 ADS感知计算:系统计算复杂度挑战
ADS感知计算:系统计算复杂度挑战

为了能够深入解读Tesla上述的这些设计理念,本文从ADAS感知算法演进和工程化需求的角度,首先来重点介绍Tesla于2021年底发布的用来改进原有HydraNet方案的Occupancy Network。
HydraNet是一种对8个摄像头的视频帧(36fps)分别进行空间变换矫正补偿和特征提取(ResNet),在BEV空间进行多摄像头的时空特征融合,然后进行多任务学习(行人检测,交通灯,可行驶区域分割,等等)。如图1所示的几例交通事故场景,可以看出纯视觉的HydraNet方案在目标检测上存在的一些致命的缺陷,例如小样本目标的漏检误检问题,非立体的平面目标画像的误检问题等等。其根因可以简单归纳几点(Thinkautonomous, 2022):
1、接近地平线的远景区域深度极度不一致问题:
小样本目标问题:远距离目标的深度信息消失,或者超低分辨率很难决定一个目标区域的深度(例如图右桥墩漏检后导致致命性车辆撞击问题)
2、遮挡问题:
鬼影问题:不能穿透遮挡区域或者行驶车辆来识别被遮挡目标,遮挡目标长记忆轨迹预测困难
3、2D或者2.5D视频约束问题:
非立体的平面目标画像问题:难以对应到真实3D场景,难区分静态和动态目标
2D目标固定框问题:难以识别悬挂或者悬空的障碍物(可能不在目标检测框内,例如卸货卡车的千斤顶支撑架,卡车货架顶上的人梯等)

图1可行驶空间3D目标漏检场景
Occupancy Network在HydraNet基础上通过添加高度这个维度对2DBEV空间进行扩展,其首先对图像的特征图进行MLP学习生成Value和Key,在BEV空间通过栅格坐标的位置编码来生成Query,新栅格的区别是采用原有的2D栅格和高度一起构成3D栅格,对应生成的特征也从BEV特征变成了Occupancy特征。
其设计思路来自机器人设计用的occupancy grid mapping,即将真实3D场景分割成一个个3D的栅格grid。如图2所示,每个栅格存在两种状态(占用或空闲),可以是多视觉3D呈现的Occupancy Volume,当然为了处理速度,目标的形状不会是一种精确表征,只能是简单逼近,但可以用来区分静态和动态目标(更像是一个3D的blob),可以以3x以上的帧速运行(>100fps),内存占用也非常高效。
Occupancy Network将3D空间图分割成一个个超小的cub或者voxel,通过DNN模型做占空两个状态的预测,显然可以解决上述2D目标固定框问题(即所谓的悬空障碍物的问题),以及换了一种思维设计来解决业界难以实现的通用目标检测器的问题(即所谓数据长尾效应下对未知障碍物的识别和避障能力问题)。
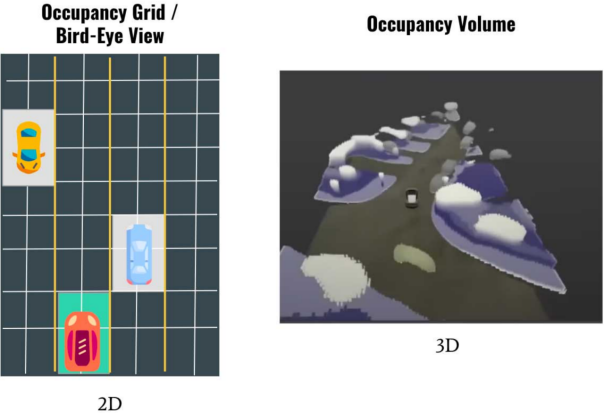
图 2Occupancy Network与HydraNet目标表征对比
Occupancy Network网络架构分析
如图3所示,Occupancy Network在HydraNet基础上,依旧采用Regnet + BiFPN进行特征提取,Attention模块采用图像位置编码,利用Key, Value和固定的查询(car vs not car, but vs not bus, traffic sign vs not traffic sign)来生产Occupancy Feature Volume。
时空融合后会生成4D Occupancy Grid。通过Deconvolution进行特征增强到原有尺寸,可以通过网络层输出上述讨论过的Occupancy Volume,以及Occupancy Flow。Occupancy Flow其实就是针对每个voxel进行光流估计来观察每一辆车在3D定位下运动流的向量预测(例如目标方向: red-向前;blue:backward;grey-stationary, 等等),可以用来有效解决目标遮挡问题,以及多目标运动预测与规划等。
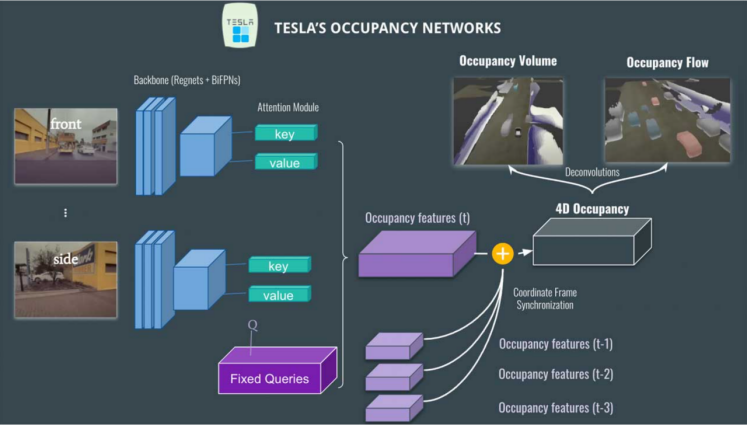
图 3Occupancy Network架构
Tesla AI day上所介绍的Full Self Driving(FSD)解决方案框架中包括训练数据(Auto Labelling, Simulation, Data Engine)、感知NN(Occupancy, Lanes & Objects)和规划决策Planning三个模块,以及AI模型的编译训练和推理部署的优化策略。
感知模块(Lanes, Occupancy, Moving Objects)为规划决策联合建模提供视觉度量数据(Sparse Abstractions, Latent Features),通过几何空间占有率来理解3D维度的遮挡问题,从而解决目标交互遮挡中产生的不确定性因素。其中Occupancy 展示在车道上发生了什么,而Sparse Abstractions用来对车道,道路使用者,运动目标等进行稀疏表征和特征编码,稀疏表征特性除了减少复杂度以外,应用优势包括可以将路口区域IOU提升4.2%等等。Occupancy网络通过构建可驾驶的Surface,通过对道路上人车和障碍物的3D信息构建和呈现,预测这些目标物的属性、运动状态和趋势。

Occupancy子模块的特性包括:
Volumetric Occupancy
Multi-Camera & Video Context
Persistent Through Occlusions
Occupancy Semantics
Occupancy Flow
Resolution Where It Matters
Efficient Memory and Compute
Runs in around 10 milliseconds
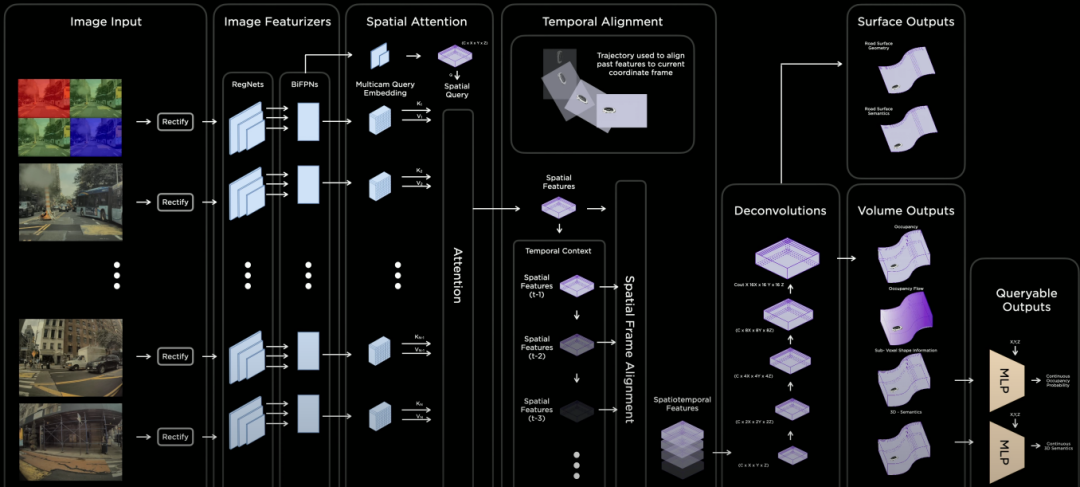
图 4Tesla Occupancy Network模块架构
在图 4中,输入采用未经过ISP处理的raw RGB图像(10-bit Photon Count Stream,36Hz,在低照场景下感光度高,噪声小),可以让特征提取模块同步也进行低照增强学习,可以将整体召回率提升3.9%,准确率提升1.7%左右。
从图 4还可以看出,Occupancy Network在Rectify层进行图像的View Transformation,然后采用Regnet + BiFPN进行特征提取,Attention模块采用图像位置编码,采用Key, Value和Query来生产occupancy feature volume。利用里程计的定位信息进行栅格特征的时间轴对齐,以及特征信息时空融合后会生成4D Occupancy Grid。
通过Deconvolution进行特征增强到原有尺寸,可以通过网络层输出Volume(Occupancy Volume, Occupancy Flow, Sub-Voxel形状信息,和3D的语义信息)和Surface(道路表面几何信息和语义信息)。对接Volume还可以输出轻量级可查询的输出,包括连续的Occupancy概率和3D语义理解,这种设计思路除了可以提供Occupancy的速度加速度外,查询功能还可以提供类似NeRF的分辨率可变化的聚焦能力。输出3D Volume和Surface信息,可以提供NeRF状态信息,通过Volumetric Rendering来生成不同角度的3D场景重建。
总体而言,Tesla AI day上介绍的纯视觉的Occupancy Network的推理计算时间在10毫秒左右,对应视频的36Hz采样速度,与10Hz采样速度的LiDAR而言,对高速目标的感知能力,可以有很强的优势。同时从2D BEV特征演进到3D Occupancy特征,可以有效应对曲面地面感知和有高低变化的车道线感知,提升3D目标轮廓的定位误差。
Tesla采用低精度LD地图并对车道线几何/拓扑关系的信息,车道线数量,宽度,以及一些特殊车道属性等信息来进行编码,与视觉感知的特征信息一起用来生成车道线Dense World Tensor提供给Vector Lane模块,由于篇幅原因其具体细节将会另文进行对比分析。
ADS感知计算的演进趋势分析
对于自动驾驶ADS行业,我们可以将其核心演进趋势定义为群体智能的社会计算,简单表述为,用NPU大算力和去中心化计算来虚拟化驾驶环境,通过数字化智能体(自动驾驶车辆AV)的多模感知交互(社交)决策,以及车车协同,车路协同,车云协同,通过跨模数据融合、高清地图重建、云端远程智驾等可信计算来构建ADS的社会计算能力。
在真实的交通场景里,一个理性的人类司机在复杂的和拥挤的行驶场景里,通过与周围环境的有效协商,包括挥手给其它行驶车辆让路,设置转向灯或闪灯来表达自己的意图,来做出一个个有社交共识的合理决策。而这种基于交通规则+常识的动态交互,可以在多样化的社交/交互驾驶行为分析中,通过对第三方驾驶者行为和反应的合理期望,来有效预测场景中动态目标的未来状态。这也是设计智能车辆AV安全行驶算法的理论基础,即通过构建多维感知+行为预测+运动规划的算法能力来实现决策安全的目的。
在ADS动态和不确定性的场景中,环境需要建模成部分可观察的马尔可夫决策过程MDP即POMDP,为了降低计算复杂度,一般都选择离散化空间或者部分连续空间来解决POMDP问题。对不确定性信息评估的一种常用的做法是对当前状态进行概率分布进行构建,得到一个置信(belief)状态,这种形态可以通过离线或者在线构建。
驾驶者的决策过程,可以转化为对部分可观察环境虚拟化或参数化,同时对个体间社交选择的偏爱进行参数化,嵌入到价值函数中去,通过基于优化的状态反馈策略,寻求驾驶群体利益最大化问题的最优解。
ADS算法的典型系统分层架构,一般包括传感层,感知层,定位层,决策层(预测+规划)和控制层。ADS算法的典型系统分层架构如图5所示,对ADS感知计算而言,目前已经从多模数据结构化+决策层后融合演进到了一个全新的Birds-Eye-View (BEV)统一空间感知融合架构,即4D时空的多模态多任务学习+传感信息协同共享。对比Tesla纯视觉模态的技术方案,ADS感知算法面临的类似挑战具体体现在:
能够在统一BEV空间支持多模传感器感知融合,通过Multiview Camera +LiDAR/Radar组合模式,但需要解决3D目标定位误差问题、漏检误检、目标发现不及时问题,以及路面下曲面目标感知、车道线信息缺失/不规则/不清晰、3D场景下复杂车道线感知能力不足等问题。
能够在统一BEV空间支持多模组合多任务共享,需要提升有限算力下的计算效率,更需要降低设计方案的计算复杂度。
能够提供全场景的适配能力,需要解决算法模型在信息提取中对极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的泛化感知能力,降低对标注数据和高清地图的过度依赖。
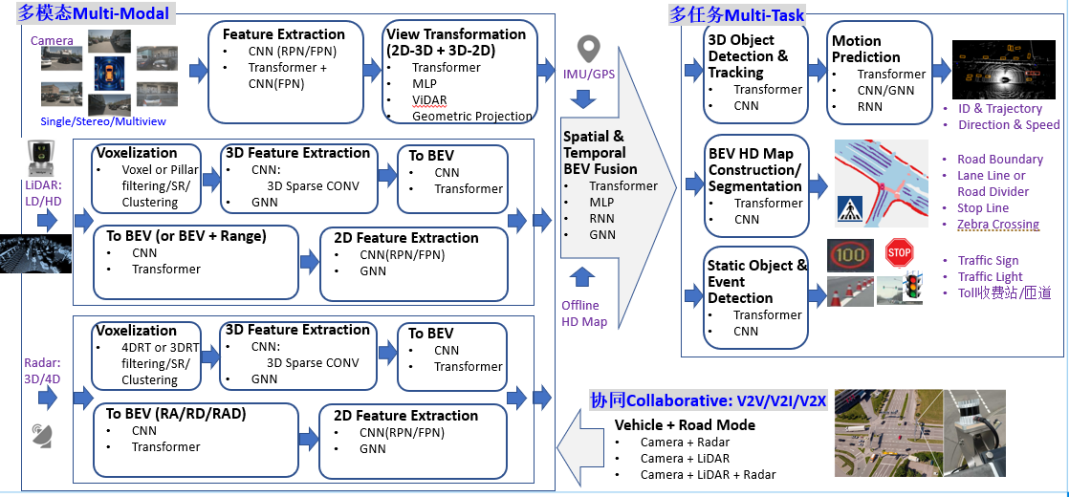
图5BEV统一空间感知融合架构案例
ADS感知计算:系统计算复杂度挑战
ADS感知计算,其实主要是对物理世界的一个3D几何空间重建任务。对比Tesla和行业主流设计方案的异同,可以看出选择BEV空间的独特优势,它消除了2D任务中常见的Perspective-View(PV,2D空间)下重叠遮挡或者比例问题,便利于随后进行预测规划和控制。如图5所示,BEV感知计算可以分成三个部分:
BEV Camera:纯视觉或者以视觉为主,Single/Stereo/Multi-view多方位配置, 感知计算包括3D目标识别和分割
BEV LiDAR:基于点云/Grid/Voxel进行目标检测或者场景分割任务
BEV Radar:基于Range/Angle/Doppler进行大目标检测或者场景分割任务
BEVFusion:多模融合,包括Camera, LiDAR, GNSS, Odometry, HD Map, CAN-bus等等。
在图5中,BEV感知计算通常包括2D或者3D特征提取,View Transformation视觉变换(可选,也可以直接采用Front-View,或者直接对2D特征进行3D目标识别)和3DDecoder。采用2D特征提取或者2D View Transformation在2D空间进行显然可以降低计算复杂度,但会带来性能损失。
3DDecoder可以在2D/3D空间直接对特征进行3D感知多任务计算,包括3D目标bounding box检测,BEVmap Segmentation分割, 3D Lane Keypoints检测等等。
类似于Tesla所采用的BEV Camera纯视觉方案中,View Transformer模块可以分成两个部分:
1、2D-3D Mapping:
Geometric Projection:工业界较常用,数学计算复杂度高,多在CPU上进行运算,负载重,而且空间对齐也是一个问题,类似Tesla同时采用一个额外NN网络进行补偿矫正。
DNN-alike:计算复杂,可以用GPU/NPU进行运算,减少CPU负荷,如果能够添加深度信息提取通道,可以增强系统性能。
2、3D-2DMapping
Grid Sampler:工业界常用,但依赖于Camera参数,长期使用有偏移问题。
MLP或者Transformer:通过Cross-Attention来进行几何空间变换,计算量会比较大。
在图5中,BEVLiDAR通道,通常可以采用几种数据表征Points, BEVGrid,Voxel, Pillar。相对而言,Pillar是一种特殊类型的Voxel,通过柱形映射到2D空间,拥有无限高度属性。采用Pillar特征可以大大减少内存空间和计算复杂度,可以说是工程化中一个非常好的折衷。
在这里值得一提的是,对于Transformer进行3D目标检测的计算复杂度问题,尤其是针对BEVLiDAR或者BEVRadar数据,在覆盖的驾驶区域非常大的场景(100m x 100m)下,如何有效降低内存需求和感知计算复杂度。这需要从Transformer网络架构层面针对超大点云数据处理方式进行有效调整。
以3D目标检测与跟踪为例,Transformer Encoder中输入Token数量显著变多后,Token间自关注Self-Attention模块计算对内存需求成二次元非线性方式加速度增加。简单地采用Point-based或者BEV-Grid-based亚采样导致Token跨越区域或者Grid会导致目标检测性能严重受损。
一种设计思路案例如图 6所示,用计算复杂度低的主干网络backbone,例如PointPillars来完全替代Transformer Encoder。Transformer Encoder的优势是在于可以更好地提取上下文的全局特征信息,而CNN网络可以很好地对上下文局部信息进行编码和特征提取。
主干网络的特征输出进行降维变换成一系列Token(特征向量),而且网络类型的可选取范围也相对比较广,只要能够在BEV Grid或者3D空间内提供特定位置的特性向量就可以。Transformer Encoder这个计算瓶颈模块被移除后, Token长度N的选取可以更大一些,如果decoder输入查询Q的数量是M, 对应Transformer Decoder的最大Cross Attention矩阵的尺寸是N x M,其中N 远远大于M。
在Decoder分层传递中通过采用一种查询刷新的策略,可以有效弥补Transformer Encoder被替换后估计精度下降的问题。值得一提的是Transformer Decoder输出的矢量是可以语义解释的Object-bound的特征向量,可以直接做为ReID特征项用于目标跟踪,同时这种设计思路可以拓展到Multi-modal多模输入。
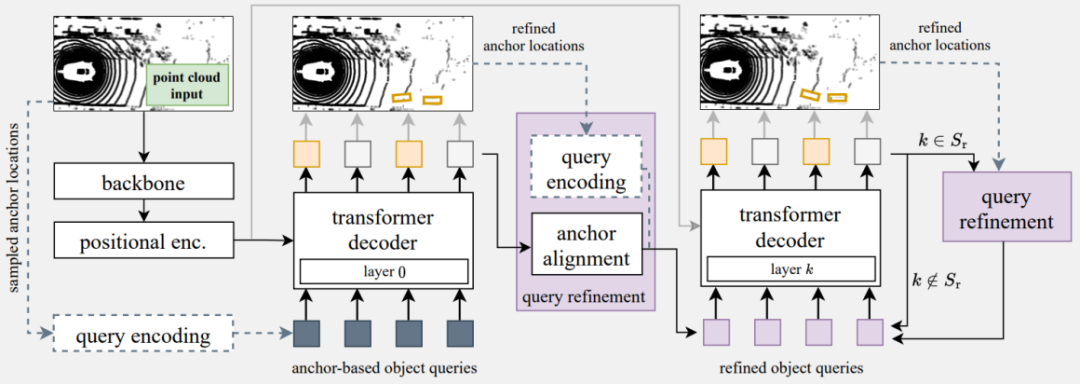
图63D目标检测的改进架构案例
审核编辑:刘清
-
检测器
+关注
关注
1文章
948浏览量
50142 -
ADAS技术
+关注
关注
0文章
21浏览量
3592 -
FSD
+关注
关注
0文章
105浏览量
7144 -
MLP
+关注
关注
0文章
57浏览量
5034
原文标题:特斯拉ADS算法的自我革命
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
PCB与PCBA工艺复杂度的量化评估与应用初探!
基于纹理复杂度的快速帧内预测算法
嵌入式视频教程之软硬件关系的复杂度
嵌入式视频教程之软硬件关系的复杂度
嵌入式视频教程之软硬件关系的复杂度
如何降低LMS算法的计算复杂度,加快程序在DSP上运行的速度,实现DSP?
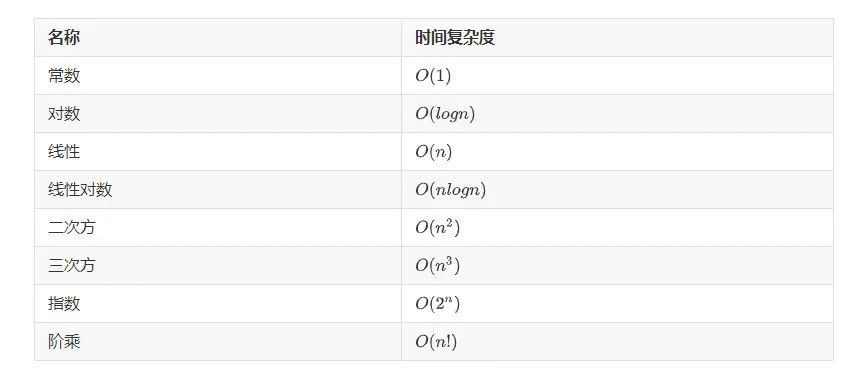
时间复杂度是指什么
图像复杂度对信息隐藏性能影响分析
基于移动音频带宽扩展算法计算复杂度优化
基于QR分解的低复杂度的可靠性约束算法

一种低复杂度稀疏信道估计算法的详细资料说明
常见机器学习算法的计算复杂度
如何计算时间复杂度




评论