现高精度和高保真的模拟仿真。
如今,超级计算机普遍是由商用而非专用零部件制造而成的。我们把多个处理器核心封装在一起做成通用的CPU,这些CPU组成了超级计算机的节点。当我们希望提高计算能力和计算速度时,可以把GPU放在CPU旁边,利用GPU提高超级计算机的性能。多个这样的节点装在一个机柜里,然后在大房间(目前最快的超级计算机占地约为2个网球场大)里装满这样的机柜,再通过网络把这些节点连起来,就组成了一台超级计算机。
当今的超级计算机主要具备以下四个特点:
1.高度并行化。超级计算机是高度并行化的系统,内存也是分布式的。在这样的系统上,我们通常基于消息传递接口(Message Passing Interface,MPI)和OpenMP的编程模型做开发。
2.异构性。超算排行榜上速度最快的计算机的算力由CPU和GPU共同提供,这就是我们所说的异构性。3.数据传输代价高。在超级计算机上,与数值计算相比,数据在各处传输的代价十分高昂。4.多样的浮点数支持。主流的计算机大都支持64位(双精度)、32位(单精度)和16位(半精度)浮点运算,目前一些计算机也支持8位浮点数。这些支持较低精度浮点数的计算机主要用于机器学习。 当我们评价世界上最快的超级计算机时,会使用ExaFLOP来衡量。ExaFLOP是什么呢?一个FLOP指的是完成一次浮点数(通常为64位)加法或乘法运算,因此一个ExaFLOP,或者简称为EFLOP,就是指完成一百亿亿(1018)次浮点数运算。假设我们让地球上所有人每秒钟做一次计算,那么完成一个ExaFLOP需要4年时间,而如果让目前最好的超级计算机做,只需要一秒钟,我们把这样的计算机叫做E级计算机。
LINPACK与TOP500
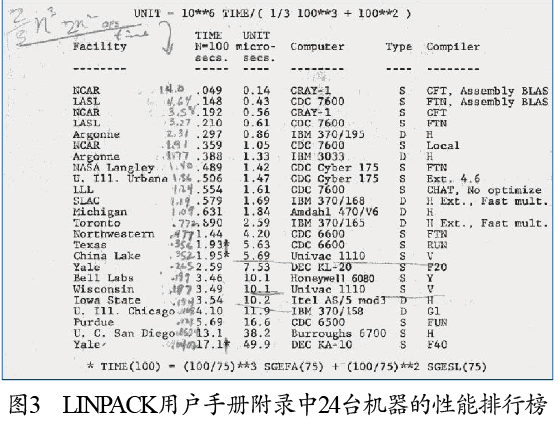
LINPACK是我在1979年开始做的项目,用于求解线性方程组。图1是当时项目组的合影,从右到左分别是吉姆邦奇(Jim Bunch)、彼得斯图尔特(Pete Stewart)、克里夫莫勒尔(Cleve Moler)和我,中间是我的汽车,车牌正好也是LINPACK。这个项目是我在新墨西哥大学发起的,当时我还是一名研究生。LINPACK用户手册(见图2)的附录中列出了24台机器求解规模为100的线性方程组的性能排行榜(见图3)。排行榜中最快的计算机是美国国家大气研究中心(National Center for Atmospheric Research)的克雷1号(Cray-1),当时它的运算速度是14 MFLOPS(1400万次浮点运算/秒)。

TOP500项目始于1993年,由我、汉斯梅乌尔(Hans Meuer)、埃里希斯特罗迈尔(Erich Strohmaier)和霍斯特西蒙(Horst Simon)等人共同发起。TOP500排行榜每年发布两次,其中一次是6月在德国的国际超算大会(ISC)上发布,另一次是11月在美国的超算大会(SC)上发布。在TOP500的评测中,我们测量求解线性方程组Ax=b的时间,然后把它换算为运行速度。当增大线性方程组的规模时,运算速度会上升,直到达到稳定点(asymptotic point)。这一稳定的速率被作为TOP500评测的结果。 图4是超级计算机的性能随时间变化的曲线:红线表示运算速度最快(即第一名)的计算机的性能,橙线表示刚进入名单(即第500名)的计算机的性能,蓝线是TOP500榜单中算力的总和。1993年的冠军是美国洛斯阿拉莫斯国家实验室(Los Alamos National Lab,LANL)的CM5计算机,它有1024个处理器,峰值性能为59.7 GFLOPS(597亿次浮点运算/秒),主要用于设计核武器。这种算力在今天是不值一提的。以我作报告使用的Apple M2芯片为例,它的算力约为426 GFLOPS,比1993年的冠军高了一个数量级,而我却只用它收发电子邮件。实际上,这个芯片的性能与1997年的冠军——位于日本筑波大学的日立CP-PAC的性能相当,而这台机器竟然有2048个处理器。
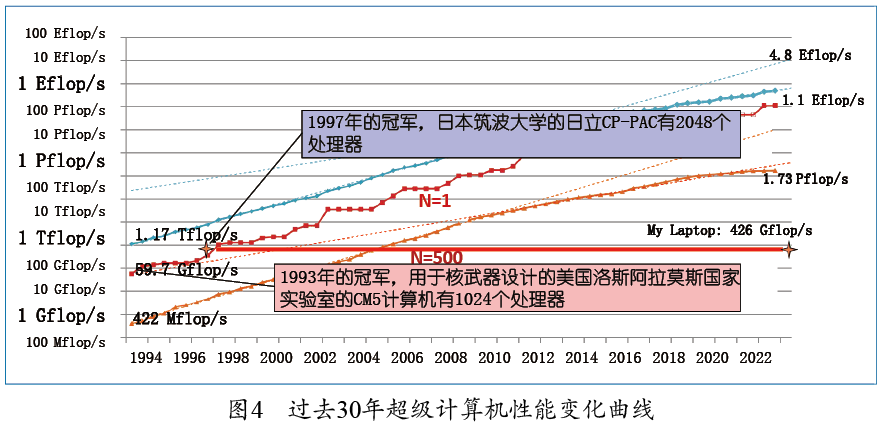
表1列出了最近刚发布的TOP500中排名前十的机器。美国有5台超级计算机位居前十,其中4台部署在美国能源部下属的实验室,另一台在英伟达公司。日本、芬兰、意大利各有一台,中国有两台。
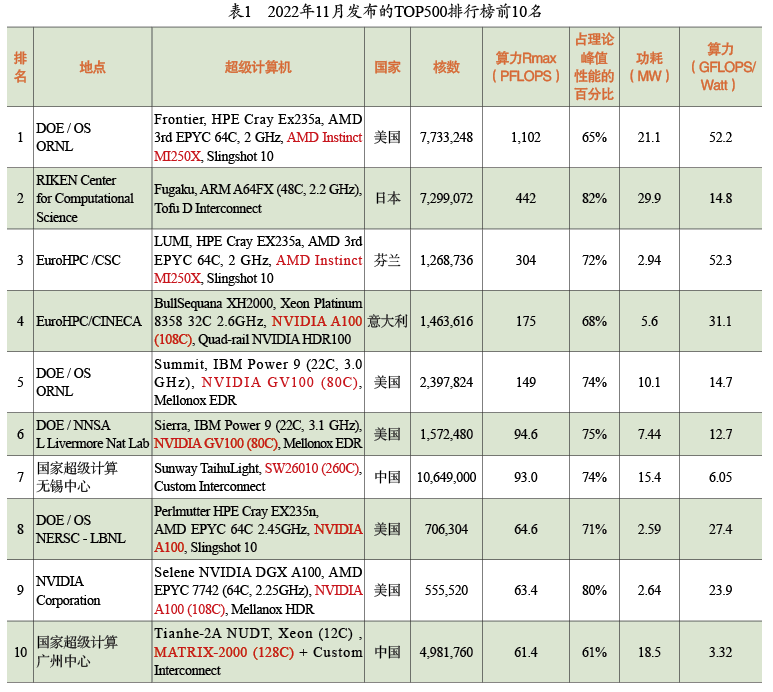
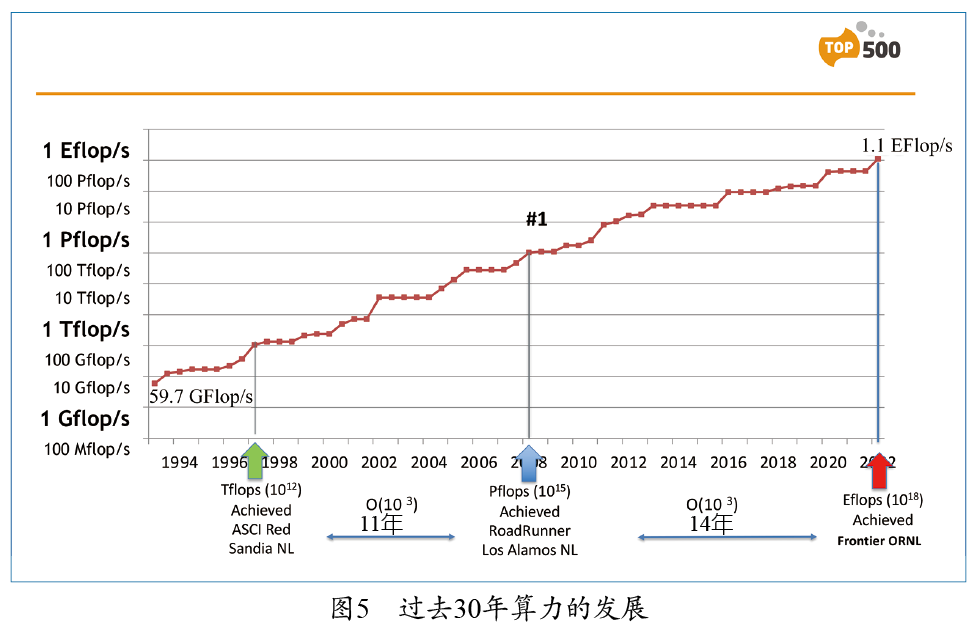
排行榜的第一名是位于美国橡树岭国家实验室(Oak Ridge National Lab,ORNL)的超级计算机Frontier。它是由系统集成商HPE使用超威(AMD)的CPU和GPU制造的,由9408个节点,共计约800万个核心组成。这台机器的算力测试结果为1.1 EFLOPS,达到了理论峰值性能的65%,功耗高达21兆瓦,以美国的电价计算,这台计算机一年的电费约为2100万美元。这台机器非常高效,每瓦的能耗可以提供52.2 GFLOPS的算力。 中国上榜的两台机器中,位于无锡的“神威太湖之光”非常引人注目,它使用了中国自己生产的申威处理器。另一台是由国防科技大学研制的“天河二号A”,它使用英特尔处理器,并配备了国防科技大学自研的加速器。 最新的TOP500排行榜中,中国拥有162台 超级计算机,数量位居第一;美国有125台,排名第二;然后是德国(34台)、日本(32台)和法国(24台)等。中国不仅拥有数量最多的超级计算机,还拥有数量最多的超级计算机研发机构,包括联想、中科曙光、浪潮、华为和国防科技大学等。据悉,中国目前有两台E级计算机,速度比目前排名第一的Frontier还快。其中一台是位于青岛的新一代神威超级计算机,基于这台计算机的研究成果获得了2021年的“戈登贝尔”奖(高性能计算领域的最高奖项);另一台是位于天津的天河三号。目前,这两台超级计算机尚未提交LINPACK的测试结果,因此还未列入TOP500排行榜。 回顾超级计算机的发展(见图5),我们发现1997年时算力达到了T级,即每秒1012次浮点数操作。11年后的2008年,算力提高了3个数量级,达到了P级,即每秒1015次浮点数操作。又过了14年,到今年(2022年),算力再次提高了3个数量级,达到了E级。那么什么时候能达到Z级(ZettaFLOPS,每秒1021次浮点数操作)呢?我认为时间要比14年长得多。
新的计算模式与基准测试
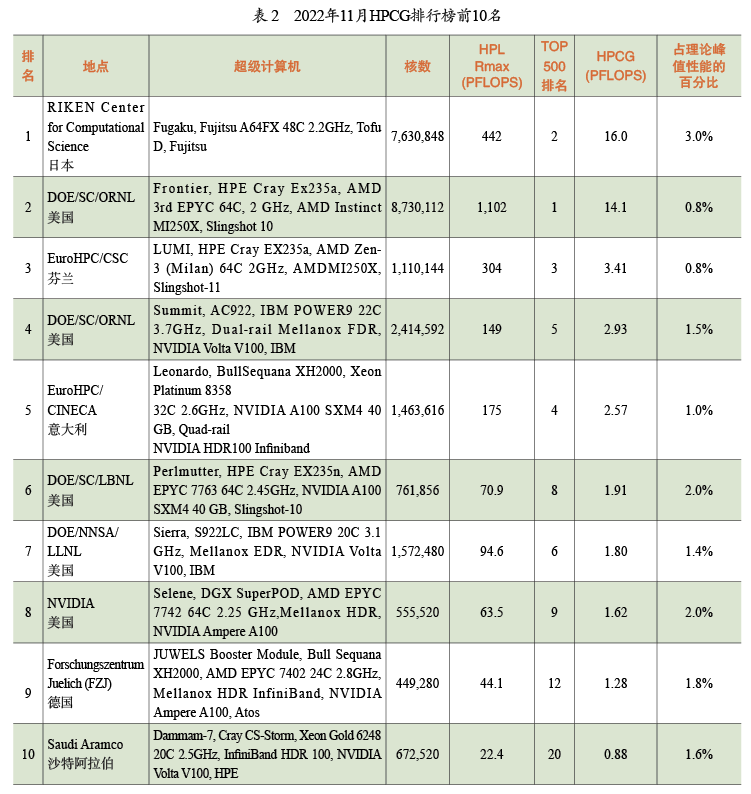
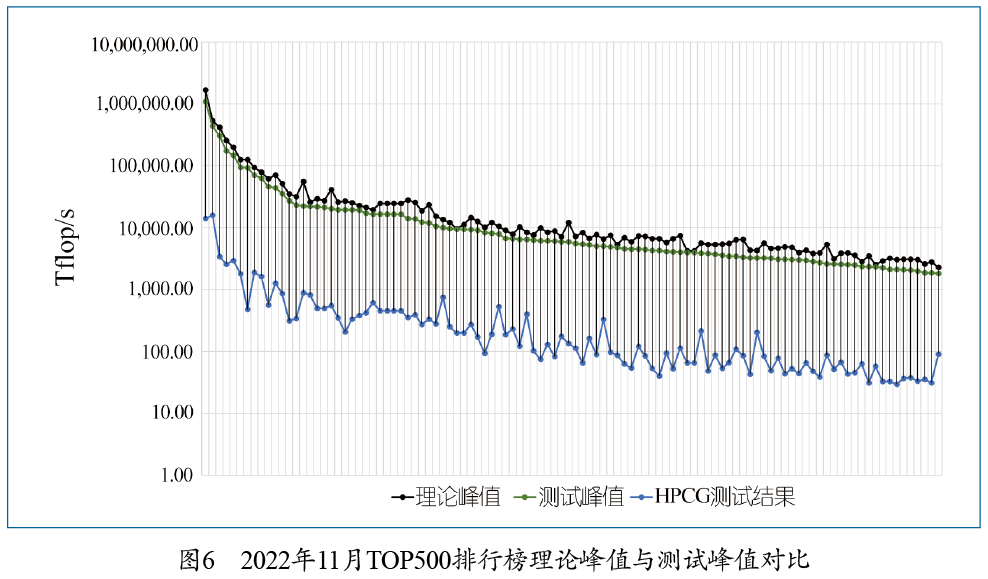
我们设计LINPACK的时候,通过矩阵乘法评价浮点数的计算性能。这在过去是个很重要的指标,但现在不是了。今天,我们需要用新的基准测试来关注数据传输的性能。有一个比较新的基准测试叫作HPCG(High Performance Conjugate Gradients),它使用共轭梯度算法解决稀疏矩阵上的问题,这个问题在当前各类应用中普遍出现。表2是基于新基准HPCG的计算机排名,表中列出的HPL(High Performance LINPACK)是旧基准下的算力数值,HPCG是新基准下的算力数值。如果我们只比较这些数字,会发现旧基准给出了比新基准更高的算力结果,但实际上新基准更能反映在这些机器上运行应用程序的实际性能。 表2中的占理论峰值性能的百分比表示HPCG基准下,测试所得算力与理论峰值算力的比值。其中排名第一的日本超级计算机富岳(Fugaku)达到了理论峰值算力的3%,而TOP500中排名第一的Frontier仅达到了理论峰值的0.8%。算力与理论峰值存在差异的主要原因是通信的带宽和延迟。图6展示了TOP500排行榜上机器的算力情况,其中黑色圆点表示根据硬件配置计算得到的理论峰值算力;绿色圆点表示LINPACK基准测试得到的峰值算力,非常接近理论峰值;蓝色圆点表示HPCG测试结果,相比之下低得多,但它更能反映大多数应用的实际效果。
近年来,人工智能和机器学习十分火热。它们已经存在很长时间了,为什么现在才火起来呢?原因之一是,近年来互联网产生了大量数据,可以用于训练和构建机器学习算法。原因之二是,计算能力的不断发展(主要是GPU的出现)提高了机器学习的可行性。此外,近年来我们也更深入地理解了算法和理论背后的原理。这些因素都让我们更有效地利用计算机实现人工智能。今天的人工智能涵盖很多方面,包括机器学习、自然语言处理、专家系统、计算机视觉、语音、机器人等。不仅如此,人工智能在科学发现方面也起到了很重要的作用,提高了我们解决问题的能力,包括气候、生物、制药、材料、高能物理在内的各个领域都在使用人工智能。 尽管线性代数在机器学习中仍然十分重要,但对于精度的要求却不高。很多时候16位浮点数足以满足要求,因此很多公司都在设计新硬件和新架构来满足这样的场景。今天的超级计算机大多基于CPU和GPU构建,也许在未来,我们会使用更多的其他加速器,例如神经形态计算(neuromorphic computing),甚至是光学计算(optical computing)加速器。在未来,用户或许可以像接入互联网那样轻松地使用超算服务。 展望未来,数据的移动将会是计算机体系架构发展中重要的考量因素,我希望未来的计算机可以在数据移动性能和浮点数计算性能之间取得更好的平衡。虽然在短期内,我们不会看到量子计算机取代现有的计算机,它不能解偏微分方程,也不能解决我们今天使用超级计算机时遇到的各种问题,但量子计算(quantum computing)有望发挥加速器的作用,与现有的计算模式协作解决某些问题。此外,今天的超级计算机仍然被英特尔和超微的处理器主导,TOP500中仅有5台计算机使用ARM处理器,还没有任何机器使用RISC-V处理器。RISC-V目前对高性能计算的影响很小,未来或许会有所改变。
结论
从标量到向量,到分布式内存,到加速器,再到混合精度,高性能计算的变迁从未停止过。我认为这里有三场计算的变革。第一个是高性能计算,利用高性能计算推动科学的新发现是当今科学研究的重要组成部分,拥有最好的超级计算机就能做最好的科学研究;第二个是深度学习,它对提高我们利用超级计算机解决问题的能力至关重要;第三个是边缘计算与人工智能。我认为,算法和软件通常会随着硬件的进步而发展,硬件发展在先,软件发展在后。几年前,《科学》杂志上发表了一篇非常有趣的论文,是查尔斯雷瑟尔森(Charles Leiserson)等人所写的《我们仍有向上的空间:摩尔定律之后什么将推动计算机性能》(There’s plenty of room at the Top: What will drive computer performance after Moore's law?)。这篇文章讨论的正是这个问题:我们需要设计更好的软件、更好的算法来匹配已有的硬件,以更有效地利用硬件。我想,这或许可以与理查德费曼(Richard Feynman)1959年在加州理工学院作的经典演讲相呼应,费曼讲的是在物理世界的底层还有很多研究空间,例如量子效应、量子计算,以及我们如何利用它们。
审核编辑 :李倩
-
cpu
+关注
关注
68文章
11389浏览量
226661 -
加速器
+关注
关注
2文章
842浏览量
40337 -
超级计算机
+关注
关注
2文章
485浏览量
43544
原文标题:Jack Dongarra:高性能计算及其未来需求
文章出处:【微信号:信息与电子工程前沿FITEE,微信公众号:信息与电子工程前沿FITEE】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论