 术开发一种硬件高效的RepGhost模块
术开发一种硬件高效的RepGhost模块

1 RepGhost:重参数化技术构建硬件高效的 Ghost 模块
GhostNetV2 解读:NeurIPS'22 Spotlight|华为诺亚GhostNetV2出炉:长距离注意力机制增强廉价操作
G-GhostNet 解读:想要一个适配GPU端的轻量级网络?安排!华为诺亚带着 G-GhostNet 走来
1.1.1 特征复用技术和本文动机
特征复用技术是指:通过简单地连接来自不同层的已有的一些特征图,来额外获得一些其他的特征。比如在 DenseNet[1] 中,在一个 Stage 内,前面层的特征图被重复使用并被馈送到它们的后续层,从而产生越来越多的特征图。或者在 GhostNet 中,作者通过一些廉价的操作来生成更多的特征图,并将它们与原始特征图 Concat 起来,从而产生越来越多的特征图。它们都通过 Concat 操作,利用特征复用技术,来扩大 channel 数量和网络容量,同时保持一个比较低的 FLOPs。似乎 Concat 操作已经成为特性复用的标准操作。
Concat 操作确实是一种 0 Params,0 FLOPs 的操作。但是,它在硬件设备上的计算成本是不可忽略的。 因为参数量和 FLOPs 不是机器学习模型实际运行时性能的直接成本指标。作者发现,在硬件设备上,由于复杂的内存复制,Concat 操作比加法操作效率低得多。因此,值得探索一种更好的、硬件效率更高的方法,以更好地适配特征复用技术。
因此,作者考虑引入结构重参数化方法,这个系列方法的有效性在 CNN 体系结构设计中得到了验证。具体而言,模型训练时是一个复杂的结构,享受高复杂度的结构带来的性能优势,训练好之后再等价转换为简单的推理结构,且不需要任何时间成本。受此启发,作者希望借助结构重参数化方法来实现特征的隐式重用,以实现硬件高效的架构设计。
所以本文作者希望通过结构重新参数化技术开发一种硬件高效的 RepGhost 模块,以实现特征的隐式重用。如前文所述,要把 Concat 操作去掉,同时修改现有结构以满足重参数化的规则。因此,在推断之前,特征重用过程可以从特征空间转移到权重空间,使 RepGhost 模块高效。
1.1.2 Concat 操作的计算成本
作者将 GhostNet 1.0x 中的所有 Concat 操作替换成了 Add 操作,Add 操作也是一种处理不同特征的简单操作,且成本较低。这两个运算符作用于形状完全相同的张量上。如下图1所示为对应网络中所有32个对应运算符的累计运行时间。Concat 操作的成本是 Add 操作的2倍。
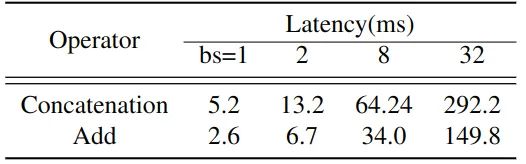
图1:在基于 ARM 的手机上 Concat 操作和 Add 操作处理不同 Batch Size 的数据的运行时间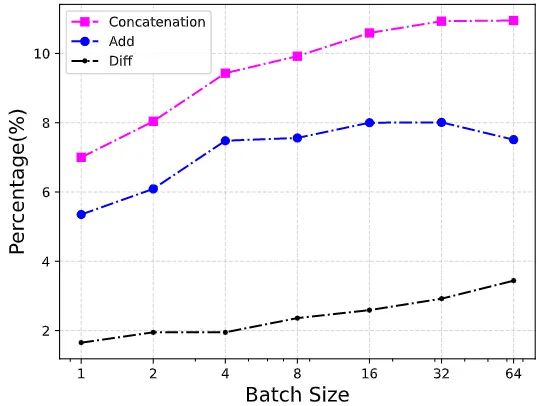
图2:每个操作符在整个网络中的运行时间的百分比。Diff:Concat 操作和 Add 操作的差值的百分比
1.1.3 Concat 操作和 Add 操作
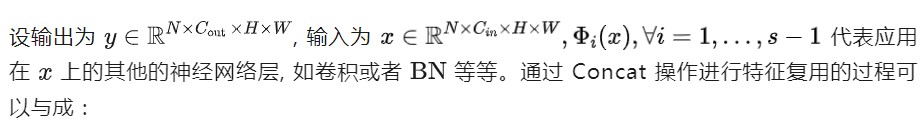
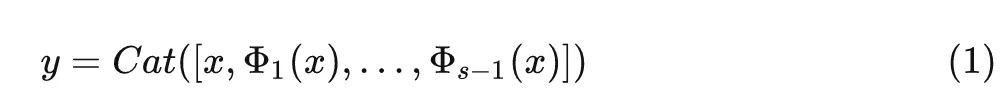
式中, 代表 Concat 操作。它只保留现有的特征映射,将信息处理留给下面的层。例如,在 Concat 操作之后通常会有一个 1×1 卷积来处理信道信息。但是,Concat 操作的成本问题促使作者寻找一种更有效的方法。
通过 Add 操作进行特征复用的过程可以写成:
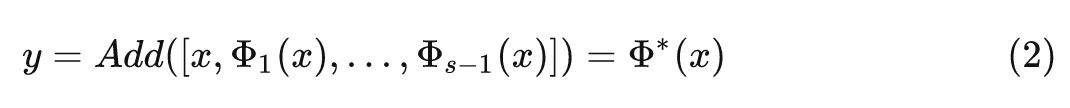
式中, 代表 Add 操作。与 Concat 操作不同,Add 操作还具有特征融合的作用,而且特征融合过程是在权值空间中完成的,不会引入额外的推理时间。
基于此,作者提出了以下 RepGhost 模块。
1.1.4 RepGhost 模块
这一小节介绍如何通过重参数化技术来进行特征复用,具体而言介绍如何从一个原始的 Ghost 模块演变成 RepGhost 模块。如下图3所示,从 Ghost 模块开始:
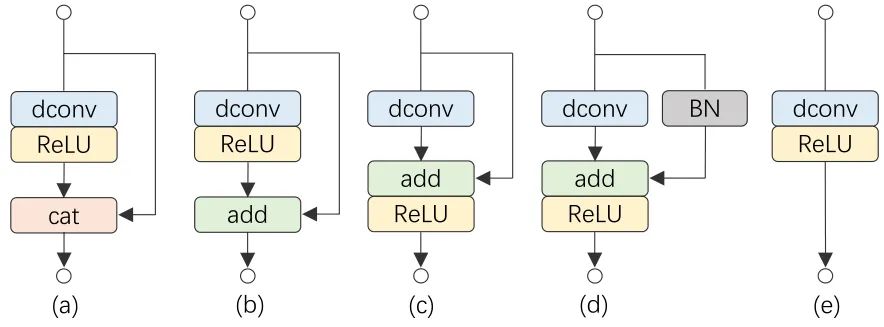
图3:从一个原始的 Ghost 模块演变成 RepGhost 模块的过程
(a) 原始的 Ghost 模块,这里省去了第一步的 1×1 卷积。
(b) 把原始的 Ghost 模块的 Concat 操作换成 Add 操作,以求更高的效率。
(c) 把 ReLU 移到 Add 操作之后,这种移动使得模块满足结构重新参数化规则,从而可用于快速推理。
(d) 在恒等映射 Identity Mapping 分支中添加 BN 操作,使得在训练过程中带来非线性,并且可以被融合用于快速推断。
(e) 模块 (d) 可以被融合成模块 (e),用于快速推断。RepGhost 模块有一个简单的推理结构,它只包含规则的卷积层和ReLU,这使得它具有较高的硬件效率。特征融合的过程是在权重空间,而不是在特征空间中进行,然后把两个分支的参数进行融合产生快速推理的结构。
与 Ghost 模块的对比
作用:
Ghost 模块提出从廉价的操作中生成更多的特征图,因此可以以低成本的方式扩大模型的容量。
RepGhost 模块提出了一种更有效的方法,通过重参数化来生成和融合不同的特征图。与 Ghost 模块不同,RepGhost 模块去掉了低效的 Concat 操作,节省了大量推理时间。并且信息融合过程由 Add 操作以隐含的方式执行,而不是留给其他卷积层。

1.1.5 RepGhostNet 网络

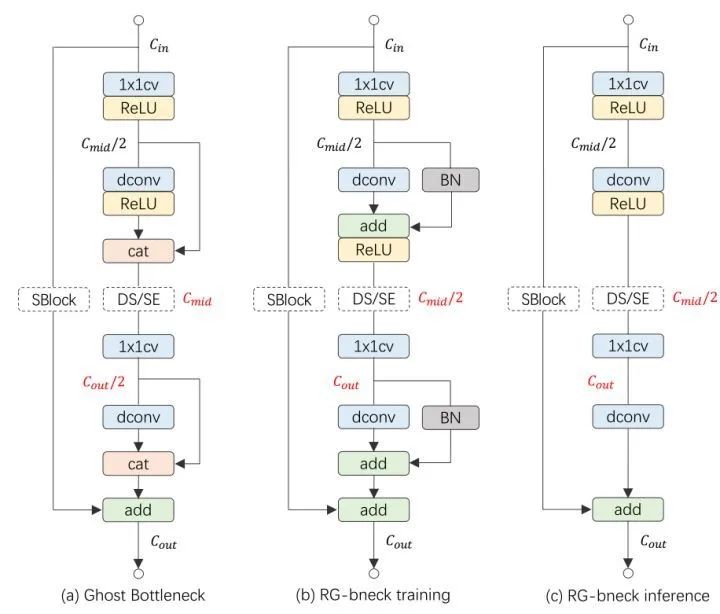
图4:(a) GhostNet 网络的一个 Block。(b) RepGhost 网络训练时的一个 Block。(c) RepGhost 网络推理时的一个 Block
下图5所示是 RepGhostNet 的网络架构。首先是一个输出通道为16的卷积层处理输入数据。一堆正常的 1×1 卷积和 AvgPool 预测最终输出。根据输入大小将 RepGhost Bottleneck 分成5组,并且为每组中除最后一个 Bottleneck 之外的最后一个 Bottleneck 设置 stride=2。
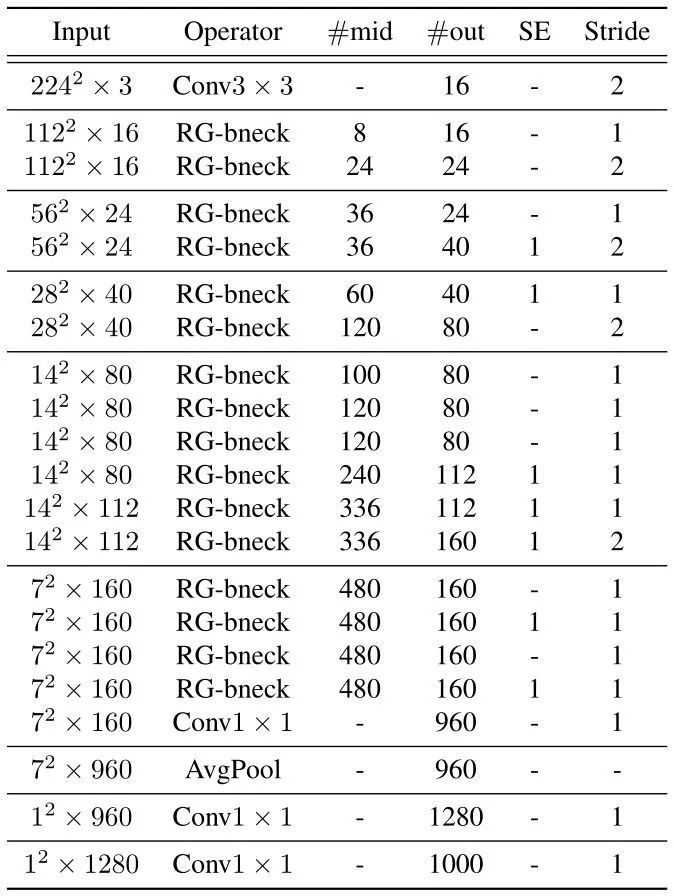
图5:RepGhost 网络架构
1.1.6 实验结果
ImageNet-1K 实验结果
如下图所示是 ImageNet-1K 图像分类任务的实验结果。NVIDIA V100 GPUs ×8 作为训练设备,Batch size 开到1024,优化器 SGD (0.9 momentum),基本学习率为 0.6,Epoch 数为 300,weight decay 为1e-5,并且使用衰减系数为0.9999的 EMA (Exponential Moving Average) 权重衰减。数据增强使用 timm 库的图像裁剪和翻转,prob 0.2 的随机擦除。对于更大的模型 RepGhostNet 1.3×,额外使用 auto augment。
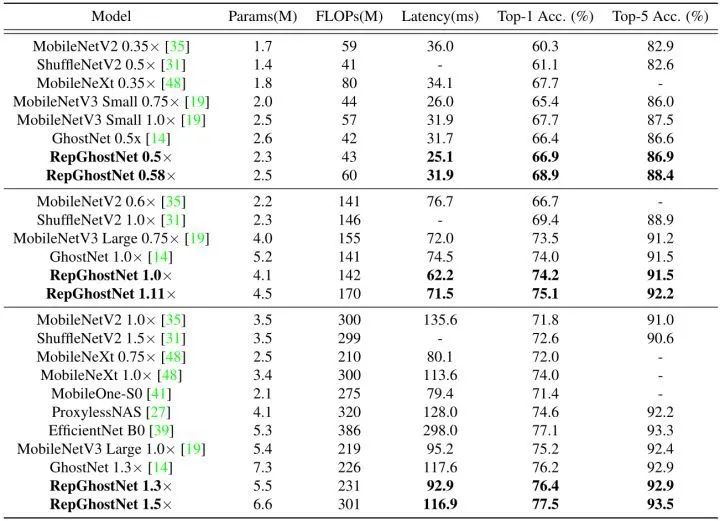
图6:ImageNet-1K 实验结果
实验结果如上图6所示。根据 FLOPs,所有模型被分为3个级别。在基于 ARM 的手机上评估每个模型的相应延迟。图1描绘了所有模型的延迟和精度。可以看到,在准确性-延迟权衡方面,RepGhostNet 优于其他手动设计和基于 NAS 的模型。
RepGhostNet 实现了与其他先进的轻量级 CNN 相当甚至更好的准确性,而且延迟低得多。例如,RepGhostNet 0.5× 比 GhostNet 0.5× 快 20%,Top-1 准确性高 0.5%,RepGhostNet 1.0× 比 MobileNetV3 Large 0.75× 快 14%,Top-1 准确性高 0.7%。在延迟相当的情况下,RepGhostNet 在所有三个量级大小的模型上面都超过所有对手模型。比如,RepGhostNet 0.58× 比 GhostNet 0.5× 高 2.5%,RepGhostNet 1.11× 比MobileNetV3 Large 0.75× 高 1.6%。
目标检测和实例分割实验结果
使用 RetinaNet 和 Mask RCNN分别用于目标检测任务和实例分割任务。仅替换 ImageNet 预训练的主干,并在8个 NVIDIA V100 GPUs 中训练12个时期的模型结果如下图7所示。RepGhostNet 在两个任务上都优于MobileNetV2,MobileNetV3 和 GhostNet,且推理速度更快。例如,在延迟相当的情况下,RepGhostNet 1.3× 在这两项任务中比 GhostNet 1.1× 高出 1% 以上,RepGhostNet 1.5× 比 MobileNetV2 1.0× 高出 2% 以上。
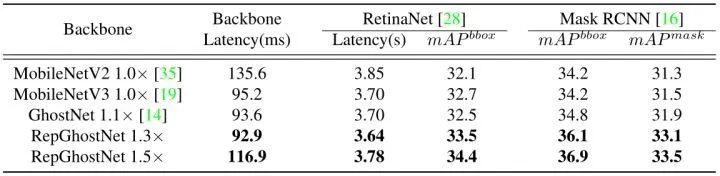
图7:目标检测和实例分割实验结果
消融实验1:与 Ghost-Res50 的对比
为了验证大模型的 RepGhost 模块的泛化性,作者将其与 GhostNet 模型 Ghost-Res50 进行了比较。用 RepGhost 模块替换 Ghost-Res50 中的 Ghost 模块,得到 RepGhost-Res50。所有模型都使用相同的训练设置进行训练。对于 MNN 延时,与图6结果使用相同的手机测得。对于 TRT 延迟,作者首先将模型转换为 TensorRT,然后在 Batch size 为32的 T4 GPU 上运行框架上的每个模型100次,并报告平均延迟。
结果如下图8所示。可以看到,RepGhost-Res50 在 CPU 和 GPU 上都明显快于 Ghost-Res50,但精度相当。特别地,在 MNN 推理和 TensorRT 推理中,RepGhost-Res50 (s=2) 比 Ghost-Res50 (s=4) 分别获得了 22% 和44% 的加速比。

图8:与 Ghost-Res50 的对比
消融实验2:重参数化结构
为了验证重新参数化结构,作者在 RepGhostNet 0.5× 上进行消融实验,方法是在图 3(c) 所示的模块的恒等映射分支中交替使用 BN,1×1 Depth-wise Convolution 和恒等映射本身。结果如下图9所示。可以看到,带有 BN 重参数化的 RepGhostNet 0.5× 达到了最好的性能。作者将其作为所有其他 RepGhostNet 的默认重新参数化结构。
作者将这种改善归因于 BN 的非线性,它提供了比恒等映射更多的信息。1×1 Depth-wise Convolution 之后也是 BN,因此,由于后面的归一化,其参数对特征不起作用,并且可能使 BN 统计不稳定,作者推测这导致了较差的性能。
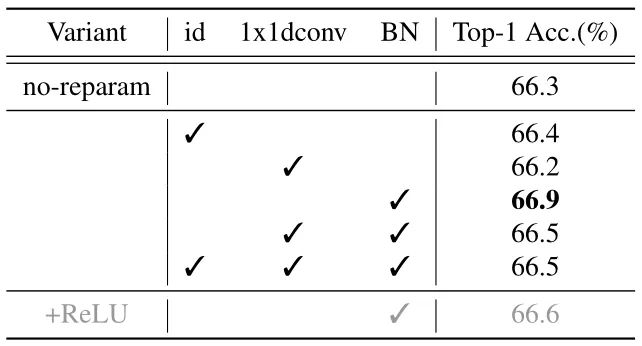
图9:重新参数化结构消融实验
消融实验3:Shortcut 的必要性
尽管 会增加内存访问成本 (从而影响运行时性能),但对于计算受限的移动设备来说,这种影响可以忽略不计,如表所示。7.考虑到所有这些,我们确认快捷方式对于轻量级CNN是必要的,并在我们的RepGhostNet中保留快捷方式。mageNet 数据集上的准确性,结果如下图显示了使用和不使用快捷方式时 RepGhostNet 的准确性和延迟。
很明显,Shortcut 不会严重影响实际运行的延时,但有助于优化过程。另一方面,大模型去掉 Shortcut 对 Latency 的影响要小于小模型,这可能意味着 Shortcut 对于轻量级 CNN 比大型模型更重要,例如 RepVGG 和 MobileOne。
尽管 Shortcut 会增加内存访问成本 (从而影响运行时性能),但对于计算受限的移动设备来说,这种影响可以忽略不计。考虑到所有这些,我们认为 Shortcut 对于轻量级 CNN 是必要的,并在 RepGhostNet 中保留了 Shortcut 操作。
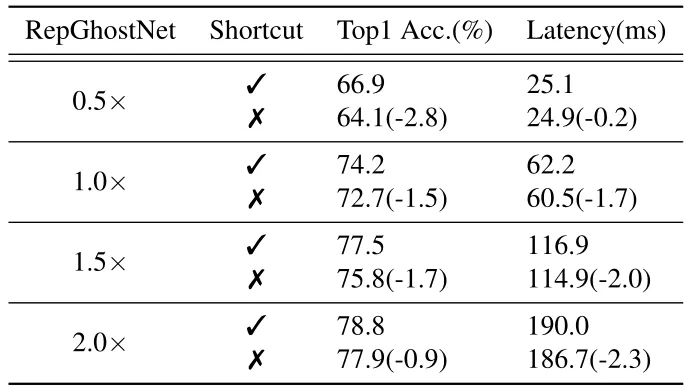
图10:Shortcut 的必要性消融实验结果
总结
GhostNet 通过一些廉价的操作来生成更多的特征图,并将它们与原始特征图 Concat 起来,从而产生越来越多的特征图,它利用特征复用技术,来扩大 channel 数量和网络容量,同时保持一个比较低的 FLOPs。似乎 Concat 操作已经成为特性复用的标准操作。Concat 操作确实是一种 0 Params,0 FLOPs 的操作。
但是,它在硬件设备上的计算成本是不可忽略的。所以本文作者希望通过结构重新参数化技术开发一种硬件高效的 RepGhost 模块,以实现特征的隐式重用。RepGhostNet 把 Concat 操作去掉,同时修改现有结构以满足重参数化的规则。最终得到的 RepGhostNet 是一个高效的轻量级 CNN,在几个视觉任务中都展示出了移动设备的精度-延迟权衡方面良好的技术水平。
审核编辑:刘清
-
gpu
+关注
关注
28文章
5272浏览量
136072 -
机器学习
+关注
关注
67文章
8565浏览量
137228 -
cnn
+关注
关注
3文章
356浏览量
23547 -
ema
+关注
关注
0文章
4浏览量
2505
原文标题:轻量级CNN模块!RepGhost:重参数化实现硬件高效的Ghost模块
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【WaRP7试用申请】一种高效的协议融合解决方案
一种高效LLC电源参考设计
一种无线射频收发模块的应用
开发DSP硬件驱动程序的一种方法
一种模块化高效电子商务推荐系统的设计

一种基于GaN的超高效功率模块
一种明场成像细胞术(BFIC)技术
一种简单高效配置FPGA的方法



评论