 使用NVIDIA cuQuantum等工具开启高性能计算的未来之旅
使用NVIDIA cuQuantum等工具开启高性能计算的未来之旅

使用 NVIDIA cuQuantum 等工具,立即开启高性能计算的未来之旅。
是时候开始打造未来的混合量子计算机了。
如今,我们拥有可不抗拒的动机、清晰明确的道路,并且打造混合量子计算机所需的关键组件也已备齐。
量子计算有望攻破当今面临的一些严峻挑战,推动从药物研发到天气预报等各项工作的发展。简言之,量子计算将在未来的 HPC 中发挥巨大作用。
当今的量子模拟
创造未来并非易事,但开启这条道路所需的工具已经准备就绪。
当今的超级计算机模拟量子计算作业,其规模和性能水平是现有的相对较小且易出错的量子系统无法达到的,这是我们向前迈出的第一步。
数十家量子组织已经在使用 NVIDIA cuQuantum 软件开发套件,在 GPU 上加速
其量子电路模拟。
最近, AWS 宣布在其 Braket 服务中提供 cuQuantum。它还在 Braket 上展示了 cuQuantum 如何在量子机器学习工作负载上实现高达 900 倍的加速。
cuQuantum 现已能够在主要的量子软件框架上实现加速计算,包括 Google 的 qsim、 IBM 的 Qiskit Aer、Xanadu 的 PennyLane 和 Classiq 的 Quantum Algorithm Design 平台。这意味着这些框架的用户可以访问 GPU 加速,而无需再进行任何编码。
量子驱动药物发现
如今, Menten AI 开始使用 cuQuantum 来支持其量子工作。
这家湾区药物研发初创公司将使用 cuQuantum 的 Tensor 网络库来模拟蛋白质相互作用并优化新的药物分子。这样做旨在利用量子计算的潜力来加速药物设计,该领域与化学类似,是公认的率先受益于量子加速的领域。
具体而言, Menten AI 正在开发一套量子计算算法(包括量子机器学习),以解决治疗设计中需要进行大量计算的问题。
Menten AI 的首席科学家 Alexey Galda 表示:“虽然能够运行这些算法的量子计算硬件仍处于开发阶段,但 NVIDIA cuQuantum 等经典计算工具对于推进量子算法的开发至关重要。”
构建量子链路
随着量子系统的发展,下一个重大飞跃是朝混合系统迈进:量子计算机和经典计算机协同工作。研究人员都希望这些系统级量子处理器(即 QPU)成为功能强大的新型加速器。
因此,摆在面前的一个重要任务就是将传统系统和量子系统桥接到混合量子计算机中。这项任务包括两个主要部分。
首先,我们需要在 GPU 和 QPU 之间建立快速、低延迟的连接。这样一来,混合系统可使用 GPU 完成其擅长的传统作业,例如电路优化、校正和纠错。
GPU 可以缩短这些步骤的执行时间,并大幅降低经典计算机和量子计算机之间的通信延迟,而这是当今混合量子作业面临的主要瓶颈。
其次,该行业需要一个统一的编程模型,其中包含高效易用的工具。我们在 HPC 和 AI 方面的经验使我们和用户了解到了固态软件栈的价值。
适合作业的工具
当前,为了对 QPU 进行编程,研究人员只能使用相当于低级组装代码的量子,不是量子计算专家的科学家无法使用这种代码。此外,开发者缺乏统一的编程模型和编译器工具链,因此无法在任何 QPU 上运行工作。
这种现象亟待改变,而且我们相信将会有所改变。在 3 月份的一篇博客中,我们讨论了为构建更出色的编程模型而开展的一些初步工作。
为了高效地找到量子计算机加速工作的方法,科学家需要轻松地将其 HPC 应用的一部分先移植到模拟版 QPU,然后再移植到真正的 QPU。这个过程需要一个编译器,使科学家们能够以熟悉的方式高效工作。
将 GPU 加速的模拟工具、编程模型和编译器工具链全部结合在一起后, HPC 研究人员就可以开始构建未来的混合量子数据中心。
入门指南
对部分人来说,量子计算可能听上去像是科幻小说,是几十年后的未来情景。而事实上,研究人员每年都在构建数量更多、规模更庞大的量子系统。
NVIDIA 正全力参与这项工作,并邀请您加入我们,立即开始共同构建未来的混合量子系统。
原文标题:ISC22 | 混合量子——HPC 数据中心之路由此开始
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
NVIDIA
+关注
关注
14文章
5496浏览量
109091 -
计算机
+关注
关注
19文章
7764浏览量
92682 -
数据中心
+关注
关注
16文章
5515浏览量
74649
原文标题:ISC22 | 混合量子——HPC 数据中心之路由此开始
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
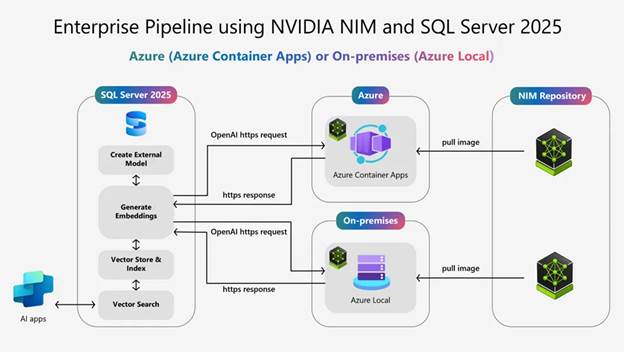
使用NVIDIA Nemotron RAG和Microsoft SQL Server 2025构建高性能AI应用
NVIDIA DGX Spark桌面AI计算机开启预订

NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展
使用树莓派构建 Slurm 高性能计算集群:分步指南!

高性能计算面临的芯片挑战

快手上线鸿蒙应用高性能解决方案:数据反序列化性能提升90%

飞腾ITX主板D2000 ITX:国产高性能计算的未来之选

FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......
PAD国产飞腾主板,开启高性能运算时代
重磅发布 | 晶丰明源多相数字控制器和DrMOS,为NVIDIA显卡提供高性能供电解决方案






 工商网监
工商网监
评论