 SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深层网络连体视觉跟踪的演变
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深层网络连体视觉跟踪的演变

论文:https://arxiv.org/pdf/1812.11703.pdf
程序:https://github.com/PengBoXiangShang/SiamRPN_plus_plus_PyTorch
摘要
基于孪生网络的跟踪器将跟踪表述为目标模板和搜索区域之间的卷积特征互相关。然而孪生网络的算法不能利用来自深层网络(如 resnet-50或更深层)的特征,与先进的算法相比仍然有差距。
在文章中我们证明了核心原因是孪生网络缺乏严格的平移不变性。我们突破了这一限制,通过一个简单而有效的空间感知采样策略,成功地训练了一个具有显著性能提升的基于ResNet网络的孪生跟踪器。此外,我们还提出了一种新的模型体系结构来执行分层和深度聚合,这不仅进一步提高了计算的准确性,而且还减小了模型的尺寸。我们在五个大型跟踪基准上获得了结果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。
该论文主要解决的问题是将深层基准网络ResNet、Inception等网络应用到基于孪生网络的跟踪网络中。在SiameseFC算法之后,很多的基于孪生网络的跟踪算法都使用浅层的类AlexNet作为基准特征提取器,直接使用预训练好的深层网络反而会导致跟踪算法精度的下降。
1.介绍
在平衡精度和速度方面,即使是性能好的孪生跟踪器,如SiamRPN,在OTB2015等跟踪基准上仍与现有技术有显著差距。所有这些跟踪都在类似于AlexNet的架构上构建了自己的网络,并多次尝试训练具有更复杂架构(如ResNet)的孪生网络,但没有性能提升。在这种观察的启发下,我们对现有的孪生追踪器进行了分析,发现其核心原因是绝对平移不变性(strict translation invariance)的破坏。由于目标可能出现在搜索区域的任何位置,因此目标模板的学习特征表示应该保持空间不变性,并且我们进一步从理论上发现,在新的深层体系结构中,只有AlexNet的zero-padding才能满足这种空间不变性要求。
我们引入了一种采样策略来打破孪生跟踪器的空间不变性限制。我们成功地训练了一个基于SiamRPN的跟踪器,使用ResNet作为主干网络。利用ResNet结构,提出了一种基于层的互相关运算特征聚合结构(a layer-wise feature aggravation structure),该结构有助于跟踪器从多个层次的特征中预判出相似度图。通过对孪生网络结构的交叉相关分析,发现其两个网络分支在参数个数上存在高度不平衡,因此我们进一步提出了一种深度可分离的相关结构,它不仅大大减少了目标模板分支中的参数个数,而且使模型的训练过程更加稳定。此外,还观察到一个有趣的现象,即相同类别的对象在相同通道上具有较高的响应,而其余通道的响应则被抑制。正交特性也可以提高跟踪性能。
综上所述,本文的主要贡献如下:
1.我们对Siam进行了深入的分析,并证明在使用深网络时,精度的降低是由于绝对平移不变性的破坏。
2.我们提出了一种采样策略以打破空间不变性限制,成功训练了基于ResNet架构的孪生跟踪器。
3.提出了一种基于层次的互相关操作特征聚集结构,该结构有助于跟踪器根据多层次学习的特征预测相似度图。
我们提出了一个深度可分离的相关结构来增强互相关,从而产生与不同语义相关的多重相似度图。
在上述理论分析和技术贡献的基础上,我们开发了一种高效的视觉跟踪模型,在跟踪精度方面更为先进。同时以35 fps的速度高效运行。我们称它为SiamRPN++,在五个大的跟踪基准上持续获得跟踪结果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。此外,我们还提出了一种使用MobileNet主干网的快速跟踪器,该主干网在以70 fps的速度运行时有良好的实时性能。
2.相关工作
RPN详细介绍:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC详细介绍:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN详细介绍:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
3.深层孪生网络跟踪算法
如果使用更深层次的网络,基于孪生网络的跟踪算法的性能可以显著提高。然而仅仅通过直接使用更深层的网络(如ResNet)来训练孪生跟踪器并不能获得预期的性能改进。我们发现其根本原因主要是由于孪生追踪器的内在限制。
3.1 孪生网络跟踪分析
基于孪生网络的跟踪算法将视觉跟踪作为一个互相关问题,并从具有孪生网络结构的深层模型中学习跟踪相似性图,一个分支用于学习目标的特征表示,另一个分支用于搜索区域。
目标区域通常在序列的第一帧中给出,可以看作是一个模板z。目标是在语义嵌入空间Φ(·)中从后续帧x中找到相似的区域(实例):
f(z,x)=\\phi(z)×\\phi(x)+b_i
其中b是偏移量。
这个简单的匹配函数自然意味着孪生网络跟踪器有两个内在的限制。
1.孪生跟踪器中使用的收缩部分和特征抽取器对绝对平移不变性有内在的限制。
f(z,x[\\Delta\\tau_j])=f(z,x)[\\Delta\\tau_j]
确保了有效的训练和推理。
2.收缩部分对结构对称性有着内在的限制,即:
f(z,x)=f(x,z)
适用于相似性学习。即如果将搜索区域图像和模板区域图像进行互换,输出的结果应该保持不变。
通过详细的分析,我们发现防止使用深网络的孪生跟踪器的核心原因与这两个方面有关。具体来说,一个原因是深层网络中的填充会破坏绝对平移不变性。另一个是RPN需要不对称的特征来进行分类和回归。我们将引入空间感知抽样策略来克服第一个问题,并在3.4中讨论第二个问题。
绝对平移不变性只存在于no padding的网络中,如修改后的AlexNet。以前基于孪生的网络设计为浅层网络,可以满足这一限制。然而,如果使用的网络被新型网络如ResNet或MobileNet所取代,padding将不可避免地使网络更深入,从而破坏了绝对平移不变性限制。我们的假设是,违反这一限制将导致学习到空间偏移。例如SiamFC在训练方法时正样本都在正中心,网络逐渐会学习到样本中正样本分布的情况,图像的中心会有更大的权重。
我们通过在带有padding的网络上进行模拟实验来验证我们的假设。移位定义为数据扩充中均匀分布产生的大平移范围。我们的模拟实验如下。首先,在三个单独的训练实验中,目标被放置在具有不同shift range(0、16和32)的中心。Shift为正样本距离中心点的距离。在收敛后,我们将测试数据集上生成的热图集合起来,然后将结果显示在图1中。
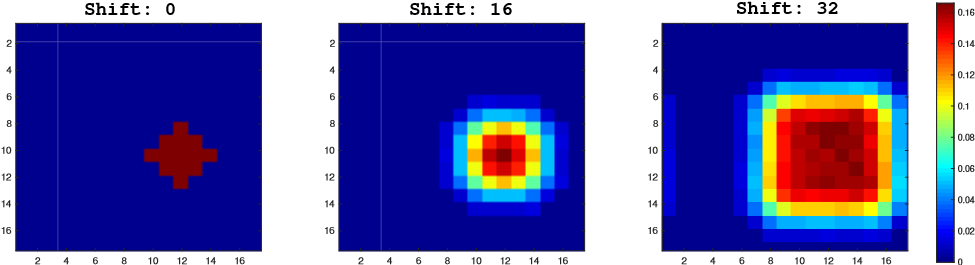
图1. 当使用不同的随机翻译时,可视化正样本的先验概率。在±32像素内随机平移后,分布变得更均匀。
在shift-0模拟中存在很强的中心偏移,只有中心位置具有较大的响应值,边界区域的概率降为零。另外两个模拟表明,增加位移范围(shift range)将逐渐增加图中响应的范围。分析表明32-shift的总热图更接近于测试对象的位置分布。因此空间感知抽样策略有效地缓解了填充网络对严格平移不变性的破坏。
为了避免对物体产生中心偏差,我们采用空间感知采样策略,在训练过程中,不再把正样本块放在图像正中心,而是按照均匀分布的采样方式让目标在中心点附近进行偏移。用ResNet50主干训练SiamRPN。

图2.随机平移对VOT数据集的影响。
如图2所示,在VOT2018上 0-shift的EAO只有0.14,适当增加shift可以提高EAO(将算法的鲁棒性和准确性结合起来的一个综合指标)。Shift=64时EAO最高。
3.2 基于ResNet的孪生网络跟踪算法
基于以上分析,我们消除了对中心位置的学习偏差,任何现成的网络(如MobileNet,ResNet)都可以用于视觉跟踪。此外,还可以自适应地构造网络拓扑结构,揭示深度网络的视觉跟踪性能。
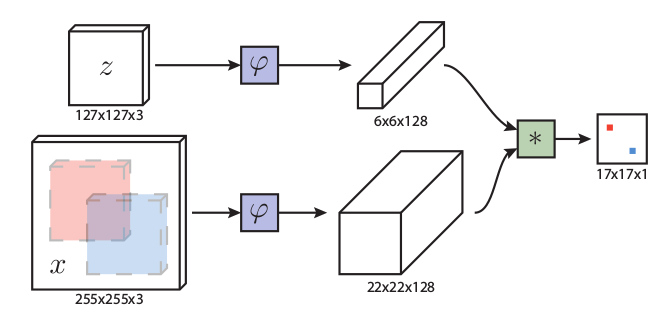
在本小节中,我们将讨论如何将深度网络传输到我们的跟踪算法中,实验主要集中在ResNet-50 。原来的ResNet有32 pix的大stride,不适合密集的孪生网络预测。如图3所示,我们通过修改conv4和conv5块以获得单位空间步幅,将后两个块的有效步幅从16像素和32像素减少到8像素,并通过扩大卷积增加其感受野。在每个块输出端附加一个额外的1×1卷积层,将通道减少到256。

图3.我们提出的框架的插图。给定目标模板和搜索区域,网络通过融合多个SiamRPN块的输出来输出密集预测。每个SiamRPN块都显示在右侧。
由于所有层的填充都保持不变,模板特征的空间大小增加到15,这给相关模块带来了沉重的计算负担。因此,我们裁剪中心的7×7区域作为模板特征,其中每个特征单元仍然可以捕获整个目标区域。
在SiamRPN的基础上,我们将互相关层(cross correlation layers)和全卷积层组合成头模块(head module) 用于计算分类分数(用S表示)和边界框回归器(用B表示)的头模块。SiameseRPN块用P表示。此外可以微调ResNet将提高性能,通过将ResNet提取器的学习速率设置为比RPN小10倍可以更好的用于跟踪任务。与传统的孪生方法不同,深层网络的参数以端到端的方式进行联合训练。这是第一个在深度孪生网络(>20层)上实现端到端学习的视觉跟踪算法。
3.3 分层聚合
利用像ResNet 50这样的深层网络,可以聚合不同的深度层。直观地说,视觉跟踪需要丰富的表示,从低到高,从小到大,从细到粗的分辨率。即使在卷积网络中有深度的特征,单独的层是不够的。复合和聚合这些特征可以提高识别和定位。
在以前的文献中,仅使用像AlexNet这样的浅层网络,多层特性不能提供多元的特征表示。然而,考虑到感受野的变化很大,ResNet中的不同层更有意义。浅层特征主要集中在颜色、形状等低级信息上,对于定位是必不可少的,而缺乏语义信息;深层特征具有丰富的语义信息,在运动模糊、大变形等挑战场景中有利于定位。我们假设使用这种丰富的层次信息对于跟踪任务是有帮助的。
在我们的网络中,多分支特征被提取出来共同推断目标定位。对于ResNet 50,我们探索从 后三个残差模块(residual blocks)中提取的多级特性,以进行分层聚合。我们将这些输出特征分别称为F3(z)、F4(z) 和F5(z)。如图3所示,conv3、 conv4、conv5的输出分别输入三个SiamRPN模块。由于三个RPN模块的输出尺寸具有相同的空间分辨率,因此直接在RPN输出上采用加权求和。加权融合层结合了所有的输出。
S_{all}=\\sum^5_{l=3}\\alpha_i×S_l,B_{all}=\\sum^5_{l=3}\\beta×B_l
S——分类,B——回归。

图4 不同互相关层的图示。(a)交叉相关(XCorr)层预测目标模板和搜索区域之间的单通道相似度图。(b)向上通道互相关(UP-XCorr)层通过在SiamRPN中将一个具有多个独立XCorr层的重卷积层级联而输出多通道相关特征。(c)深度相关(DW-XCorr)层预测模板和搜索块之间的多通道相关特征。
组合权重被分开用于分类和回归,因为它们的域是不同的。权重与网络一起进行端到端优化离线。与以前的论文相比,我们的方法没有明确地结合卷积特征,而是分别学习分类器和回归。请注意,随着骨干网络的深度显著增加,我们可以从视觉语义层次结构的充分多样性中获得实质性效果。
3.4 深度交叉相关
互相关模块是嵌入两个分支信息的核心操作。SiamFC 利用交叉相关层获得目标定位的单通道响应图。在SiamRPN 中,通过添加巨大的卷积层来扩展通道(UP-XCorr),交叉相关被扩展为嵌入更高级别的信息,例如anchors。巨大的up-channel模块严重影响参数分布的不平衡(即RPN模块包含20M参数,而特征提取器在SiamRPN中仅包含4M参数),这使得SiamRPN中的训练优化变得困难。
在本小节中,我们提出了一个轻量级互相关层,名为Depth wise Cross Correlation(DW-XCorr),以实现有效的信息关联。DW-XCorr层包含的参数比SiamRPN中使用的UP-XCorr少10 倍,而性能却很高。

图5. conv4中深度相关输出的通道。conv4中共有256个通道,但是在跟踪过程中只有少数通道具有高响应。因此我们选择第148,222,226通道作为演示,图中为第2,第3,第4行。第一行包含来自OTB数据集的六个对应搜索区域。不同的通道代表不同的语义,第148通道对汽车有很高的响应,而对人和人脸的反应很低。第222和第226通道分别对人和面部有很高的反应。
为实现此目的,采用conv-bn块来调整每个残差模块(residual blocks)的特征以适应跟踪任务。至关重要的是,bb的预测和基于anchor的分类都是不对称的,这与SiamFC不同(见第3.1节)。为了对差异进行编码,模板分支和搜索分支传递两个非共享卷积层。然后,具有相同数量的通道的两个特征图按通道进行相关操作。附加另一个conv-bn-relu块以融合不同的通道输出。然后,附加用于分类或回归输出的最后一个卷积层。通过将互相关替换为深度相关,我们可以大大降低计算成本和内存使用。通过这种方式,模板和搜索分支上的参数数量得到平衡,从而使训练过程更加稳定。
此外,有趣的现象如图5所示。同一类别中的对象在相同的通道上具有高响应(第148通道中的车,第222通道中的人,以及第226通道中的人),而其余通道的响应被抑制。由于深度互相关产生的通道方式特征几乎正交并且每个通道代表一些语义信息,因此可以理解该属性。我们还使用上通道互相关分析热图,并且响应图的解释性较差。
4.实验结果
4.1训练集及评估
训练
我们的架构的骨干网络在ImageNet 上进行了预训练,用于图像标记,已经证明这是对其他任务的非常好的初始化。我们在COCO,ImageNet DET,ImageNet VID和YouTube-Bounding-Boxes数据集的训练集上训练网络,并学习如何测量视觉跟踪的一般对象之间相似性的一般概念。在训练和测试中,我们使用单比例图像,其中127个像素用于模板区域,255个像素用于搜索区域。
评估
我们专注于OTB2015 [46],VOT2018 [21]和UAV123 [31]上的短时单目标跟踪。我们使用VOT2018-LT [21]来评估长时跟踪任务。在长时跟踪中,物体可能长时间离开视野或完全遮挡,这比短期跟踪更具挑战性。我们还分析了我们的方法在LaSOT [10]和TrackingNet [30]上的实验,这两个是最近才出现的单一目标跟踪的benchmarks。
4.2 实施细节
网络结构
在实验中,我们按照DaSiamRPN进行训练和设置。我们将两个同级卷积层连接到减少步幅(stride-reduced)的ResNet-50(第3.2节),用5个anchors执行分类和边界框回归。将三个随机初始化的1×1卷积层连接到conv3,conv4,conv5,以将特征尺寸减小到256。
优化
SiamRPN ++采用随机梯度下降(SGD)进行训练。我们使用8个GPU的同步SGD,每个小批量共128对(每个GPU 16对),需要12小时才能收敛。我们使用前5个时间段的0.001的预热学习率来训练RPN分支。在过去的15个时间段中,整个网络都是端到端的训练,学习率从0.005到0.0005呈指数衰减。使用0.0005的重量衰减和0.9的动量。训练损失是分类损失和回归的标准平滑L1损失的总和。
4.3 对比实验
主干架构
特征提取器的选择至关重要,因为参数的数量和层的类型直接影响跟踪器的内存消耗,速度和性能。我们比较了视觉跟踪的不同网络架构。图6显示了使用AlexNet,ResNet-18,ResNet-34,ResNet-50和MobileNet-v2作为主干的性能。我们画出了在OTB2015上成功曲线的曲线下面积(AUC)相对于ImageNet的top1精度的性能。我们观察到我们的SiamRPN ++可以从更深入的ConvNet中受益。
逐层特征聚合
为了研究分层特征聚合的影响,首先我们在ResNet-50上训练三个具有单个RPN的变体。单独使用conv4可以在EAO中获得0.374的良好性能,而更深的层和更浅的层则会有4%的下降。通过组合两个分支,conv4 和conv5获得了改进,但是在其他两个组合上没有观察到改善。尽管如此,鲁棒性也增加了10%,这说明我们的追踪器仍有改进的余地。在汇总所有三个层之后,准确性和稳健性都稳步提高,VOT和OTB的增益在3.1%和1.3%之间。总体而言,逐层特征聚合在VOT2018上产生0.414的 EAO分数,比单层基线高4.0%。
5.结论
在本文中,我们提出了一个统一的框架,称为SiamRPN ++,用于端到端训练深度连体网络进行视觉跟踪。我们展示了如何在孪生跟踪器上训练深度网络的理论和实证证据。我们的网络由多层聚合模块组成,该模块组合连接层次以聚合不同级别的表示和深度相关层,这允许我们的网络降低计算成本和冗余参数,同时还导致更好的收敛。使用SiamRPN ++,我们实时获得了VOT2018上先进的结果,显示了SiamRPN ++的有效性。SiamRPN ++还在La-SOT和TrackingNet等大型数据集上实现了先进的结果,显示了它的泛化性。
学习更多编程知识,请关注我的公众号:

-
神经网络
+关注
关注
42文章
4840浏览量
108147 -
视觉跟踪
+关注
关注
0文章
12浏览量
8932
发布评论请先 登录
双目立体视觉原理大揭秘(二)
基于立体视觉的变形测量
双目立体视觉的运用
双目立体视觉在嵌入式中有何应用
基于预测的立体视觉_力反馈研究
自动跟踪对称电源:Tracking Regulated Po
FM跟踪发射器FM Tracking Transmitter
图像处理基本算法-立体视觉
基于信息熵的级联Siamese网络目标跟踪方法
SiamFC:用于目标跟踪的全卷积孪生网络 fully-convolutional siamese networks for object tracking
SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network 孪生网络
SA-Siam:用于实时目标跟踪的孪生网络A Twofold Siamese Network for Real-Time Object Tracking
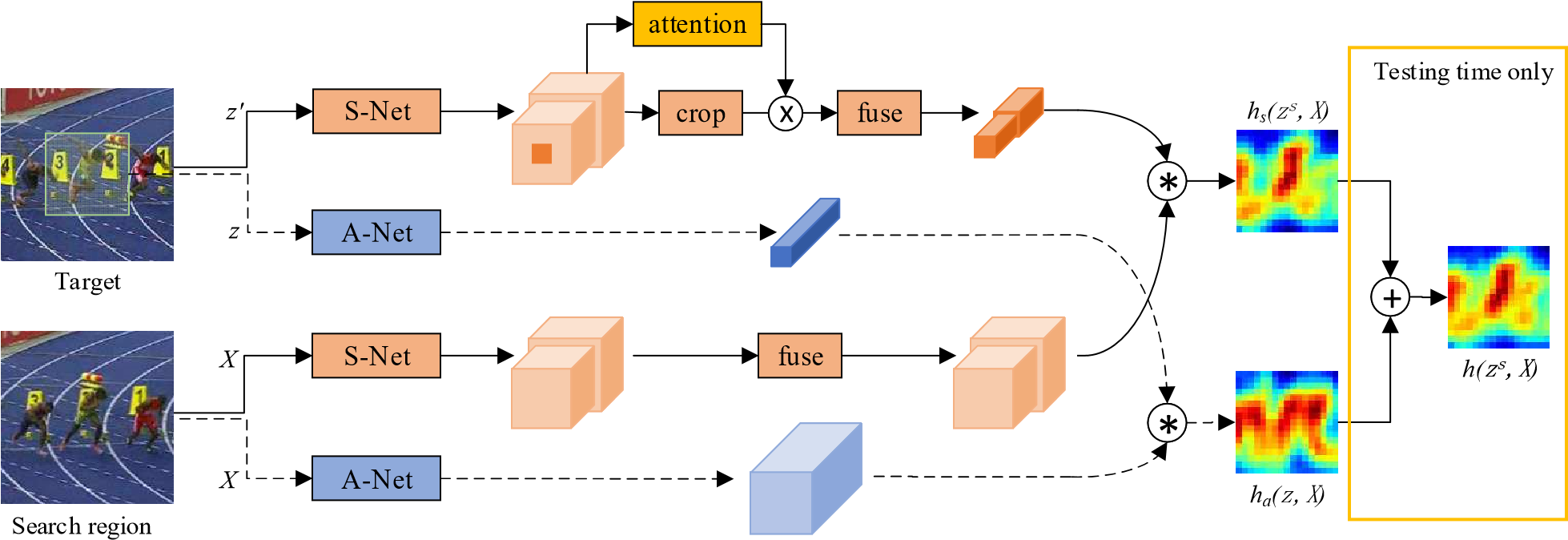
DW-Siam:Deeper and Wider Siamese Networks for Real-Time Visual Tracking 更宽更深的孪生网络
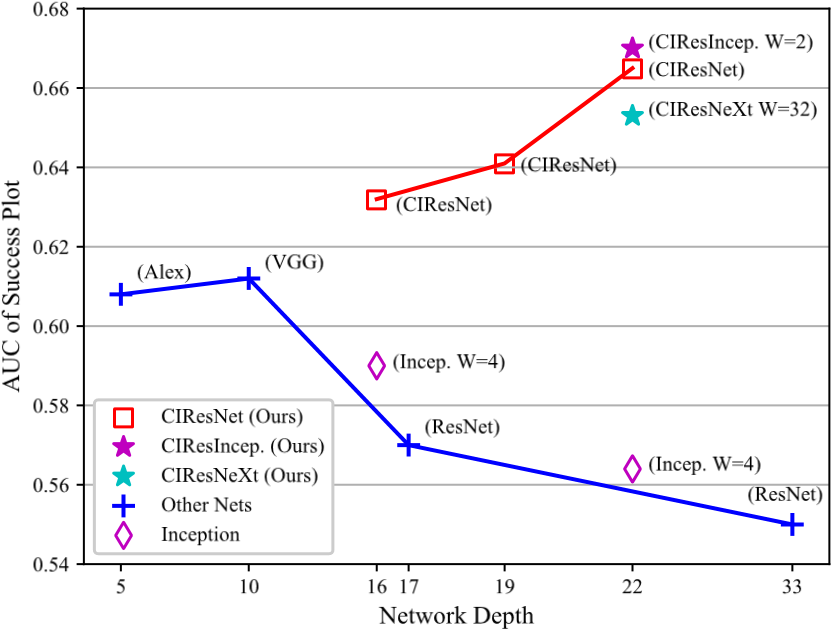
传输丰富的特征层次结构以实现稳健的视觉跟踪Transferring Rich Feature Hierarchies for Robust Visual Tracking




评论