 基于深度学习的视觉检测系统的特点及应用
基于深度学习的视觉检测系统的特点及应用

一、什么是视觉检测中的深度学习?
在深度学习算法出来之前,对于视觉算法来说,大致可以分为以下5个步骤:特征感知,图像预处理,特征提取,特征筛选,推理预测与识别。早期的机器学习中,占优势的统计机器学习群体中,对特征是不大关心的。
深度学习是机器学习技术的一个方面,由人工神经网络提供支持。深度学习技术的工作原理是教机器通过实例学习。通过为神经网络提供特定类型数据的标记示例,可以提取这些示例之间的共同模式,然后将其转换为数学方程。这有助于对未来的信息进行分类。
通过视觉检测技术,深度学习算法的集成可以区分零件、异常和字符,在运行计算机化系统的同时模拟人类视觉检测。
那么,这到底是什么意思呢?举个例子。
如果要为汽车制造创建视觉检测软件,你应该开发一种基于深度学习的算法,并使用必须检测的缺陷示例对其进行训练。有了足够的数据,神经网络最终会在没有任何额外指令的情况下检测缺陷。
基于深度学习的视觉检测系统擅长检测性质复杂的缺陷。它们不仅可以解决复杂的表面和外观缺陷,还可以概括和概念化汽车零件的表面。
仿生学角度看深度学习
如果不手动设计特征,不挑选分类器,有没有别的方案呢?能不能同时学习特征和分类器?即输入某一个模型的时候,输入只是图片,输出就是它自己的标签。比如输入一个明星的头像,出来的标签就是一个50维的向量(如果要在50个人里识别的话),其中对应明星的向量是1,其他的位置是0。
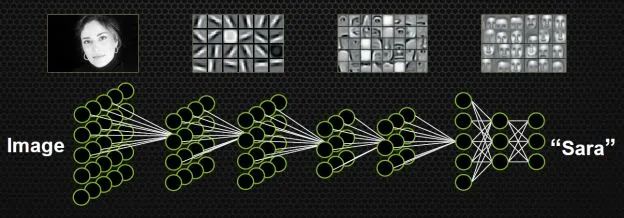
这种设定符合人类脑科学的研究成果。
1981年诺贝尔医学生理学奖颁发给了David Hubel,一位神经生物学家。他的主要研究成果是发现了视觉系统信息处理机制,证明大脑的可视皮层是分级的。他的贡献主要有两个,一是他认为人的视觉功能一个是抽象,一个是迭代。抽象就是把非常具体的形象的元素,即原始的光线像素等信息,抽象出来形成有意义的概念。这些有意义的概念又会往上迭代,变成更加抽象,人可以感知到的抽象概念。
像素是没有抽象意义的,但人脑可以把这些像素连接成边缘,边缘相对像素来说就变成了比较抽象的概念;边缘进而形成球形,球形然后到气球,又是一个抽象的过程,大脑最终就知道看到的是一个气球。
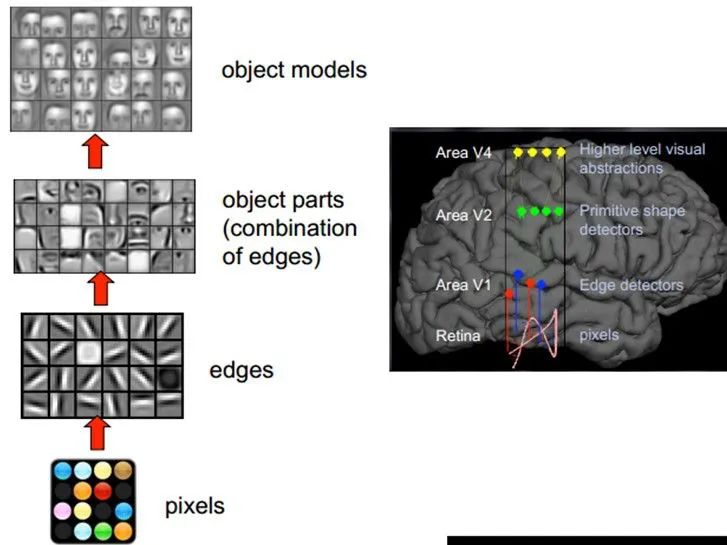
模拟人脑识别人脸,也是抽象迭代的过程,从最开始的像素到第二层的边缘,再到人脸的部分,然后到整张人脸,是一个抽象迭代的过程。
再比如看到图片中的摩托车,我们可能在脑子里就几微秒的时间,但是经过了大量的神经元抽象迭代。对计算机来说最开始看到的根本也不是摩托车,而是RGB图像三个通道上不同的数字。
所谓的特征或者视觉特征,就是把这些数值给综合起来用统计或非统计的形式,把摩托车的部件或者整辆摩托车表现出来。深度学习的流行之前,大部分的设计图像特征就是基于此,即把一个区域内的像素级别的信息综合表现出来,利于后面的分类学习。
如果要完全模拟人脑,我们也要模拟抽象和递归迭代的过程,把信息从最细琐的像素级别,抽象到“种类”的概念,让人能够接受。
卷积的概念
计算机视觉里经常使卷积神经网络,即CNN,是一种对人脑比较精准的模拟。
什么是卷积?卷积就是两个函数之间的相互关系,然后得出一个新的值,他是在连续空间做积分计算,然后在离散空间内求和的过程。实际上在计算机视觉里面,可以把卷积当做一个抽象的过程,就是把小区域内的信息统计抽象出来。
比如,对于一张爱因斯坦的照片,我可以学习n个不同的卷积和函数,然后对这个区域进行统计。可以用不同的方法统计,比如着重统计中央,也可以着重统计周围,这就导致统计的和函数的种类多种多样,为了达到可以同时学习多个统计的累积和。
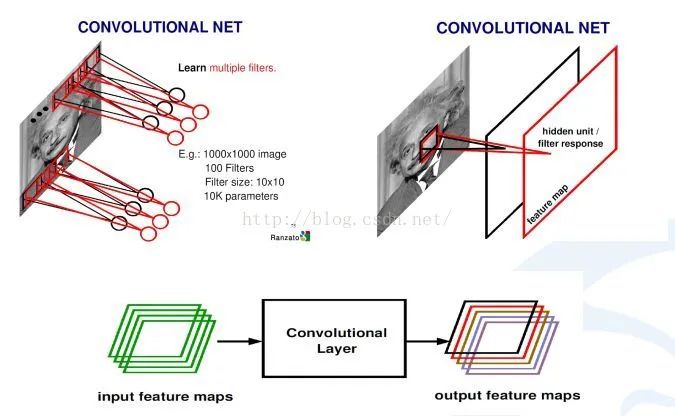
上图中是,如何从输入图像怎么到最后的卷积,生成的响应map。首先用学习好的卷积和对图像进行扫描,然后每一个卷积和会生成一个扫描的响应图,我们叫response map,或者叫feature map。如果有多个卷积和,就有多个feature map。也就说从一个最开始的输入图像(RGB三个通道)可以得到256个通道的feature map,因为有256个卷积和,每个卷积和代表一种统计抽象的方式。
在卷积神经网络中,除了卷积层,还有一种叫池化的操作。池化操作在统计上的概念更明确,就是一个对一个小区域内求平均值或者求最大值的统计操作。
带来的结果是,如果之前我输入有两个通道的,或者256通道的卷积的响应feature map,每一个feature map都经过一个求最大的一个池化层,会得到一个比原来feature map更小的256的feature map。
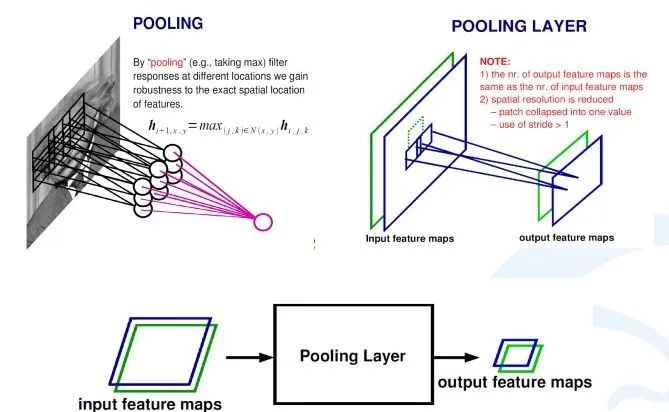
在上面这个例子里,池化层对每一个2X2的区域求最大值,然后把最大值赋给生成的feature map的对应位置。如果输入图像是100×100的话,那输出图像就会变成50×50,feature map变成了一半。同时保留的信息是原来2X2区域里面最大的信息。
操作的实例:LeNet网络
Le顾名思义就是指人工智能领域的大牛Lecun。这个网络是深度学习网络的最初原型,因为之前的网络都比较浅,它较深的。LeNet在98年就发明出来了,当时Lecun在AT&T的实验室,他用这一网络进行字母识别,达到了非常好的效果。
怎么构成呢?输入图像是32×32的灰度图,第一层经过了一组卷积和,生成了6个28X28的feature map,然后经过一个池化层,得到得到6个14X14的feature map,然后再经过一个卷积层,生成了16个10X10的卷积层,再经过池化层生成16个5×5的feature map。
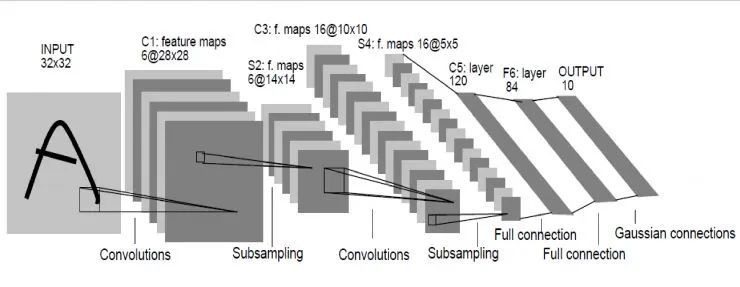
从最后16个5X5的feature map开始,经过了3个全连接层,达到最后的输出,输出就是标签空间的输出。由于设计的是只要对0到9进行识别,所以输出空间是10,如果要对10个数字再加上26个大小字母进行识别的话,输出空间就是62。62维向量里,如果某一个维度上的值最大,它对应的那个字母和数字就是就是预测结果。
压在骆驼身上的最后一根稻草
从98年到本世纪初,深度学习兴盛起来用了15年,但当时成果泛善可陈,一度被边缘化。到2012年,深度学习算法在部分领域取得不错的成绩,而压在骆驼身上最后一根稻草就是AlexNet。
AlexNet由多伦多大学几个科学家开发,在ImageNet比赛上做到了非常好的效果。当时AlexNet识别效果超过了所有浅层的方法。此后,大家认识到深度学习的时代终于来了,并有人用它做其它的应用,同时也有些人开始开发新的网络结构。
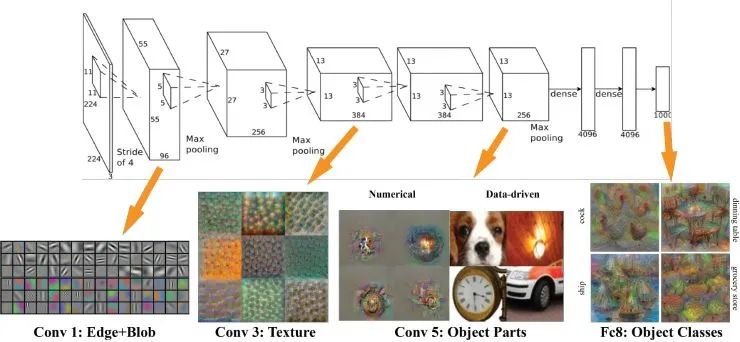
其实AlexNet的结构也很简单,只是LeNet的放大版。输入是一个224X224的图片,是经过了若干个卷积层,若干个池化层,最后连接了两个全连接层,达到了最后的标签空间。
去年,有些人研究出来怎么样可视化深度学习出来的特征。那么,AlexNet学习出的特征是什么样子?在第一层,都是一些填充的块状物和边界等特征;中间的层开始学习一些纹理特征;更高接近分类器的层级,则可以明显看到的物体形状的特征。
最后的一层,即分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
可以说,不论是对人脸,车辆,大象或椅子进行识别,最开始学到的东西都是边缘,继而就是物体的部分,然后在更高层层级才能抽象到物体的整体。整个卷积神经网络在模拟人的抽象和迭代的过程。
二、如何集成AI视觉检测系统
1. 明确需求:
视觉检测开发通常从业务和技术分析开始。这里的目标是确定系统应该检测什么样的缺陷。
需要提前明确的重要问题包括:
什么是AI视觉检测系统的环境?
AI检测应该是实时的还是延时的?
AI视觉检测应该如何彻底检测缺陷,是否应该按类型区分?
是否有任何现有的软件可以集成视觉检测功能,还是需要从头开始开发?
系统应如何将检测到的缺陷通知用户?
AI视觉检测系统是否应该记录缺陷检测统计数据?
关键问题是:是否存在用于深度学习模型开发的数据,包括“好”和“坏”产品的图像以及不同类型的缺陷?
2. 收集和准备数据:
在深度学习模型开发开始之前,数据科学工程师必须收集和准备训练未来模型所需的数据。对于制造流程,实施物联网数据分析非常重要。在谈论AI视觉检测模型时,数据通常是视频记录,其中视觉检测模型处理的图像包括视频帧。数据收集有多种选择,但最常见的是:
现有视频记录,适用于特定目的的开源视频记录,根据深度学习模型要求从头开始收集数据。
这里最重要的参数是视频记录的质量。更高质量的数据将导致更准确的结果。一旦我们收集了数据,我们就为建模做好准备、清理、检查异常并确保其相关性。
3. 开发深度学习模型
深度学习模型开发方法的选择取决于任务的复杂性、所需的交付时间和预算限制。有几种方法:
1)使用深度学习模型开发(例如:Google Cloud ML Engine、Amazon ML 等)
当缺陷检测功能的要求与给定服务提供的模板一致时,这种类型的方法是有意义的。这些服务可以节省时间和预算,因为无需从头开始开发模型。只需要根据相关任务上传数据并设置模型选项。
问题就是这些类型的模型不可定制。模型的功能仅限于给定服务提供的选项。
2) 使用预训练模型
预训练模型是一种已经创建的深度学习模型,它可以完成与我们想要执行的任务类似的任务。我们不必从头开始构建模型,因为它使用基于用户自己的数据训练模型。
预训练模型可能不会 100% 符合我们的所有任务,但它可以节省大量时间和成本。使用之前在大型数据集上训练过的模型,用户可以根据自己的问题定制这些解决方案。
3)从零开始深度学习模型开发
这种方法非常适用于复杂且安全的视觉检测系统。这种方法可能需要大量时间和精力,但结果是值得的。
在开发自定义视觉检测模型时,数据科学家会使用一种或多种计算机视觉算法。这些包括图像分类、对象检测和实例分割。
许多因素会影响深度学习算法的选择。这些包括:
业务目标;
物体/缺陷的大小;
光照条件;
检验产品数量;
缺陷类型;
图像分辨率;
假设我们正在开发用于建筑物质量评估的目视检查模型。主要重点是检测墙壁上的缺陷。需要大量数据集才能获得准确的视觉检查结果,因为缺陷类别可能非常多样化,从油漆剥落和霉菌到墙壁裂缝。这里的最佳方法是从头开始开发基于实例分割的模型。在某些情况下,预先训练的模型方法也是可行的。
4. 训练和评估
开发视觉检测模型后的下一步是对其进行训练。在这个阶段,数据科学家验证和评估模型的性能和结果准确性。测试数据集在这里很有用。对于视觉检测系统,它可能是一组过已有的或类似于要在部署后处理的视频资料。
5. 部署和改进
在部署视觉检测模型时,重要的是要考虑软件和硬件系统架构如何与模型容量对应。
1)软件
视觉检测驱动软件的结构基于用于数据传输的 Web 解决方案和用于神经网络处理的 Python 框架的组合。这里的关键参数是数据存储。有三种常见的数据存储方式:在本地服务器、云服务或无服务器架构上。
AI视觉检测系统涉及视频记录的存储。数据存储解决方案的选择通常取决于深度学习模型功能。例如,如果视觉检测系统使用大型数据集,则最佳选择可能是云服务。
2)硬件
根据行业和自动化流程,集成视觉检测系统所需的设备可能包括:
摄像头。关键的摄像头选项是实时视频流。一些示例包括 IP Camera 和 CCTV。
网关。专用硬件设备和软件程序都适用于视觉检测系统。
CPU/GPU。如果需要实时结果,GPU 将是比 CPU 更好的选择,因为前者在基于图像的深度学习模型方面具有更快的处理速度。可以优化 CPU 来运行视觉检查模型,但不能优化用于训练。
光度计(可选)。根据视觉检测系统环境的照明条件,可能需要使用光度计。
色度计(可选)。在检测光源的颜色和亮度时,成像色度计始终具有高空间分辨率,可进行详细的AI视觉检测。
热像仪(可选)。在蒸汽/水管道和设施的自动检查的情况下,拥有热像仪数据是个好主意。热像仪数据为热/蒸汽/水泄漏检测提供了有价值的信息。热像仪数据也可用于隔热检查。
无人机(可选)。如今,很难想象在没有无人机的情况下对难以到达的区域进行自动检查:建筑物内部结构、天然气管道、油轮目视检查、火箭/航天飞机检查。无人机可能配备高分辨率相机,可以进行实时缺陷检测。
深度学习模型在部署后可以改进。深度学习方法可以通过新数据的迭代收集和模型重新训练来提高神经网络的准确性。结果是一个“更智能”的视觉检测模型,它通过增加操作期间的数据量来学习。
三、AI视觉检测的应用示例
通用安防:
适用于社区、楼宇、企业园区等场所的安防管理场景,如:人员进出、车辆进出、周界防范、危险区域闯入、可疑徘徊等,提高场所的安全管理水平。
明厨亮灶:
基于多种算法(厨师帽/厨师服识别、抽烟识别、玩手机识别、垃圾桶未盖检测、动火离人检测、陌生人检测、猫/狗/老鼠识别等),可以有效监测餐饮行业后厨的食品安全、环境卫生、四害防治等是否有违规或异常情况出现,并能实时发出告警信息。
森林防火:
可对前端设备采集的图像、视频等数据进行实时风险监测与烟火识别分析,根据火灾烟雾火焰特征,可准确识别出烟雾、火焰、火点,并立即触发告警。 智慧安监:适用于企业安全生产监管场景,如:工地、煤矿、危化品、加油站、烟花爆竹、电力等行业,有助于降低生产过程中的安全隐患、保障生命财产安全。 智慧景区:适用于景区、公园等场景,可实时统计监控范围内的人流量、预警人群拥挤事件、防止危险区域有人员闯入、识别烟火等,助力景区智能化监管。 智慧校园:可用于校园内部及周边的安防监测场景,包括师生人脸门禁、车辆进出、周界防范、翻越围墙、危险区域闯入、人员拥挤、异常聚集、烟火等。 区域安全监测:适用于重点场所的安全监测场景,如:政府机构、军事区域、机场、变电站、工业重地、看守所、农场养殖等,监测周界入侵、人员闯入、徘徊等事件。
无人值守:可用于野外远程监控场景,如:水利、电力等,防范可疑人员靠近、人员破坏/偷盗设备、闯入危险区域等,可联动语音等装置进行驱离提醒。 在岗离岗:可用于需要人员时刻在岗的监测场景中,能实时检测固定工作岗位的人员在岗离岗情况,当检测到离岗时,可立即触发告警提醒。 加油站安全监管:用于加油站安全监管,对加油区、卸油区、储油罐等区域进行重点监测,可对区域内的安全风险,如:抽烟、打电话、烟火、静电释放等进行告警提醒。 公共防疫:协助公共区域防疫工作的开展,实时监测区域内人员是否佩戴口罩,并可结合语音装置发出提醒,可应用于楼宇、商场、车站、公交、出租车、地铁、广场、景区、工厂、园区等场景。
审核编辑:郭婷
-
计算机
+关注
关注
19文章
7841浏览量
93467 -
AI
+关注
关注
91文章
41176浏览量
302626 -
深度学习
+关注
关注
73文章
5608浏览量
124637
原文标题:基于深度学习算法的AI智能视觉检测技术
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

【智能检测】基于AI深度学习与飞拍技术的影像测量系统:实现高效精准的全自动光学检测与智能制造数据闭环
友思特案例 | 金属行业视觉检测案例一:彩涂钢板卷对卷检测

【精选活动】缺陷系统检测不走坑!10年+资深LabVIEW视觉专家全套珍藏

穿孔机顶头检测仪 机器视觉深度学习
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
从0到1,10+年资深LabVIEW专家,手把手教你攻克机器视觉+深度学习(5000分钟实战课)
如何深度学习机器视觉的应用场景
友思特案例 | 医疗设备行业视觉检测案例集锦(四)

机器视觉检测PIN针
如何在机器视觉中部署深度学习神经网络

地铁隧道病害智能巡检系统——机器视觉技术的深度应用

锂电行业视觉检测案例集锦(二)




评论