 加速ViT模型新思路!Meta推出Token Merging
加速ViT模型新思路!Meta推出Token Merging

【导读】由Meta AI的研究人员推出Token Merging(ToMe),无需训练即可加速 ViT 模型。更重要的是,这个模型不需对token进行剪枝。
视觉变换器(ViT)在两年前进入大众视野,并成为计算机视觉研究的核心组成部分。 它成功将一个在自然语言处理领域的Transformer模型迁移到计算机视觉领域。从那时起,计算机视觉领域的进步已经加速。
尽管在成本与性能方面被超越,Vanilla ViT仍有许多优点。
它们是由简单的矩阵乘法组成的,这使得它们的速度比它们的原始运算量所显示的要快。
此外,它们支持强大的自监督预训练技术,如MAE(掩码自动编码器),可以产生最先进的结果,同时可以进行快速训练。
而且由于它们不对数据进行假设,它们可以几乎不加改变地应用在图片、音频、文本等诸多模式中。
当然,理想很丰满,现实很骨感。ViT模型的规模大,有较大延时。在资源有限的设备上,运行这个复杂模型会产生很大问题。
Token剪枝:变好了,但没完全好 针对运算慢的问题,研究人员给出了多个解决方案。其中一种常见的加速视觉 Transformer模型的方法是对进行token剪枝。 在运行时修剪标记,通过修剪不太重要的token产生高效的Transformer。如DynamicViT分层修剪冗余token,从而在分类任务中实现FLOPs减少。
然而,token剪枝有几个问题,其中最主要的,是由于修剪token会产生信息损失,因此,人们对ViT模型token的剪枝数量是有限的,为了减少信息损失,只能对不重要的token进行修剪。
而且,为了使修剪过的token有效,人们需要再次训练模型。这就造成额外的资源消耗。
更重要的是,token剪枝是动态的过程,需要根据不同的图像或句子确定token剪枝的不同数量。虽然这有利于提高准确性,但却不够实用实用性,因为这种情况下,数据不能再进行批处理。
为了解决这个问题,人们需要在剪枝过程中添加掩码,而这会进一步影响效率的提升。
简单来说,token剪枝确实让ViT跑得更快,但这是在信息损耗的代价上实现的。
TokenMerging:换个想法
怎样才能使ViT的速度类似于剪枝,但保持比剪枝更高的准确度呢?Meta AI研究团队给出了新的解题思路:Token Merging(ToMe)。

论文链接:https://arxiv.org/pdf/2210.09461.pdf
Token Merging选择将token结合,而非进行剪枝。由于其定制的匹配算法,它和剪枝一样快,同时更准确。另外,它的工作不需要任何额外的训练,所以你可以在巨大的模型上使用它来加快它们的速度,而不会牺牲很多准确性。
Meta的目标是在现有的ViT中插入一个Token Merging的模块,通过合并冗余的token,在不需要额外训练的前提下提高训练和推理的吞吐量。
基本思路是:在Transformer模型中,通过合并,使每层减少r个token。假设一个Transformer模型有L层,那么通过合并就可以减少rL个token。变量r的大小决定了速度和精度的关系,因为更少的标记意味着更低的准确度但更高的吞吐量。
值得注意的是,在Token Merging中,无论图像的内容如何,都会减少rL标记。这完美解决了token剪枝中无法进行批处理的问题。
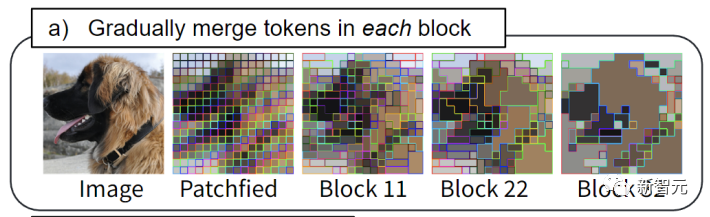
通过ToMe,类似的token批在每个Transformer块中被合并:例如,狗的皮毛被合并成一个token。
Token Merging被插入每个attention块和每个Transformer块。这也与token剪枝的工作流程形成对比。后者倾向于将剪枝步骤放在每个Transformer块的开头。
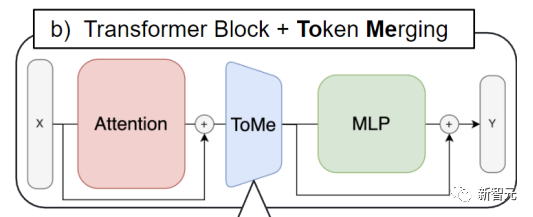
通过Token Merging,需要被合并的token的信息可以得到传播,ViT也能够借助attention块中的特征来决定需要合并哪些token。
具体做法
合并的第一步是确定相似的token。在Transformer中的QKV(query, key, value)已被提取的条件下,通过消融实验,研究团队发现使用key可以最好衡量token之间的相似度(下图紫色部分)。
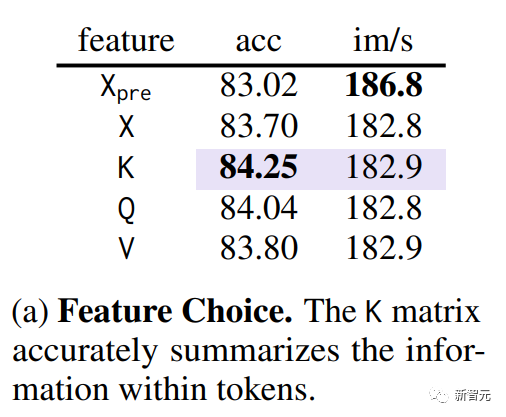
因为key已经总结了每个token中包含的信息,以便用于Attention中的dot-product来衡量token间的相似度。
除了研究哪个指标更好衡量token相似度外,还需要知道什么距离衡量相似度。通过实验研究团队发现,使用使用余弦距离来衡量toke之间的相似度可以获得最好的精度和速度的关系。
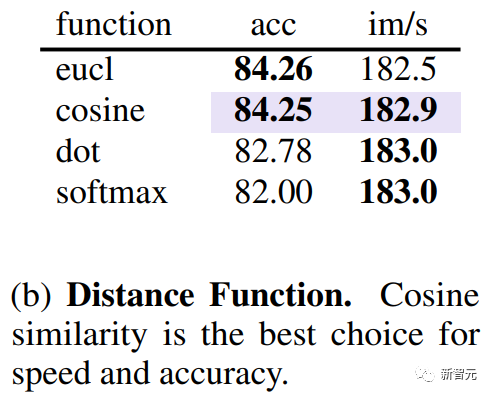
确定了token的相似性,接下来需要一个快速的方法来确定哪些token需要匹配,以减少总数的r。
Meta团队没有使用kmeans聚类算法或图分割算法,而是使用匹配算法,因为后者不仅可以精准匹配每一层token的数量,还能快速执行上千次匹配。这些都是迭代聚类算法无法完成的。
因此,Meta团队提出了一个更有效的解决方案。
设计目标如下。1.)避免任何无法并行化的迭代,2.)希望合并的变化是渐进的,因为聚类对多少个标记可以合并到一个组中没有限制(这可能会对网络产生不利影响),而匹配则使大多数标记没有被合并。
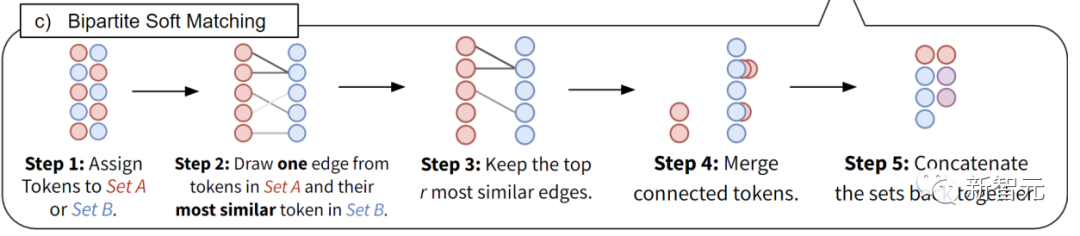
将所有token分为相同大小的2个集合A与B。
把从集合A中的每个token到B中与其最相似的token画一条边。
只留下最相似的r条边, 其余删掉。
融合仍然相连的边(特征取均值)。
把这两个集合拼在一起, 得到最终的合并结果。
通过这项独特的技术,可以提高ViT模型的吞吐量和实际训练速度。使用Token Merging可以将训练速度提高一倍。它可以用于图像、视频和音频任务,并且仍然可以达到最先进的准确性。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3873浏览量
52337 -
Meta
+关注
关注
0文章
326浏览量
12514 -
自然语言处理
+关注
关注
1文章
630浏览量
14756
原文标题:加速ViT模型新思路!Meta推出Token Merging,不靠剪枝靠合并
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
华为携手产业伙伴共筑Byte与Token融合发展新范式
运营商铺路,Token工厂造血:Token经济产业链迎来大爆发
Token成本激增、大模型集体涨价,Agent时代端侧算力迎来价值重估

零基础手写大模型资料2026
Token工厂加速兑现!迅策携手国家级数据交易所,深化垂类Token开发

Token中文新译名:「符元」——一文七个维度讲清Token的本质定义

加快进程!Meta计划2027年底前推出四代自研AI芯片
数字音频放大器新思路:MAX98360全方位解析

NVIDIA 推出 Nemotron 3 系列开放模型

PowerVR上的LLM加速:LLM性能解析

Arm与Meta深化战略合作
NVIDIA Spectrum-X 以太网交换机助力 Meta 和 Oracle 加速网络性能




评论