 GPU面临挑战及应用场景解析
GPU面临挑战及应用场景解析

在机器学习算法上,TPU比传统的加速方案(谷歌之前使用GPU加速方案)在能耗效率上提升一个数量级,相比传统解决方案领先7年(摩尔定律三代节点)。
例如在GPU中,通常支持IEEE754-2008标准浮点数操作,这一浮点数字宽为32位,其中尾数字宽为23+1(使用隐藏尾数技术)位。 如果数据通道中使用8位字宽的低精度尾数,则GPU中各个计算部件所需的晶体管和功耗均会大大减少。
例如,在GPU计算核心中,面积最大,功耗最高的计算部件是ALU,ALU中最重要的部件是浮点MA(乘加混合)单元,现有技术下这一单元的延迟与尾数的字宽log2N成大致正比,而面积/功耗/晶体管数量大体上与N2log2N成正比。 如果字宽由24比特减少到8比特,那么MA的面积可降至约1/14左右,约一个数量级。 由图可知ALU占据了GPU芯片面积的很大比例,因此单单优化ALU即可获得足够提高。
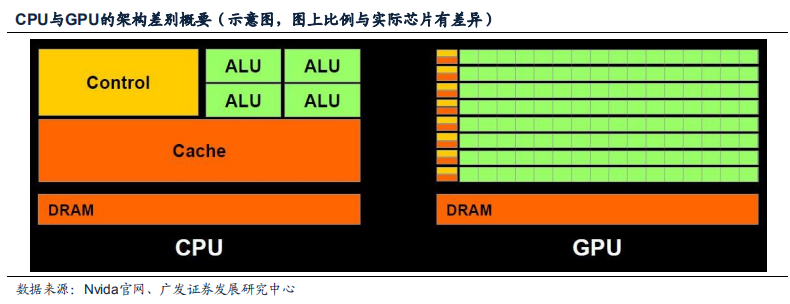
除了降低字宽所带来的关键组件优化,GPU原有组件中针对图像处理的组件如光栅、材质贴图单元,均可以根据人工智能的计算需求选择优化或裁剪。 对普通GPU进行深度定制处理,削减在神经网络算法不需要的数据位宽和功能即可达到谷歌所宣称的“能耗效率上提升一个数量级”,因此业内有专家认为谷歌采用了此种思路。
2、从谷歌 TPU 设计思路看人工智能硬件发展趋势
目前的GPU加速方案以及FPGA加速方案在人工智能计算领域都存明显缺点:
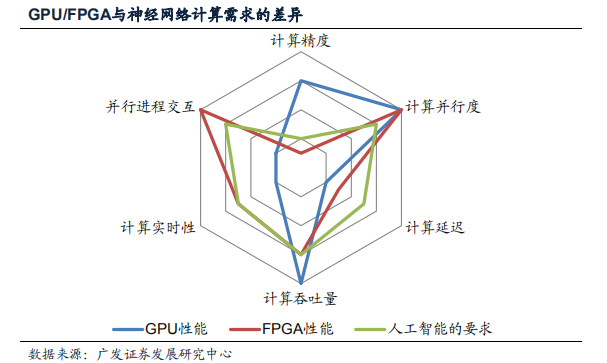
在计算单元上,GPU的内置计算单元主要针对图像处理设计,计算精度过高存在浪费; FPGA的LUT功能过于弱小,没有针对低精度浮点计算优化;
在NOC架构上,FPGA和GPU原始设计匹配的目标均与神经网络计算存在很大差异性,因此用于人工智能计算加速都存在一定缺憾。
以上表现在计算需求雷达图上即为图:GPU(蓝线)和FPGA(红线)均不能较好的覆盖住人工智能的需求(绿线)。 除了进程交互问题外,实时性和计算延迟同样是人工智能加速的一个重要问题。 在人工智能的一些应用场景,如无人驾驶汽车中,汽车的运行速度可能高达40m/s,在计算中额外0.1s的延迟意味着汽车多行驶4米,这就是生与死的差距。 GPU的延迟和实时性较差从长期来看会影响其应用在类似无人驾驶这样在实时性和延迟要求较高的场景中。
3、GPU/FPGA 用于神经网络计算的弱点:片上网络
在人工智能硬件领域,FPGA加速同样是一条有竞争力的技术路径。 早在中国搜索引擎巨头百度就尝试与Altera合作探索使用FPGA加速神经网络运算用于搜索结果的优化中,微软也在bing搜索服务中做了相似的探索。 Auviz Systems公司在2015年发布了一份研究数据,在神经网络计算中,高端FPGA可处理14个或更多图像/秒/瓦特,而同期一个高端的GPU仅能处理4个图像/秒/瓦特。
但目前学术界已有共识,不管是FPGA还是GPU,由于其最初设计匹配的计算模型与神经网络计算模型存在不同,其并行计算核心之间的通信架构-NOC(Network on Chip,片上网络)应用在神经网络运算中均存在缺点。
由于FPGA/GPU针对的并行计算模型不同,其片上网络的实现方式也就不同:
GPU最初针对图像处理SIMT类任务优化,各个处理核心之间的通信较少且形式简单,因此计算节点主要通过片上共享存储通信,原理如图: A/C计算节点分别向片上共享存储的不同地址写入数据,然后B/D通过读数据的方式完成A->B/C->D的通信。 这种片上网络每次通信涉及读写片上共享存储各一次,不仅速度慢,当通信量更多(原本不会发生在图形处理任务中)的时候存储的读写端口还会因堵塞成为系统性能的关键瓶颈。
FPGA包含大量细粒度,可编程,但功能较弱的LUT(Look up table查找表)计算节点,各个LUT之间通过网格状NOC连接,网格的节点具备Routing(路由)功能。 FPGA可以提供计算单元间直接通讯功能:A节点可通过路由网络沿着红色箭头将数据传输至芯片上任意计算节点B,且传输路径动态可编程。 因此网格NOC相比共享内存方案能提供大的多的片上通讯容量,相比之下也不易出现瓶颈节点堵塞问题。 Auviz Systems能够得出FPGA在神经网络处理中优于高端GPU的方案的结论,很大程度依靠FPGA的片上通信能力而不是羸弱的LUT计算能力。
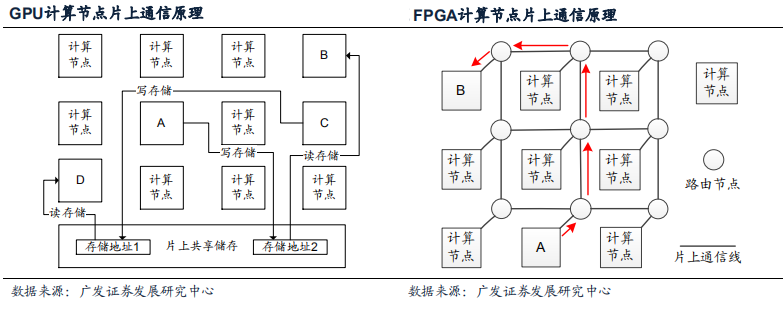
神经网络作为一种并行计算程序,适配的计算节点通讯硬件是提升性能的关键要素之一。 目前FPGA和GPU的片上网络架构均不完全匹配神经网络的实际需求,相比之下GPU的共享内存连接的匹配度更差一些。 学术界对于定制特殊的NOC去匹配神经网络加速需求已有一定研究,但之前因神经网络算法本身没有商用化,因此定制NOC硬件这一思路也停留在实验室内。 随着人工智能实用化和产业化的发展,这些技术将对现有的GPU/FPGA方案形成威胁和替代。
02 GPU 未来较适应场景解析
GPU虽然不能处理所有大规模并行计算问题,但在其适应的特定计算领域,特别是图形优化处理上依然具备绝对性能优势。 GPU未来较为适合拓展应用场景应为VR/AR(虚拟现实/增强现实)、云计算+游戏结合、以及云计算服务器中为特定的大数据分析提供加速。 在这些领域的增长点有可能是独立GPU突破现有增长迟缓障碍的新增长领域。
1、VR 应用:持续增长的优势领域
在VR(Virtual Reality,虚拟现实)设备性能指标中,图像显示性能是其核心竞争力。 在VR中降低从用户头部动作到画面改变的延迟至20毫秒以下是防止用户眩晕的必要条件; 而达到这点除了需要软件和OS优化以外,足够的硬件图像计算能力是基础。 表1举例了VR图形显示的要求以及大众级显卡能够提供的图形显示水平:
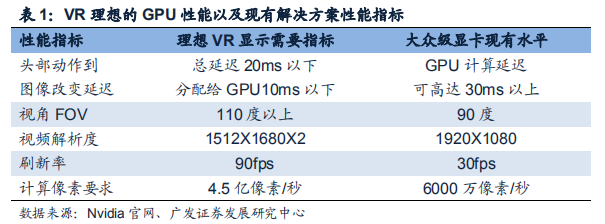
正因目前大众显卡无法提供VR所需的图形处理计算能力,现有的两大主流头显Oculus Rift和HTC VIVE均要求配套的PC配置顶级显卡,如Nvidia GTX970或AMDR9 290级别的显卡。 从长期来看,VR/AR设备将拉动中高端GPU市场的持续增长。
VR以及AR(增强现实)更广阔的应用在于独立一体机上:独立一体机具备移动能力,让VR/AR超脱出了客厅应用这一范畴,与移动互联网结合后成为每个人都需要消费电子产品。 但移动一体机对计算芯片的能耗,体积乃至散热都有着严格的要求。 目前SoC(System on Chip, 片上系统)上集成GPU在移动一体机上的优势是独立GPU显卡暂时无法动摇的。
2、云计算/大数据应用
亚马逊风靡全球的计算平台EC2中,Nvidia GPU已经被作为一个重要的并行计算组件提供给客户,用作大规模并行浮点数计算。 用户每使用一个实例可调用两个Nvidia Tesla m2050 GPU。 在EC2中调用GPU的原理是AWS的管理程序Hypervisor被直接跳过,而DomU OS和应用可以直接通过IO与GPU通信,充分发挥GPU在浮点数的并行计算能力。
3、GPU,云和游戏服务结合
在现如今互联网基础设施已经完善的市场,把GPU和云计算以及游戏结合在一起是游戏产业下一个具有吸引力的发展方向。
对于游戏开发者,不需要担心盗版问题; 对于游戏运营商,云服务可以获得更精确的客户资料,开展新式计费; 对于游戏玩家,无需购买昂贵高端游戏主机或PC,初始投资少; 对于游戏玩家,云服务游戏更具备移动性。
目前云计算+GPU+游戏这个模式限于现有网络基础设施限制,依然没有大规模商用,但Nvidia依然对其抱有厚望并积极推动。 从这个侧面也可以看出,Nvidia自己也知道GPU未来最主要的应用领域依然是游戏的图像处理上。
GPU还有一块市场是军用GPU市场,这一市场与民用GPU市场有着很大不同。 民用GPU追求画面性能的极致,以最好的画面满足消费者,特别是游戏玩家的需求; 而军用GPU更多的要求在于高可靠性、高耐用性、抗高空辐射、能在野战环境下安全使用。 需求的导向不同导致GPU从工艺到芯片设计理念都截然不同。
审核编辑:汤梓红
-
谷歌
+关注
关注
27文章
6271浏览量
112197 -
gpu
+关注
关注
28文章
5324浏览量
136219 -
人工智能
+关注
关注
1821文章
50523浏览量
267786 -
机器学习
+关注
关注
67文章
8570浏览量
137425 -
TPU
+关注
关注
0文章
176浏览量
21734
原文标题:GPU面临挑战及应用场景解析
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
蓝牙网关是什么?都有哪些功能?应用场景有哪些?
【F3使用场景】F3经典使用场景
一文看完GPU八大应用场景,抢食千亿美元市场
GPU八大主流的应用场景
GPU设计实时光线追踪面临的挑战
深度学习的火热,GPU面临严峻挑战
GPU深度学习面临的挑战分析
揭秘GPU: 高端GPU架构设计的挑战




评论