 【AI简报20221028】 vivo公布自研芯片、AR-HUD处于爆发前夜
【AI简报20221028】 vivo公布自研芯片、AR-HUD处于爆发前夜

嵌入式 AI
AI 简报 20221028 期
1. vivo公布自研芯片黑科技 AI-ISP让算力捅破天
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
在讨论一款手机的实力时,影像是其中最重要的评判维度之一。随着手机摄影的发展,许多之前困扰手机的拍照难题,都迎来了行之有效的解决方案。其中,自研影像芯片成为移动影像迭代的一个核心方向,让手机能够在暗光和运动场景等一些高挑战性场景中拍出好照片。
如今,一聊到自研芯片,很多熟悉数码圈的朋友第 一时间想到的可能就是蓝厂了。2021 年,vivo X70 系列携vivo自研芯片V1 发布,实现更好的夜景成像效果,加之vivo对影像技术的大力投入,使得X系列获得了很高的市场与消费者口碑。从X70 系列之后,手机行业也正式掀起了自研影像芯片的潮流。

在刚刚结束的影像战略发布会上,vivo展示了其完善的影像技术矩阵。作为影像算法升级的最有力保障,vivo宣布将在下一代自研芯片设计中升级全新的架构——从传统ISP架构升级为AI ISP架构,进一步提升影像效果体验。
那么问题来了,AI-ISP是什么?
传统ISP架构虽然能以极低延时处理大量的数据流水,但只能解决已知的、特定的问题,面对复杂、随机问题时则会面临巨大的困难。而AI擅长处理复杂的、未知的问题。因此,将传统 ISP 低延时、高能效的特点进一步带入到 AI 实时处理运算架构中,AI-ISP应运而生。AI-ISP架构结合两者的优势,相当于给传统ISP芯片加一个新的AI大脑。
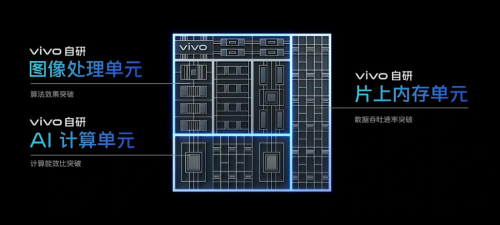
据vivo介绍,在AI-ISP上集成vivo自研的AI计算单元,让数据吞吐速率、能效比都有了大幅提升,更适合海量的信息处理,因此能实现发散式的信息处理及存储,使得处理与存储的效率大大提高。在此基础上AI-NR降噪、HDR影调融合、MEMC插帧等算法效果可以得到极大的优化。
2. 车载抬头显示HUD从“黑科技”走向标配,AR-HUD处于爆发前夜
原文:
https://mp.weixin.qq.com/s/TMhMjFZbw96n4CUkVQ_z1w
在高端乘用车完成试点以及认知普及之后,车载HUD(抬头显示系统)终于在2020年开始了规模商用,很多人将这一年定义为车载HUD的产业化元年。在智能驾驶汽车的推动下,HUD有望在乘用车搭载方面更进一步,成为系统标配,产业将迎来爆发期。
根据QYResearch的《2022-2028中国车载HUD系统市场现状研究分析与发展前景预测报告》市场调研报道,2022年全球车载HUD市场规模有望达到22亿美元,渗透率达到9.5%;到2025年,车载HUD渗透率有望达到45%,2019年-2025年的年复合增长率高达71%。
从C-HUD到AR-HUD
HUD的英文全称是Head Up Display,所以中文译作抬头显示系统,最早应用于军用飞机上,帮助驾驶员减轻认知负荷。发展至今,车载HUD已经演化出三种形式,也完成了从C-HUD到AR-HUD的蜕变,另外一种是W-HUD。
C-HUD是指Combiner HUD,组合式抬头显示系统。C-HUD是将信息投放在仪表盘上方的树脂板上,这是一个半透明的板子,能够反射出投射信息的虚像。由于C-HUD需要树脂板作为投放介质,因此往往会以后装的方式安装,这就导致C-HUD存在一些“先天性”的弊病,比如投射范围小,距离近,且容易引发车祸时的二次伤害。
W-HUD是指Windshield HUD,属于C-HUD的升级版,不再需要树脂板这样的辅助器材,如其名称所显露的,W-HUD直接将信息投放在汽车前挡风玻璃上。由于没有介质板的限制,W-HUD的投射范围更大、更远。不过,由于汽车挡风玻璃的形状是弧形、斜向的,增加了光学信息的投射难度,产品光学结构相对复杂,成本相对较高。
比W-HUD更进一步的便是AR-HUD,全称为Augmented Reality HUD。顾名思义,AR-HUD便是AR技术在汽车领域的一次成功的应用尝试。AR-HUD的投放介质同样是汽车挡风玻璃,相较于W-HUD投放信息和道路实况是脱离的,AR-HUD通过数字微镜原件生成图像元素,经过反射镜投射出去的图片具有层次感,分为近投影和远投影。其中近投影所包含的速度和油表信息与W-HUD差别不大,不过远投影能够实现虚拟图像和现实路况的融合,增加驾驶员对道路信息的认知,使得驾驶更方便安全。
根据德州仪器的介绍和演示,如果要实现AR-HUD,VID>7米,并且FOV>10°。在远投影方面,将融入跟车提醒、行人预警、车道偏离指引、变道指引等信息。
目前,在车载HUD市场上,W-HUD是市场主流,AR-HUD则是未来的趋势,已经进入量产和推广阶段。不过,AR-HUD比W-HUD的光学系统更复杂,成本也就更高,因此最先搭载AR-HUD的车型大都价格不菲,以中高端车型为主。
产业上下游积极布局
无论是现阶段的W-HUD,还是未来的AR-HUD,都受到了车厂的推崇,是汽车智能座舱重要的组成部分,也是汽车核心卖点之一。
从产业链分布来看,车载HUD的上游主要是原材料供应厂商和软件方案公司,中游是各大车载HUD品牌商,下游则是整车厂。车载HUD所用到的原材料除了挡风玻璃和曲面镜以外,最重要的还是显示源,也就是光学系统。
车载HUD显示源用到的主要芯片包括控制芯片、ISP芯片、DLP、LCD芯片、LCOS芯片等。供应商包括德州仪器、京东方、爱普生、非宝电子、索尼等企业。目前,W-HUD用到的主要激光显示技术包括四种:DLP、LCD、LCOS以及MEMS激光投影。
在DLP方面,和全球数字放映机市场类似,TI在车载DLP芯片方面具有绝对的领先优势。该公司自2015年发布首款应用车载HUD的DLP芯片组之后,此后一直深耕于此,目前基于TI的DLP芯片组已经能够实现AR-HUD方案。
LCD液晶投影技术具有图像色彩饱和度好,层次丰富,色彩分离好等优点,主要的核心技术掌握在索尼和爱普生手中,不过国内的京东方、天马、信利等也在布局这一块;LCOS是硅基液晶技术,索尼同样是重要的技术提供商,此外还有JVC和晶典等。
MEMS激光投影是将RGB三基色激光模组与微机电系统结合的投影显示技术,优点是高亮度、体积小、色域广,不过成本也相对较高。相较于其他显示方案的核心技术握在国际厂商手里,MEMS激光投影被认为是自主品牌在车载HUD核心芯片突围的好机会。目前,车规级MEMS激光投影芯片主要供应商是Microvision、丰宝电子等。
在品牌方面,目前W-HUD的主要市场份额主要掌握在外资品牌手中,包括电装、日本精机、伟世通、德国大陆等,这些公司占据着国内外大部分的市场份额,并拥有成熟的前装供应链体系,也具备前装优势。当然,国内的汽车零部件生产商泽景电子、华阳集团、均胜电子等也在布局车载HUD。随着AR-HUD进入量产阶段,目前华为、欧菲光等科技企业以及未来黑科技、点石创新等初创企业迎来市场机遇。
据统计,2021年以来AR-HUD密集上车,长城摩卡、吉利星越L、大众ID系列、广汽传祺GS8、北汽魔方、飞凡R7等车型均选择搭载了AR-HUD,在2021年上半年,AR-HUD在国内的装配量达到3.5万辆,并且已经在2021年8月份超过了C-HUD。
对于国产厂商而言,想要突围目前来看还是任重道远。截止到2020年的统计数据显示,国内车载HUD市场的前三大厂商均为国际厂商,分别是精机、大陆集团和电装,市占比分别为33.3%、27%和20%。
写在最后
目前,车载HUD正处在W-HUD向AR-HUD过渡的时代,国际Tier 1级汽车零部件供应商的话语权在降低,国产品牌迎来了机会,在核心器件和品牌方面都已经打入到市场中心区域。不过,汽车供应链一直以来都较为稳定,国产品牌想要更进一步,还需在技术和产品性能上领先于人。
3. AI传感器成为趋势!功耗更低、效率更高
原文:
https://mp.weixin.qq.com/s/ElDo7m_fsbbp6rRUW99pYw
近日消息,剑桥初创公司InferSens表示,将其低功耗传感器与复杂深度学习技术相结合,研究了用于智能建筑的低功耗边缘AI传感器。
InferSens使用具有本地AI模型和创新机械和系统工程的第三方处理器来为建筑环境创建智能传感器。该公司传感器技术的第一个版本计划于2023年第一季度推出。这是一种低成本、电池供电的水流量和温度传感器,用于监测和检测水系统中的军团菌风险。
意法半导体、索尼等传统芯片厂商都推出AI传感器
不久前,意法半导体也推出了内置智能传感器处理单元 (ISPU) 的惯性传感器ISM330ISN。ISM330ISN内置的智能技术赋能智能设备在传感器中执行高级运动检测功能,而无需与外部微控制器 (MCU)交互,从而降低了系统级功耗。
意法半导体的方法是直接在传感器芯片上集成为机器学习应用优化的专用处理器 ISPU。意法半导体的 ISPU基于数字信号处理 (DSP) 架构,极其紧凑和节能,具有 40KB 的 RAM内存。ISPU 执行单精度浮点运算,是设计机器学习应用和二元神经网络的理想选择。
这个智能内核占用的芯片面积非常小,因此,ISM330ISN模块的封装面积比典型的在封装内整合MCU的传感器解决方案小50%,功耗低 50%。
意法半导体模拟 MEMS 和传感器产品部营销总经理 Simone Ferri 表示,智能从前是部署在网络边缘的应用处理器上,而现在正在转向深度边缘的传感器内部。ISM330ISN IMU 预示着新一类智能传感器的来临,即开始利用嵌入式 AI 处理复杂任务,比如模式识别和异常检测,可以大大提高系统能效和性能。
其实早在2020年,索尼就宣布推出了两款AI图像传感器——IMX500和IMX501。AI图像传感器兼具运算能力和内存,能够在没有额外硬件辅助的情况下执行机器学习驱动的计算机视觉任务,可以使很多依赖机器学习算法的图像处理技术能够在本地运行,更简单、高效、安全。
索尼推出的AI图像传感器,首批目标是零售商和工业客户。索尼业务与创新副总裁马克·汉森认为,相比将数据发送到云端的解决方案,AI图像传感器的应用潜力巨大,成本效益更高,尤其是在边缘计算领域。
商汤、旷视等新兴AI技术公司也在探索AI传感器
除了传统的传感器厂商之外,商汤、旷视等AI公司也在探索AI传感器。今年7月,商汤智能产业研究院发布《AI传感器:智能手机影像新核心》白皮书。该白皮书提到,在智能手机市场缓慢步入瓶颈期的趋势下,影像功能成为产业破局焦点,而AI软件与CMOS图像传感器硬件的融合,将是智能手机影像能力持续提升的破题之道。
过去几年,AI算法让手机的影像能力得到了不小的提升。但在这种方案中,图像传感和AI算法的运行,在不同的硬件上完成,图像传感器提供图像信号,处理器或者AI加速芯片执行AI算法。这会造成能耗资源的浪费,并且难以处理一些需要及时响应的场景。
白皮书指出,融入了AI技术的CMOS图像传感器,可以最大化地发挥原始光信号的价值。
在设备获取视觉信号的伊始,AI传感器就可以进行优化和处理,增强真实世界感知、提高图像和视频的质量、丰富内容细节,同时最大限度地降低了设备功耗,并增强了数据安全性。
据介绍,早在2019年,商汤就与全球领先的图像传感器厂商开展紧密合作,将AI算法和传感器硬件直接融合。目前,商汤AI传感器已完成多款产品,并成功落地多款高端旗舰手机。
商汤认为,面向未来,AI传感器的价值不仅在于提升智能手机的影像能力,它更将成为机器认知世界的基础设施,为更多物联网终端赋予智能感知与内容增强的能力。比如,在智能汽车领域,AI传感器将成为车辆感知世界的核心部件;在智慧城市领域,AI传感器更将为挖掘视频信息的价值发挥重要作用。
旷视研究员范浩强今年7月也在某个论坛上谈到,随着AI、视觉算法等领域的发展,传感器将不再单独的、直接地提供应用价值,传感器和应用之间需要算法来作为承上启下的桥梁。从技术角度讲,这两者最显著的结合点就是计算摄影。
旷视也已经深度参与手机影像的能力提升中,目前旷视的4K级别的硬件方案已经实现了量产,并积极推动8K AI画质硬件方案的研发与产品化。
小结
从传统芯片厂商及AI公司的表现来看,AI传感器似乎成为一种新的趋势。在传感器内部增加智能的部分,有诸多好处,之前传感器和AI算法的运行实在不同的硬件上完成,耗费资源,而增加了智能的AI传感器,可以使得整个系统更简单、更高效、更安全。
4. 掀起一股中国风,最强中文AI作画大模型文心ERNIE-ViLG 2.0来了
原文:
https://mp.weixin.qq.com/s/x3dnkBF7BKDMEU_rt8QmDg
据了解,ERNIE-ViLG 2.0 在文本生成图像公开权威评测集 MS-COCO 和人工盲评上均超越了 Stable Diffusion、DALL-E 2 等模型,取得了当前该领域的世界最好效果,在语义可控性、图像清晰度、中国文化理解等方面均展现出了显著优势。
论文链接:
https://arxiv.org/pdf/2210.15257.pdf
体验链接:
https://wenxin.baidu.com/ernie-vilg
AIGC (AI-Generated Content) 是继 UGC、PGC 之后,利用 AI 技术自动生成内容的新型生产方式。AI 作画作为 AIGC 重要方向之一,蕴含了极大的产业应用价值。相比于人类创作者,AI 作画展现出了创作成本低、速度快且易于批量化生产的巨大优势。
近一年来,该领域迅猛发展,国际科技巨头和初创企业争相涌入,国内也出现了众多 AI 作画产品,这些产品背后主要使用基于扩散生成算法的 DALL-E 2 和 Stable Diffusion 等国外模型。目前,这类基础模型在国内尚处空白,ERNIE-ViLG 2.0 是国内首个在该方向取得突破的工作。
当前 AI 作画技术在图像细节纹理的流畅度、清晰度、语义的可控性等方面还存在诸多问题。基于此,百度提出了基于知识增强的混合降噪专家(Mixture-of-Denoising-Experts,MoDE)建模的跨模态大模型 ERNIE-ViLG 2.0,在训练过程中,通过引入视觉知识和语言知识,提升模型跨模态语义理解能力与可控生成能力;在扩散降噪过程中,通过混合专家网络建模,增强模型建模能力,提升图像的生成质量。
我们先来欣赏下 ERNIE-ViLG 2.0 根据文本描述生成图像的一些示例:
ERNIE-ViLG 2.0 可应用于工业设计、动漫设计、游戏制作、摄影艺术等场景,激发设计者创作灵感,提升内容生产的效率。通过简单的描述,模型便可以在短短几十秒内生成设计图,极大地提升了设计效率、降低商业出图的门槛。
5. DeepMind新作:无需权重更新、提示和微调,transformer在试错中自主改进
原文:
https://mp.weixin.qq.com/s/zKQIlXJ1jRKCyGQn_dqjDw
论文地址:
https://arxiv.org/pdf/2210.14215.pdf
目前,Transformers 已经成为序列建模的强大神经网络架构。预训练 transformer 的一个显著特性是它们有能力通过提示 conditioning 或上下文学习来适应下游任务。经过大型离线数据集上的预训练之后,大规模 transformers 已被证明可以高效地泛化到文本补全、语言理解和图像生成方面的下游任务。
最近的工作表明,transformers 还可以通过将离线强化学习(RL)视作顺序预测问题,进而从离线数据中学习策略。Chen et al. (2021)的工作表明,transformers 可以通过模仿学习从离线 RL 数据中学习单任务策略,随后的工作表明 transformers 可以在同领域和跨领域设置中提取多任务策略。这些工作都展示了提取通用多任务策略的范式,即首先收集大规模和多样化的环境交互数据集,然后通过顺序建模从数据中提取策略。这类通过模仿学习从离线 RL 数据中学习策略的方法被称为离线策略蒸馏(Offline Policy Distillation)或策略蒸馏(Policy Distillation, PD)。
PD 具有简单性和可扩展性,但它的一大缺点是生成的策略不会在与环境的额外交互中逐步改进。举例而言,谷歌的通才智能体 Multi-Game Decision Transformers 学习了一个可以玩很多 Atari 游戏的返回条件式(return-conditioned)策略,而 DeepMind 的通才智能体 Gato 通过上下文任务推理来学习一个解决多样化环境中任务的策略。遗憾的是,这两个智能体都不能通过试错来提升上下文中的策略。因此 PD 方法学习的是策略而不是强化学习算法。
在近日 DeepMind 的一篇论文中,研究者假设 PD 没能通过试错得到改进的原因是它训练用的数据无法显示学习进度。当前方法要么从不含学习的数据中学习策略(例如通过蒸馏固定专家策略),要么从包含学习的数据中学习策略(例如 RL 智能体的重放缓冲区),但后者的上下文大小(太小)无法捕获策略改进。

研究者的主要观察结果是,RL 算法训练中学习的顺序性在原则上可以将强化学习本身建模为一个因果序列预测问题。具体地,如果一个 transformer 的上下文足够长,包含了由学习更新带来的策略改进,那么它不仅应该可以表示一个固定策略,而且能够通过关注之前 episodes 的状态、动作和奖励来表示一个策略改进算子。这样开启了一种可能性,即任何 RL 算法都可以通过模仿学习蒸馏成足够强大的序列模型如 transformer,并将这些模型转换为上下文 RL 算法。
研究者提出了算法蒸馏(Algorithm Distillation, AD),这是一种通过优化 RL 算法学习历史中因果序列预测损失来学习上下文策略改进算子的方法。如下图 1 所示,AD 由两部分组成。首先通过保存 RL 算法在大量单独任务上的训练历史来生成大型多任务数据集,然后 transformer 模型通过将前面的学习历史用作其上下文来对动作进行因果建模。由于策略在源 RL 算法的训练过程中持续改进,因此 AD 不得不学习改进算子以便准确地建模训练历史中任何给定点的动作。至关重要的一点是,transformer 上下文必须足够大(即 across-episodic)才能捕获训练数据的改进。
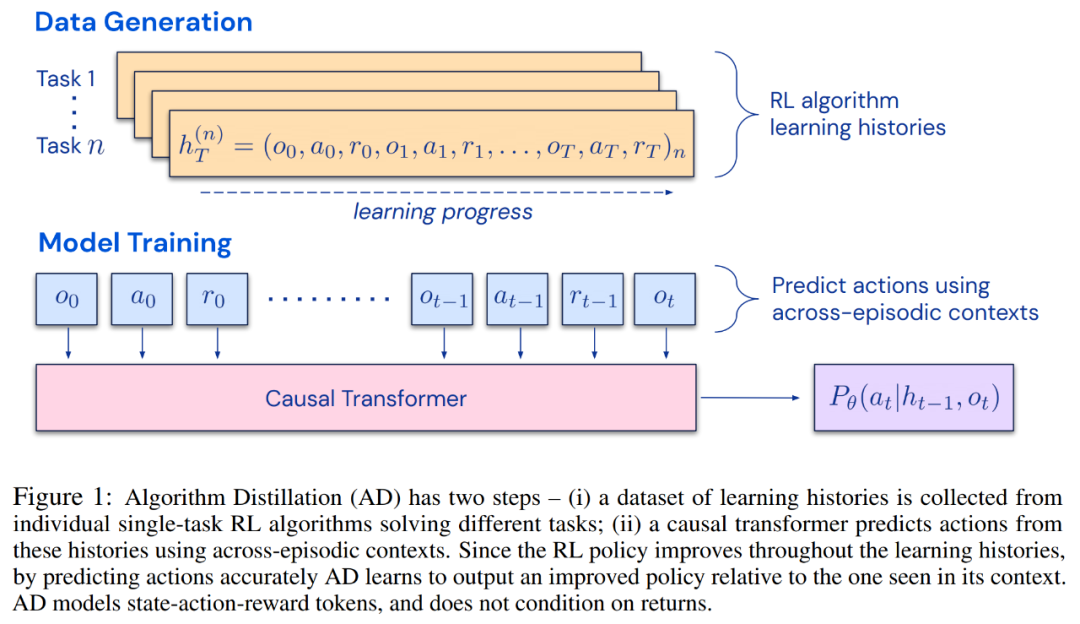
研究者表示,通过使用足够大上下文的因果 transformer 来模仿基于梯度的 RL 算法,AD 完全可以在上下文中强化新任务学习。研究者在很多需要探索的部分可观察环境中评估了 AD,包括来自 DMLab 的基于像素的 Watermaze,结果表明 AD 能够进行上下文探索、时序信度分配和泛化。此外,AD 学习到的算法比生成 transformer 训练源数据的算法更加高效。
6. AI绘画逆着玩火了,敢不敢发自拍看AI如何用文字形容你?
原文:
https://mp.weixin.qq.com/s/TlzktHflCHHmuXDRy4uPgg
笑不活了家人们,最近突然流行起一个新玩法:给AI发自拍,看AI如何描述你。
比如这位勇敢晒出自拍的纽约大学助理教授,他的笑容在AI看来居然是“兽人式微笑”。
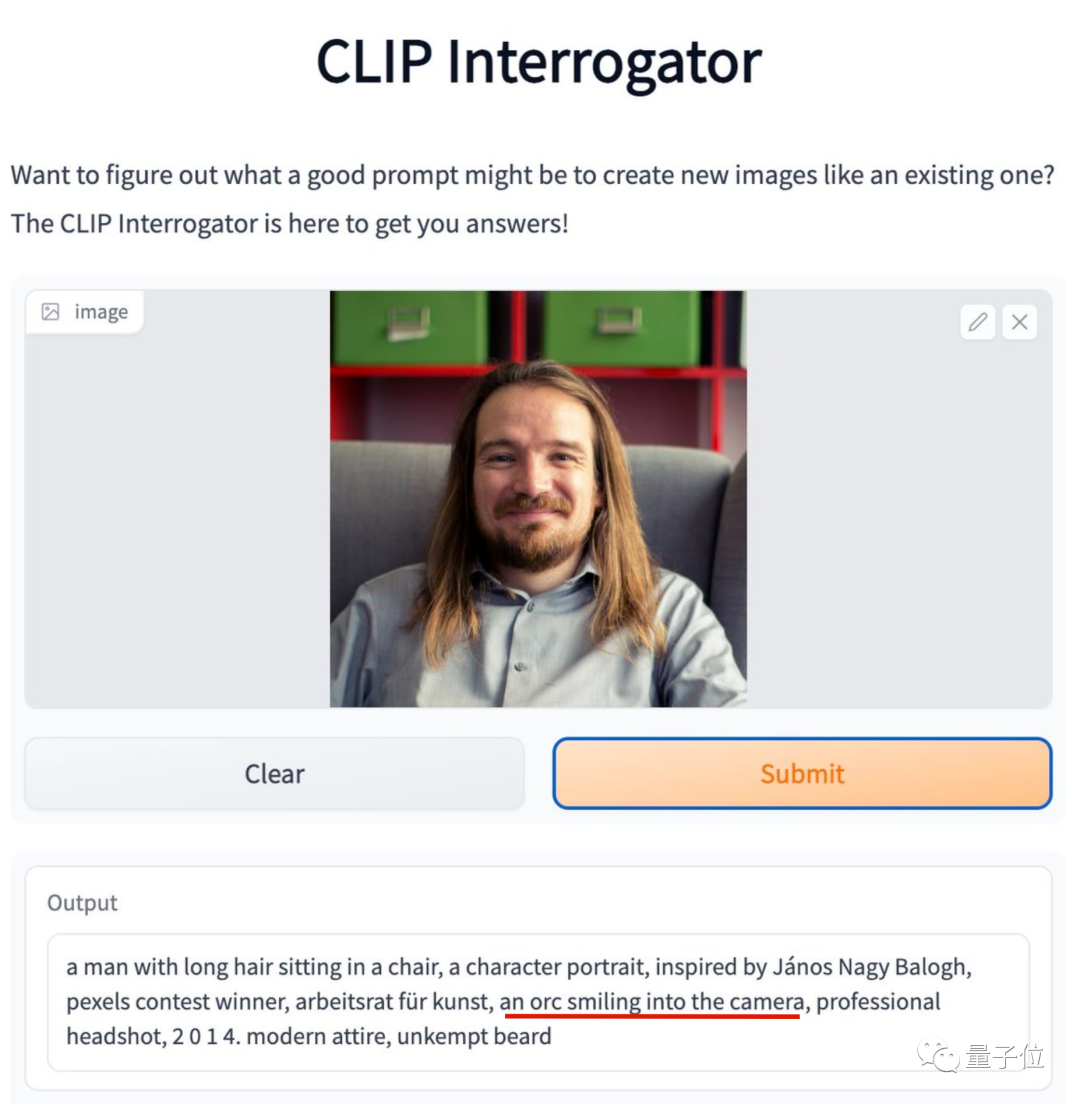
AI还吐槽他胡子没有打理,但他表示拍照那天胡子要比平常整齐多了。

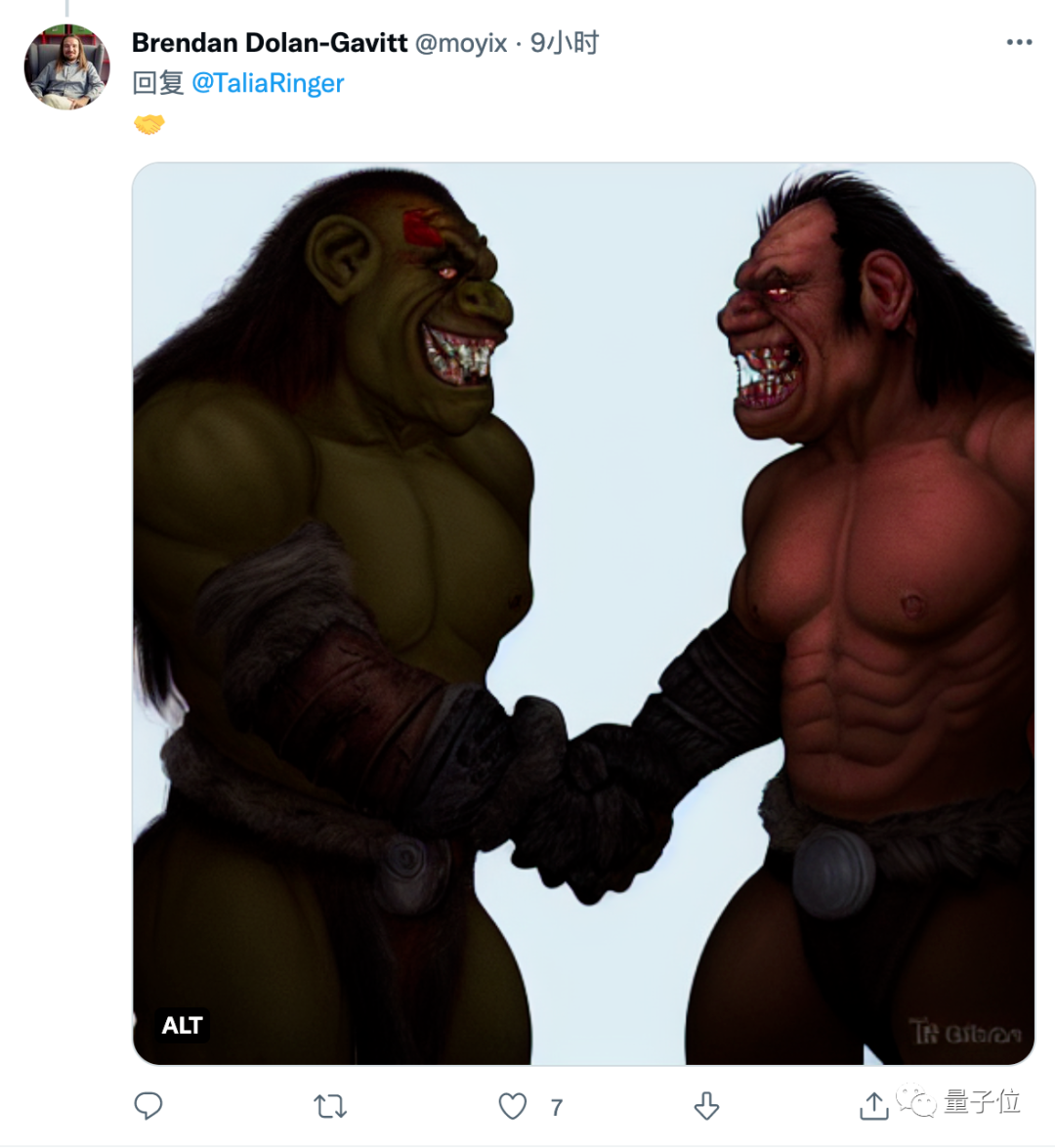
在评论区里还有一位也被评价为兽人微笑的网友现身。两位“部落勇士”就这样赛博认了个亲。
上面这个玩法,相当于把最近火爆的AI绘画逆过来玩,输入图片输出文字描述。
负责文字描述的正是大名鼎鼎的CLIP,也就是DALL·E、Stable Diffusion等AI绘画模型中负责理解语言的那部分。
目前这个CLIP Interrogator(CLIP审问官),在HuggingFace上已有现成的Demo可玩。

7. 《YOLOv5全面解析教程》一,网络结构逐行代码解析
原文:
https://mp.weixin.qq.com/s/qR2ODIMidsNR_Eznxry5pg
YOLOv5 网络结构解析
引言
YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,
分别应对yaml文件中的depth_multiple和width_multiple参数。
还需要注意一点,官方除了n, s, m, l, x版本外还有n6, s6, m6, l6, x6,区别在于后者是针对更大分辨率的图片比如1280x1280,
当然结构上也有些差异,前者只会下采样到32倍且采用3个预测特征层 , 而后者会下采样64倍,采用4个预测特征层。
本章将以 yolov5s为例 ,从配置文件 models/yolov5s.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml) 到 models/yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py) 源码进行解读。
yolov5s.yaml文件内容:
1nc:80#numberofclasses数据集中的类别数
2depth_multiple:0.33#modeldepthmultiple模型层数因子(用来调整网络的深度)
3width_multiple:0.50#layerchannelmultiple模型通道数因子(用来调整网络的宽度)
4#如何理解这个depth_multiple和width_multiple呢?它决定的是整个模型中的深度(层数)和宽度(通道数),具体怎么调整的结合后面的backbone代码解释。
5
6anchors:#表示作用于当前特征图的Anchor大小为xxx
7#9个anchor,其中P表示特征图的层级,P3/8该层特征图缩放为1/8,是第3层特征
8-[10,13,16,30,33,23]#P3/8,表示[10,13],[16,30],[33,23]3个anchor
9-[30,61,62,45,59,119]#P4/16
10-[116,90,156,198,373,326]#P5/32
11
12
13#YOLOv5sv6.0backbone
14backbone:
15#[from,number,module,args]
16[[-1,1,Conv,[64,6,2,2]],#0-P1/2
17[-1,1,Conv,[128,3,2]],#1-P2/4
18[-1,3,C3,[128]],
19[-1,1,Conv,[256,3,2]],#3-P3/8
20[-1,6,C3,[256]],
21[-1,1,Conv,[512,3,2]],#5-P4/16
22[-1,9,C3,[512]],
23[-1,1,Conv,[1024,3,2]],#7-P5/32
24[-1,3,C3,[1024]],
25[-1,1,SPPF,[1024,5]],#9
26]
27
28#YOLOv5sv6.0head
29head:
30[[-1,1,Conv,[512,1,1]],
31[-1,1,nn.Upsample,[None,2,'nearest']],
32[[-1,6],1,Concat,[1]],#catbackboneP4
33[-1,3,C3,[512,False]],#13
34
35[-1,1,Conv,[256,1,1]],
36[-1,1,nn.Upsample,[None,2,'nearest']],
37[[-1,4],1,Concat,[1]],#catbackboneP3
38[-1,3,C3,[256,False]],#17(P3/8-small)
39
40[-1,1,Conv,[256,3,2]],
41[[-1,14],1,Concat,[1]],#catheadP4
42[-1,3,C3,[512,False]],#20(P4/16-medium)
43
44[-1,1,Conv,[512,3,2]],
45[[-1,10],1,Concat,[1]],#catheadP5
46[-1,3,C3,[1024,False]],#23(P5/32-large)
47
48[[17,20,23],1,Detect,[nc,anchors]],#Detect(P3,P4,P5)
49]
anchors 解读
yolov5 初始化了 9 个 anchors,分别在三个特征图 (feature map)中使用,每个 feature map 的每个 grid cell 都有三个 anchor 进行预测。分配规则:
-
尺度越大的 feature map 越靠前,相对原图的下采样率越小,感受野越小, 所以相对可以预测一些尺度比较小的物体(小目标),分配到的 anchors 越小。
-
尺度越小的 feature map 越靠后,相对原图的下采样率越大,感受野越大, 所以可以预测一些尺度比较大的物体(大目标),所以分配到的 anchors 越大。
-
即在小特征图(feature map)上检测大目标,中等大小的特征图上检测中等目标, 在大特征图上检测小目标。
backbone & head解读
[from, number, module, args] 参数
四个参数的意义分别是:
1、第一个参数 from :从哪一层获得输入,-1表示从上一层获得,[-1, 6]表示从上层和第6层两层获得。
2、第二个参数 number:表示有几个相同的模块,如果为9则表示有9个相同的模块。
3、第三个参数 module:模块的名称,这些模块写在common.py中。
4、第四个参数 args:类的初始化参数,用于解析作为 moudle 的传入参数。
下面以第一个模块Conv 为例介绍下common.py中的模块
更多的内容请点击原文查看.
8. LeCun转推,PyTorch GPU内存分配有了火焰图可视化工具
原文:
https://mp.weixin.qq.com/s/_ChQM04s0900BDWhSBtwvg
近日,PyTorch 核心开发者和 FAIR 研究者 Zachary DeVito 创建了一个新工具(添加实验性 API),通过生成和可视化内存快照(memory snapshot)来可视化 GPU 内存的分配状态。这些内存快照记录了内存分配的堆栈跟踪以及内存在缓存分配器状态中的位置。
接下来,通过将这些内存快照可视化为火焰图(flamegraphs),内存的使用位置也就能一目了然地看到了。
图灵奖得主 Yann Lecun 也转推了这个工具。

下面我们来看这个工具的实现原理(以第一人称「我们」描述)。
可视化快照
_memory_viz.py 工具也可以生成内存的可视化火焰图。

可视化图将分配器中所有的字节(byte)按不同的类来分割成段,如下图所示(原文为可交互视图)。
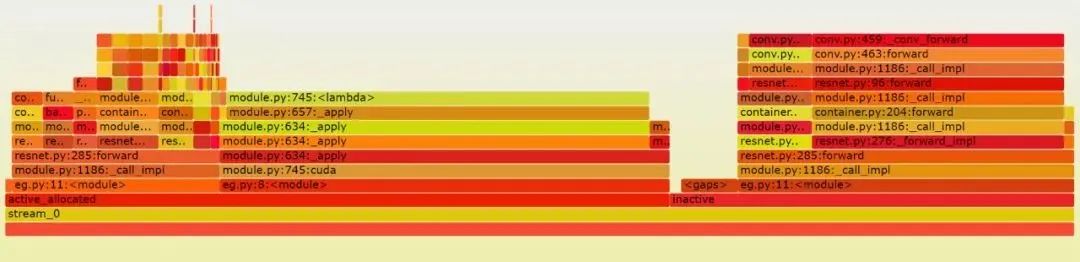
火焰图可视化是一种将资源(如内存)使用划分为不同类的方法,然后可以进一步细分为更细粒度的类别。
memory 视图很好地展现了内存的使用方式。但对于具体地调试分配器问题,首先将内存分类为不同的 Segment 对象是有用的,而这些对象是分配轨迹的单个 cudaMalloc 段。
更多的使用方法,请参考原文!
END

-
RT-Thread
+关注
关注
32文章
1644浏览量
45296
原文标题:【AI简报20221028】 vivo公布自研芯片、AR-HUD处于爆发前夜
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
加快进程!Meta计划2027年底前推出四代自研AI芯片
阿里自研AI芯片“真武”亮相 “通云哥”黄金三角浮出水面
基于太阳光模拟的AR-HUD聚焦光斑检测

不同光照模拟下的车载 AR-HUD 颜色可见性评估
1600TOPS!美国新势力车企自研5nm芯片,转用激光雷达硬刚特斯拉

艾迈斯欧司朗X零跑汽车强强联合:AR-HUD赋能视驾协同,共启智驾新体验

CINNO预计2025年中国乘用车市HUD渗透率约17%
AI业界新闻:OpenAI官宣自研首颗芯片 黄仁勋时隔9年再次给马斯克“送货”
经纬恒润AR-HUD双奖加冕

经纬恒润超清观感AR-HUD:日夜兼程,持续守护,画面始终通透清晰

Arm CEO:公司正在自研芯片
AR-HUD动态环境测试:太阳光模拟器的技术突破
深耕AR-HUD赛道!经纬恒润市占率跻身前五




评论