 在NGC上玩转飞桨自然语言处理模型库PaddleNLP!信息抽取、文本分类、文档智能、语义检索、智能问答等产业方
在NGC上玩转飞桨自然语言处理模型库PaddleNLP!信息抽取、文本分类、文档智能、语义检索、智能问答等产业方

飞桨自然语言处理模型库 PaddleNLP,聚合众多百度自然语言处理领域自研 SOTA 算法以及社区开源模型,并凭借飞桨核心框架底层能力,不断开源适合产业界应用的模型、场景、预测加速与部署能力,得到学术界与产业界的广泛关注。今年,PaddleNLP 带来重大升级,覆盖信息抽取、文本分类、情感分析、语义检索、智能问答等自然语言处理领域核心任务。欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器,在 NVIDIA GPU 上进行体验!
PaddleNLP 开源首个面向通用信息抽取的产业级技术方案 UIE,零样本、小样本效果领先
通用信息抽取技术 UIE(Universal Information Extraction)大一统诸多任务,在实体、关系、事件和情感等 4 个信息抽取任务、13 个数据集的全监督、低资源和少样本设置下,取得了 SOTA 性能,这项成果发表在 ACL 2022。PaddleNLP 结合文心大模型中的知识增强 NLP 大模型 ERNIE 3.0,发挥了 UIE 在中文任务上的强大潜力,开源了首个面向通用信息抽取的产业级技术方案 UIE,其多任务统一建模特性大幅降低了模型开发成本和部署的机器成本,基于 Prompt 的零样本抽取和少样本迁移能力更是惊艳!
通过调用paddlenlp.TaskflowAPI即可实现零样本(zero-shot)抽取多种类型的信息,以实体抽取为例:
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
[{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手':[{'end':31,'probability':0.8981548639781138,'start':28,'text':'谷爱凌'}]}]
对于复杂目标,可以标注少量数据(Few-shot)进行模型训练,以进一步提升效果。PaddleNLP 打通了从数据标注-训练-部署全流程,方便大家进行定制化训练。以金融领域事件抽取任务为例,仅仅标注 5 条样本,F1 值就提升了 25 个点!
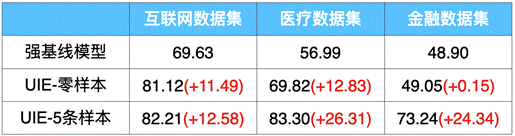
表 1:UIE 在信息抽取数据集上零样本和小样本效果(F1-score)
GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie开源文心 ERNIE-Layout,文档智能不再难
(1)文心 ERNIE-Layout 多语言版跨模态布局增强文档预训练大模型
文心 ERNIE-Layout 依托文心 ERNIE,基于布局知识增强技术,融合文本、图像、布局等信息进行联合建模,能够对多模态文档(如文档图片、PDF 文件、扫描件等)进行深度理解与分析,刷新了五类 11 项文档智能任务效果,为各类上层应用提供 SOTA 模型底座。
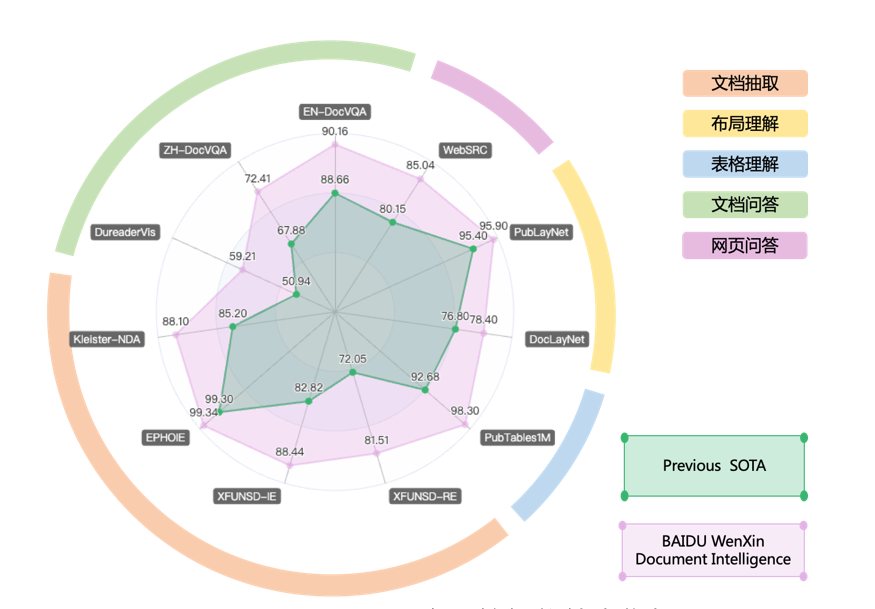
图 1:百度文档智能技术指标
(2)DocPrompt 开放文档抽取问答模型(基于 ERNIE-Layout)
DocPrompt 以 ERNIE-Layout 为底座,可精准理解图文信息,推理学习附加知识,准确捕捉图片、PDF 等多模态文档中的每个细节。通过PaddleNLP Taskflow,仅用三行Python代码即可快速体验DocPrompt功能。

DocPrompt 零样本效果非常强悍!能够推理学习空间位置语义,准确捕捉跨模态文档信息,轻松应对各类复杂文档:
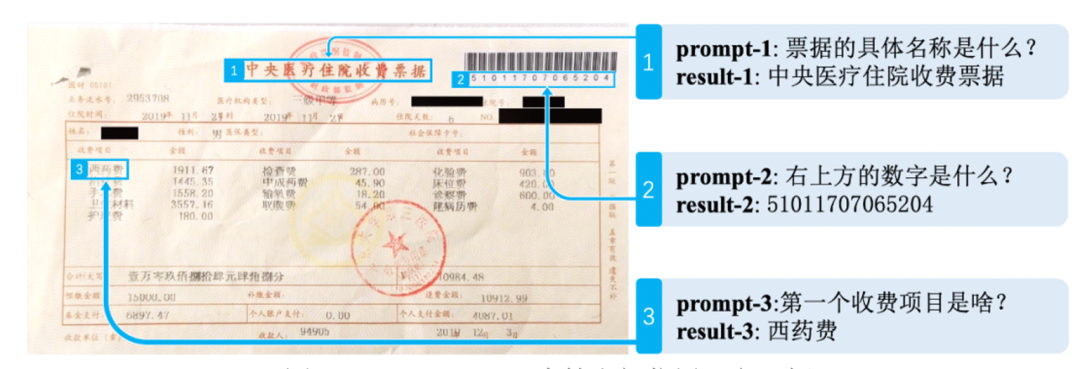
图 2:DocPrompt 可支持空间位置语义理解

图 3:DocPrompt 支持多维度无框线表格问答

GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layoutPaddleNLP 发布 NLP 流水线系统Pipelines,
10 分钟搭建检索、问答等复杂系统
Pipelines 将各个 NLP 复杂系统的通用模块抽象封装为标准组件,支持开发者通过配置文件对标准组件进行组合,仅需几分钟即可定制化构建智能系统,让解决 NLP 任务像搭积木一样便捷、灵活、高效。同时,Pipelines 中预置了前沿的预训练模型和算法,在研发效率、模型效果和性能方面提供多重保障。
Pipelines 中集成 PaddleNLP 中丰富的预训练模型和领先技术。例如针对检索、问答等任务,Pipelines 预置了领先的召回模型和排序模型,其依托国际领先的端到端问答技术 RocketQA 和首个人工标注的百万级问答数据集 DuReader。
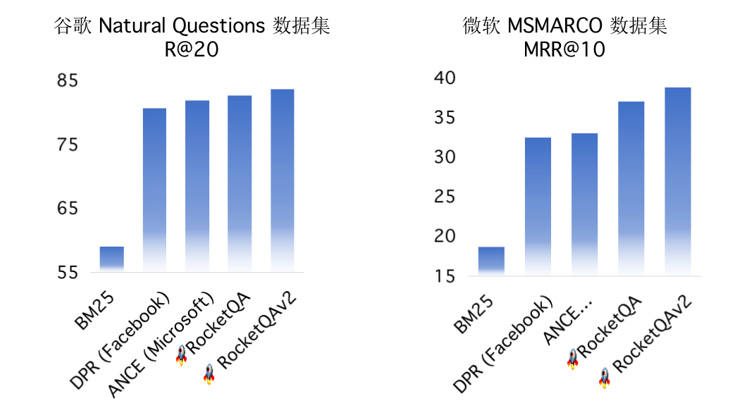
图 5:RocketQA 问答技术领先
为了进一步降低开发门槛,提供最优效果,PaddleNLP Pipelines 针对高频场景内置了产业级端到端系统。目前已开源语义检索、MRC(阅读理解)问答、FAQ 问答、跨模态文档问答等多个应用。以检索系统为例,Pipelines 内置的语义检索系统包括文档解析(支持 PDF、WORD、图片等解析)、海量文档建库、模型组网训练、服务化部署、前端 Demo 界面(便于效果分析)等全流程功能。

图 6:检索系统流水线示意图

图 7:检索系统前端 Demo
GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines发布多场景文本分类方案,新增数据增强策略,可信增强技术
文本分类任务是 NLP 领域最常见、最基础的任务之一,顾名思义,就是对给定的一个句子或一段文本进行分类。PaddleNLP 基于多分类、多标签、层次分类等高频分类场景,提供了预训练模型微调、提示学习、语义索引三种端到端全流程分类方案。
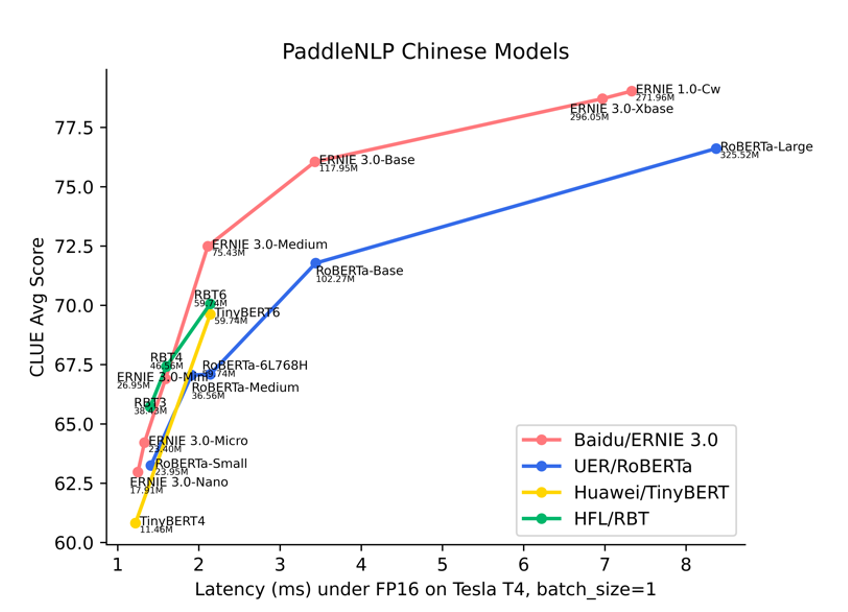
图 8:模型精度-时延图
以上方案均离不开预训练模型,在预训练模型选择上,ERNIE 系列模型在精度和性能上的综合表现已全面领先于 UER/RoBERTa、Huawei/TinyBERT、HFL/RBT、RoBERTa-wwm-ext-large 等中文模型。PaddleNLP 开源了如下多种尺寸的 ERNIE 系列预训练模型,满足多样化的精度、性能需求:
-
ERNIE 1.0-Large-zh-CW(24L1024H)
-
ERNIE 3.0-Xbase-zh(20L1024H)
-
ERNIE 2.0-Base-zh (12L768H)
-
ERNIE 3.0-Base(12L768H)
-
ERNIE 3.0-Medium(6L768H)
-
ERNIE 3.0-Mini(6L384H)
-
ERNIE 3.0-Micro(4L384H)
-
ERNIE 3.0-Nano(4L312H)
… …
除中文模型外,PaddleNLP 也提供 ERNIE 2.0 英文版、以及基于 96 种语言(涵盖法语、日语、韩语、德语、西班牙语等几乎所有常见语言)预训练的多语言模型 ERNIE-M,满足不同语言的文本分类任务需求。
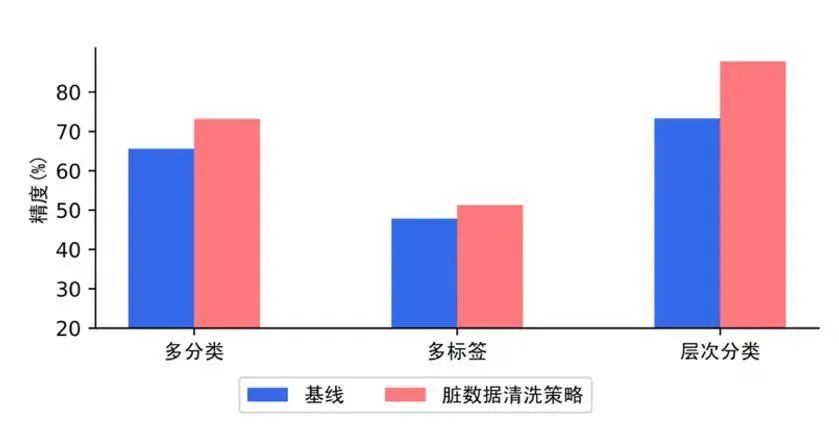
此外,PaddleNLP 文本分类方案依托TrustAI 可信增强能力和数据增强 API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化策略,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。例如,使用 TrustAI 进行脏数据清洗后,文本分类精度有明显提升。
新增 AutoPrompt 自动化提示功能,轻松上手 Prompt Learning,解决小样本难题
通过配置自动化运行的提示学习框架 AutoPrompt,开发者可以以最低学习成本上手提示学习。AutoPrompt 借鉴了 OpenPrompt 对 Template、Verbalizer 等概念的抽象和设计,并在此基础上扩展了更多特性,包括更灵活的提示设计,更便捷的算法切换,通过配置即可运行选择最优模型。
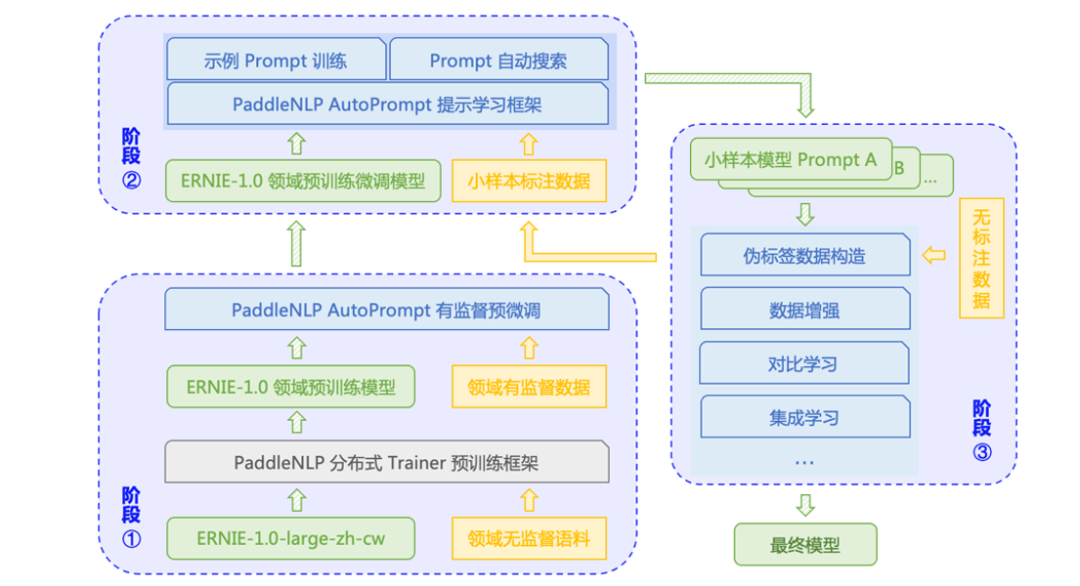
图 10:AutoPrompt 整体流程方案
AutoPrompt 使用文档:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/advanced_guide/prompt.md以上是 PaddleNLP 近期新发功能介绍,欢迎前往官方地址了解更多详情。喜欢的小伙伴欢迎star支持哦~您的支持是我们不断进取的最大动力!也欢迎加入 PaddleNLP 官方交流群,探讨前沿技术与产业实践经验。
PaddleNLP 地址:
https://github.com/PaddlePaddle/PaddleNLP
NGC 飞桨容器介绍
如果您希望体验 PaddleNLP 的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的 NVIDIA 的软件栈(如 CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
最佳的开发环境搭建工具 - 容器技术。
-
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub等等),或者你需要进行跨操作系统级别的迁移。
-
容器镜像方便了开发者的版本化管理
-
容器镜像是一种易于复现的开发环境载体
-
容器技术支持多容器同时运行
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL(DALI, RAPIDS)、训练(cuDNN, NCCL)和推理(TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
-
适配最新版本的 NVIDIA 软件栈(例如最新版本 CUDA),更多功能,更高性能。
-
更新的 Ubuntu 操作系统,更好的软件兼容性
-
按月更新
-
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取
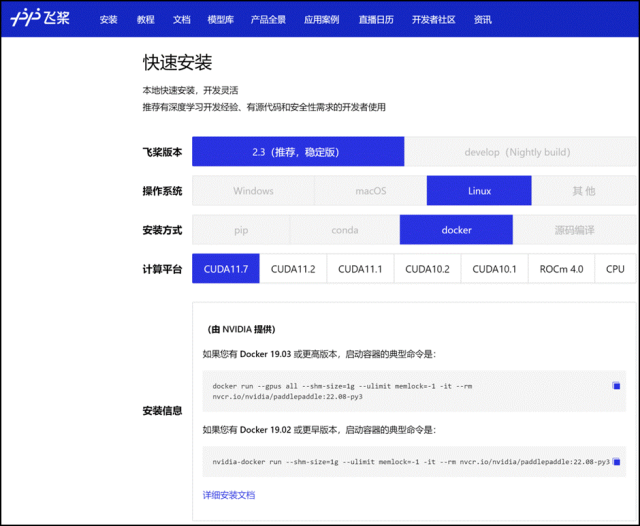
环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
-
Docker 引擎
-
NVIDIA GPU 驱动程序
-
NVIDIA 容器工具包
有关支持的版本,请参阅NVIDIA 框架容器支持矩阵和NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
NGC 飞桨容器正式安装:
要运行容器,请按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中Running A Container一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用 NGC 的更多信息,请参阅 NGC 容器用户指南。如果您有 Docker 19.03 或更高版本,启动容器的典型命令是:

*详细安装介绍 《NGC 飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html*详细产品介绍视频
【飞桨开发者说|NGC 飞桨容器全新上线 NVIDIA 产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飞桨与 NVIDIA NGC 合作介绍
NVIDIA 非常重视中国市场,特别关注中国的生态伙伴,而当前飞桨拥有超过 470 万的开发者。在过去五年里我们紧密合作,深度融合,做了大量适配工作,如下图所示。

今年,我们将飞桨列为 NVIDIA 全球前三的深度学习框架合作伙伴。我们在中国已经设立了专门的工程团队支持,赋能飞桨生态。
为了让更多的开发者能用上基于 NVIDIA 最新的高性能硬件和软件栈。当前,我们正在进行全新一代 NVIDIA GPU H100 的适配工作,以及提高飞桨对 CUDA Operation API 的使用率,让飞桨的开发者拥有优秀的用户体验及极致性能。
以上的各种适配,仅仅是让飞桨的开发者拥有高性能的推理训练成为可能。但是,这些离行业开发者还很远,门槛还很高,难度还很大。
为此,我们将刚刚这些集成和优化工作,整合到三大产品线中。其中 NGC 飞桨容器最为闪亮。
NVIDIA NGC Container – 最佳的飞桨开发环境,集成最新的 NVIDIA 工具包(例如 CUDA)

点击查看往期精彩内容
六:在 NGC 上玩转图像分割!NeurIPS 顶会模型、智能标注 10 倍速神器、人像分割 SOTA 方案、3D 医疗影像分割利器应有尽有!
五:在 NVIDIA NGC 上搞定模型自动压缩,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
四:在 NVIDIA NGC 上体验轻量级图像识别系统
三:在 NVIDIA NGC 上体验一键 PDF 转 Word
二:PaddleDetection 发新,欢迎在 NVIDIA NGC 飞桨容器中体验最新特性!
一:NVIDIA Deep Learning Examples飞桨ResNet50模型上线训练速度超PyTorch ResNet50
原文标题:在NGC上玩转飞桨自然语言处理模型库PaddleNLP!信息抽取、文本分类、文档智能、语义检索、智能问答等产业方案应有尽有!
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4039浏览量
97646
原文标题:在NGC上玩转飞桨自然语言处理模型库PaddleNLP!信息抽取、文本分类、文档智能、语义检索、智能问答等产业方案应有尽有!
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
意法半导体STM32 MCU AI模型库再扩容
openDACS 2025 开源EDA与芯片赛项 赛题七:基于大模型的生成式原理图设计
聆思大模型智能FAE,看得懂技术,答得准问题
【HZ-T536开发板免费体验】5- 无需死记 Linux 命令!用 CangjieMagic 在 HZ-T536 开发板上搭建 MCP 服务器,自然语言轻松控板
小白学大模型:从零实现 LLM语言模型

DevEco Studio AI辅助开发工具两大升级功能 鸿蒙应用开发效率再提升
VLM(视觉语言模型)详细解析






 工商网监
工商网监
评论