 NVIDIA Triton 系列文章(11):模型类别与调度器-2
NVIDIA Triton 系列文章(11):模型类别与调度器-2

在上篇文章中,已经说明了有状态(stateful)模型的“控制输入”与“隐式状态管理”的使用方式,本文内容接着就继续说明“调度策略”的使用。
(续前一篇文章的编号)
(3) 调度策略(Scheduling Strategies)在决定如何对分发到同一模型实例的序列进行批处理时,序列批量处理器(sequence batcher)可以采用以下两种调度策略的其中一种:
现在简单说明以下配置的内容: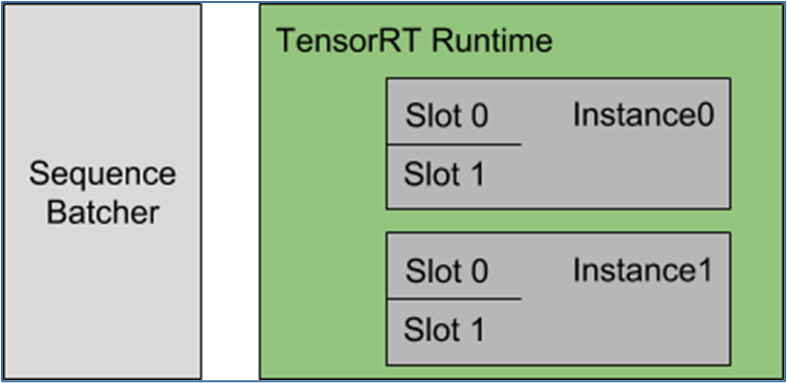 每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
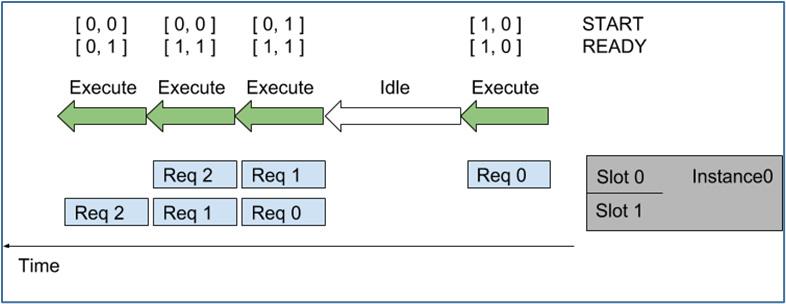
下图显示使用直接调度策略,将多个序列调度到模型实例上的执行:
 图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
 随着时间的推移(从右向左),会发生以下情况:
随着时间的推移(从右向左),会发生以下情况:
在本示例中,模型需要序列批量处理的开始、结束和相关 ID 控制输入。下图显示了此配置指定的序列批处理程序和推理资源的表示。
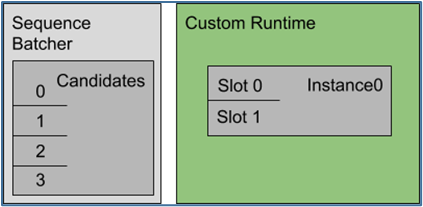 使用最旧的调度策略,序列批处理程序会执行以下工作:
使用最旧的调度策略,序列批处理程序会执行以下工作:
下图显示将多个序列调度到上述示例配置指定的模型实例上,左图显示 Triton 接收了四个请求序列,每个序列由多个推理请求组成:
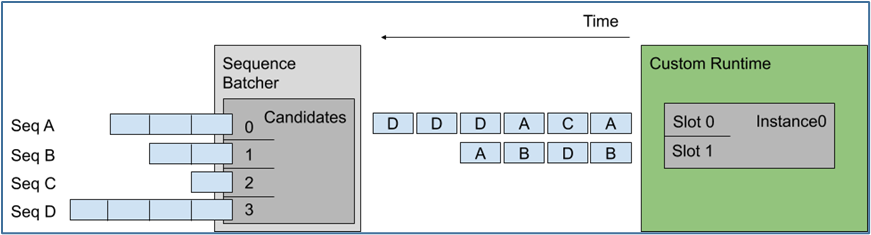 这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
- 直接(direct)策略
| name: "direct_stateful_model"platform: "tensorrt_plan"max_batch_size: 2sequence_batching{ max_sequence_idle_microseconds: 5000000direct { } control_input [{name: "START" control [{ kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ]}]},{name: "READY" control [{ kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ]}]}]}#续接右栏 | #上接左栏input [{name: "INPUT" data_type: TYPE_FP32dims: [ 100, 100 ]}]output [{name: "OUTPUT" data_type: TYPE_FP32dims: [ 10 ]}]instance_group [{ count: 2}] |
- sequence_batching 部分指示模型会使用序列调度器的 Direct 调度策略;
- 示例中模型只需要序列批处理程序的启动和就绪控制输入,因此只列出这些控制;
- instance_group 表示应该实例化模型的两个实例;
- max_batch_size 表示这些实例中的每一个都应该执行批量大小为 2 的推理计算。
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
| 所识别的推理请求种类 | 执行动作 |
| 需要启动新序列 | 1. 有可用处理槽时:就为该序列分配批处理槽2. 无可用处理槽时:就将推理请求放在积压工作中 |
| 是已分配处理槽序列的一部分 | 将该请求分发到该配置好的批量处理槽 |
| 是积压工作中序列的一部分 | 将请求放入积压工作中 |
| 是最后一个推理请求 | 1. 有积压工作时:将处理槽分配给积压工作的序列2. 有积压工作:释放该序列处理槽给其他序列使用 |
图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
- 在实例 0 与实例 1 中各有两个槽 0 与槽 1;
- 根据接收的顺序,为序列 0 至序列 3 各分配一个批量处理槽,而序列 4 与序列 5 先处于排队等候状态;
- 当序列 3 的请求全部完成之后,将处理槽释放出来给序列 4 使用;
- 当序列 1 的请求全部完成之后,将处理槽释放出来给序列 5 使用;
随着时间的推移(从右向左),会发生以下情况:- 序列中第一个请求(Req 0)到达槽 0 时,因为模型实例尚未执行推理,则序列调度器会立即安排模型实例执行,因为推理请求可用;
- 由于这是序列中的第一个请求,因此 START 张量中的对应元素设置为 1,但槽 1 中没有可用的请求,因此 READY 张量仅显示槽 0 为就绪。
- 推理完成后,序列调度器会发现任何批处理槽中都没有可用的请求,因此模型实例处于空闲状态。
- 接下来,两个推理请求(上面的 Req 1 与下面的 Req 0)差不多的时间到达,序列调度器看到两个处理槽都是可用,就立即执行批量大小为 2 的推理模型实例,使用 READY 显示两个槽都有可用的推理请求,但只有槽 1 是新序列的开始(START)。
- 对于其他推理请求,处理以类似的方式继续。
- 最旧的(oldest)策略
| 直接(direct)策略 | 最旧的(oldest)策略 |
|
direct {} |
oldest { max_candidate_sequences: 4 } |
使用最旧的调度策略,序列批处理程序会执行以下工作:
| 所识别的推理请求种类 | 执行动作 |
| 需要启动新序列 | 尝试查找具有候选序列空间的模型实例,如果没有实例可以容纳新的候选序列,就将请求放在一个积压工作中 |
| 已经是候选序列的一部分 | 将该请求分发到该模型实例 |
| 是积压工作中序列的一部分 | 将请求放入积压工作中 |
| 是最后一个推理请求 | 模型实例立即从积压工作中删除一个序列,并将其作为模型实例中的候选序列,或者记录如果没有积压工作,模型实例可以处理未来的序列。 |
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
原文标题:NVIDIA Triton 系列文章(11):模型类别与调度器-2
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
英伟达
+关注
关注
23文章
4115浏览量
99633
原文标题:NVIDIA Triton 系列文章(11):模型类别与调度器-2
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
NVIDIA 扩展开放模型系列,推动代理式、物理和医疗 AI 下一阶段发展
新闻摘要: ●NVIDIA Nemotron 3 全模态理解模型 (Omni-understanding Models) 为 AI 智能体提供动力 ,使其能够实现自然对话、复杂推理和高级视觉能力

NVIDIA Jetson模型赋能AI在边缘端落地
开源生成式 AI 模型不再局限于数据中心,而是开始深入到现实世界的各种机器中。从 Orin 到 Thor,NVIDIA Jetson 系列正在成为运行 NVIDIA Nemotron、

借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
NVIDIA CUDA Tile 是基于 GPU 的编程模型,其设计目标是为 NVIDIA Tensor Cores 提供可移植性,从而释放 GPU 的极限性能。CUDA Tile 的一大优势是允许开发者基于其构建自定义的 DS
七大基于大模型的地面测控站网调度分系统软件的应用与未来发展
七大基于大模型的地面测控站网智能调度系统 “七大基于大模型的地面测控站网调度分系统”并非公开资料中的标准化术语,而是结合国际航天测控领域发展趋势,以及人工智能大
NVIDIA 推出 Nemotron 3 系列开放模型
新闻摘要: ● Nemotron 3 系列开放模型包含 Nano、Super 和 Ultra 三种规模,具有极高的效率和领先的精度,适用于代理式 AI 应用开发。 ● Nemotron 3 Nano

NVIDIA携手Mistral AI发布全新开源大语言模型系列
全新 Mistral 3 系列涵盖从前沿级到紧凑型模型,针对 NVIDIA 平台进行了优化,助力 Mistral AI 实现云到边缘分布式智能愿景。
NVIDIA推动面向数字与物理AI的开源模型发展
NVIDIA 发布一系列涵盖语音、安全与辅助驾驶领域的全新 AI 工具,其中包括面向移动出行领域的行业级开源视觉-语言-动作推理模型(Reasoning VLA) NVIDIA DRI
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
NVIDIA 最近发布了 NVIDIA Cosmos 开放世界基础模型(WFM)的更新,旨在加速物理 AI 模型的测试与验证数据生成。借助 NVID
面向科学仿真的开放模型系列NVIDIA Apollo正式发布
用于加速工业和计算工程的开放模型系列 NVIDIA Apollo 于近日举行的 SC25 大会上正式发布。
NVIDIA开源Audio2Face模型及SDK
NVIDIA 现已开源 Audio2Face 模型与 SDK,让所有游戏和 3D 应用开发者都可以构建并部署带有先进动画的高精度角色。NVIDIA 开源 Audio

NVIDIA Nemotron Nano 2推理模型发布
NVIDIA 正式推出准确、高效的混合 Mamba-Transformer 推理模型系列 NVIDIA Nemotron Nano 2。

如何本地部署NVIDIA Cosmos Reason-1-7B模型
近日,NVIDIA 开源其物理 AI 平台 NVIDIA Cosmos 中的关键模型——NVIDIA Cosmos Reason-1-7B。这款先进的多模态大
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践
针对基于 Diffusion 和 LLM 类别的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能显著提升推理速度。在单张

NVIDIA GTC巴黎亮点:全新Cosmos Predict-2世界基础模型与CARLA集成加速智能汽车训练
。这种向使用大模型的过渡大大增加了对用于训练、测试和验证的高质量、基于物理学传感器数据的需求。 为加速下一代辅助驾驶架构的开发,NVIDIA 发布了 NVIDIA Cosmos Pre
NVIDIA使用Qwen3系列模型的最佳实践
阿里巴巴近期发布了其开源的混合推理大语言模型 (LLM) 通义千问 Qwen3,此次 Qwen3 开源模型系列包含两款混合专家模型 (MoE),235B-A22B(总参数




评论