 Arm Neoverse生态及性能优势和迁移建议
Arm Neoverse生态及性能优势和迁移建议

简介:Arm Neoverse生态及性能优势和迁移建议
2022年11月5日,“倚天开启云原生算力新时代”专场在杭州·云栖大会D馆云栖科创SHOW场举行,安谋科技(Arm China)高级软件经理别再平带来了题为《Neoverse生态与软件迁移》的主题分享,详细的介绍了Arm Neoverse生态及性能优势和迁移建议,本文根据该演讲整理而成。
01 Arm完善、丰富的生态成为国内外多家云厂商首选
在Arm的生态系统中包含CPU架构、CPU微架构,芯片实现三个概念,CPU架构定义了用户对CPU核心的期望行为,包括寄存器、内存模型,异常模型等等,而CPU微架构则是一个CPU核心的具体实现,芯片则是芯片厂商在CPU核心的基础上配合各种加速器和总线互联最终实现。

同一个CPU架构可以有不同的微架构实现,例如上图右侧中的例子:Arm的Cortex A710和Arm的Neoverse N2两款CPU核心,都是基于Armv9.0架构实现,同一款软件也同样可以在两款CPU上运行。

上图中展示的是Arm的CPU架构演进,Arm自2011年推出基于64位的Armv8架构以来,保持着逐代演进的节奏,根据市场和客户的需求,不断地在安全、性能、功能等方面加入不同的CPU特性,不同的CPU特性会组合成为一个CPU扩展,也就是一个小(新)版本。Arm的CPU版本是逐年演进且向前兼容的,像Neoverse N2是基于Armv9的架构,它可以同时兼容前代架构的所有特性,系统软件等也可以通过查询系统寄存器了解当前硬件所实现的具体CPU架构特性。
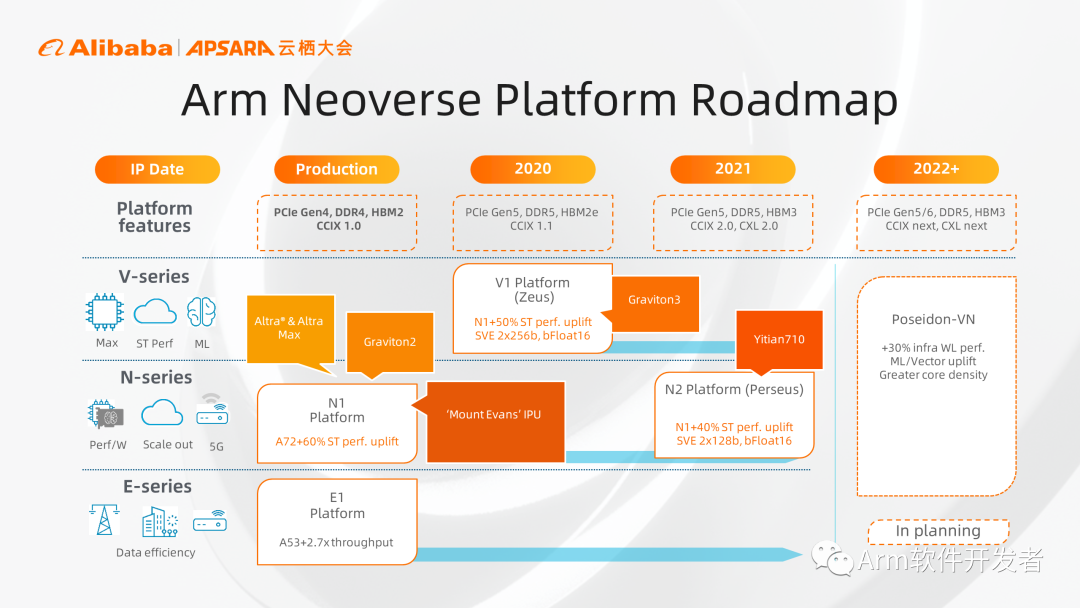
2018年Arm战略性地将服务器芯片设计和传统客户端芯片设计分离,推出了Arm Neoverse产品线,纵向看Arm Neoverse平台有三个系列产品,V系列、N系列和E系列。V系列强调性能,可提供最高单核处理能力,主要用于HPC和数据中心云应用等;N系列更注重性能、功耗和面积的平衡,具备最高的可扩展性,主要适用于数据中心、云计算应用;E系列更注重功耗和面积,主要应用于无线接入等功耗受限的领域。
横向看Neoverse平台近几年推出的CPU产品,N1平台是第一代聚焦基础设施的CPU实现,目前已经获得广泛应用。在服务器领域,基于N1的产品有AWS和Ampere的服务器芯片,DPU领域有英特尔基于Neoverse N1的DPU实现。第二代是V1,属V系列产品,更注重单核性能,新增2×256的SVE加速引擎,AWS的Graviton 3是基于V1来实现的,并且已经于今年5月份正式商用。
N2是第一个支持Armv9架构的CPU核心,支持2×128的SVE引擎,倚天710芯片也是基于N2平台实现的。
Poseidon平台基于Armv9.2架构,在N2的基础上性能再提高30%,且增加了CCA架构特性,支持机密计算。

上图展示的是Arm Neoverse平台推出以来,在最近两年时间里取得的一些成就。可以看到在云上,AWS、微软、谷歌、阿里云等都推出了基于Arm Neoverse的云实例。在智能网卡领域,Marvell推出了基于Neoverse的智能网卡,谷歌云和英特尔联合推出了“Mt Evans”DPU。在企业领域,惠普发布了基于Ampere的ProLiant Gen11平台,也代表Arm正进入传统的企业领域。同时在规范方面,Arm推出了System Ready认证项目,针对Arm系统的软硬件进行测试认证,确保最终Arm的系统可以开箱即用和安装多样的操作系统,过去两年已经有五十多个系统获得System Ready认证。

聚焦云计算领域,从上图中可以看到Arm Neoverse系统已经被部署在公有云、私有云,混合云等方方面面,且已经被国内外主流云计算厂商所采用,比如阿里云、腾讯云、AWS、微软、谷歌等。

在云原生的软件生态方面,Arm持续致力于开源软件开发和支持。目前Arm对超过100个开源项目进行投入,可以看到(上图)自下而上从网络、OS、虚拟化、容器,编程语言以及各种上层应用负载,Arm都有很完善的支持。对底层网络侧的DPDK、OVS、ODP均可支持。在语言层面,OpenJDK、GoLang等也都可以在Arm平台上直接运行,包括压缩方面的主流计算库,Arm也可以很好的支持。
顶部(上图)列出了一些主流的云负载应用,有常见的一些数据库、缓存、Web服务器、大数据、存储等。左侧(上图)中可以看到Arm在CI/CD领域也有很大的投入,GitLab、Github Actions、Travis等都原生支持Arm系统,方便开发者在Arm系统上进行开发构建。

在操作系统领域,从主流的发行版OS到社区版OS,Arm都已经是所谓的”第一等公民“,Red Hat Enterprise Linux、CentOS、SUSE、龙蜥社区等对Arm系统都有原生支持。

在编译器领域,在GCC和LLVM,Arm和生态伙伴一起合作,持续投入,确保在Silicon硬件系统面世以前,相应的架构特性和微架构实现就在编译器中获得支持。随着编译器版本的更新,Arm会逐步支持相应架构特性,以及相应微架构实现,保证客户用最简便的编译方法获得最优化的运行性能。
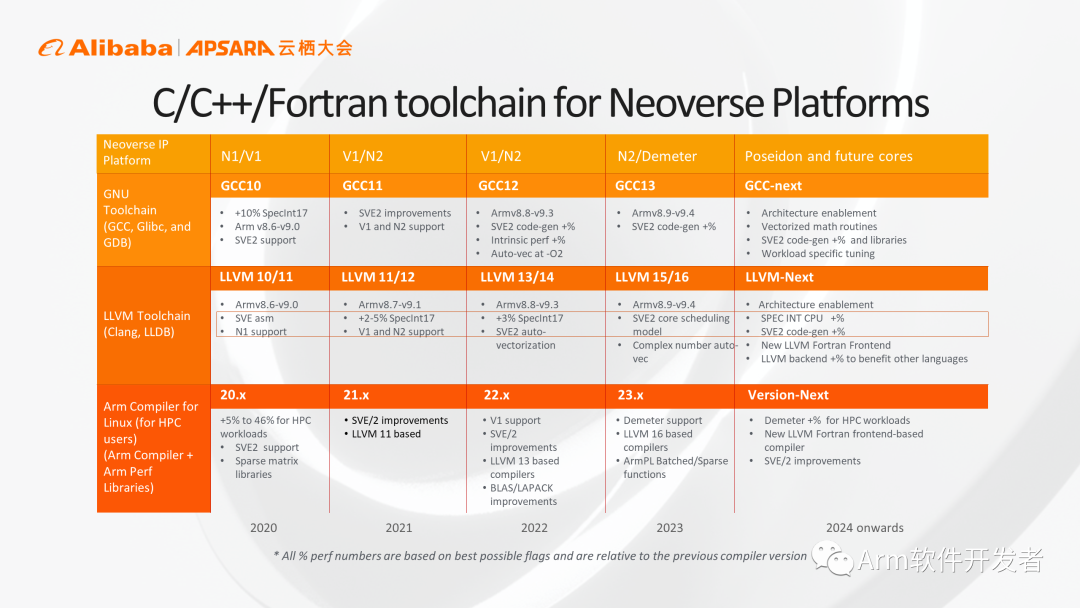
从另一角度可以看到,Arm会把自己的IP路线图和编译器路线图相配合,例如在2024年之后,相应的编译器就会支持Poseidon,我们会在Poseidon平台落地前,就把相应的功能支持加入到编译器当中,保证最终用户拿到硬件之后可以第一时间用现有的编译器获得最好的性能。
02 多兼容,可扩展,Arm多业务场景性能大幅提升
下图中列了Neoverse平台的N1、N2两款CPU核心以及Cortex A72的性能对比及架构特性的增强。Arm Neoverse N1这款CPU核心,对比Cortex A72有60%的性能提升,同时降低了30%的功耗。Arm Neoverse N1加入了很多服务器领域的架构特性,例如独立的L2 Cache,支持原子操作,同时也支持基本的RAS特性。

接下来的Neoverse N2 CPU核心,在N1基础上提升了35%的性能,且保持了同样的功耗,使得N2有了非常好的可扩展性,同时N2也是第一款支持Armv9架构的CPU实现,尤其指出N2实现了MPAM架构特性,类似于传统x86的RDT,可以把内存及cache进行隔离划分,可以避免系统抖动及云环境下多租户之间的相互影响。
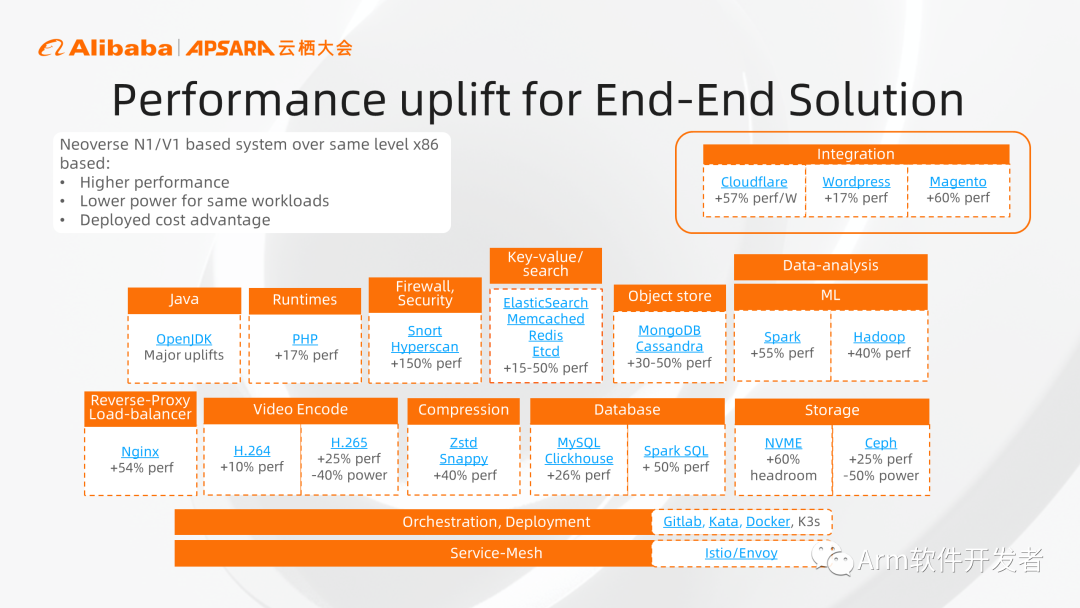
使用基于Arm Neoverse平台的服务器,可以获得更高的性能,更低的功耗,以及最终带来更低的部署成本。给大家列一个端到端的例子,上图中包含网络服务的端到端的解决方案,可以看到从整个解决方案中的各种软件,Arm都有相应的性能提升,比较熟悉的包括前端的web服务、反向代理、防火墙,后端的数据库、缓存,以及业务处理的Java、视频编解码等,Arm系统相对于同代的x86系统,都有20%以上的性能优势。
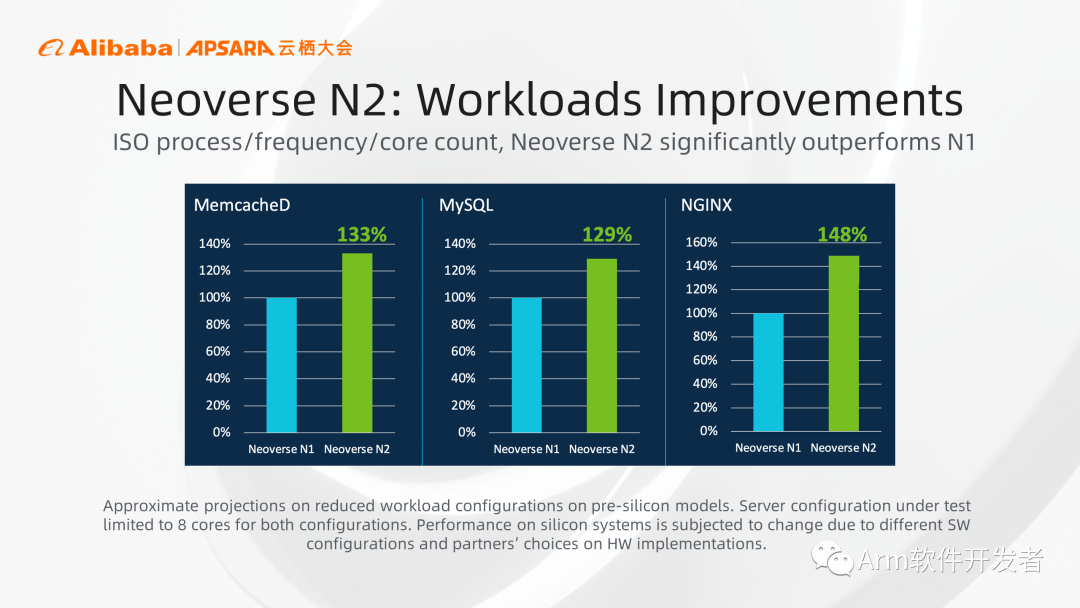
相对于第一代N1来说,N2在各种应用负载上均有大幅的性能提升,在MemcacheD、MySQL、NGINX上分别有30%、29%、48%的性能提升。
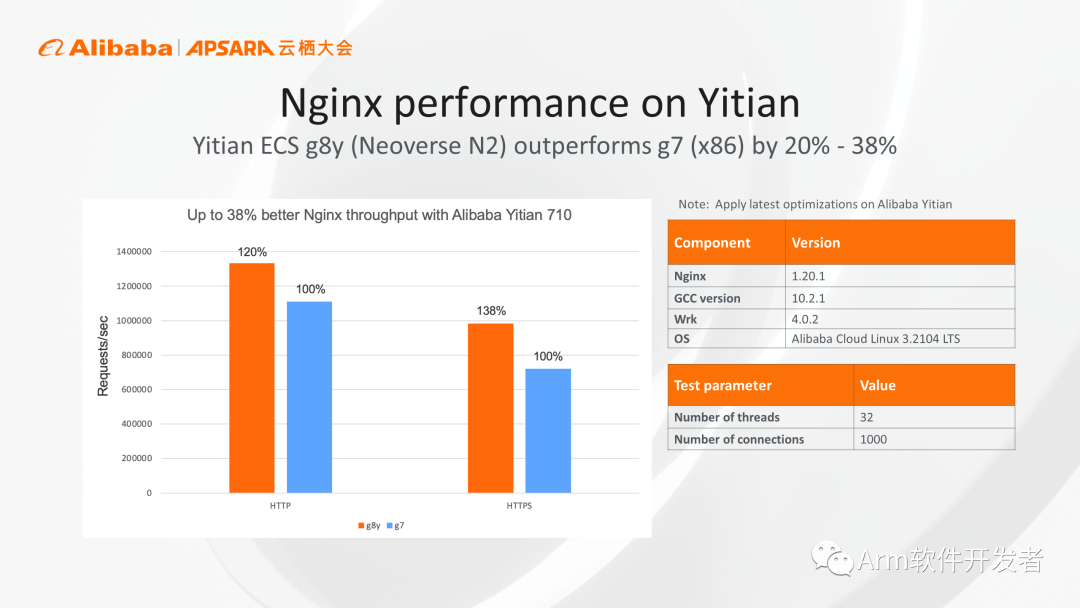
上图中为大家展示的是我们基于Neoverse N2的倚天G8y实例,和传统x86实例的实测对比结果,我们对Web服务器场景进行测试,使用默认的编译器及软件版本,最终测试得到的结果显示,对于HTTP场景下,G8y实例相对于x86实例有20%的性能优势。如果再考虑加密层面,针对HTTPS进行测试会有38%的性能优势。倚天G8y实例将于11月15号正式商用,相应的测试参数都在上图中列了出来,大家可以参考进行对比测试。
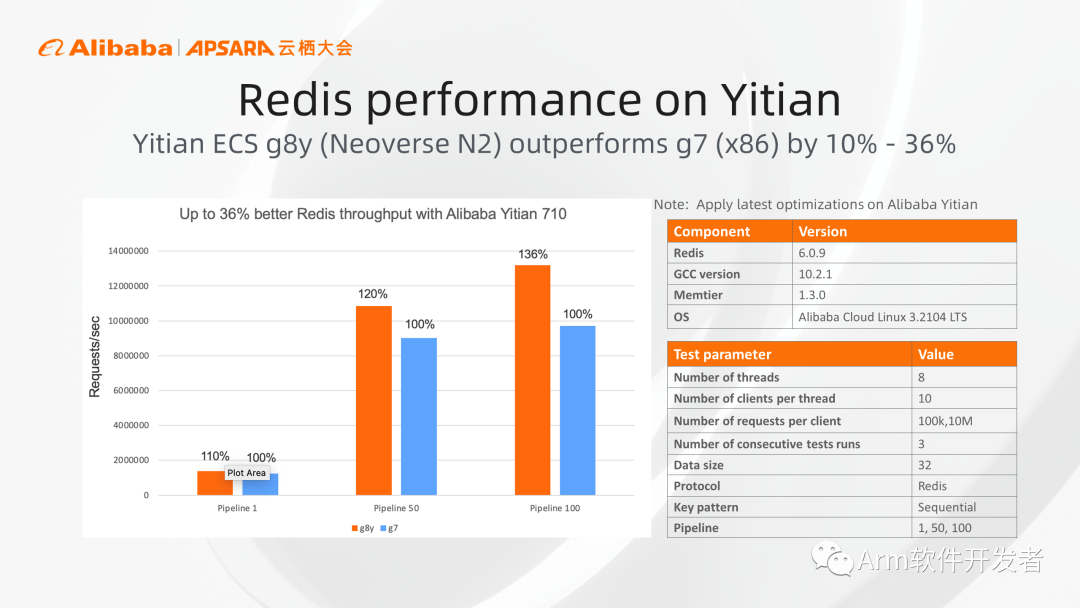
同时我们也进行了内存数据库Redis的测试,在pipeline参数分别设置为1、50、100的情况下,基于倚天710芯片的g8y实例相对于x86实例分别有10%、20%,36%的性能收益。其中整个软件都是直接用现有的开源软件项目直接下载并直接编译安装,无需经过任何手动优化即可获得图中的结果。
03 有效操作优化保障代码安全,实现性能提升
在上文中我们已经看到,Arm本身有很完善的软件生态,尤其在云原生领域,用户在使用的时候,基本无需进行特殊代码改动,接近于开箱即用的场景,我这边给到大家的迁移建议主要是针对一些自研非开源的软件,尤其是大家之前的软件中使用了一些针对x86系统的手动优化,在这些场景下,主要是在SIMD并发处理和内存访问优化方面给大家提一些建议。

首先是SIMD单指令多数据的优化,通过使用这种技术,我们可以在一条指令中同时执行多个操作,提高操作并行度,进而最终提高IPC。Arm架构主要包含两个架构扩展,Neon和SVE,特别适合用在一些数据量比较大的处理场景,起到加速作用,例如视频编解码、图形图像处理、音频语音处理、压缩与解压缩,以及一些网络的处理等等。
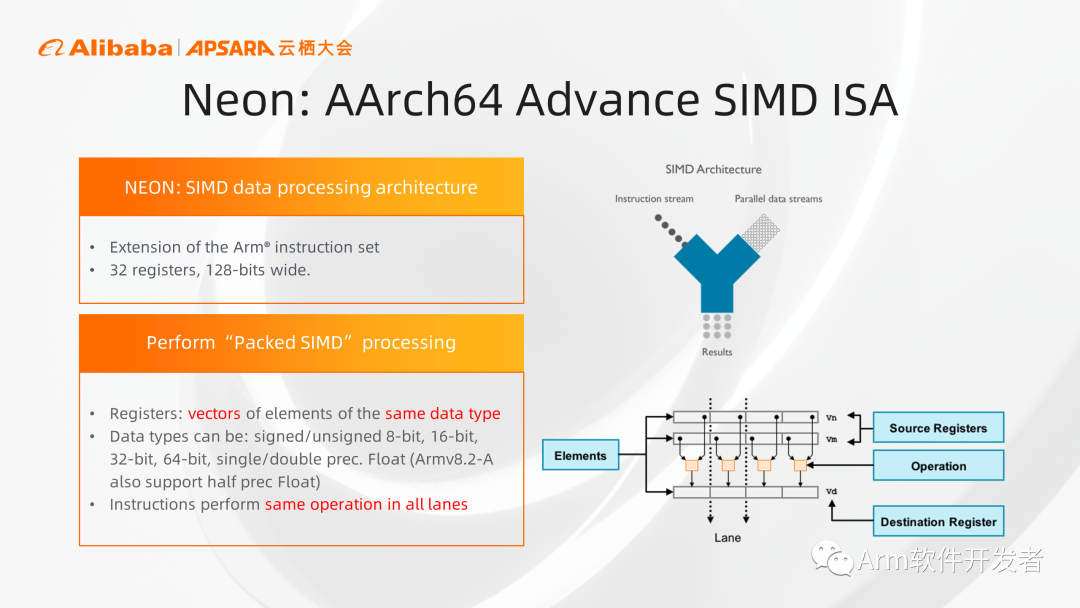
首先来看Neon,我们可以把一个128比特的寄存器,当做是几个元素的集合,元素的大小可以是8、16、32、64位,元素可以被当作整数或者浮点数进行处理,但是要保证这里面的每个元素和数据类型是相同的,对应的元素会组成一个通道,当我们执行一条Neon指令的时候,就可以同时处理多个数据元素,提高效率。
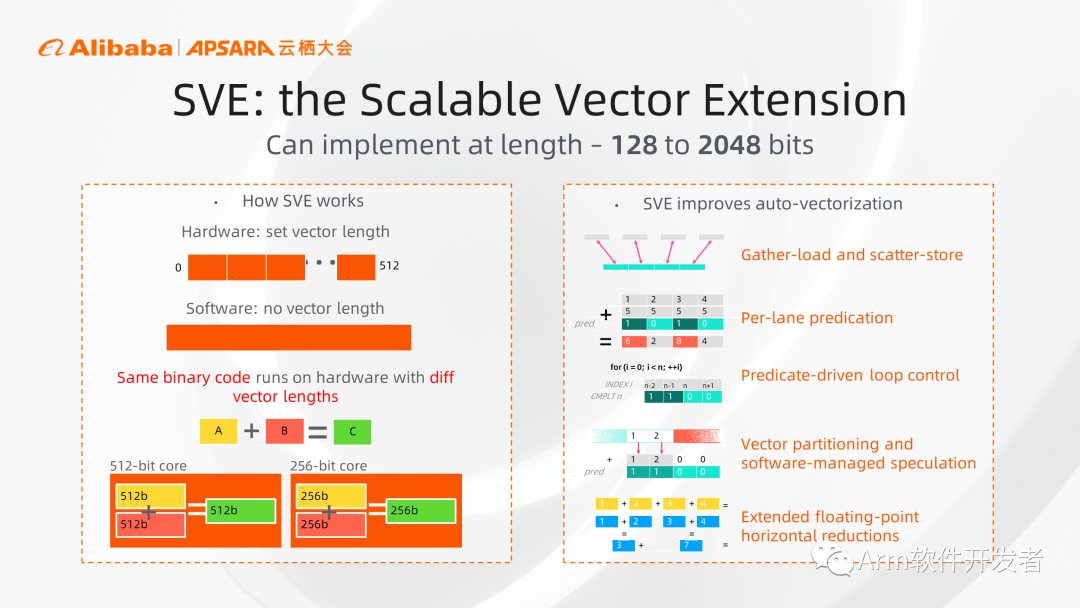
再看SVE架构扩展,其功能和Neon类似,但SVE相比Neon主要有两个方面的优势:
1、从架构角度看,Neon寄存器宽度固定为128比特,限制了它的扩展。SVE在架构上允许从128一直到2048比特的位宽,只要是128比特的整数倍就可以,给了设计者更大的灵活度。
2、从软件角度看,SVE在软件上不需要关心Vector具体的宽度,开发人员只需要写一套代码,就可以运行在不同硬件上。

关于使用Neon和SVE加速,最常用的方式是通过传入一些编译选项,或者编译器识别当前CPU类型去自动应用Neon和SEV加速。但如果大家发现了一些热点想要手动进行优化的时候,建议直接用intrinsics方式,相对于汇编代码,代码逻辑更清晰且更容易编写,同时也便于编译器进一步进行性能优化。

关于性能优化的例子:Arm在SPDK当中应用Neon对算法进行优化,无论编码还是解码,基本上都有大约2倍的性能提升,在SPDK内存清零操作中,使用SVE加速获得了8倍的性能提升。右侧(上图)是代码的示例,通过代码示例,在右下角也可以看到,这套代码没有具体vector宽度的指定,不管最终SVE硬件的宽度是128还是256, 都可以直接运行。另外也可以看到这个SVE版本的循环没有针对尾循环的特殊处理,因为SVE扩展配合特殊的循环指令以及相应的掩码预测寄存器,可以自动处理尾循环。
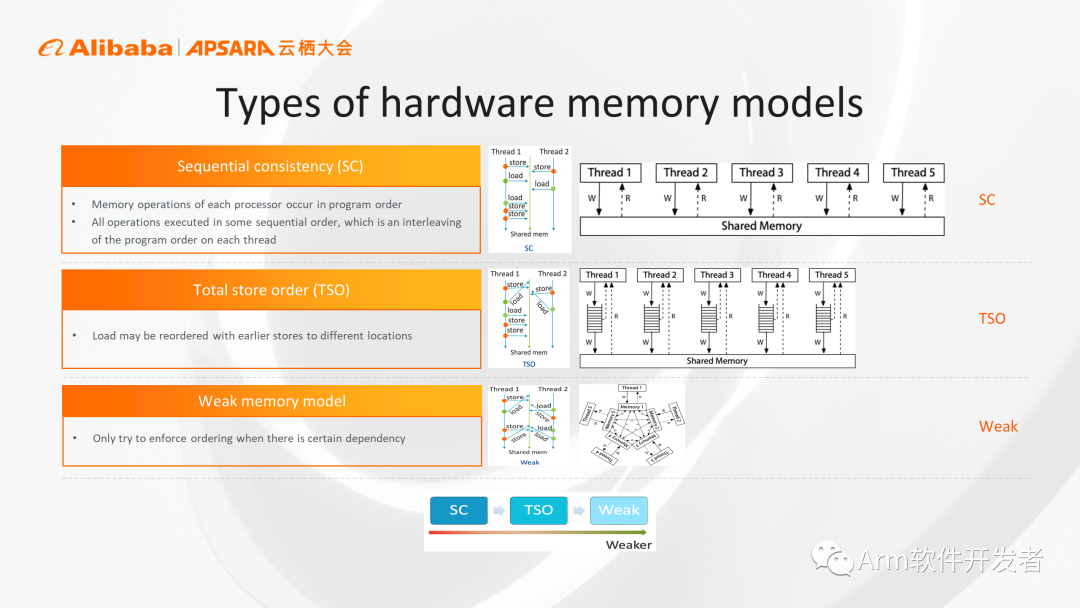
Arm和传统x86 CPU之间一个很显著的区别是它们的内存模型(memory model)。大家最直观的内存序是顺序内存序(SC),这种情况下所有的内存操作都不会乱序,好处是容易理解,但对于CPU的实现限制太严,会严重影响CPU性能。目前比较多的是x86采用的TSO模型,相对于第一种SC,解除了一些限制,允许存储和加载这两个操作乱序。
Arm架构则采用了一种限制更少的memory model,这种模型下所有的内存加载和存储操作都可以进行乱序,这样给了微架构设计者最大的自主权,可以带来更高的性能。
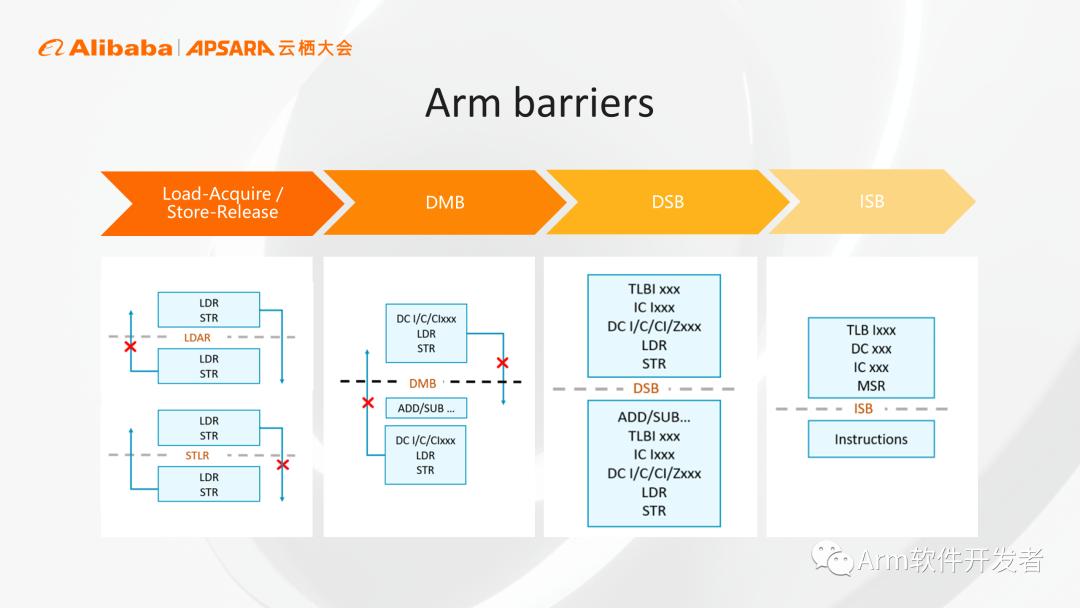
Arm为了提高性能允许各种内存操作进行乱序,当我们需要按照一种固定的顺序执行时,Arm提供了各种内存栅栏来保证内存访问的顺序,帮助大家来保证代码正确性。从左到右(上图)分别是Load-Acquire / Store-Release半栅栏、DMB全栅栏、DSB、ISB,屏障的限制越来越强,对性能的影响也越来越大,在保障正确性的前提下,尽量选择比较弱的栅栏,做到恰到好处地实现正确性和性能的平衡。
我们的建议是写代码时,先选择比较强的栅栏,保证代码的正确性,后续进行代码评测优化的过程中如果发现成为瓶颈的话,再选用一些比较弱的栅栏进行优化。

上图是Arm对DPDK Virtio应用进行优化的例子,包含前端后端,通过一个队列进行通信,相当于一个生产者一个消费者。这里最初使用的是全栅栏,后续在性能测试时发现是一个瓶颈,做优化时把相应的全栅栏DMB换成了半栅栏后,在PVP测试场景下获得了20%的性能提升,只要改动这一处即可达到性能提升的效果。

这里说明一下,Arm memory model是一种硬件定义的内存模型,对于大多数情况,我们并不建议大家直接操作依赖于具体架构的汇编代码,一种更推荐的方式是借助于语言定义的memory model,例如我们可以使用C++11或者C11的memory model,调用其API,这样工具链会处理语言的memory model并自动映射到最终硬件架构的memory model,这样的操作方便移植且不容易出错。
最后再次强调,与内存序相关的编程非常复杂,memory model是非常容易出问题的点,我们必须仔细权衡其正确性和性能。为了代码的安全,建议大家在开发初期可以使用一些较强的屏障指令保证逻辑正确,在后续的代码优化过程当中,通过移除一些冗余屏障或在必要时切换到较轻的屏障,最终达到提高性能的目的。
以上就是我要分享的全部内容,谢谢大家。
审核编辑 :李倩
-
cpu
+关注
关注
68文章
11330浏览量
225904 -
迁移
+关注
关注
0文章
35浏览量
8189 -
生态系统
+关注
关注
0文章
711浏览量
21617
原文标题:安谋科技(Arm China)高级软件经理别再平:Neoverse生态与软件迁移
文章出处:【微信号:Arm软件开发者,微信公众号:Arm软件开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Arm亲自下场!自研首款数据中心AGI CPU发布!

如何在Arm Neoverse N2平台上提升llama.cpp扩展性能
西门子EDA与Arm携手合作加速系统设计验证进程与软件启动

Arm架构助力Azure Cobalt 100虚拟机工作负载性能提升

Arm Neoverse平台集成NVIDIA NVLink Fusion
Arm Neoverse CPU上大代码量Java应用的性能测试

全新Arm Lumex CSS平台实现两位数性能提升

微电子所在芯粒集成电迁移EDA工具研究方向取得重要进展
Arm神经超级采样 以ML进一步强化性能 实现卓越的移动端图形性能

西门子 Veloce CS 助力 Arm Neoverse 计算子系统验证与确认
包云岗:原位替代 ARM,并未真正发挥 RISC-V 的优势
Arm Neoverse N2平台实现DeepSeek-R1满血版部署




评论