 在DeepStream上使用自己的Pytorch模型
在DeepStream上使用自己的Pytorch模型

DeepStream是NVIDIA专为处理多个串流影像,并进行智能辨识而整合出的强大工具。开发语言除了原先的C++,从DeepStream SDK 5.1也支持基于原先安装,再挂上Python套件的方式,让较熟悉Python程序语言的使用者也能使用DeepStream。
本文主要将其应用在Jetson Nano上,并于DeepStream导入自己的模型执行辨识。
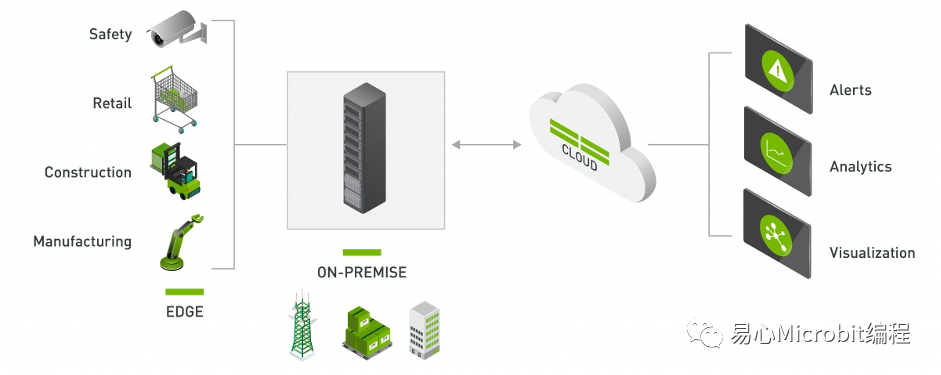
在Jetson Nano上面安装DeepStream
笔者使用的硬件为Jetson Nano 2GB/4GB,参照官方提供的步骤与对应的版本,几乎可以说是无痛安装。对比同样采用干净映像档,使用源码或是Docker安装的JetBot与Jetson Inference要快上许多。
执行官方范例
DeepStream有提供不少范例,不论是从CSI或USB接口的摄影机取得画面,或是多影像辨识结果显示,都能经由查看这些范例,学习如何设定。
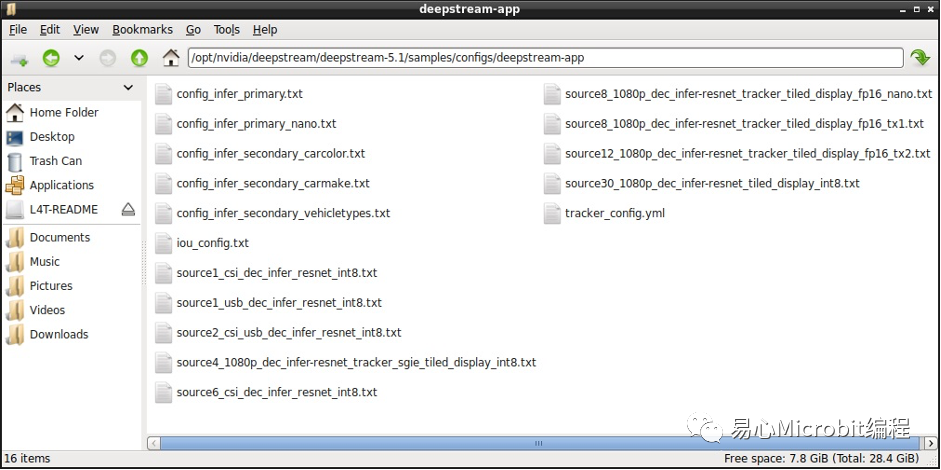
透过下列指令执行一个配置文件,查看DeepStream是否安装成功,这个配置文件会开启一部mp4影片,并模拟产生8个输入来源,经模型推论处理过后于同一个画面显示,点击单一个区块可以显示该来源的详细信息。实际应用上可以将各部摄影机的画面同时输出并进行处理。
deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt

使用自己的模型
如果您与笔者一样是NVIDIA官方课程小粉丝,从拥有Jetson Nano开始,就按部就班的跟着课程学习,那您一定看过下列三种不同主题的课程。
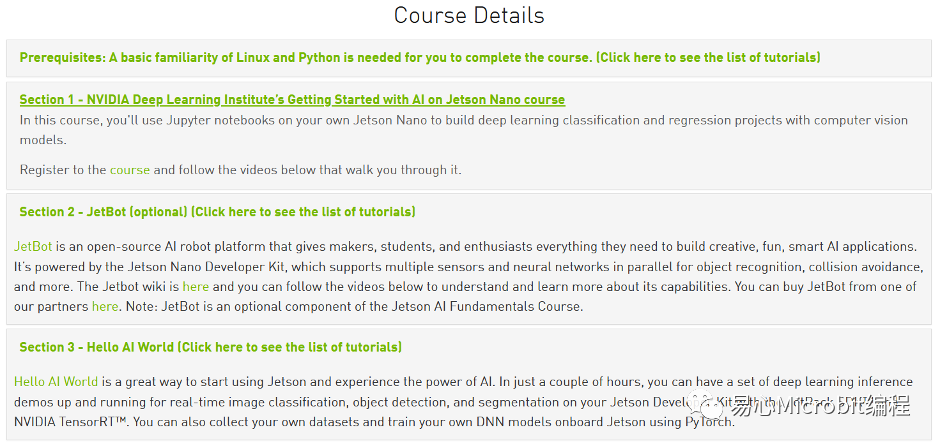
从入门的Section 1开始,到执行Section 2的JetBot自驾车项目,最后Section 3 Hello AI World。经过三个Section,您应该稍微熟悉Pytorch,并且也训练了不少自己的模型,特别是在Hello AI World有训练了Object Detection模型。既然都有自己的模型,何不放到DeepStream上面制作专属的串流辨识项目,针对想要辨识的项目导入适合的模型。
在Hello AI World项目训练Object Detection模型的时候,我们使用的是SSD-Mobilenet,在DeepStream的对象辨识范例中有提供使用自己的SSD模型方法,可在下列路径找到参考文件,文件中使用的例子是使用coco数据集预训练的SSD-Inception。
/opt/nvidia/deepstream/deepstream-5.1/sources/objectDetector_SSD
可惜的是文件中使用的是从Tensorflow训练的模型,经由转换.uff再喂给DeepStream,与官方课程使用的Pytorch是不同路线。笔者在网上寻找解决方法,看是否有DeepStream使用Pytorch模型的方案,也于NVIDIA开发者论坛找到几个同样的提问,但最终都是导到上述提到的参考文件。
从Hello AI World训练的Object Detection模型,经过执行推论的步骤,您应该会有三个与模型有关的档案,分别是用Pytorch训练好的.pth,以及为了使用TensorRT加速而将.pth转换的.onnx,最后是执行过程中产生的.engine。既然Pytorch模型找不到解决方案,那就从ONNX模型下手吧,所幸经过一番折腾,终于让笔者找到方法。
https://github.com/neilyoung/nvdsinfer_custom_impl_onnx
neilyoung提供的方法主要是能产生动态函式库,以便我们能在DeepStream使用ONNX模型,除了准备好自己训练的ONNX模型档案与Labels档案,只要再新增设定模型路径与类型的config档案,与deepstream配置文件就能实现使用自己的模型进行推论啰!
STEP 1:
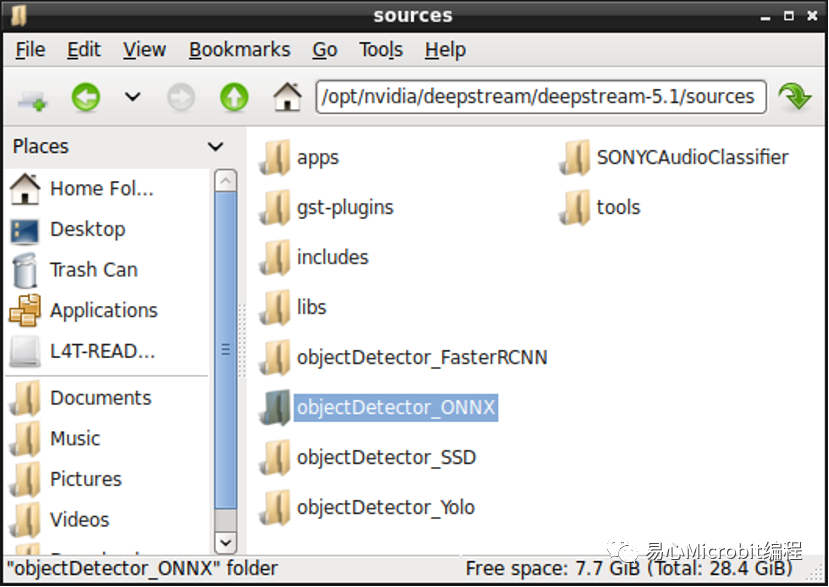
首先于以下路径底下新增执行ONNX项目的文件夹,笔者命名为objectDetector_ONNX。
/opt/nvidia/deepstream/deepstream-5.1/sources
STEP 2:
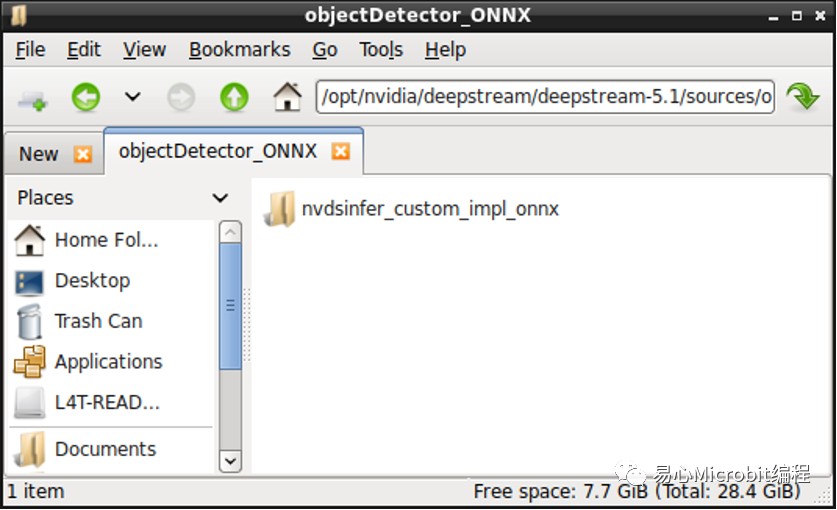
新增专案文件夹后,请clone方才的nvdsinfer_custom_impl_onnx专案到文件夹内。
STEP 3:
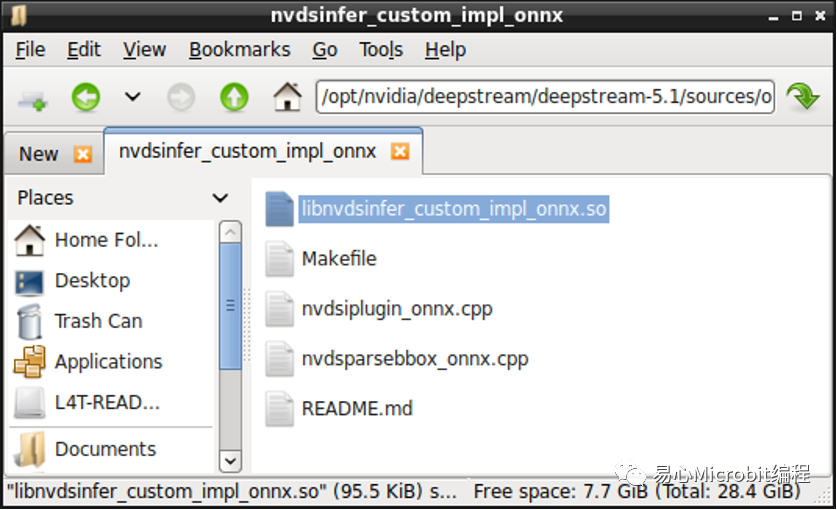
打开Terminal进到nvdsinfer_custom_impl_onnx项目里面,透过sudo make指令产生动态函式库。
STEP 4:
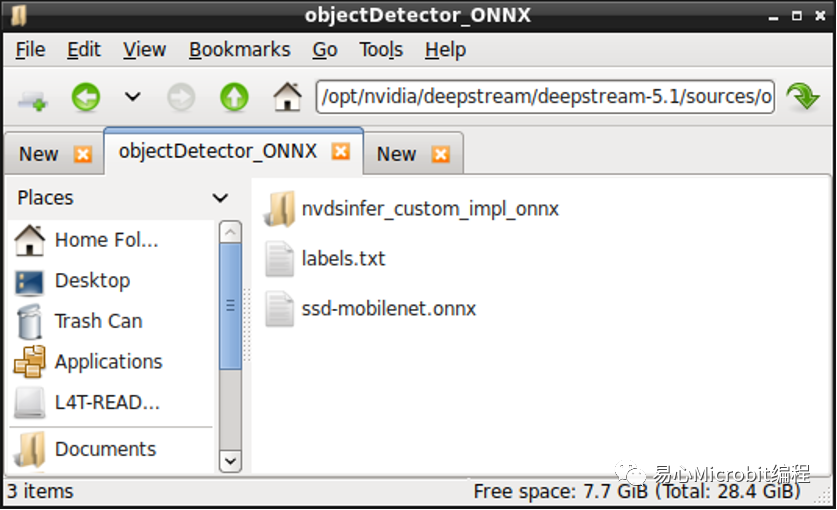
接着将自己从Hello AI World项目训练的Object Detection模型与卷标复制到objectDetector_ONNX项目文件夹。
STEP 5:
从别的项目文件夹复制config档案与deepstream配置文件到我们的文件夹内,这边复制objectDetector_SSD,因为模型类型相近,只要稍微修改即可。
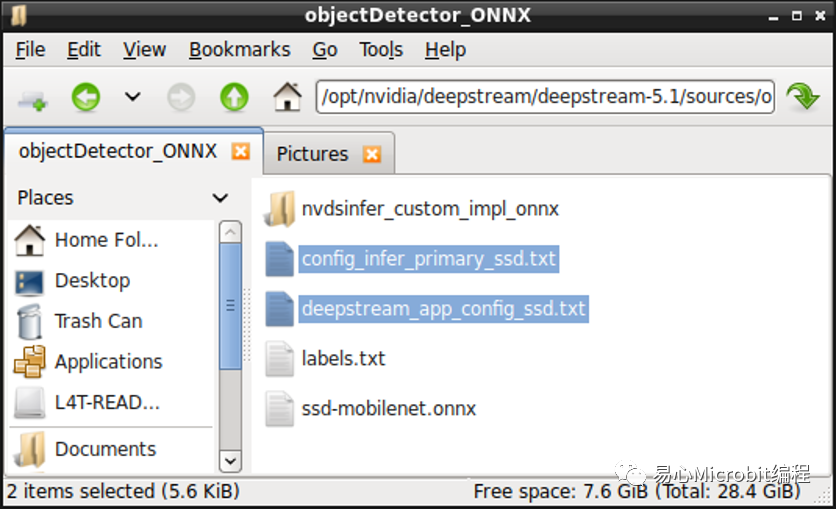
STEP 6:
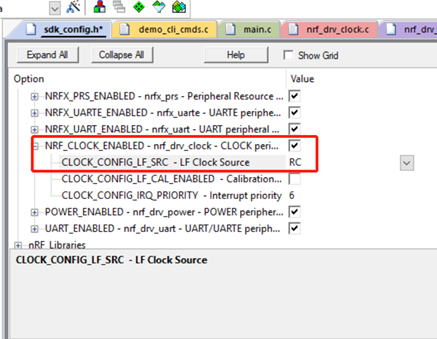
首先修改config档案,如下图所示,将模型路径与卷标路径,修正为自己的模型与卷标名称,engine档案的部份与Hello AI World项目一样,在执行ONNX档案进行TensorRT加速时会自动产生,只需给路径与名称即可。对于classes的部份,切记在Hello AI World项目训练的模型会加上BACKGROUND这一个类别,所以若是您辨识的对象有三种,就得在classes这边填上3+1。
下方三项的设定则依照nvdsinfer_custom_impl_onnx项目github上的说明,记得动态函式库的路径请改成自己的路径。
output-blob-names="boxes;scores"
parse-bbox-func-name="NvDsInferParseCustomONNX"
custom-lib-path="/path/to/lib/libnvdsinfer_custom_impl_onnx.so"
接着依照个人需求设定辨识的参数,例如希望信心指数达多少%才认定对象类别,可以修改threshold。
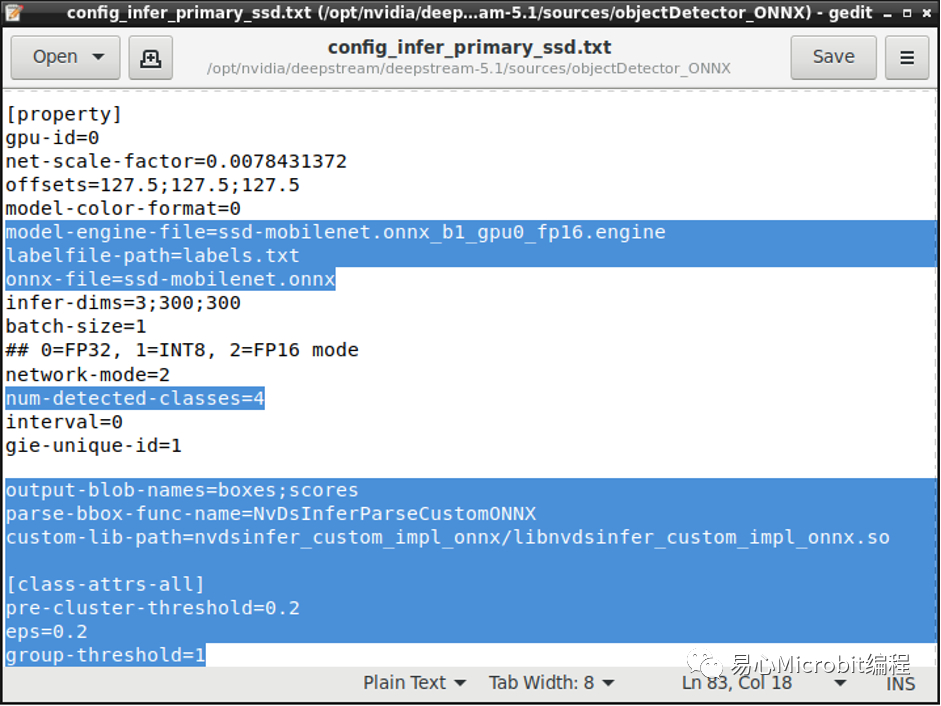
STEP 7:
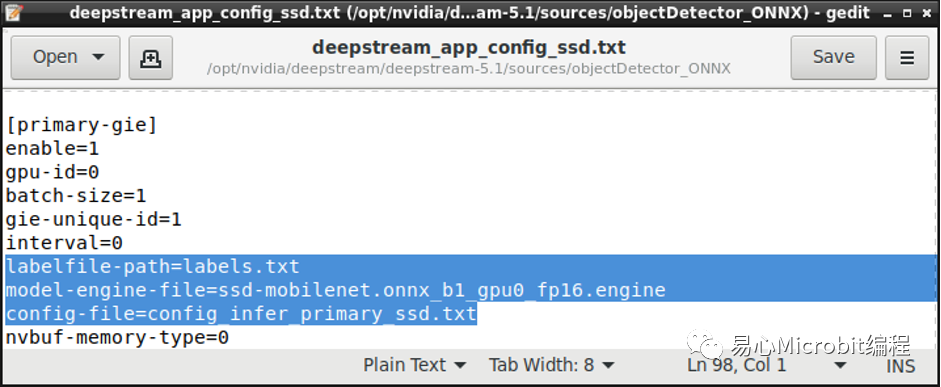
接着修改deepstream配置文件,笔者在这边设定为USB Webcam输入,并输出单一窗口显示,除了正常调整输入与输出之外,请将config档案与Labels档案导引至自己的路径,engine的部份与config设定相同即可,如下图所示。
完成上述7步骤后,就能执行配置文件查看是否有正确执行我们的ONNX模型,第一次执行会较久,过程会产生engine档案,一旦有了engine档,之后执行就不会再重复产生。
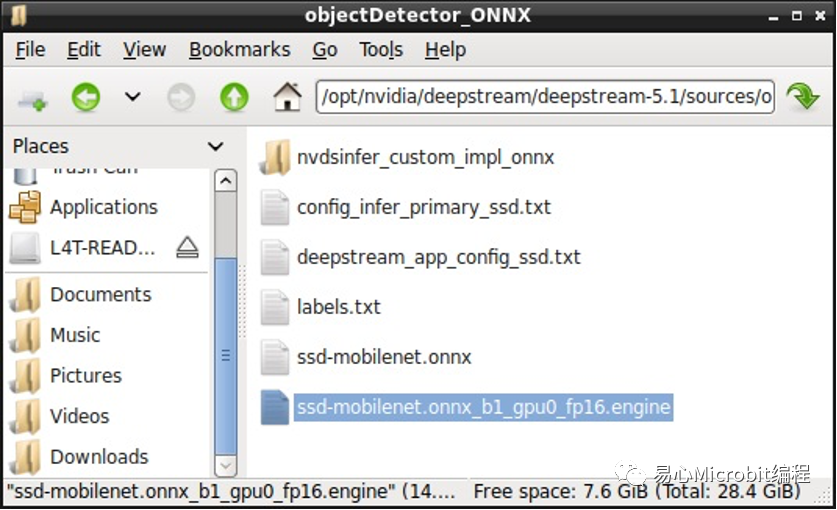
成功执行自定义模型的结果。

结论
原官方范例大多执行车流检测,若是想执行别的应用就得自己研究。本篇透过将自己训练好的Pytorch模型转换为ONNX,经7步骤后让DeepStream可以使用我们自己的模型进行辨识,使其能应用在交通以外的场景,例如室内监控、多机台管控…等。
审核编辑 :李倩
-
C++
+关注
关注
22文章
2127浏览量
77357 -
pytorch
+关注
关注
2文章
813浏览量
14921
原文标题:在DeepStream上使用自己的Pytorch模型
文章出处:【微信号:易心Microbit编程,微信公众号:易心Microbit编程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
后量化模型在 iMX93 NPU 上运行,但输出不正确怎么解决
在 NPU 上运行了 eIQ TensorFlow Lite 示例模型报错
【瑞萨AI挑战赛】手写数字识别模型在RA8P1 Titan Board上的部署
PyTorch 中RuntimeError分析
Pytorch 与 Visionfive2 兼容吗?
在以下嵌入式软件设计模型中,属于数据流模型的是,哪里有设计模型的介绍?
Arm方案 基于Arm架构的边缘侧设备(树莓派或 NVIDIA Jetson Nano)上部署PyTorch模型
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
为什么无法在GPU上使用INT8 和 INT4量化模型获得输出?
FA模型访问Stage模型DataShareExtensionAbility说明
同样的代码在官方开发板上运行正常,在自己板子上就跑不起来,怎么办?



评论