 基于端到端的单噪声图像降噪和校正网络实现高质量的车牌识别
基于端到端的单噪声图像降噪和校正网络实现高质量的车牌识别

在本文中,我们提出了一种用于从真实世界中的低质量图像中进行车牌识别的算法。我们的算法建立在降噪和校正的框架上,并且每个任务都是由卷积神经网络来执行。在先前的研究中,降噪和校正任务分别被一个神经网络来处理。不同以往,我们提出了一种可训练的端到端的图像恢复网络,即“单噪声图像降噪和校正”网络(SNIDER),致力于一起解决这两个问题。此外,我们提出了一种利用辅助任务优化多任务训练损失的方法。在两个具有挑战性的LPR数据集AOLP-RP和VTLPs进行了大量的实验,证明了我们提出的方法的有效性,并且在从低质量的车牌图像中恢复高质量的车牌图像时本方法优于其他的SOAT方法。
一、研究背景
真实世界中的车牌识别(LPR)是多种智能运输系统(ITS)应用程序,如车辆重识别,户外场景理解,用于隐式保护的去识别等的基本问题之一。过去几年,LPR已经在理论,实验和数理方面得到了广泛的研究,以提供鲁棒的图像特征表示。一些LPR方法可以捕获图像和噪声的结构属性,以进行严格的约束。虽然已经取得了一些成果,但由于外观,噪声,角度和光照的变化,在野外进行车牌识别仍不能取得令人满意的效果。近年来,由于卷积神经网络的发展,许多计算机视觉任务取得了很大进步例如目标检测,语义分割,人脸识别等。同时CNN引导的LPR方法也被广泛用于解决识别现实世界中捕获的车牌。然而,现有的LPR方法仍然无法学习到野外所有类型的样本,这些算法实际上是将高质量的图像作为输入。通常,在现实世界中收集的车牌可能包含质量很低的图像,从而导致LPR性能下降。因此,在真实世界场景中开发鲁棒的LPR框架是必要的。
在本文中,我们基于多个辅助任务设计了一个端到端的单噪声图像降噪和校正网络(SNIDER)以实现更好的LPR。Figure1展示了我们的框架,其中SNIDER和预训练的LPR网络(这里是基于Darknet的YOLOV3网络)相结合。SNIDER包括两个子网络:降噪网络和校正网络。基于U-Net在恢复图像细节方面的成功,我们采用U-Net结构作为图像恢复骨干网洛,尝试从结构级别的细节中提取视觉内容。在去噪子网络(DSN)中,我们尝试将低质量的图像直接逐像素地转换为高质量的图像。DSN可以惩罚噪声和无噪声图像对之间的损失,从而获得无噪和有精细纹理的输出图像。但仅仅使用DSN,去噪图像仍不能令人满意,因为图像仍然具有随机的几何变化。因此,校正网络(RSN)被提出用于校正去噪后车牌图像的几何畸变。此外,我们提出利用新的辅助任务进一步优化SNIDER的DSN和RSN网络。一共有两个辅助任务:一个文本计数模块和一个分割预测模块。具体来说,我们使用CNN作为编码器来解决每个辅助模块。计数模块用来预测图像中的文本数量,被当作分类问题。在此模块中,尽管连续文本的边界模糊,文本计数模块仍可区分单个文本,从而使图像质量更适合于文本检测。在分割预测模块中,我们提出了一种二值分割方法来强调前景而不是背景,生成的分割结果使得车牌更加干净以进行文本识别。最后,学习辅助任务将引导图像恢复网络的中间特征,从而增加几何变化和低质量信息等困难。更重要的是,我们引入了新的损失函数,用于训练SNIDER和辅助任务,为LPR提供了更高质量的车牌数据。
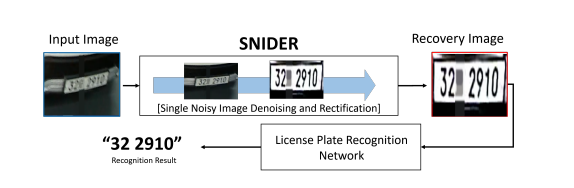
Figure 1
二、相关工作
在本节中,我们简要回顾与这项工作最相关的低质量图像恢复方法和车牌识别方法。
2.1低质量图像恢复
为了获得高质量的图像,大多数现有的方法都依赖于这样的假设:信号和噪声都是通过手工算法从特定的统计规律中产生。此外,一些非参数模型被开发来模拟图像噪声,但由于有限的观测结果,它们对野外不受约束的环境并不具有鲁棒性。近来,由于深度学习的发展,大多数降噪算法都是采用深度神经网络体系结构和数据驱动的方法设计的,而非依靠先验技术。尽管文本分类器对于清晰图像很有用,但由于文本几何形状不规则,因此仍难以识别。与现有方法不同,我们使用基于U-Net的CNN对图像进行去噪和校正。据我们所知,我们的研究可能是首个将上诉两个模块同时应用于LPR。
2.2 车牌识别
在深度学习出现之前,大多数传统的LPR方法都采用双阶段的处理流程,包括文本检测和文本识别。随着深度学习的发展,许多方法采用了单阶段流程即不进行文本检测。Li等通过将RNN与LSTM结合来提取深层特征表示,以获取车牌的连续特征。Bulan等基于完全卷积网络估计目标域和多个原域之间的域转换,以产生具有最佳识别性能的域。但这些方法仅考虑高质量的车牌图像,这容易导致模型在现实场景中性能下降。而且这些方法很少努力去改善图像样本质量,同时也占用了大量计算力。在我们的工作中,我们在真实场景中采用低质量图像恢复以提升LPR的性能。这是我们首次应用复杂的图像恢复技术来处理有挑战的真实环境,虽然有额外恢复模块,但我们的方法仍具有较高的计算效率和实时识别能力。
三、方法
我们提出的方法由三部分组成:1)主任务预测网络包括去噪网络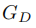 和校正网络
和校正网络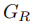 。2)辅助任务预测网络包括文本计数分类网络
。2)辅助任务预测网络包括文本计数分类网络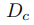 和分割网络
和分割网络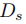 。3)用于文本检测和分类的网络LPR。整个框架可以用Figure2来表示。
。3)用于文本检测和分类的网络LPR。整个框架可以用Figure2来表示。
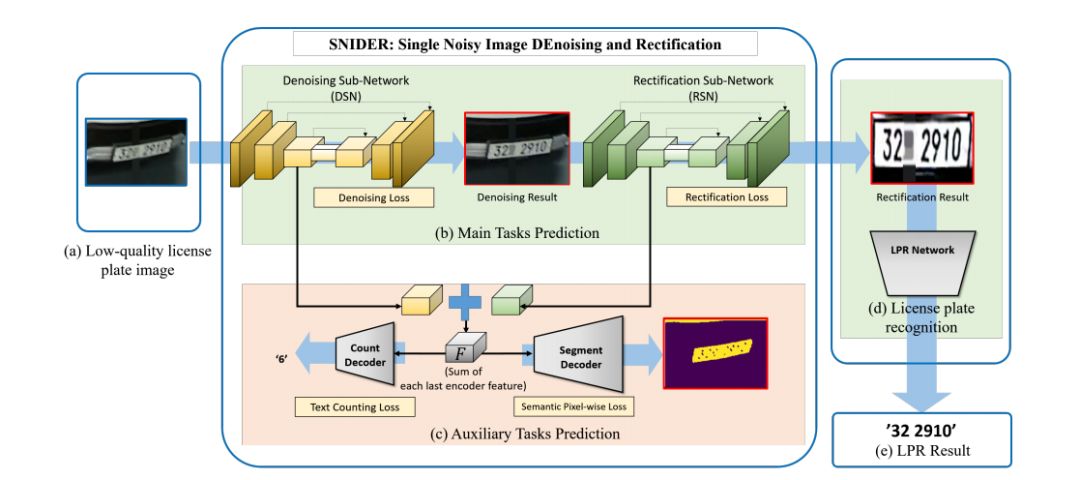
Figure 2
在训练中,用于主任务和辅助任务的数据集可以通过简单旋转(用于校正)和缩小尺寸(用于降噪)获得,如图Figure3所示。
Figure 3具体来说,一张原始图像 通过旋转不同的角度可以产生四张训练图像,其中
通过旋转不同的角度可以产生四张训练图像,其中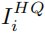 用于,
用于,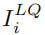 用于,
用于,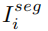 用于,c用于,
用于,c用于,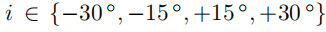 ,主任务的和网络从输入图像
,主任务的和网络从输入图像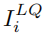 恢复为高质量图像。然后,LPR网络获取
恢复为高质量图像。然后,LPR网络获取
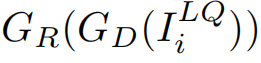
进行文本检测和识别。
3.1去噪和校正网络
我们的主任务网络包括两个子网络(即去噪子网络和校正子网络),第一个子网络以低质量图像为输入,输出为恢复图像。在本文中,我们设计了校正网络对来自降噪网络的输出结果进行校正。图像恢复结果[15]显示了U-Net的有效性,因为它可以提升图像中目标的细节信息,而不会对图像生成产生负面影响。因此,我们采用基于U-Net的结构,同时添加了跳跃连接,可以共享图像低级语义信息。
为了实现主任务,我们首先将输入到网络产生去噪后的结果。给定一对输入图像和未校正的去噪标签图像
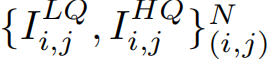
,的损失函数是逐像素的MSE损失,如等式(1)所示:
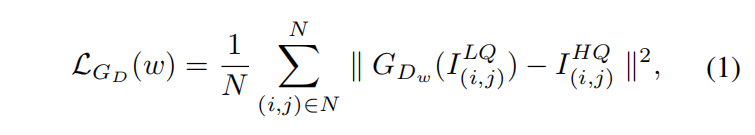
其中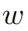 是去噪网络的参数。这种损失函数让网络不仅能提取输入图像语义信息也能生成像素级的高质量图像。然后校正网络从的输出开始处理,产生校正后的高质量图像,以更有利于LPR网络进行文本识别。训练图像对用
是去噪网络的参数。这种损失函数让网络不仅能提取输入图像语义信息也能生成像素级的高质量图像。然后校正网络从的输出开始处理,产生校正后的高质量图像,以更有利于LPR网络进行文本识别。训练图像对用
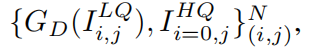
表示,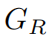 网络使用L1损失函数,如等式(2)所示:
网络使用L1损失函数,如等式(2)所示:
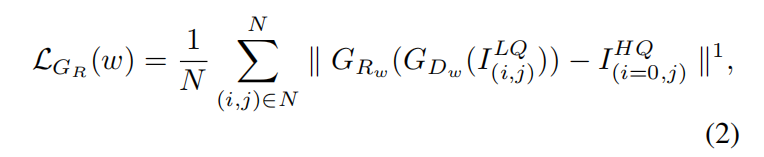
其中w是校正网络的参数。
和L2损失不同,像素级别的L1损失有助于保留目标的外观,例如图像颜色,亮度等。因此,在校正过程中,我们只会进行几何变换而不会对图像造成外观损伤,这对识别器是有用的。
3.2辅助任务预测
由于真实环境的复杂性,如文本的几何形态及其不规则,图像背景很复杂等导致车牌的二值化信息往往存在噪声。尽管我们希望和可以捕获鲁棒的特征来进行图像恢复,但是这种结构的结果并不能总是保证有良好的图像质量提升输出。因此,我们使用了两个辅助任务,即二值分割和计数估计,这将有助于我们的主任务网络产生更具区分性的代表特征。针对这个问题,我们将编码器最后一层的权值相加,以指导辅助任务网络更有效地从低质量图像中提取关键信息。
对于二值分割任务,我们介绍基于U-Net结构的分割解码器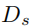 。的细节如Table1所示:
。的细节如Table1所示:

接收主任务编码器求和后的特征集F并输出车牌分割结果,每个像素位置的值代表该像素值属于车牌区域的概率。此外,用于分割的标签样本可以使用论文[4]中的OTSU算法得到,如Figure3所示。虽然[4]中的分割注释不能完全反映图像的实际细节,但我们的实验表明,这种辅助学习的策略在图像恢复方面取得了有效的进展。给定F和语义分割标签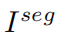 ,的损失函数为二元交叉熵损失,如公式(3)所示:
,的损失函数为二元交叉熵损失,如公式(3)所示:
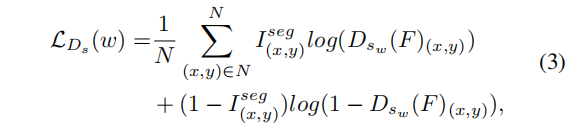
其中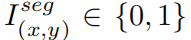 代表是否属于车牌区域。
代表是否属于车牌区域。
同时,我们发现恢复的样本通常不能区分连续的文本。所以我们增加了一个计数解码器来预测图像中字符的个数。因此,我们的扮演两个角色,第一个是使得相邻字符之间的分割更加清晰,另外一个角色是促进每个主任务的编码器产生更高质量的图像。的损失函数为L2损失,如公式(4)所示:
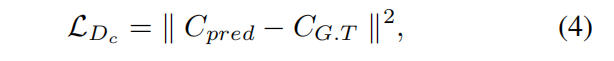
其中,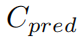 是预测值,
是预测值,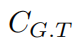 是标签。
是标签。
最终网络训练的损失函数如公式(5)所示:
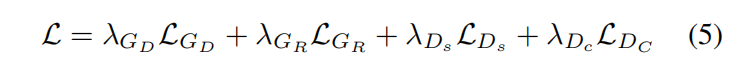
优化此损失函数更新网络的参数即可。
四、结果
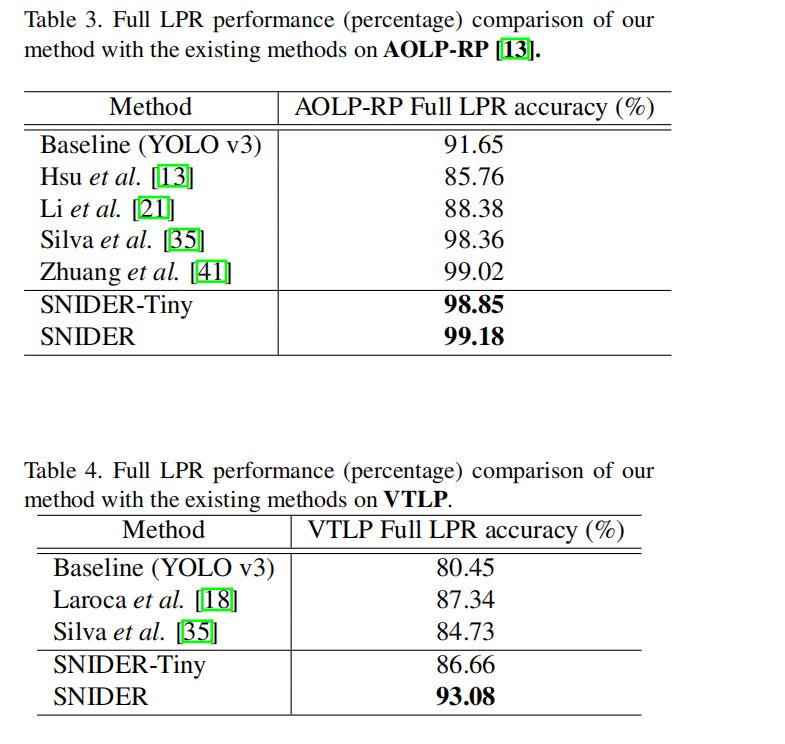
我们在两个大型的车牌数据集AOLP-RP和VTLPs上测试了我们的算法,我们在AOLP数据集上达到了惊人的99.18%的准确率,相比于直接使用YOLOV3做检测提升了近10个点,证明了我们算法的鲁棒性和有效性。在两个数据集上的测试结果如表Table3和Table4所示:
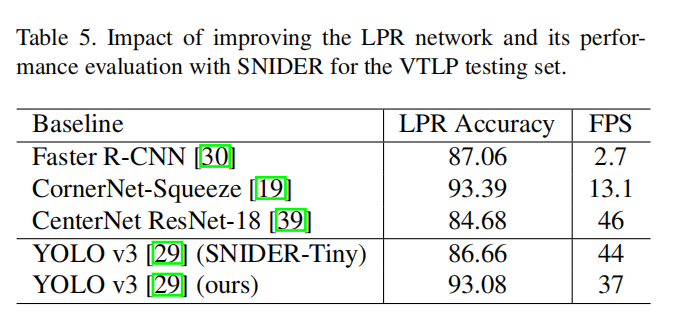
我们的算法在精度SOAT的同时,速度也可以达到实时,具有较好的实用价值。测试结果如图Table5所示:
五、结论
本文提出了一种新的端到端的可训练的图像恢复方法用于真实世界中的车牌识别。我们提出的恢复网络由两个子网络组成,即去噪子网络和校正子网络。特别地,我们设计了使用两个辅助任务来协助车牌图像恢复网络,从而使得恢复网络提取的特征更加鲁棒,以对抗现实场景中的几何变化和模糊数据。此外,一个新的损失函数被引入到骨干网络中,以提供正则化影响和提高恢复图像质量。在各种数据集上进行的广泛实验证明了在车牌恢复和识别方面的卓越性能。审核编辑:郭婷
-
车牌识别
+关注
关注
5文章
84浏览量
16753 -
深度学习
+关注
关注
73文章
5612浏览量
124669
原文标题:用于提高车牌识别的单幅噪声图像去噪和校正
文章出处:【微信号:www_51qudong_com,微信公众号:机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
移动端安卓车牌识别
源码交流=图像处理 实现夜间车牌识别、提取车牌图像[已测试]
XMOS推出用于高质量音频再现的端对端数字iPhone 底座

移动端车牌识别技术,实现手机摄像头扫描识别车牌
一种新型的移动端车牌识别技术,可支持Android、iOS平台

基于生成式对抗网络的端到端图像去雾模型




评论