 一种将信息直接编码到预训练的语言模型中的结构
一种将信息直接编码到预训练的语言模型中的结构

边界信息的挖掘,对于NER的任务是非常重要的,这种类似于分词的功能,能够很好的挖掘到词语,并且把一个句子拆分成多个词语的构成。
以目前世界杯火的例子来说:“葡萄牙有望得到冠军”,可以按照边界信息,分割成为以下的组成,接着有了这种边界信息,我们可以用来做很多的上游任务。
在之前的工业技术分享中,NER的上一步就是由分割任务来做的。
NLP基础任务的极限在哪里?一文告诉你工业界是如何做NER的
下面我们进行本次论文的分享:
Unsupervised Boundary-Aware Language Model Pretraining for ChineseSequence Labeling | EMNLP2022
在这项工作中,提出了无监督的计算边界,并提出了一种将信息直接编码到预训练的语言模型中的结构,从而产生了边界感知BERT(BABERT)。船长在此处辩证的分析一下,无监督有什么好处,有什么坏处?
好处:
可以节省大量的人力,本模型可以直接用于中文的边界信息计算任务中。
坏处:
有监督的结果一般都比无监督的结果要好,从结果的角度来看,肯定是受限的。
实际上这里最好是利用半监督学习,使用到之前标注的词库信息,在进而进行无监督的训练,这点才是值得肯定的地方。
模型结构
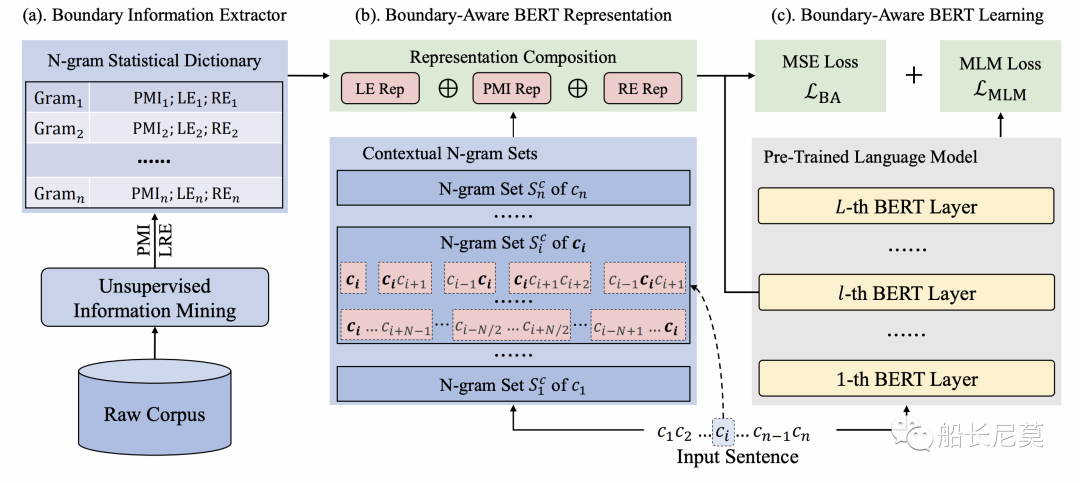
图1:边界感知预训练语言模型的总体架构。总共由三部分组成:(a) 边界信息提取器;(b)边界感知表示;(c) 边界感知BERT学习。
边界信息提取器
其实为什么第一个部分是边界信息提取器呢?因为我们的模型需要先猜一个结果,然后再判断他是否“正确”,再进行迭代来不断地进行学习。那么具体如何提取边界信息,本文分成了两个步骤。
从原始语料库中收集所有N-grams,以建立一个词典,在其中我们统计每个词的频率,并过滤掉低频项,去除掉噪声词语。
考虑到词频不足以表示汉语上下文中的灵活边界关系,本文进一步计算了两个无监督指标,这两个指标可以捕获语料库中的大部分边界信息。在下文中,我们将详细描述这两个指标。
公式预警,读者觉得复杂可以直接调到边界信息感知的BERT学习
点交互信息 PMI
给定一个N-gram,将其分成两个子字符串,并计算它们之间的互信息(MI)作为候选。然后,我们枚举所有子字符串对,并选择最小MI作为总PMI,以估计紧密性。设g={c1…cm}是由m个字符组成的N-gram,使用以下公式计算PMI:
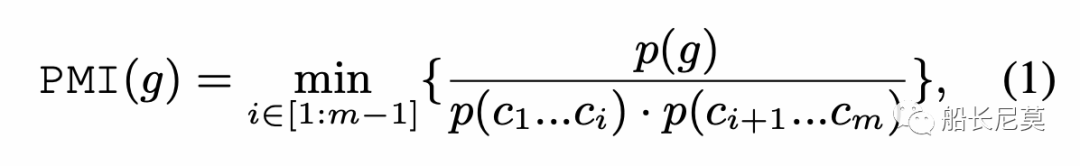
p()代表了文章中出现的概率。当m等于1的时候PMI这时也是最大的,即为1。除去这种情况后,如果PMI指数很高,也就意味着总字符串和子字符串有着同时出现的概率,例如总字符串“贝克汉姆”和子字符串“贝克”+“汉姆”,这时就让N-Gram “贝克”和“汉姆”更像是两个实体。
左右交叉熵
给定一个N-gram g,我们首先收集到左边的邻接字符集合Sl,之后我们用g和Sl的条件概率来计算左交叉熵:
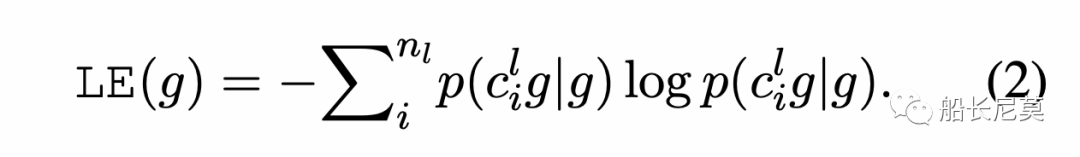
右交叉熵是同理的:
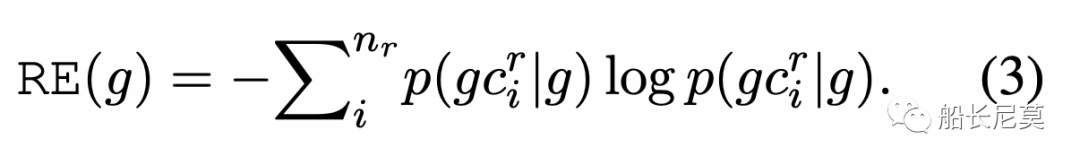
直观地说,左右交叉熵(LRE)代表了N-gram中相邻字符的数量。对于较低的LRE“汉姆”,表示它更可能是短语或实体的一部分。相反,具有更高LRE(例如,“贝克汉姆”),说明和上下文的交互很多,那么它很可能是单独的一个实体,这点是毋庸置疑的,越高说明当前的词语是单个实体的概率更大。作者使用的指标能够感知到什么是上下文,什么是实体,从而更好的做好边界计算的逻辑。
最后,我们利用PMI和LRE来测量中文上下文中的灵活边界关系,然后用上面的无监督统计指标更新每个N-gram。
边界信息表示
边界信息计算的核心就是上下文和实体之间的差别,针对于字符Ci,我们抽取出和Ci相关的N-Gram来代表Ci的上下文。设计一种组合方法,通过使用特定的条件和规则来集成S中N个词的统计特征,旨在避免统计信息的稀疏性和上下文独立性限制。
具体地,我们将信息合成方法分为PMI和熵表示。首先,我们连接了所有和字符Ci相关的N-Gram,去形成PMI的表达:

a=1+2+··+N是包含ci的N-Gram的数量。注意,在PMI表示中,每个N的位置是固定的。我们严格遵循N-gram长度的顺序和ci在N-gram中的位置来连接它们对应的PMI,确保位置和上下文信息可以被编码到交叉熵信息中:
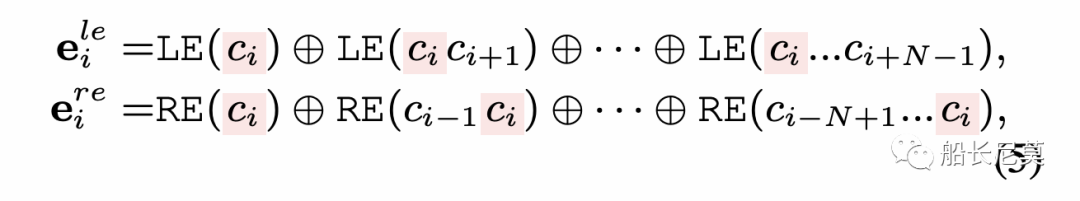
从而也就有了公式5,就是左右交叉熵。那么最终,我们就有了边界信息的表示,通过PMI和左右交叉熵的整合可以得到:
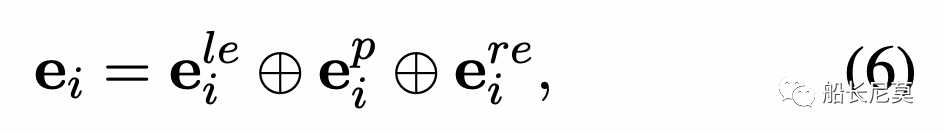
公式6很有意思,作者在文中提到,三个表达方式的顺序是很特殊的,左边的交叉熵放在了最左面,而右边的交叉熵放在了最右边,中间的是用来计算当前是否是实体的概率。那么我们可以这么理解这个公式,ei代表了 前文+实体+后文,也就是一种清晰的解决方案。
这个地方关于公式的地方读者可以自行跳过,下面我们来举一个具体的例子帮助理解,详见图2:
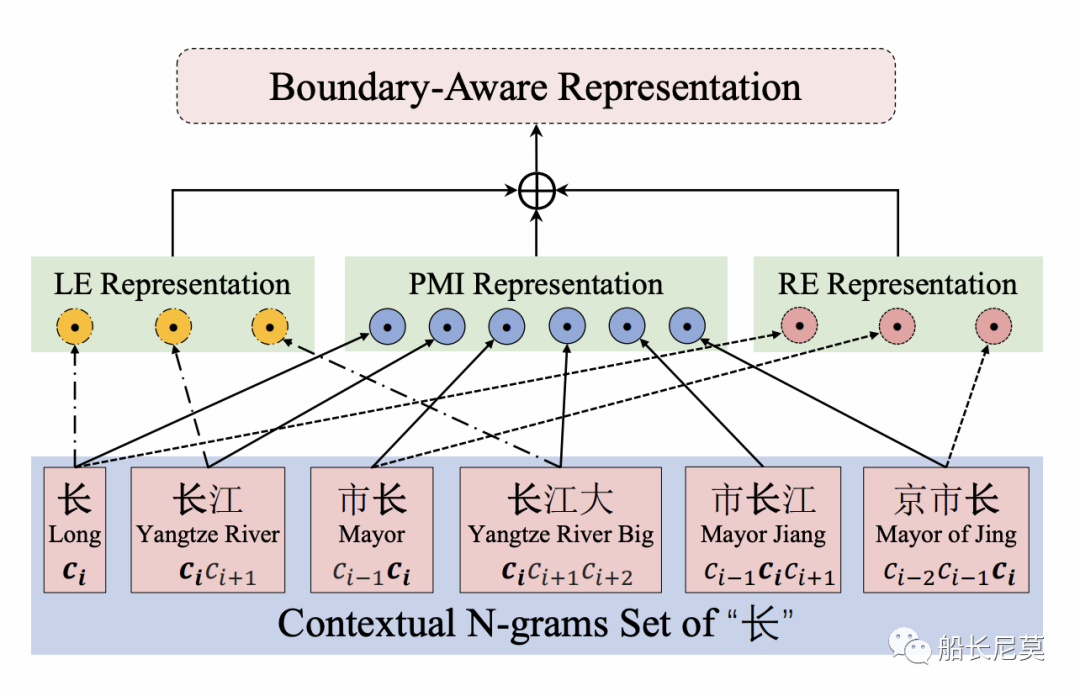
图2:字符边界感知表示的“长”在文本中“南京市长江大桥”
图2显示了边界感知表示的示例。首先整句话呢,会按照N-Gram (N=3)来进行拆分,所以我们有了下面的字符串序列,接着,我们三个公式开始计算各自的数值,LE包含了三个词,而PMI包含了所有词,RE包含了三个词,最终会把三个计算的数值并在一起作为边界信息感知的表达方式。
边界信息感知的BERT学习
边界信息感知的BERT是BERT预训练模型中的一种,在这节中,我们主要描述了如何把边界信息引入到BERT的训练中。
边界信息感知的目标训练
那么如何让BERT拥有这种信息的感知呢?实际上用MSE来规范BERT的hidden states,让这个和公式6中的ei来不断地接近。详细公式如公式7所示,其中h代表了BERT中某一层的隐状态,W是可学习参数矩阵。
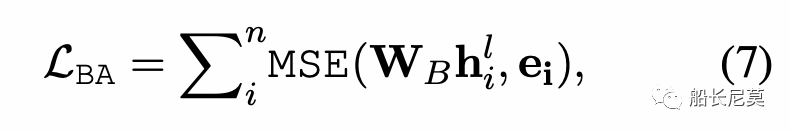
不过话说回来,船长平日做实验的时候,很少有发现MSE loss针对这种回归有效的,因为两个向量本身就在不同的向量空间,如何让他们两个接近呢?其实很难。
最终BERT的预训练损失函数,由两部分组成,也即公式7+完形填空任务。完形填空任务类似于把某一个单词挖空,然后让BERT去预测这个单词,这种方式能够加强BERT对于上下文的感知能力。
序列标注任务的微调
微调的方法是很简单粗暴的,对于序列标注的任务,只需要序列标注的信号,输入文本,模型的输出层加上CRF进行预测。因为本模型和BERT的结构几乎一样,所以在使用起来可以完全按照BERT+CRF的框架来走。
如何引入词语?
回到了我们做NER的初心,如何利用好词语的信息,是增强NER的关键之一,那么本文的方式就是利用Adapter的方式来引入词语的信息,他的方法和我之前分析过的论文是类似的,感兴趣的读者可以看看我之前发的文章。
如何把单词插入到预训练模型?达摩院研究告诉你答案
数据集
图3:基准数据集的句子数统计。对于没有测试部分的数据集,我们从相应的训练集中随机选择10%的句子作为测试集。
本文的数据集有三种类型,分别是NER (Named Entity Recognition), POS (Part-Of-Speech Tagging),CWS (Chinese Word Segmentation)。
结果
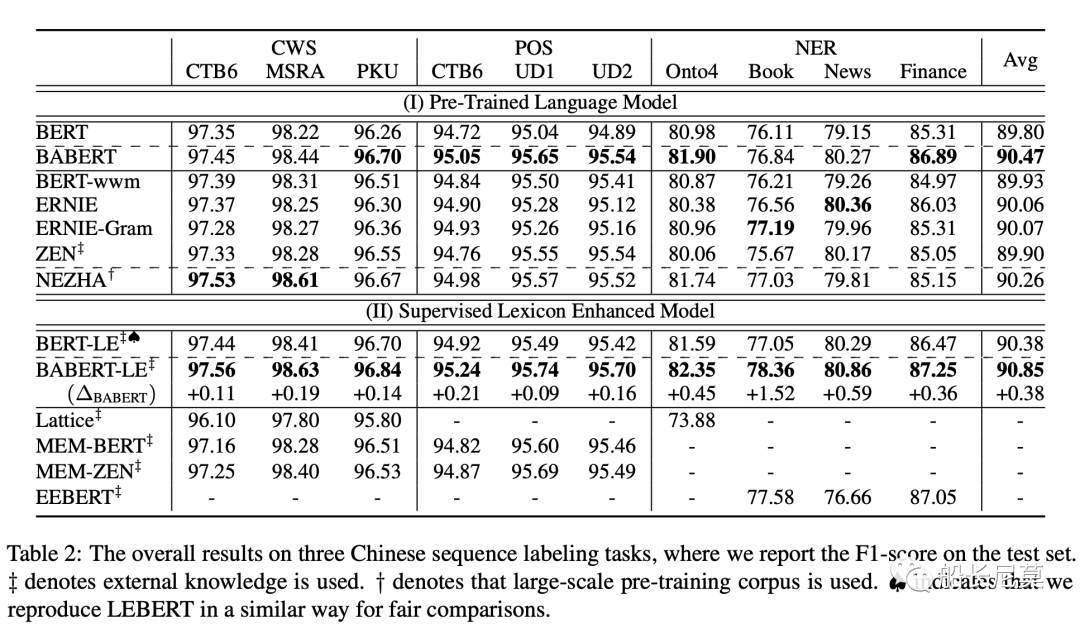
从结果的角度来讲,提升是比较明显的,相对于原始的BERT,很多数值都已经刷到了SOTA,确实是一篇很容易借鉴的工作。
写在最后
在本文,提出了BABERT,一种用于中文序列标记的新的无监督边界感知预训练模型。在BABERT中,给定一个中文句子,使用无监督统计信息计算边界感知表示以捕获边界信息,并在预训练期间将这些信息直接注入BERT的参数学习。与之前的工作不同,BABERT开发了一种以无监督方式利用边界信息的有效方法,从而减轻了基于监督词典的方法的局限性。在三个不同任务的十个基准数据集上的实验结果表明,方法非常有效,并且优于其他中文的预训练模型。此外,与监督词典扩展相结合可以在大多数任务上实现进一步的改进和最先进的结果。
接下来船长提几个问题,读者可以思考一下:
我想用这个模型,如何使用呢?
首先,先拿论文的框架训练出BABERT,然后在自己的语料上训练/微调,最终可以当做一个普通BERT来使用,我们可以做NER任务,也可以去做CWS任务。
这个模型好用吗?
客观的来说,这个模型有一些地方很难调参,比如说MSE Loss,还有MSE Loss中的隐状态的层数,我们并不知道哪一层的结果最好。总不能每次实验都去确定层数吧?这点很困难。除了上述的,其他的都比较好复现。
审核编辑:刘清
-
SCWS技术
+关注
关注
0文章
2浏览量
5949 -
PMI
+关注
关注
0文章
17浏览量
9796 -
NER
+关注
关注
0文章
7浏览量
6439
原文标题:如何将边界信息融入到预训练模型中?最新顶会告诉你答案
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在Ubuntu20.04系统中训练神经网络模型的一些经验
用PaddleNLP为GPT-2模型制作FineWeb二进制预训练数据集


VLM(视觉语言模型)详细解析

从Open Model Zoo下载的FastSeg大型公共预训练模型,无法导入名称是怎么回事?
小白学大模型:训练大语言模型的深度指南

用PaddleNLP在4060单卡上实践大模型预训练技术







 工商网监
工商网监
评论